Bagaimanakah kita harus mengoptimumkan model "split everything" Meta Blog yang ditulis oleh pasukan PyTorch ini akan membantu anda menjawabnya dari mudah kepada mendalam.
Dari awal tahun hingga sekarang, AI generatif telah berkembang pesat. Tetapi banyak kali, kita perlu menghadapi masalah yang sukar: bagaimana untuk mempercepatkan latihan, penaakulan, dll. AI generatif, terutamanya apabila menggunakan PyTorch. Dalam artikel ini, penyelidik dari pasukan PyTorch memberikan kami penyelesaian. Artikel ini memfokuskan pada cara menggunakan PyTorch asli tulen untuk mempercepatkan model AI generatif Ia juga memperkenalkan ciri PyTorch baharu dan contoh praktikal tentang cara menggabungkannya. Apakah hasilnya? Pasukan PyTorch berkata mereka menulis semula model "Split Everything" (SAM) Meta, menghasilkan kod yang 8 kali lebih pantas daripada pelaksanaan asal tanpa kehilangan ketepatan, semuanya dioptimumkan menggunakan PyTorch asli. 
Alamat blog: https://pytorch.org/blog/accelerating-generative-ai/Selepas membaca artikel ini, anda akan tahu:
#🎜🎜:#Torch.com Pengkompil model PyTorch, PyTorch 2.0 menambah fungsi baharu yang dipanggil torch.compile (), yang boleh mempercepatkan model sedia ada dengan satu baris kod; dengan mengurangkan ketepatan pengiraan; 🎜# Separa berstruktur (2:4) jarang: format memori yang jarang dioptimumkan untuk GPU; data bersaiz tidak seragam ke dalam tensor tunggal, seperti imej dengan saiz yang berbeza; komponen PyTorch melalui pendaftaran pengendali tersuai.
- atas kepala.
- SAM telah dicadangkan oleh Meta Untuk maklumat lanjut tentang kajian ini, sila rujuk "#. 🎜 🎜#CV tidak lagi wujud? Meta mengeluarkan model AI "Split Everything", CV boleh menyambut detik GPT-3
-
Seterusnya, artikel memperkenalkan proses pengoptimuman SAM, termasuk analisis prestasi, pengenalan kesesakan dan cara mengintegrasikan ciri baharu ini ke dalam PyTorch untuk menyelesaikan masalah dihadapi oleh SAM tentang isu-isu ini. Selain itu, artikel ini juga memperkenalkan beberapa ciri baharu PyTorch: torch.compile, SDPA, kernel Triton, Nested Tensor dan sparsity separa berstruktur.
Kandungan artikel ini secara mendalam langkah demi langkah Pada akhir artikel, versi pantas SAM akan diperkenalkan rakan-rakan boleh memuat turunnya di GitHub Selain itu, artikel ini juga Data ini divisualisasikan melalui UI Perfetto untuk menggambarkan nilai aplikasi setiap ciri PyTorch.
Alamat GitHub: https://github.com/pytorch-labs/segment-anything-fast#🎜 Kajian menyatakan bahawa jenis data garis dasar SAM yang digunakan dalam artikel ini ialah float32 dtype, dan saiz kelompok ialah 1. Keputusan penggunaan PyTorch Profiler untuk melihat surih kernel adalah seperti berikut:
#🎜🎜 #
Artikel ini mendapati terdapat dua tempat di mana SAM boleh dioptimumkan: Yang pertama ialah panggilan panjang ke aten::index, yang disebabkan oleh panggilan asas yang dijana oleh operasi indeks tensor (seperti []) . Walau bagaimanapun, masa sebenar yang dibelanjakan oleh GPU untuk aten::index adalah agak rendah Sebabnya ialah semasa proses memulakan dua teras, aten::index menyekat cudaStreamSynchronize antara mereka. Ini bermakna CPU menunggu sehingga GPU selesai diproses sehingga teras kedua dilancarkan. Oleh itu, untuk mengoptimumkan SAM, kertas kerja ini percaya bahawa seseorang harus berusaha untuk menghapuskan penyegerakan GPU yang menyekat yang menyebabkan masa terbiar. Yang kedua ialah SAM menghabiskan banyak masa GPU dalam pendaraban matriks (hijau gelap dalam imej di atas), yang biasa berlaku dalam Transformers. Jika kita boleh mengurangkan jumlah masa GPU yang dibelanjakan oleh model SAM untuk pendaraban matriks, kita boleh mempercepatkan SAM dengan ketara. Seterusnya, artikel ini menggunakan daya pemprosesan SAM (img/s) dan overhed memori (GiB) untuk mewujudkan garis dasar. Selepas itu datang proses pengoptimuman. . Bfloat16 ialah jenis separuh ketepatan yang biasa digunakan yang boleh menjimatkan banyak masa dan memori pengkomputeran dengan mengurangkan ketepatan setiap parameter dan pengaktifan. 1 Gunakan BFLOAT16 untuk menggantikan jenis Padding Selain itu, untuk mengalih keluar penyegerakan GPU, artikel ini mendapati terdapat dua kedudukan yang boleh dioptimumkan. 
Secara khusus (lebih mudah untuk difahami dengan merujuk kepada gambar di atas, nama pembolehubah yang muncul adalah semua dalam kod), kajian mendapati bahawa dalam pengekod imej SAM, terdapat pembolehubah q_coords dan k_coords, pembolehubah ini diperuntukkan dan diproses pada CPU. Walau bagaimanapun, sebaik sahaja pembolehubah ini digunakan untuk mengindeks dalam rel_pos_resized, operasi pengindeksan ini akan mengalihkan pembolehubah ini secara automatik ke GPU, dan salinan ini akan menyebabkan penyegerakan GPU. Untuk menyelesaikan masalah di atas, kajian menyatakan bahawa bahagian ini boleh diselesaikan dengan menulis semula menggunakan obor.di mana seperti yang ditunjukkan di atas. . Untuk mendapatkan pemahaman yang lebih mendalam tentang fenomena ini, artikel ini bermula dengan analisis prestasi inferens SAM dengan saiz kelompok 8: Apabila melihat masa yang dihabiskan bagi setiap teras, artikel ini memerhatikan bahawa SAM membelanjakan sebahagian besar GPUnya masa Pada kernel mengikut elemen dan operasi softmax. 
Kini anda dapat melihat bahawa kos relatif pendaraban matriks adalah jauh lebih kecil. Menggabungkan penyegerakan GPU dan pengoptimuman bfloat16, prestasi SAM dipertingkatkan sebanyak 3 kali ganda.
Torch.compile (+ pemecahan graf dan graf CUDA) #🎜🎜🎜🎜 dalam artikel ini mendapati bahawa kajian SAM Terdapat banyak operasi kecil dalam proses Mereka percaya bahawa menggunakan pengkompil untuk menyepadukan operasi mempunyai faedah yang besar, jadi PyTorch telah membuat pengoptimuman berikut untuk torch.compile: #🎜🎜🎜##. 🎜🎜## 🎜🎜#
Gabungan urutan operasi seperti nn.LayerNorm atau nn.GELU ke dalam satu kernel GPU; Gabungan mengikuti Operasi selepas kernel pendaraban matriks untuk mengurangkan bilangan panggilan kernel GPU.
- Melalui pengoptimuman ini, kajian telah mengurangkan bilangan perjalanan pergi balik memori global GPU, dengan itu mempercepatkan inferens. Kini kita boleh mencuba torch.compile pada pengekod imej SAM. Untuk memaksimumkan prestasi, artikel ini menggunakan beberapa teknik kompilasi lanjutan: 🎜🎜#
Hasilnya menunjukkan bahawa torch.compile berfungsi dengan baik. Dapat diperhatikan bahawa softmax mengambil sebahagian besar masa, diikuti oleh pelbagai varian GEMM. Ukuran berikut adalah untuk saiz kelompok 8 dan ke atas.
SDPA: scaled_dot_product_attention #🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 #Seterusnya, artikel ini menjalankan percubaan pada SDPA (perhatian_produk_berskala_titik_titik fokus kajian ialah mekanisme perhatian). Secara umum, mekanisme perhatian asli berskala kuadratik dengan panjang jujukan dalam masa dan ingatan. Operasi SDPA PyTorch dibina berdasarkan prinsip perhatian cekap memori Flash Attention, FlashAttentionV2 dan xFormer, yang boleh mempercepatkan perhatian GPU dengan ketara. Digabungkan dengan torch.compile, operasi ini membolehkan menyatakan dan menggabungkan corak biasa dalam varian MultiheadAttention. Selepas perubahan kecil, model kini boleh menggunakan perhatian_produk_berskala.
#🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 #Seterusnya, artikel ini menjalankan percubaan pada SDPA (perhatian_produk_berskala_titik_titik fokus kajian ialah mekanisme perhatian). Secara umum, mekanisme perhatian asli berskala kuadratik dengan panjang jujukan dalam masa dan ingatan. Operasi SDPA PyTorch dibina berdasarkan prinsip perhatian cekap memori Flash Attention, FlashAttentionV2 dan xFormer, yang boleh mempercepatkan perhatian GPU dengan ketara. Digabungkan dengan torch.compile, operasi ini membolehkan menyatakan dan menggabungkan corak biasa dalam varian MultiheadAttention. Selepas perubahan kecil, model kini boleh menggunakan perhatian_produk_berskala.
Kernel Trace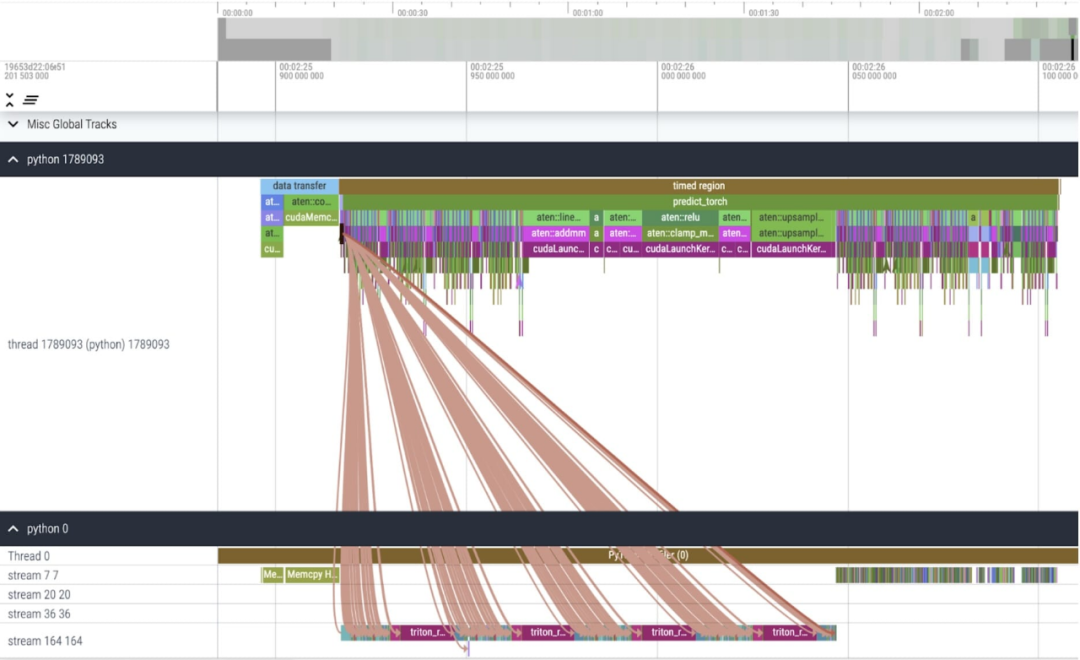
#🎜🎜🎜🎜🎜🎜🎜 Kini anda dapat melihat bahawa kernel perhatian cekap memori mengambil banyak masa pengiraan pada GPU: 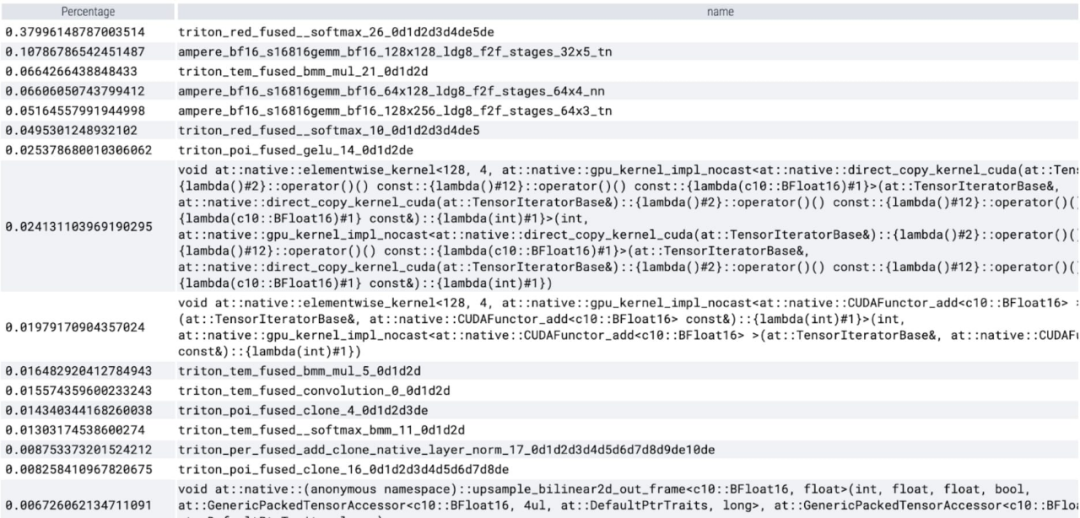
Menggunakan skala_dot_product_attention asli PyTorch, pemprosesan kelompok boleh saiz yang meningkat dengan ketara. Graf di bawah menunjukkan perubahan untuk saiz kelompok 32 dan ke atas. 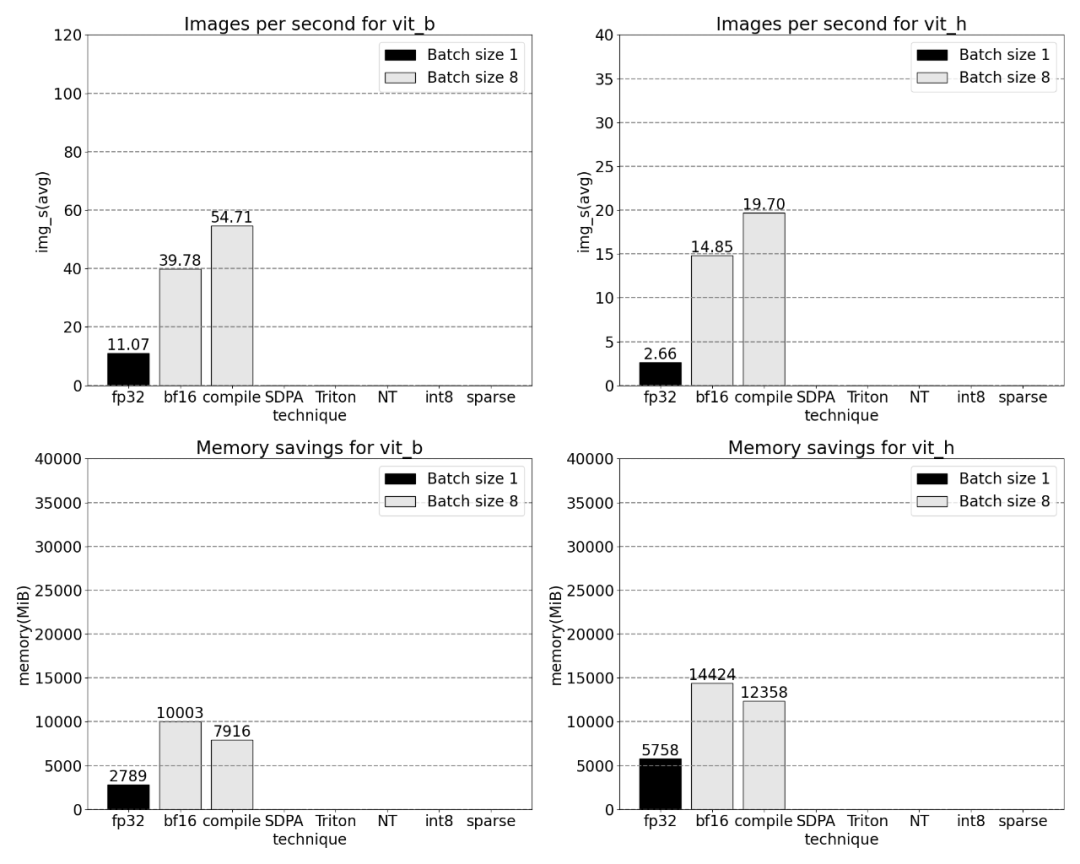
Selepas itu, penyelidikan itu turut bereksperimen dengan Triton, NestedTensor, pemprosesan batch Predict_torch, kuantisasi int8, jimat separa berstruktur (2:4) dan lain-lain operasi.
Sebagai contoh, artikel ini menggunakan kernel Triton kedudukan tersuai dan memerhatikan hasil pengukuran dengan saiz kelompok 32. 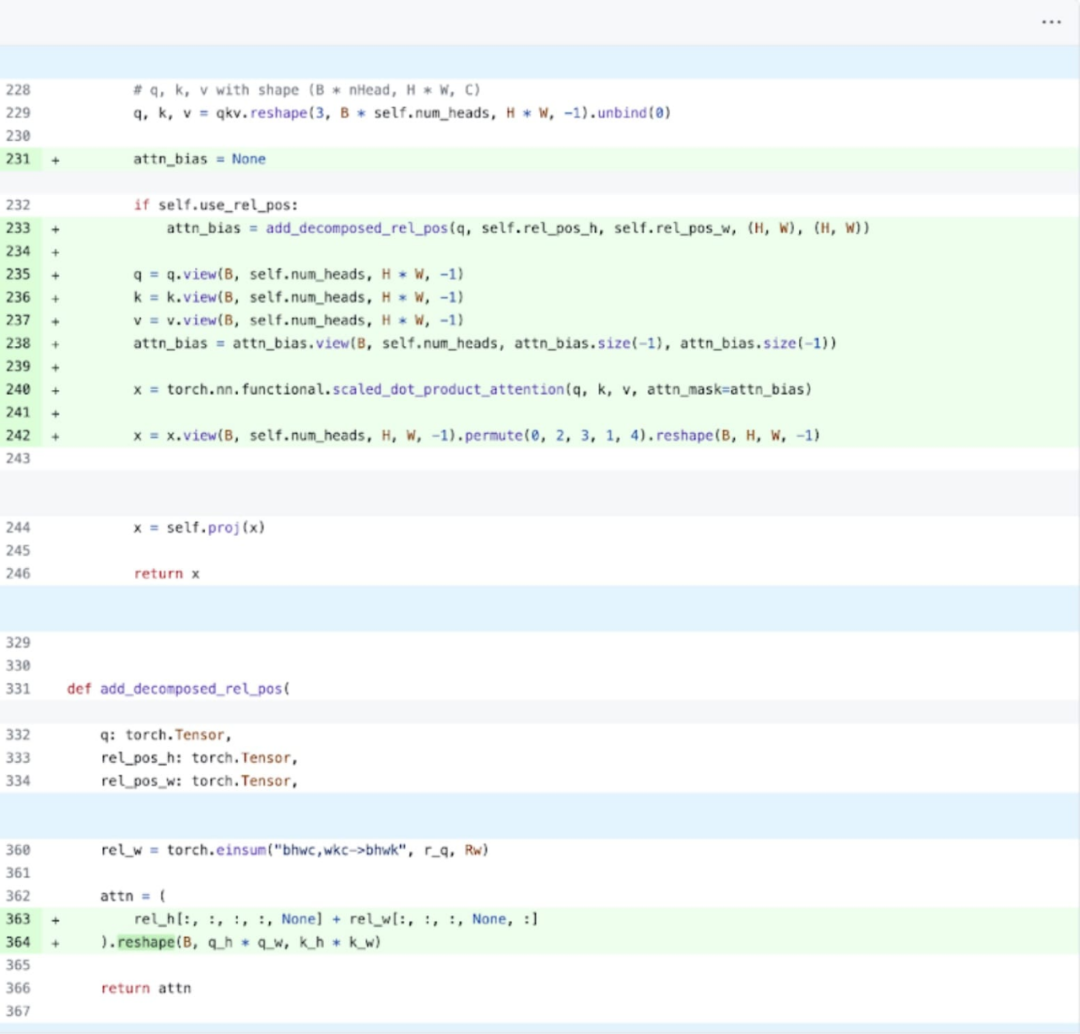 Menggunakan Nested Tensor, saiz kelompok berbeza dari 32 dan ke atas.
Menggunakan Nested Tensor, saiz kelompok berbeza dari 32 dan ke atas.
Ukuran untuk saiz kelompok 32 dan ke atas selepas menambah kuantisasi. Penghujung artikel ialah sparsity separa berstruktur. Kajian menunjukkan bahawa pendaraban matriks masih menjadi hambatan yang perlu dihadapi. Penyelesaiannya adalah dengan menggunakan sparsifikasi untuk menganggarkan pendaraban matriks. Dengan matriks yang jarang (iaitu mensifarkan nilai) lebih sedikit bit boleh digunakan untuk menyimpan pemberat dan tensor pengaktifan. Proses menetapkan pemberat dalam tensor yang ditetapkan kepada sifar dipanggil pemangkasan. Pemangkasan berat yang lebih kecil berpotensi mengurangkan saiz model tanpa kehilangan ketepatan yang ketara. Terdapat banyak cara untuk memangkas, daripada tidak berstruktur sepenuhnya kepada berstruktur tinggi. Walaupun pemangkasan tidak berstruktur secara teorinya mempunyai kesan minimum pada ketepatan, GPU, walaupun sangat cekap dalam melakukan pendaraban matriks padat yang besar, mungkin mengalami kemerosotan prestasi yang ketara dalam kes yang jarang berlaku. Kaedah pemangkasan yang disokong oleh PyTorch baru-baru ini bertujuan untuk mencapai keseimbangan yang dipanggil sparsity separa berstruktur (atau 2:4). Storan yang jarang ini mengurangkan tensor asal sebanyak 50% sambil menghasilkan output tensor yang padat. Lihat ilustrasi di bawah. 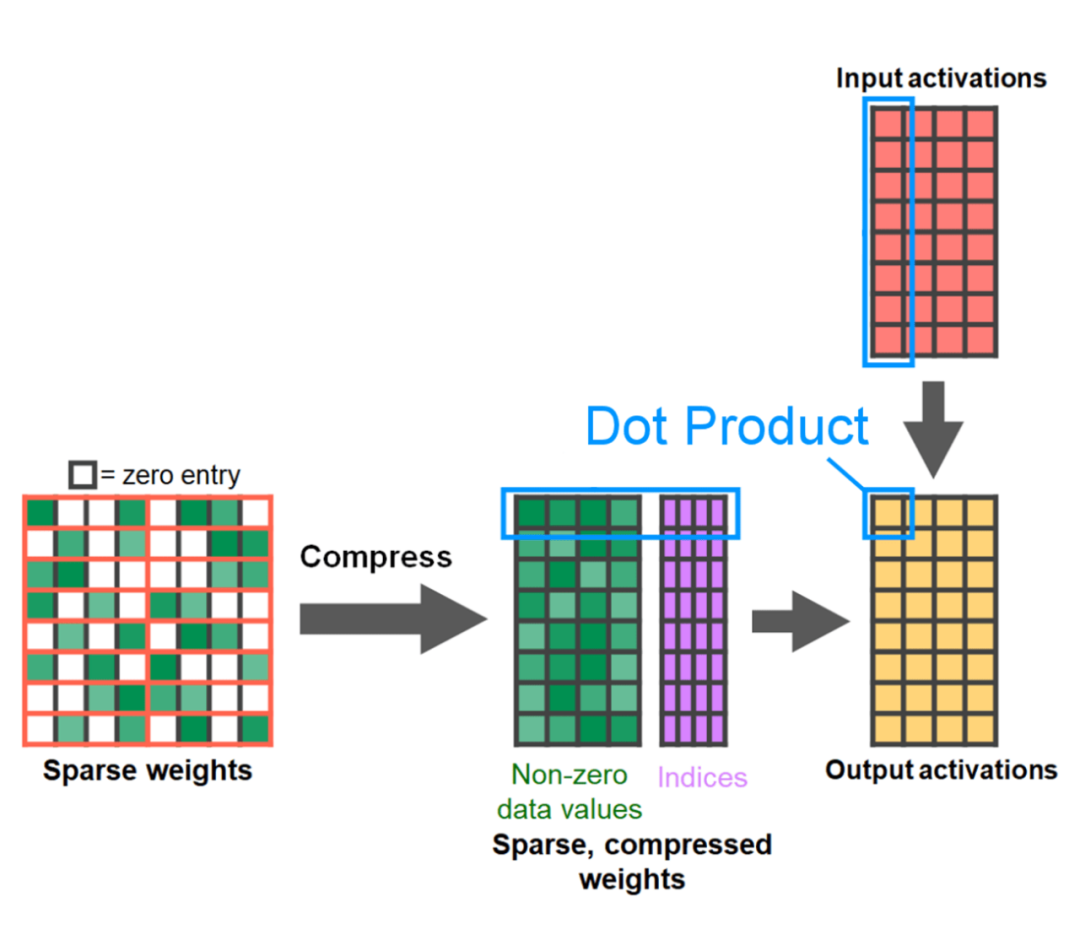
Untuk menggunakan format storan jarang ini dan isirong cepat yang berkaitan, perkara seterusnya yang perlu dilakukan ialah memangkas pemberat. Artikel ini memilih dua pemberat terkecil untuk pemangkasan pada kesederhanaan 2:4 Menukar pemberat daripada reka letak lalai PyTorch ("strided") kepada reka letak jarang separa berstruktur ini adalah mudah. Untuk melaksanakan apply_sparse (model), hanya 32 baris kod Python diperlukan: 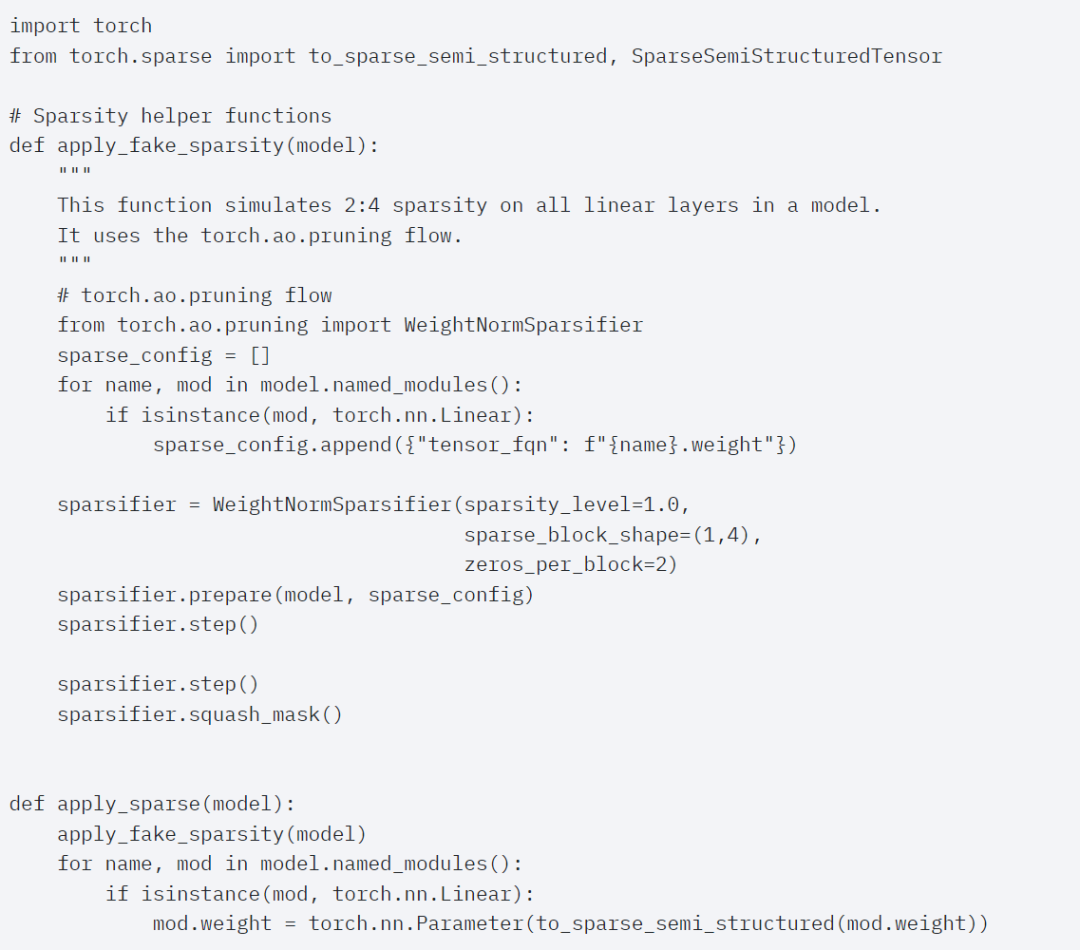
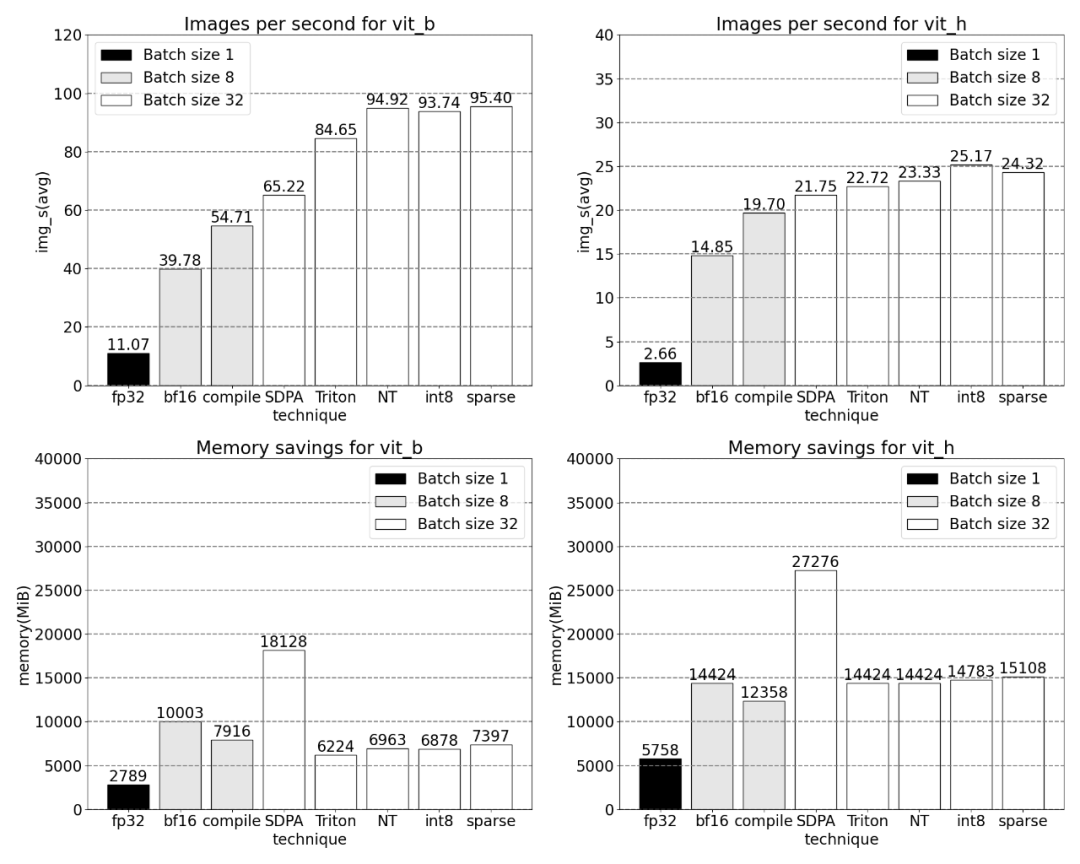
Pada kesederhanaan 2:4, kertas ini memerhatikan prestasi puncak SAM apabila vit_b dan saiz kumpulan ialah 32: 
Untuk meringkaskan artikel ini dalam satu ayat: Artikel ini memperkenalkan pelaksanaan Apa-apa Segmen terpantas pada PyTorch setakat ini Dengan satu siri ciri baharu yang dikeluarkan secara rasmi, artikel ini menulis semula SAM asal dalam PyTorch tulen tanpa kehilangan ketepatan.
Pembaca yang berminat boleh menyemak blog asal untuk maklumat lanjut.
Pautan rujukan: https://pytorch.org/blog/accelerating-generative-ai/🎜🎜Atas ialah kandungan terperinci Pasukan PyTorch menulis semula model 'split everything', iaitu 8 kali lebih pantas daripada pelaksanaan asal. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


