


Inferens LLM pada berbilang GPU menggunakan perpustakaan Accelerate

Model bahasa berskala besar (llm) telah merevolusikan bidang pemprosesan bahasa semula jadi. Apabila model ini berkembang dalam saiz dan kerumitan, permintaan pengiraan inferens juga meningkat dengan ketara. Untuk menangani cabaran ini, memanfaatkan berbilang GPU menjadi kritikal.

Oleh itu, artikel ini akan melakukan inferens pada berbilang GPU secara serentak Kandungan terutamanya termasuk: pengenalan kepada perpustakaan Accelerate, kaedah mudah dan contoh kod kerja, dan penanda aras prestasi menggunakan berbilang GPU
Artikel ini
. skalakan inferens llama2-7b pada berbilang GPU menggunakan berbilang 3090s
Contoh asas
Kami mula-mula memperkenalkan contoh mudah untuk menunjukkan "melalui mesej" berbilang gpu menggunakan Accelerate .
from accelerate import Accelerator from accelerate.utils import gather_object accelerator = Accelerator() # each GPU creates a string message=[ f"Hello this is GPU {accelerator.process_index}" ] # collect the messages from all GPUs messages=gather_object(message) # output the messages only on the main process with accelerator.print() accelerator.print(messages)
['Hello this is GPU 0', 'Hello this is GPU 1', 'Hello this is GPU 2', 'Hello this is GPU 3', 'Hello this is GPU 4']
Inferens berbilang GPUBerikut ialah kaedah inferens bukan kelompok yang ringkas. Kod ini sangat mudah, kerana perpustakaan Accelerate telah melakukan banyak kerja untuk kami, kami boleh menggunakannya secara langsung:
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:# store output of generations in dictresults=dict(outputs=[], num_tokens=0) # have each GPU do inference, prompt by promptfor prompt in prompts:prompt_tokenized=tokenizer(prompt, return_tensors="pt").to("cuda")output_tokenized = model.generate(**prompt_tokenized, max_new_tokens=100)[0] # remove prompt from output output_tokenized=output_tokenized[len(prompt_tokenized["input_ids"][0]):] # store outputs and number of tokens in result{}results["outputs"].append( tokenizer.decode(output_tokenized) )results["num_tokens"] += len(output_tokenized) results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time {timediff}, total tokens {num_tokens}, total prompts {len(prompts_all)}")
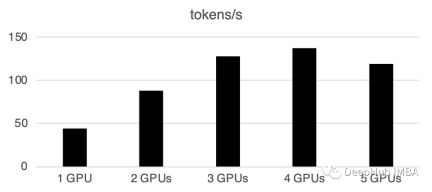
1 GPU: 44 token/saat, masa: 225.5 s
2 GPU: Memproses 88 token sesaat, jumlah masa 112.9 saat
3 GPU: Memproses 128 token sesaat, jumlah masa 77.6 saat
1
1: GPU masa ke 13 saat: : 72.7s
Pemprosesan kelompok pada berbilang GPU
boleh digunakan untuk mempercepatkan perkara dunia naik. Ini mengurangkan komunikasi antara GPU dan mempercepatkan inferens. Kami hanya perlu menambah fungsi prepare_prompts untuk memasukkan sekumpulan data ke dalam model dan bukannya sekeping data:
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() def write_pretty_json(file_path, data):import jsonwith open(file_path, "w") as write_file:json.dump(data, write_file, indent=4) # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) tokenizer.pad_token = tokenizer.eos_token # batch, left pad (for inference), and tokenize def prepare_prompts(prompts, tokenizer, batch_size=16):batches=[prompts[i:i + batch_size] for i in range(0, len(prompts), batch_size)]batches_tok=[]tokenizer.padding_side="left" for prompt_batch in batches:batches_tok.append(tokenizer(prompt_batch, return_tensors="pt", padding='longest', truncatinotallow=False, pad_to_multiple_of=8,add_special_tokens=False).to("cuda") )tokenizer.padding_side="right"return batches_tok # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:results=dict(outputs=[], num_tokens=0) # have each GPU do inference in batchesprompt_batches=prepare_prompts(prompts, tokenizer, batch_size=16) for prompts_tokenized in prompt_batches:outputs_tokenized=model.generate(**prompts_tokenized, max_new_tokens=100) # remove prompt from gen. tokensoutputs_tokenized=[ tok_out[len(tok_in):] for tok_in, tok_out in zip(prompts_tokenized["input_ids"], outputs_tokenized) ] # count and decode gen. tokens num_tokens=sum([ len(t) for t in outputs_tokenized ])outputs=tokenizer.batch_decode(outputs_tokenized) # store in results{} to be gathered by accelerateresults["outputs"].extend(outputs)results["num_tokens"] += num_tokens results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time elapsed: {timediff}, num_tokens {num_tokens}")
Anda dapat melihat bahawa pemprosesan kelompok akan dipercepatkan dengan sangat cepat.
Apa yang perlu ditulis semula ialah: 1 GPU: 520 token/saat, masa: 19.2 saat
Dua GPU mempunyai kuasa pengkomputeran 900 token sesaat, dan masa pengiraan
3 GPU: 1205 token/saat, masa: 8.2s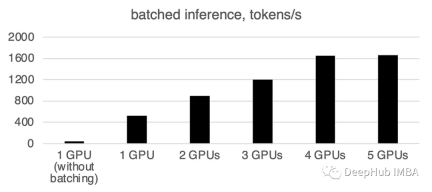
Empat GPU: 1655 token/saat, masa diperlukan: 6.0 saat
5 GPU: 1658 token sesaat. Kad,
0 saat: 6🎜 Ringkasan 🎜🎜🎜🎜 Sehingga artikel ini, llama.cpp dan ctransformer tidak menyokong inferens berbilang GPU Nampaknya llama.cpp mempunyai gabungan berbilang GPU pada bulan Jun, tetapi saya belum melihat kemas kini rasmi. , jadi disahkan bahawa berbilang GPU tidak disokong di sini buat masa ini. Jika sesiapa mengesahkan bahawa ia boleh menyokong berbilang GPU, sila tinggalkan mesej. 🎜🎜🎜🎜Pakej Accelerate huggingface memberikan kita pilihan yang sangat mudah untuk menggunakan berbilang GPU Menggunakan berbilang GPU untuk inferens boleh meningkatkan prestasi dengan ketara, tetapi kos komunikasi antara GPU meningkat dengan ketara apabila bilangan GPU meningkat. 🎜🎜
Atas ialah kandungan terperinci Inferens LLM pada berbilang GPU menggunakan perpustakaan Accelerate. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Panduan komprehensif untuk ekstrapolasiApr 15, 2025 am 11:38 AM
Panduan komprehensif untuk ekstrapolasiApr 15, 2025 am 11:38 AMPengenalan Katakan ada petani yang setiap hari memerhatikan kemajuan tanaman dalam beberapa minggu. Dia melihat kadar pertumbuhan dan mula merenungkan betapa lebih tinggi tumbuhannya dapat tumbuh dalam beberapa minggu lagi. Dari th
 Kebangkitan AI lembut dan apa maksudnya untuk perniagaan hari iniApr 15, 2025 am 11:36 AM
Kebangkitan AI lembut dan apa maksudnya untuk perniagaan hari iniApr 15, 2025 am 11:36 AMSoft AI-yang ditakrifkan sebagai sistem AI yang direka untuk melaksanakan tugas-tugas tertentu yang sempit menggunakan penalaran, pengiktirafan corak, dan pengambilan keputusan yang fleksibel-bertujuan untuk meniru pemikiran seperti manusia dengan merangkul kekaburan. Tetapi apa maksudnya untuk busine
 Rangka kerja keselamatan yang berkembang untuk sempadan AIApr 15, 2025 am 11:34 AM
Rangka kerja keselamatan yang berkembang untuk sempadan AIApr 15, 2025 am 11:34 AMJawapannya jelas-seperti pengkomputeran awan memerlukan peralihan ke arah alat keselamatan awan asli, AI menuntut satu penyelesaian keselamatan baru yang direka khusus untuk keperluan unik AI. Kebangkitan pengkomputeran awan dan pelajaran keselamatan dipelajari Dalam th
 3 cara AI Generatif menguatkan usahawan: berhati -hati dengan purata!Apr 15, 2025 am 11:33 AM
3 cara AI Generatif menguatkan usahawan: berhati -hati dengan purata!Apr 15, 2025 am 11:33 AMUsahawan dan menggunakan AI dan Generatif AI untuk menjadikan perniagaan mereka lebih baik. Pada masa yang sama, adalah penting untuk mengingati AI generatif, seperti semua teknologi, adalah penguat - menjadikan yang hebat dan yang biasa -biasa saja, lebih buruk. Kajian 2024 yang ketat o
 Kursus Pendek Baru mengenai Model Embedding oleh Andrew NgApr 15, 2025 am 11:32 AM
Kursus Pendek Baru mengenai Model Embedding oleh Andrew NgApr 15, 2025 am 11:32 AMBuka kunci kekuatan model embedding: menyelam jauh ke kursus baru Andrew Ng Bayangkan masa depan di mana mesin memahami dan menjawab soalan anda dengan ketepatan yang sempurna. Ini bukan fiksyen sains; Terima kasih kepada kemajuan dalam AI, ia menjadi R
 Adakah halusinasi dalam model bahasa besar (LLMS) tidak dapat dielakkan?Apr 15, 2025 am 11:31 AM
Adakah halusinasi dalam model bahasa besar (LLMS) tidak dapat dielakkan?Apr 15, 2025 am 11:31 AMModel bahasa besar (LLM) dan masalah halusinasi yang tidak dapat dielakkan Anda mungkin menggunakan model AI seperti ChatGPT, Claude, dan Gemini. Ini semua contoh model bahasa besar (LLM), sistem AI yang kuat yang dilatih dalam dataset teks besar -besaran ke
 Masalah 60% - Bagaimana carian AI mengalir trafik andaApr 15, 2025 am 11:28 AM
Masalah 60% - Bagaimana carian AI mengalir trafik andaApr 15, 2025 am 11:28 AMPenyelidikan baru-baru ini telah menunjukkan bahawa gambaran AI boleh menyebabkan penurunan 15-64% dalam trafik organik, berdasarkan jenis industri dan carian. Perubahan radikal ini menyebabkan pemasar untuk menimbang semula keseluruhan strategi mereka mengenai penglihatan digital. Yang baru
 Makmal Media MIT untuk meletakkan manusia berkembang di tengah -tengah AI R & DApr 15, 2025 am 11:26 AM
Makmal Media MIT untuk meletakkan manusia berkembang di tengah -tengah AI R & DApr 15, 2025 am 11:26 AMLaporan baru -baru ini dari Elon University Imagining the Digital Future Centre meninjau hampir 300 pakar teknologi global. Laporan yang dihasilkan, 'Menjadi Manusia pada tahun 2035', menyimpulkan bahawa kebanyakannya bimbang bahawa penggunaan sistem AI yang mendalam lebih daripada t


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

Dreamweaver Mac版
Alat pembangunan web visual

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

