Stable Video Diffusion secara rasminya mula memproses video -
mengeluarkan model video generatif Stable Video Diffusion (SVD).
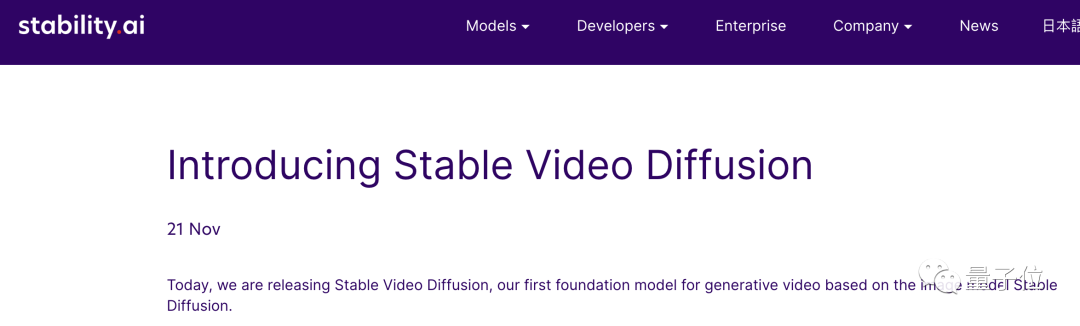
Stability AI blog rasmi menunjukkan bahawa SVD baharu menyokong teks kepada video dan imej kepada penjanaan video:

dan juga menyokong penukaran objek daripada satu perspektif kepada berbilang perspektif, iaitu sintesis 3D :

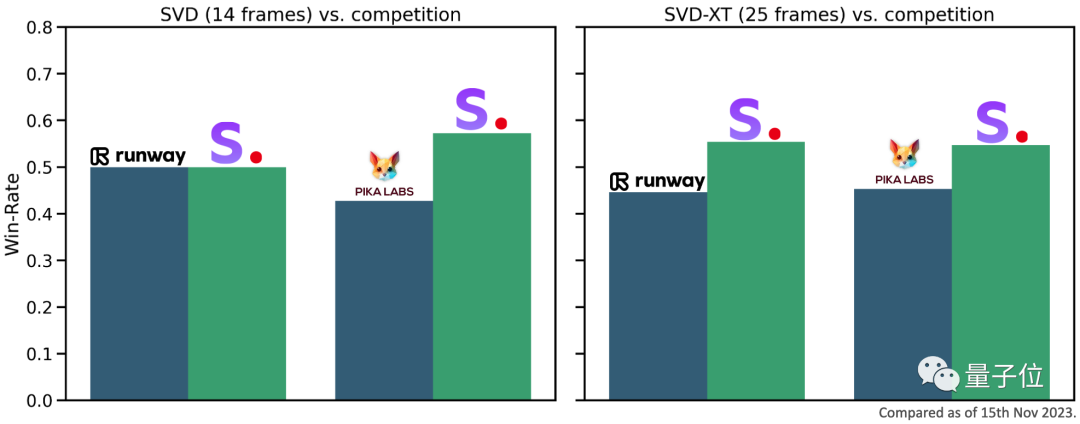
Menurut penilaian luaran, pegawai mendakwa bahawa SVD lebih popular dengan pengguna berbanding landasan dan AI generasi video Pika.
Walaupun hanya model asas telah dikeluarkan setakat ini, pegawai itu mendedahkan bahawa "ia merancang untuk terus mengembangkan dan mewujudkan ekosistem yang serupa dengan penyebaran stabil"
Berat kod kertas kini dalam talian.

Baru-baru ini, kaedah baru telah muncul dalam bidang penjanaan video Kini tiba giliran Stable Diffusion muncul, sehingga netizen mengeluh "cepat", kemajuan sedemikian terlalu pantas!

Tetapi hanya dari kesan demo, lebih ramai netizen mengatakan mereka tidak terkejut sangat.
Walaupun saya suka SD, dan demo ini hebat...tetapi terdapat juga beberapa kelemahan, pencahayaan dan bayang-bayang salah, dan ketidakselarasan keseluruhan
(video berkelip antara bingkai).

Secara keseluruhannya, ini adalah permulaan Netizen sangat optimis tentang fungsi sintesis 3D SVD:
Saya boleh jamin sesuatu yang lebih baik akan keluar tidak lama lagi. Pemandangan 3D yang lengkap

Versi rasmi video SD akan datang
Selain yang ditunjukkan di atas, pegawai itu juga telah mengeluarkan lebih banyak demo, mari kita lihat dahulu:

Space walks are also dijadualkan:
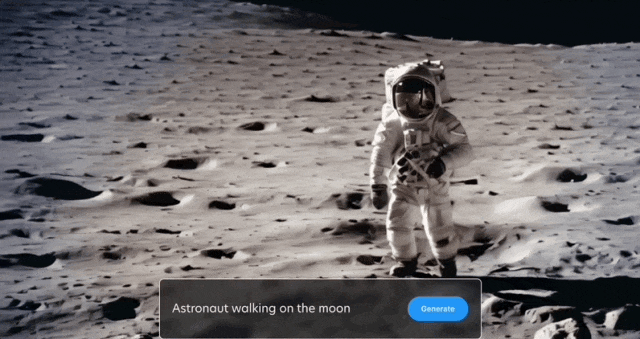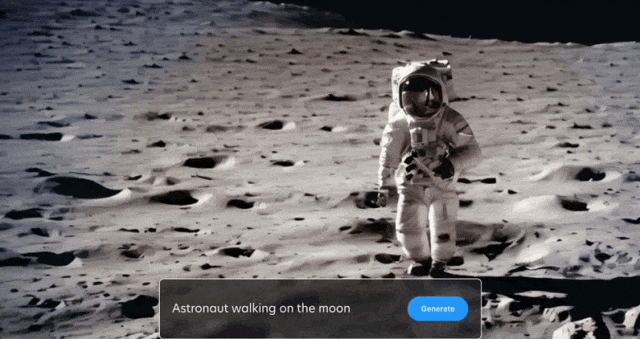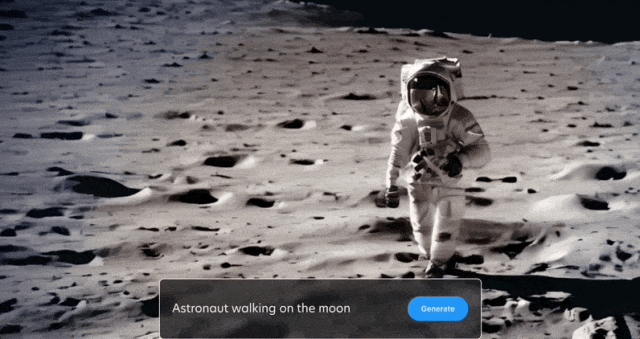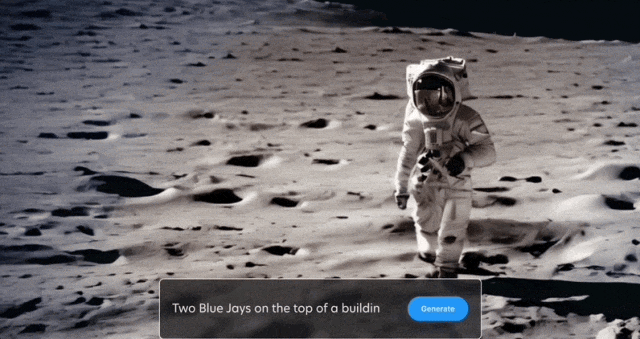
Anda juga boleh mengekalkan latar belakang dan hanya membiarkan dua burung itu bergerak:

Kertas penyelidikan mengenai SVD juga telah dikeluarkan, menurut laporan, SVD adalah berdasarkan penggunaan Stable Diffusion 2.1 set data video kira-kira 600 juta sampel Model asas adalah pra-latihan.
Mudah disesuaikan dengan pelbagai tugas hiliran, termasuk sintesis berbilang paparan daripada satu imej dengan memperhalusi set data berbilang paparan.
Selepas penalaan halus, dua model imej ke video telah diumumkan secara rasmi. Model ini boleh menjana video 14 bingkai (SVD) dan 25 bingkai (SVD-XT) pada kadar bingkai tersuai daripada 3 hingga 30 bingkai sesaat berdasarkan keperluan pengguna
Model penjanaan video berbilang tontonan yang diperhalusi Akhirnya , kami menamakannya SVD-MV

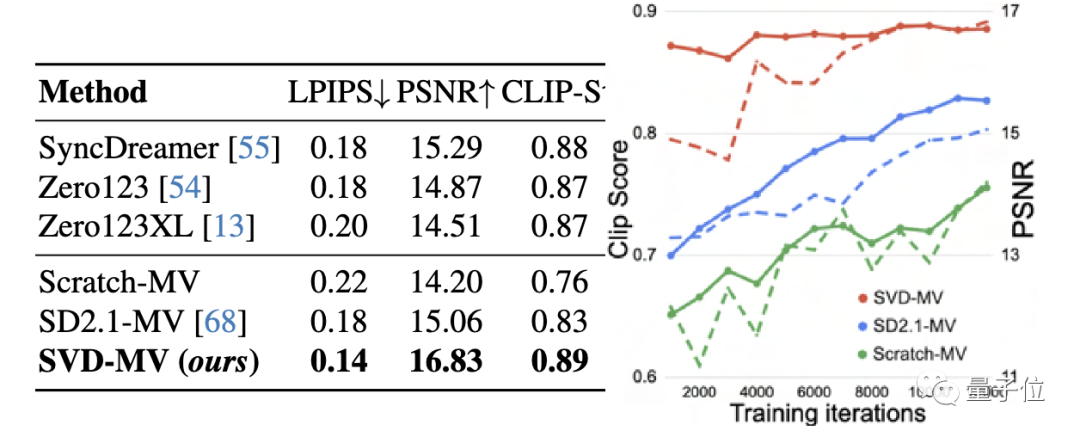
Menurut keputusan ujian, pada set data GSO, SVD-MV mendapat markah lebih baik daripada model generasi berbilang paparan Zero123, Zero123XL, SyncDreamer:
Perlu dinyatakan bahawa Stability AI menyatakan bahawa SVD kini terhad kepada penyelidikan dan tidak sesuai untuk aplikasi praktikal atau komersial. SVD tidak tersedia untuk semua orang pada masa ini, tetapi pendaftaran senarai menunggu pengguna dibuka.
Letupan penjanaan video
Baru-baru ini, berlaku keadaan "melee" dalam bidang penjanaan video
前有#🎜🎜 PikaLabs#🎜 🎜#Dibangunkan Wensheng Video AI:
 kemudiannya dikenali sebagai “generasi video AI paling berkuasa dalam sejarah
kemudiannya dikenali sebagai “generasi video AI paling berkuasa dalam sejarah
Moonvalley 🎜# Dilancarkan:
Baru-baru ini fungsi  "Motion Brush" Gen-2
"Motion Brush" Gen-2
juga telah dilancarkan secara rasmi di mana sahaja anda mahu:
Sekarang SVD telah muncul semula, anda boleh menjana video 3D 
Tetapi teks ke 3D. Nampaknya tidak banyak kemajuan dalam generasi, dan netizen juga sangat keliru dengan fenomena ini 🎜#
Sesetengah netizen berpendapat bahawa masalahnya ialah keupayaan. pembelajaran pengukuhan tidak cukup kuat

#🎜 🎜#Tahukah anda perkembangan terkini dalam bidang ini Selamat datang untuk berkongsi di ruangan komen~
#? 🎜🎜#
Pautan kertas: https://static1.squarespace.com/static/6213c340453c3f502425776e/t/ 655ce779b9d47d342a93c890/17005_473sffusion.pdf
Kandungan yang perlu ditulis semula ialah: 
Atas ialah kandungan terperinci Penyebaran Video Stabil ada di sini! Fungsi sintesis 3D menarik perhatian, netizen: kemajuan terlalu pantas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

