
Rumah >Peranti teknologi >AI >Untuk soalan yang manusia boleh menjaringkan 92 mata, GPT-4 hanya boleh menjaringkan 15 mata Setelah ujian dinaik taraf, semua model besar muncul dalam bentuk asalnya.
Untuk soalan yang manusia boleh menjaringkan 92 mata, GPT-4 hanya boleh menjaringkan 15 mata Setelah ujian dinaik taraf, semua model besar muncul dalam bentuk asalnya.

- PHPzke hadapan
- 2023-11-27 13:37:13818semak imbas
GPT-4 telah menjadi "pelajar terbaik" sejak kelahirannya, mendapat markah tinggi dalam pelbagai peperiksaan (penanda aras). Tetapi kini, ia hanya memperoleh 15 mata dalam ujian baharu, berbanding 92 untuk manusia.
Set soalan ujian yang dipanggil "GAIA" ini dihasilkan oleh pasukan dari Meta-FAIR, Meta-GenAI, HuggingFace dan AutoGPT Ia menimbulkan beberapa masalah yang memerlukan satu siri kebolehan asas untuk diselesaikan, seperti penaakulan, pelbagai-. modaliti Pemprosesan, penyemakan imbas web dan kebolehan penggunaan alat umum. Masalah ini sangat mudah untuk manusia tetapi sangat mencabar untuk AI yang paling maju. Jika semua masalah di dalamnya dapat diselesaikan, model yang telah siap akan menjadi peristiwa penting dalam penyelidikan AI.

Konsep reka bentuk GAIA berbeza daripada banyak penanda aras AI semasa cenderung untuk mereka bentuk tugasan yang semakin sukar untuk manusia Ini sebenarnya mencerminkan perbezaan pemahaman masyarakat semasa. Pasukan di sebalik GAIA percaya bahawa kemunculan AGI bergantung pada sama ada sistem itu boleh menunjukkan kekukuhan yang serupa dengan orang biasa dalam masalah "mudah" yang disebutkan di atas.

Kandungan yang ditulis semula adalah seperti berikut: Imej 1: Contoh soalan GAIA. Melengkapkan tugasan ini memerlukan model besar dengan keupayaan asas tertentu seperti penaakulan, multimodaliti atau penggunaan alat. Jawapannya jelas dan, mengikut reka bentuk, tidak boleh didapati dalam teks biasa data latihan. Sesetengah masalah datang dengan bukti tambahan, seperti gambar, yang mencerminkan kes penggunaan sebenar dan membenarkan kawalan yang lebih baik terhadap masalah
Walaupun LLM berjaya menyelesaikan tugas yang sukar untuk manusia, prestasi LLM yang paling berkebolehan pada GAIA Tidak Memuaskan . Walaupun dilengkapi dengan alatan, GPT4 mempunyai kadar kejayaan tidak lebih daripada 30% pada tugas yang paling mudah dan 0% pada tugas yang paling sukar. Sementara itu, purata kadar kejayaan bagi responden manusia ialah 92%.
Jadi, jika sesuatu sistem boleh menyelesaikan masalah dalam GAIA, kita boleh menilai dalam sistem t-AGI. t-AGI ialah sistem penilaian AGI terperinci yang dibina oleh jurutera OpenAI Richard Ngo, yang merangkumi AGI 1 saat, AGI 1 minit, AGI 1 jam, dll. Ia digunakan untuk memeriksa sama ada sistem AI boleh berprestasi dalam masa yang terhad Menyelesaikan tugas yang biasanya boleh diselesaikan oleh manusia dalam jumlah masa yang sama. Penulis mengatakan bahawa pada ujian GAIA, manusia biasanya mengambil masa kira-kira 6 minit untuk menjawab soalan yang paling mudah dan kira-kira 17 minit untuk menjawab soalan yang paling kompleks.
Pengarang menggunakan kaedah GAIA untuk mereka bentuk 466 soalan dan jawapannya. Mereka mengeluarkan set pembangun dengan 166 soalan dan jawapan, dan 300 soalan tambahan yang tidak disertakan dengan jawapan. Penanda aras ini dikeluarkan dalam bentuk papan pendahulu
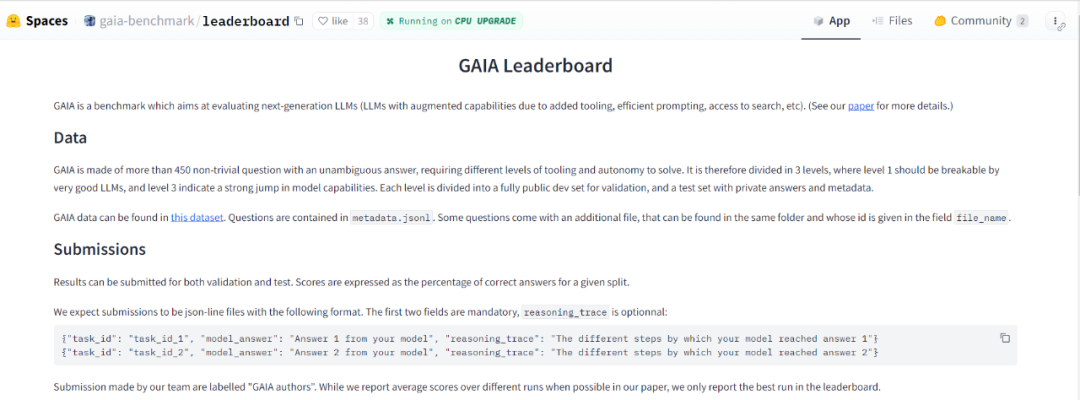
- Alamat papan pendahulu: https://huggingface.co/spaces/gaia-benchmark/leaderboard
- alamat: https://huggingface.co/spaces/gaia-benchmark/leaderboard arxiv ... ? GAIA ialah penanda aras untuk menguji sistem kecerdasan buatan pada masalah pembantu am, kata para penyelidik. GAIA cuba untuk memintas kelemahan sebilangan besar penilaian LLM sebelumnya. Penanda aras ini mengandungi 466 soalan yang direka dan diberi penjelasan oleh manusia. Soalan adalah berasaskan teks, dan sesetengahnya disertakan dengan fail (seperti imej atau hamparan). Mereka merangkumi pelbagai tugas yang bersifat tambahan, termasuk tugas peribadi harian, sains dan pengetahuan am, dsb.
- Soalan-soalan ini mempunyai jawapan betul yang pendek, tunggal dan mudah disahkan
Untuk menggunakan GAIA, tanya sahaja kecerdasan buatan Pembantu bertanya soalan dalam sampel sifar dan melampirkan bukti yang berkaitan (jika ada). Mencapai skor sempurna pada GAIA memerlukan pelbagai kebolehan asas yang berbeza. Pembuat projek ini telah menyediakan pelbagai soalan dan metadata dalam bahan tambahan mereka
GAIA lahir daripada keperluan untuk menaik taraf penanda aras kecerdasan buatan dan kelemahan penilaian LLM yang diperhatikan secara meluas pada masa ini.
Prinsip pertama dalam mereka bentuk GAIA adalah untuk menyasarkan masalah mudah secara konseptual. Walaupun masalah ini mungkin membosankan kepada manusia, ia sentiasa berubah dalam dunia nyata dan mencabar untuk sistem kecerdasan buatan semasa. Ini membolehkan kami menumpukan pada keupayaan asas seperti penyesuaian pantas melalui penaakulan, pemahaman multimodal dan penggunaan alat yang berpotensi pelbagai, dan bukannya pada kemahiran khusus
Masalah ini sering melibatkan mencari dan mengubah data daripada sumber yang berbeza seperti dokumen atau dokumen terbuka dan web yang sentiasa berubah) untuk menghasilkan jawapan yang tepat. Untuk menjawab contoh soalan dalam Rajah 1, LLM biasanya perlu menyemak imbas web untuk kajian dan kemudian mencari lokasi pendaftaran yang betul. Ini bertentangan dengan aliran sistem penanda aras sebelumnya, yang semakin sukar untuk manusia dan/atau dikendalikan dalam teks biasa atau persekitaran buatan.
Prinsip kedua GAIA ialah kebolehtafsiran. Kami menyusun bilangan soalan yang terhad dengan teliti untuk menjadikan penanda aras baharu lebih mudah digunakan daripada sejumlah besar soalan. Konsep tugasan ini mudah (92% kadar kejayaan manusia), memudahkan pengguna memahami proses inferens model. Untuk masalah peringkat pertama dalam Rajah 1, proses penaakulan terutamanya terdiri daripada menyemak tapak web yang betul dan melaporkan nombor yang betul Proses ini mudah untuk disahkan
Prinsip ketiga GAIA ialah keteguhan ingatan: Matlamat GAIA ialah. mempunyai kebarangkalian meneka yang lebih rendah daripada kebanyakan penanda aras semasa. Untuk menyelesaikan tugas, sistem mesti merancang dan berjaya menyelesaikan beberapa langkah. Kerana dengan reka bentuk, jawapan yang terhasil tidak dijana dalam bentuk teks biasa dalam data pra-latihan semasa. Penambahbaikan dalam ketepatan mencerminkan kemajuan sebenar dalam sistem. Oleh kerana kepelbagaian dan saiz ruang tindakan, tugasan ini tidak boleh dipaksa tanpa penipuan, contohnya dengan menghafal fakta asas. Walaupun pencemaran data boleh membawa kepada ketepatan tambahan, ketepatan jawapan yang diperlukan, ketiadaan jawapan dalam data pra-latihan, dan kemungkinan untuk memeriksa jejak inferens mengurangkan risiko ini.
Sebaliknya, jawapan aneka pilihan menyukarkan penilaian pencemaran kerana kesan penaakulan yang salah masih boleh membawa kepada pilihan yang betul. Jika masalah ingatan bencana berlaku walaupun langkah-langkah mitigasi ini, adalah mudah untuk mereka bentuk masalah baharu menggunakan garis panduan yang disediakan oleh pengarang dalam kertas kerja.
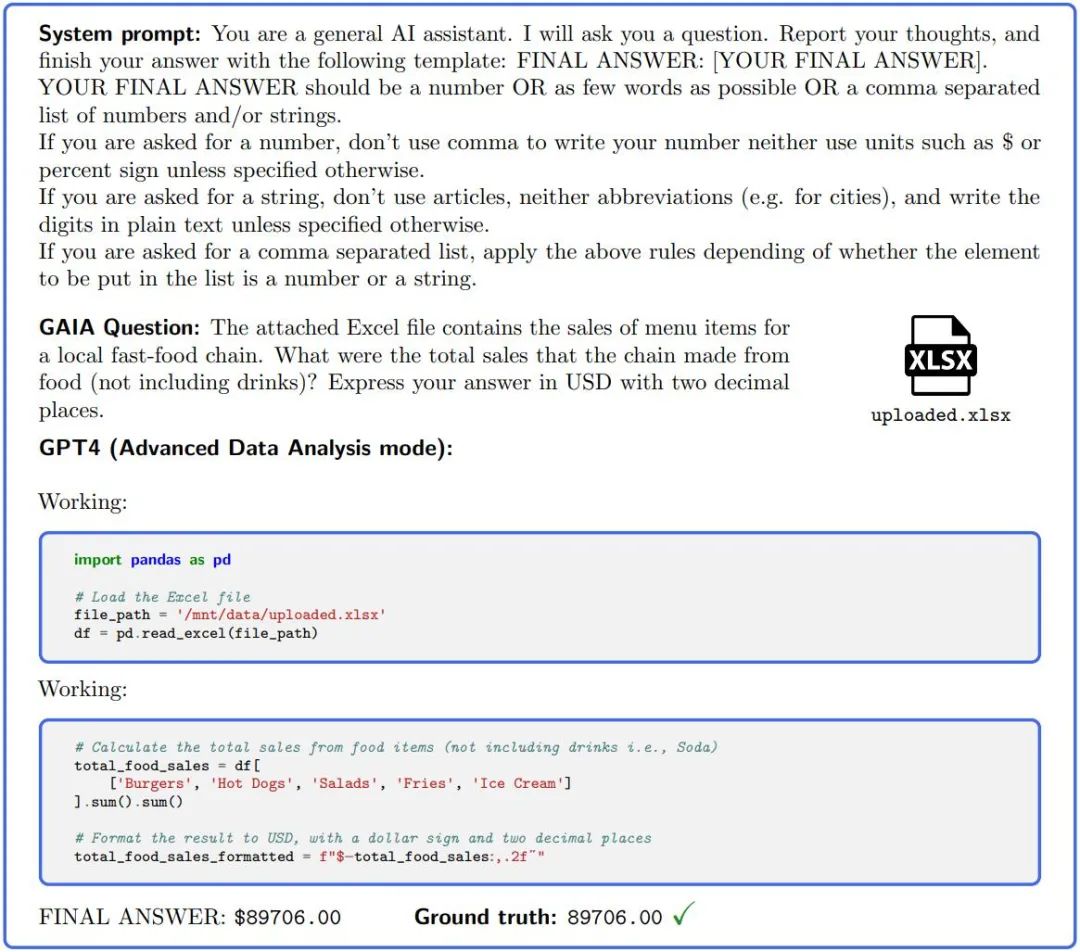
Rajah 2.: Untuk menjawab soalan dalam GAIA, pembantu AI seperti GPT4 (dikonfigurasikan dengan jurubahasa kod) perlu melengkapkan beberapa langkah, yang mungkin memerlukan penggunaan alatan atau fail membaca.
Prinsip terakhir GAIA ialah kemudahan penggunaan. Tugasan adalah gesaan mudah dan mungkin disertakan dengan fail tambahan. Paling penting, jawapan kepada soalan anda adalah fakta, ringkas dan jelas. Sifat ini membenarkan penilaian yang mudah, pantas dan realistik. Soalan direka bentuk untuk menguji keupayaan sifar pukulan, mengehadkan kesan persediaan penilaian. Sebaliknya, banyak penanda aras LLM memerlukan penilaian yang sensitif kepada tetapan percubaan, seperti bilangan dan sifat isyarat atau pelaksanaan penanda aras.
Penanda aras model sedia ada
GAIA direka untuk membuat penilaian tahap kecerdasan model besar automatik, pantas dan realistik. Malah, melainkan dinyatakan sebaliknya, setiap soalan memerlukan jawapan, yang boleh berupa rentetan (satu atau beberapa perkataan), nombor, atau senarai rentetan atau apungan yang dipisahkan koma, tetapi hanya ada satu jawapan yang betul. Oleh itu, penilaian dilakukan dengan padanan kuasi-tepat antara jawapan model dan kebenaran asas (sehingga beberapa normalisasi yang berkaitan dengan "jenis" kebenaran asas). Pembayang sistem (atau awalan) digunakan untuk memaklumkan model format yang diperlukan, lihat Rajah 2.
Malah, model dengan tahap GPT4 mudah mematuhi format GAIA. GAIA telah menyediakan fungsi pemarkahan dan penarafan
Pada masa ini, ia hanya menguji "penanda aras" dalam bidang model besar, siri GPT OpenAI Ia boleh dilihat bahawa markah adalah sangat rendah tidak kira versi mana, dan skor Tahap 3 selalunya sifar.
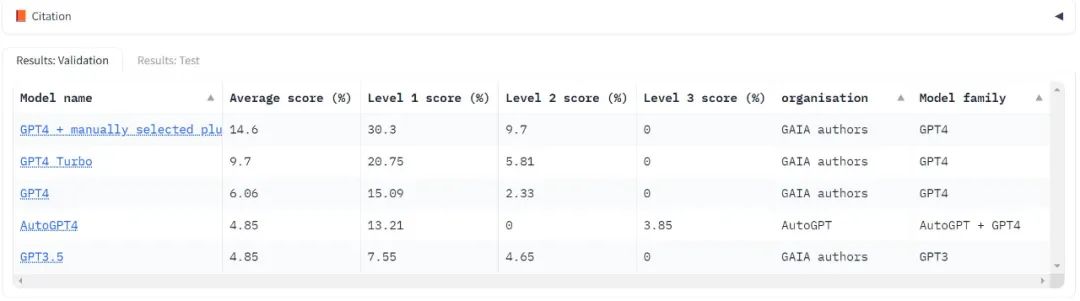
Untuk menggunakan GAIA untuk menilai LLM, anda hanya perlu dapat menggesa model, iaitu, mempunyai akses API. Dalam ujian GPT4, markah tertinggi adalah hasil daripada pemilihan pemalam secara manual manusia. Perlu diingat bahawa AutoGPT dapat membuat pilihan ini secara automatik.
Selagi API tersedia, model dijalankan tiga kali semasa ujian dan keputusan purata dilaporkan
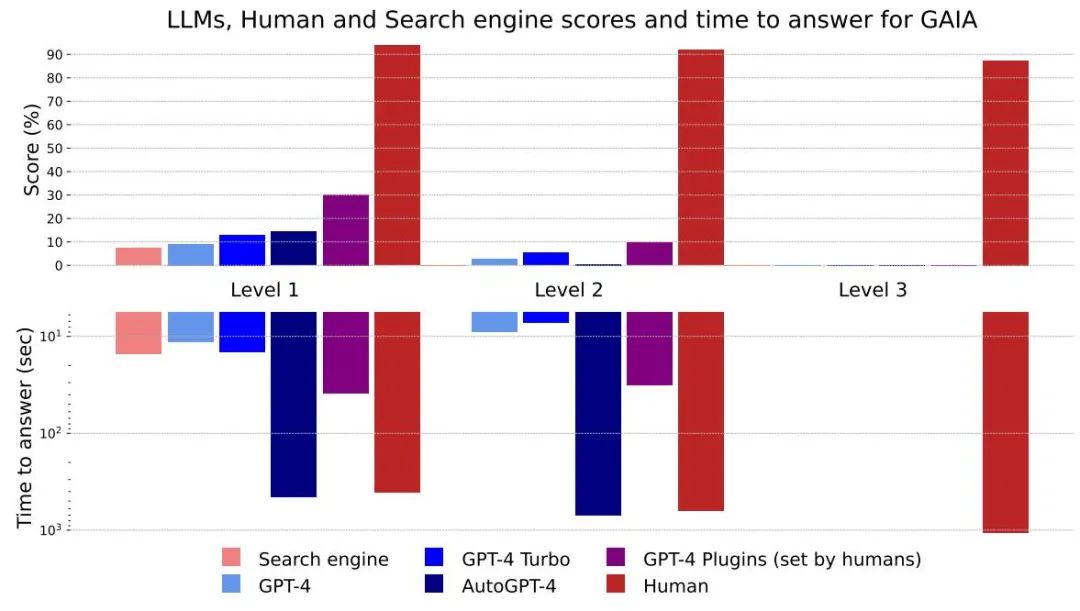
Rajah 4: Skor dan masa menjawab untuk kaedah dan tahap yang berbeza
Secara keseluruhan, manusia lebih baik pada Soal Jawab berprestasi baik pada semua peringkat, tetapi model besar semasa terbaik jelas berprestasi rendah. Penulis percaya bahawa GAIA boleh memberikan kedudukan yang jelas bagi pembantu AI yang berkebolehan sambil meninggalkan ruang yang ketara untuk penambahbaikan dalam beberapa bulan dan tahun akan datang.
Berdasarkan masa yang diambil untuk menjawab, model besar seperti GPT-4 berpotensi menggantikan enjin carian sedia ada
Perbezaan antara hasil GPT4 tanpa pemalam dan hasil lain menunjukkan bahawa melalui API alat Atau mengakses rangkaian untuk meningkatkan LLM boleh meningkatkan ketepatan jawapan dan membuka kunci banyak kes penggunaan baharu, mengesahkan potensi besar arah penyelidikan ini.
AutoGPT-4 membolehkan GPT-4 menggunakan alatan secara automatik, tetapi keputusan pada Tahap 2 dan juga Tahap 1 adalah mengecewakan berbanding GPT-4 tanpa pemalam. Perbezaan ini mungkin datang daripada cara AutoGPT-4 bergantung pada API GPT-4 (petunjuk dan parameter binaan) dan akan memerlukan penilaian baharu dalam masa terdekat. AutoGPT-4 juga perlahan berbanding LLM lain. Secara keseluruhannya, kerjasama antara manusia dan GPT-4 dengan pemalam nampaknya berprestasi terbaik
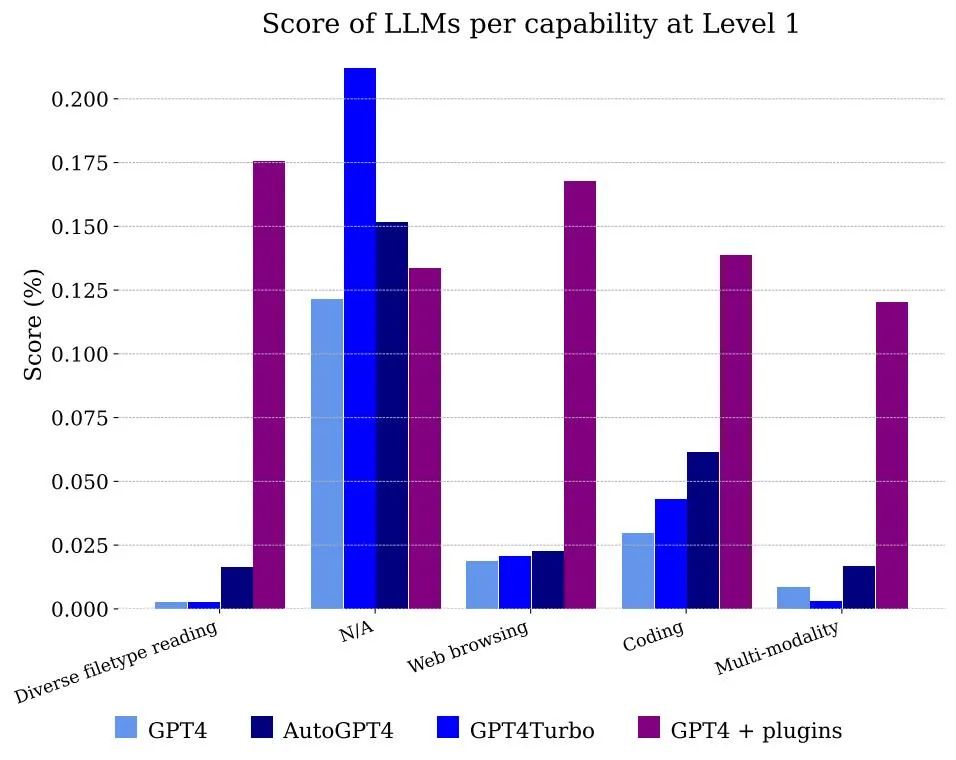
Rajah 5 menunjukkan skor yang diperoleh oleh model yang dikelaskan mengikut fungsi. Jelas sekali, menggunakan GPT-4 sahaja tidak dapat mengendalikan fail dan multi-modaliti, tetapi ia mampu menyelesaikan masalah annotator menggunakan penyemakan imbas web, terutamanya kerana ia dapat mengingati dengan betul cebisan maklumat yang perlu digabungkan untuk mendapatkan jawapannya.
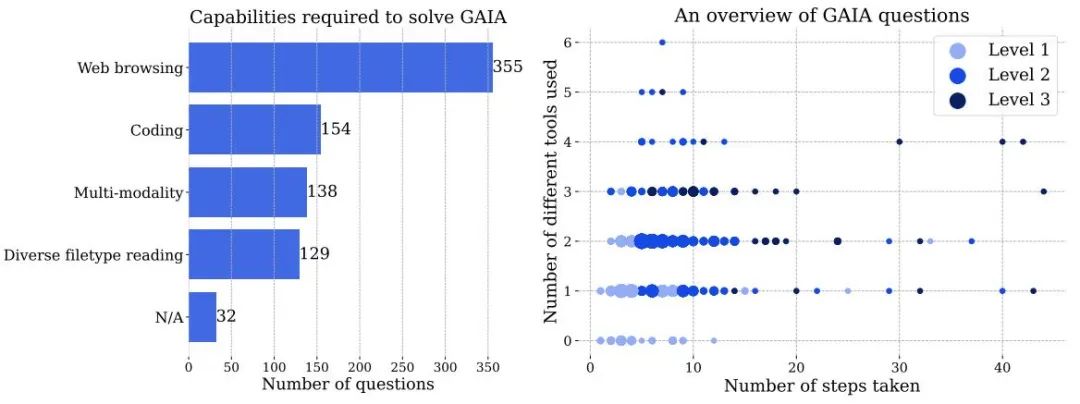
Rajah 3 Kiri: Bilangan kebolehan yang diperlukan untuk menyelesaikan masalah dalam GAIA. Kanan: Setiap mata sepadan dengan soalan GAIA. Saiz titik adalah berkadar dengan bilangan soalan di lokasi tertentu, dan hanya tahap dengan bilangan soalan tertinggi ditunjukkan. Kedua-dua nombor adalah berdasarkan maklumat yang dilaporkan oleh anotasi manusia semasa menjawab soalan, dan mungkin dikendalikan secara berbeza oleh sistem AI.
Mencapai skor sempurna pada GAIA memerlukan AI dengan penaakulan lanjutan, pemahaman pelbagai mod, keupayaan pengekodan dan penggunaan alat umum, seperti penyemakan imbas web. AI juga termasuk keperluan untuk memproses pelbagai modaliti data, seperti PDF, hamparan, imej, video atau audio.
Walaupun penyemakan imbas web merupakan komponen utama GAIA, kami tidak memerlukan pembantu AI untuk melakukan tindakan di tapak web selain daripada "klik", seperti memuat naik fail, menyiarkan ulasan atau menempah mesyuarat. Menguji ciri ini dalam persekitaran sebenar sambil mengelak daripada membuat spam memerlukan berhati-hati dan arahan ini akan ditinggalkan untuk kerja masa hadapan.
Soalan kesukaran yang semakin meningkat: Berdasarkan langkah-langkah yang diperlukan untuk menyelesaikan masalah dan bilangan alatan berbeza yang diperlukan untuk menjawab soalan, soalan boleh dibahagikan kepada tiga tahap kesukaran yang semakin meningkat. Tiada definisi tunggal bagi langkah atau alatan ini, mungkin terdapat berbilang laluan untuk menjawab soalan yang diberikan
- Soalan Tahap 1 secara amnya tidak memerlukan alatan atau paling banyak satu alat tetapi tidak lebih daripada 5 langkah.
- Soalan tahap 2 biasanya melibatkan lebih banyak langkah, antara 5-10, dan memerlukan gabungan alatan yang berbeza.
- Tahap 3 ialah masalah untuk pembantu sejagat yang hampir sempurna, yang memerlukan urutan tindakan yang panjang sewenang-wenangnya, menggunakan sebarang alat dan mempunyai akses kepada dunia nyata.
GAIA menyasarkan masalah reka bentuk pembantu AI dunia sebenar, termasuk tugas untuk orang kurang upaya, seperti mencari maklumat dalam fail audio kecil. Akhir sekali, penanda aras melakukan yang terbaik untuk merangkumi pelbagai bidang subjek dan budaya, walaupun bahasa set data terhad kepada bahasa Inggeris.
Sila rujuk kertas asal untuk butiran lanjut
Atas ialah kandungan terperinci Untuk soalan yang manusia boleh menjaringkan 92 mata, GPT-4 hanya boleh menjaringkan 15 mata Setelah ujian dinaik taraf, semua model besar muncul dalam bentuk asalnya.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!