
Rumah >Peranti teknologi >AI >Kedudukan kadar halusinasi model besar: GPT-4 adalah yang paling rendah pada 3% dan Google Palm adalah setinggi 27.2%
Kedudukan kadar halusinasi model besar: GPT-4 adalah yang paling rendah pada 3% dan Google Palm adalah setinggi 27.2%

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-11-14 20:33:071098semak imbas
Perkembangan kecerdasan buatan sedang berkembang pesat, tetapi masalah kerap berlaku. API penglihatan GPT baharu OpenAI sangat mengagumkan untuk bahagian hadapannya, tetapi ia juga sukar untuk dirungut kerana masalah halusinasinya.
Ilusi sentiasa menjadi kecacatan maut bagi model besar. Disebabkan oleh kerumitan set data, tidak dapat dielakkan bahawa akan terdapat maklumat yang lapuk dan salah, menyebabkan kualiti output menghadapi cabaran yang teruk. Terlalu banyak maklumat berulang juga boleh berat sebelah model besar, yang juga merupakan sejenis ilusi. Tetapi halusinasi bukanlah dalil yang tidak boleh dijawab. Semasa proses pembangunan, penggunaan set data yang teliti, penapisan yang ketat, pembinaan set data berkualiti tinggi, dan pengoptimuman struktur model dan kaedah latihan boleh mengurangkan masalah halusinasi pada tahap tertentu.
Terdapat banyak model berskala besar yang popular, sejauh manakah keberkesanannya dalam mengurangkan halusinasi? Berikut ialah kedudukan yang jelas membandingkan perbezaan mereka
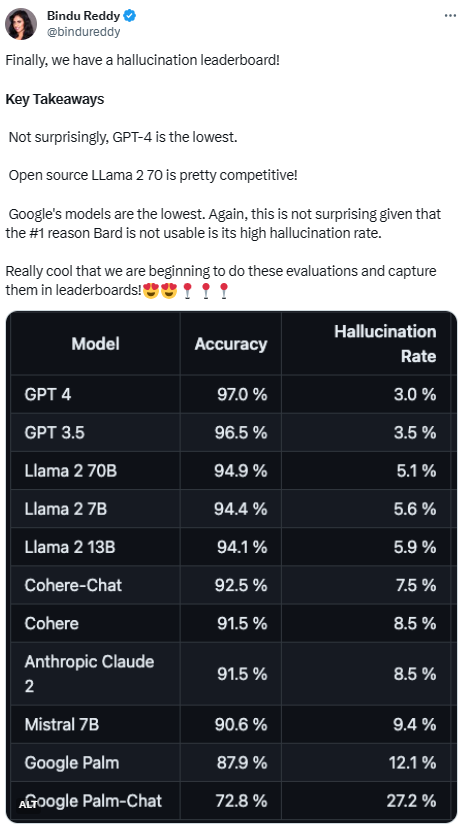
Platform Vectara mengeluarkan ranking ini, yang memfokuskan pada kecerdasan buatan. Tarikh kemas kini ranking ialah 1 November 2023. Vectara menyatakan bahawa mereka akan terus membuat susulan terhadap penilaian halusinasi untuk mengemas kini kedudukan semasa model dikemas kini
Alamat projek: https://github.com /vectara /halusinasi-papan pendahulu
Untuk menentukan papan pendahulu ini, Vectara menjalankan kajian konsistensi fakta dan melatih model untuk mengesan halusinasi dalam output LLM. Mereka menggunakan model SOTA yang setanding dan menyediakan setiap LLM dengan 1,000 dokumen ringkas melalui API awam dan meminta mereka meringkaskan setiap dokumen menggunakan hanya fakta yang dibentangkan dalam dokumen itu. Antara 1000 dokumen ini, hanya 831 dokumen telah diringkaskan oleh setiap model, dan dokumen selebihnya telah ditolak oleh sekurang-kurangnya satu model kerana sekatan kandungan. Menggunakan 831 dokumen ini, Vectara mengira ketepatan keseluruhan dan kadar ilusi untuk setiap model. Kadar di mana setiap model enggan membalas gesaan diperincikan dalam lajur "Kadar Jawapan". Tiada kandungan yang dihantar kepada model mengandungi kandungan yang menyalahi undang-undang atau tidak selamat, tetapi mengandungi perkataan pencetus yang mencukupi untuk mencetuskan penapis kandungan tertentu. Dokumen ini terutamanya daripada CNN/Daily Mail corpus
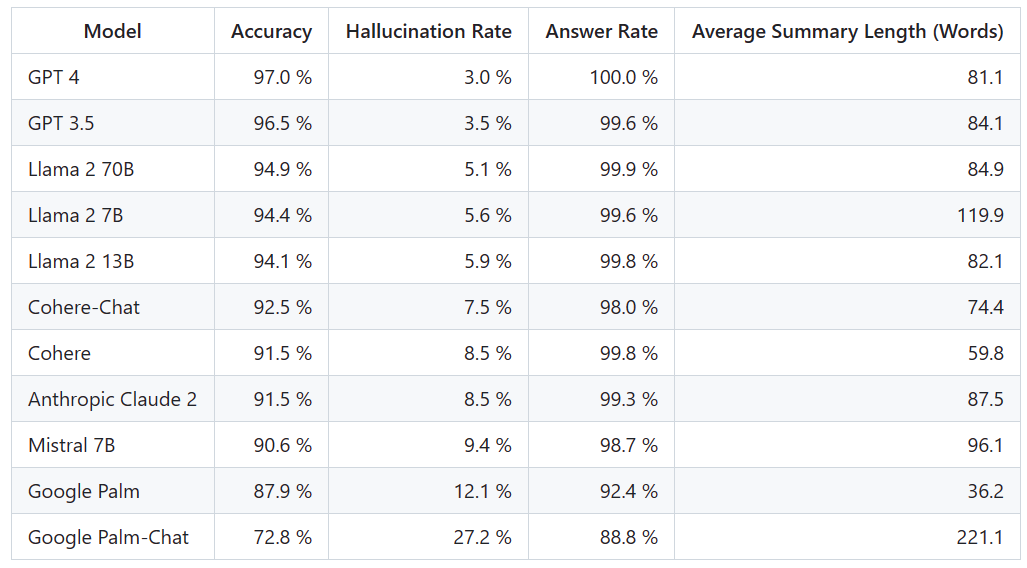
Adalah penting untuk ambil perhatian bahawa Vectara menilai ketepatan ringkasan, bukan ketepatan fakta keseluruhan. Ini membolehkan perbandingan tindak balas model terhadap maklumat yang diberikan. Dalam erti kata lain, apa yang dinilai ialah sama ada ringkasan output adalah "selaras dengan fakta" dengan dokumen sumber. Tanpa mengetahui data apa yang setiap LLM dilatih, menentukan halusinasi adalah mustahil untuk sebarang masalah tertentu. Tambahan pula, membina model yang boleh menentukan sama ada tindak balas adalah halusinasi tanpa sumber rujukan memerlukan menangani masalah halusinasi, dan memerlukan latihan model yang sama besar atau lebih besar daripada LLM yang dinilai. Oleh itu, Vectara memilih untuk melihat kadar halusinasi dalam tugasan ringkasan kerana analogi sedemikian adalah cara yang baik untuk menentukan realisme keseluruhan model.
Alamat pengesanan model halusinasi ialah: https://huggingface.co/vectara/hallucination_evaluation_model
Selain itu, semakin banyak LLM digunakan dalam saluran paip RAG (Retrieval Augmented Generation) untuk menjawab pertanyaan seperti Bing Chat dan integrasi Google Chat. Dalam sistem RAG, model ini digunakan sebagai agregator hasil carian, jadi papan pendahulu ini juga merupakan penunjuk yang baik bagi ketepatan model apabila digunakan dalam sistem RAG
Memandangkan prestasi GPT-4, ilusinya Kadar terendah nampaknya tidak mengejutkan. Namun, ada netizen berkata terkejut kerana tidak banyak perbezaan antara GPT-3.5 dan GPT-4

Selepas mengejar GPT-4 dan GPT-3.5, LLaMA 2 beraksi dengan baik. Walau bagaimanapun, prestasi model besar Google adalah tidak memuaskan. Sesetengah netizen berkata bahawa BARD Google sering menggunakan "Saya masih berlatih" untuk mengelakkan jawapan yang salah

Dengan senarai kedudukan sedemikian, kita boleh mempunyai pemahaman yang lebih intuitif tentang kelebihan dan kekurangan model yang berbeza . Beberapa hari lalu, OpenAI melancarkan GPT-4 Turbo Tidak, beberapa netizen segera mencadangkan untuk mengemas kini dalam ranking.

Kami akan tunggu dan lihat bagaimana kedudukan seterusnya dan sama ada akan berlaku sebarang perubahan besar.
Atas ialah kandungan terperinci Kedudukan kadar halusinasi model besar: GPT-4 adalah yang paling rendah pada 3% dan Google Palm adalah setinggi 27.2%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!