
Rumah >Peranti teknologi >AI >Penyebaran Video Stabil ada di sini, berat kod dalam talian
Penyebaran Video Stabil ada di sini, berat kod dalam talian

- PHPzke hadapan
- 2023-11-22 14:30:481485semak imbas
Stability AI, sebuah syarikat terkenal untuk lukisan AI, akhirnya telah memasuki industri video yang dijana AI.
Selasa ini, Stable Video Diffusion, model penjanaan video berdasarkan penyebaran stabil, telah dilancarkan, dan komuniti AI segera memulakan perbincangan# 🎜🎜#
Ramai orang berkata "Kami akhirnya menunggu."
Pautan projek: https://github.com/Stability-AI/generative-models#🎜🎜
Kini anda boleh menjana beberapa saat video daripada imej pegun sedia adaBerdasarkan Stability AI Stable Diffusion asal Vincent model graf, Stable Video Diffusion telah menjadi salah satu daripada beberapa model penjanaan video dalam peringkat sumber terbuka atau komersial.


Menurut pengenalan, Penyebaran Video Stabil boleh disesuaikan dengan mudah kepada pelbagai tugas hiliran, termasuk sintesis berbilang paparan daripada satu imej dengan menyempurnakan berbilang- lihat set data. AI Stable berkata ia sedang merancang pelbagai model yang membina dan mengembangkan asas ini, serupa dengan ekosistem yang dibina di sekitar resapan stabil #
Dengan penghantaran video yang stabil, 14 dan 25 bingkai video boleh dijana pada kadar bingkai boleh disesuaikan daripada 3 hingga 30 bingkai sesaat #
 Dalam penilaian luaran, Stability AI mengesahkan bahawa model ini mengatasi model sumber tertutup terkemuka dalam penyelidikan keutamaan pengguna:
Dalam penilaian luaran, Stability AI mengesahkan bahawa model ini mengatasi model sumber tertutup terkemuka dalam penyelidikan keutamaan pengguna:

Stability AI menekankan bahawa Stable Video Diffusion atau aplikasi komersial langsung tidak sesuai untuk dunia nyata pada peringkat ini, dan akan dipertingkatkan berdasarkan cerapan pengguna dan maklum balas tentang keselamatan dan kualiti.
 Alamat kertas: https://stability.ai/research/stable-video-diffusion-scaling-latent -model-resapan-video-kepada-set-data-besar
Alamat kertas: https://stability.ai/research/stable-video-diffusion-scaling-latent -model-resapan-video-kepada-set-data-besar
Penghantaran video yang stabil ialah ahli keluarga model sumber terbuka AI Stabil. Nampaknya kini produk mereka merangkumi pelbagai modaliti seperti imej, bahasa, audio, 3D dan kod, yang membuktikan sepenuhnya komitmen mereka untuk meningkatkan kecerdasan buatan
#🎜🎜 Aspek teknikal # Resapan Video Stabil
Sebagai model resapan yang berpotensi untuk video resolusi tinggi, model resapan video stabil telah mencapai tahap SOTA teks-ke-video atau imej-ke-video . Baru-baru ini, model resapan terpendam yang dilatih untuk sintesis imej 2D telah ditukar kepada model video generatif dengan memasukkan lapisan temporal dan memperhalusinya pada set data video berkualiti tinggi yang kecil. Walau bagaimanapun, kaedah latihan berbeza secara meluas dalam kesusasteraan, dan bidang ini masih belum bersetuju mengenai strategi bersatu untuk penyusunan data video Dalam makalah Stable Video Diffusion, Stability AI dikenal pasti dan dinilai Tiga peringkat berbeza untuk melatih model resapan terpendam video. : pra-latihan teks-ke-imej, pra-latihan video dan penalaan halus video berkualiti tinggi. Mereka juga menunjukkan kepentingan set data pra-latihan yang disediakan dengan teliti untuk menjana video berkualiti tinggi dan menerangkan proses penyusunan sistematik untuk melatih model asas yang kukuh, termasuk sari kata dan strategi penapisan.
Stability AI Makalah ini juga meneroka kesan penalaan halus model asas pada data berkualiti tinggi dan melatih model teks ke video yang setanding dengan penjanaan video sumber tertutup. Model ini menyediakan perwakilan gerakan yang berkuasa untuk tugas hiliran seperti penjanaan imej-ke-video dan kebolehsuaian kepada modul LoRA khusus gerakan kamera. Selain itu, model ini juga boleh menyediakan 3D berbilang paparan yang berkuasa, yang boleh digunakan sebagai asas model resapan berbilang paparan #Model menjana berbilang paparan objek dalam cara suapan ke hadapan. hanya memerlukan kuasa pengkomputeran kecil Keperluan, prestasi juga lebih baik daripada kaedah berasaskan imej .

Khususnya, latihan model berjaya memerlukan tiga peringkat berikut : #🎜 berikut 🎜#
Fasa 1: Pra-latihan imej. Artikel ini menganggap imej pra-latihan sebagai peringkat pertama saluran paip latihan, dan membina model awal pada Stable Diffusion 2.1, sekali gus melengkapkan model video dengan perwakilan visual yang berkuasa. Untuk menganalisis kesan pra-latihan imej, artikel ini juga melatih dan membandingkan dua model video yang sama. Keputusan Rajah 3a menunjukkan bahawa model imej pra-latihan lebih diutamakan dari segi kualiti dan penjejakan kiu.
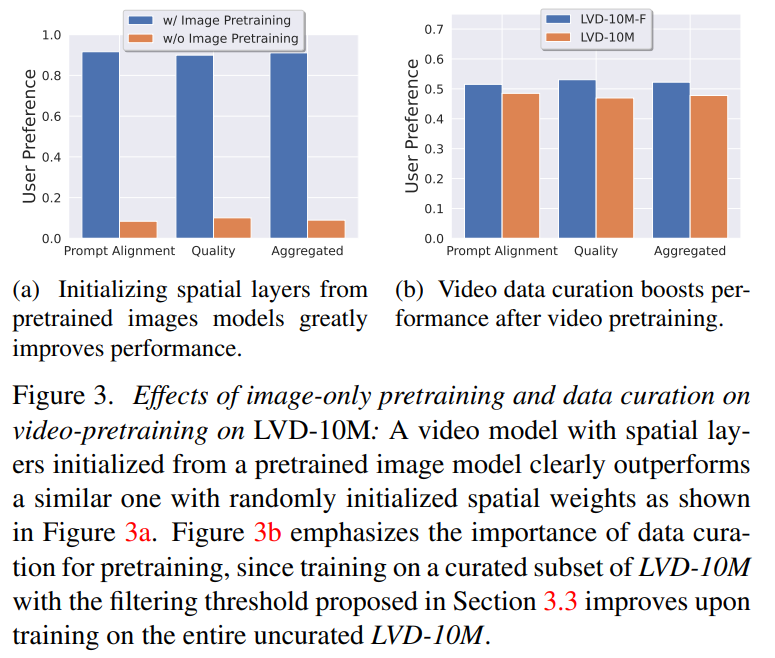
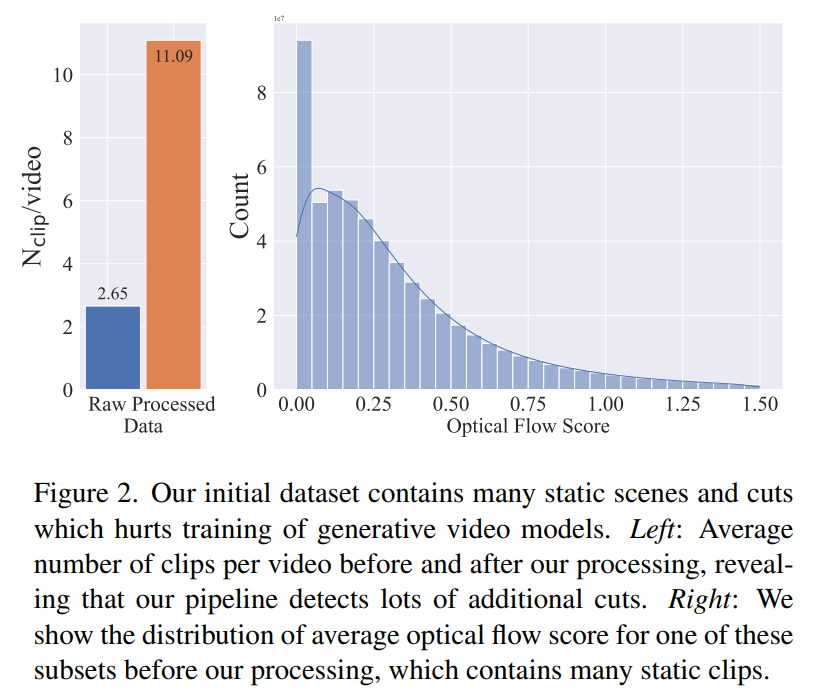
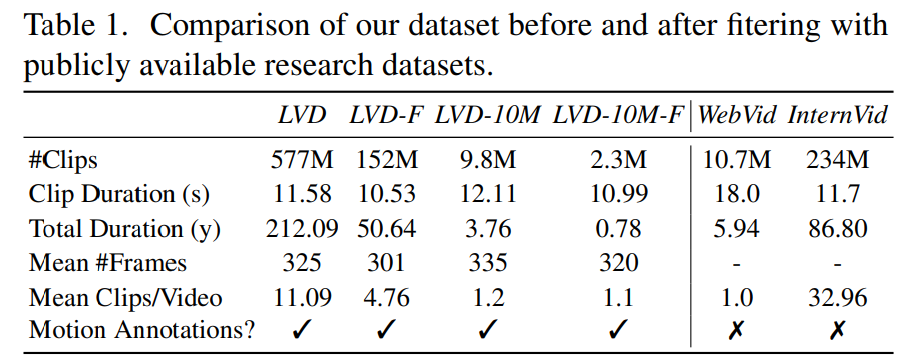
Fasa 2: Kumpulan data pra-latihan video. Artikel ini bergantung pada pilihan manusia sebagai isyarat untuk mencipta set data pra-latihan yang sesuai. Set data yang dibuat dalam artikel ini ialah LVD (Set Data Video Besar), yang terdiri daripada 580M pasang klip video beranotasi.
Siasatan lanjut mendedahkan bahawa set data yang dijana mengandungi beberapa contoh yang mungkin merendahkan prestasi model video akhir. Oleh itu, dalam artikel ini kami menggunakan aliran optik padat untuk menganotasi set data
Denda berkualiti tinggi -tala . Untuk menganalisis kesan pra-latihan video pada peringkat akhir, kertas kerja ini memperhalusi tiga model yang berbeza hanya dalam pemulaan. Rajah 4e menunjukkan keputusan.

Atas ialah kandungan terperinci Penyebaran Video Stabil ada di sini, berat kod dalam talian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!