
Rumah >Peranti teknologi >AI >Tajuk baharu: NVIDIA H200 dikeluarkan: Kapasiti HBM meningkat sebanyak 76%, cip AI paling berkuasa yang meningkatkan prestasi model besar sebanyak 90% dengan ketara
Tajuk baharu: NVIDIA H200 dikeluarkan: Kapasiti HBM meningkat sebanyak 76%, cip AI paling berkuasa yang meningkatkan prestasi model besar sebanyak 90% dengan ketara

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-11-14 15:21:131448semak imbas

Berita pada 14 November, Nvidia secara rasmi mengeluarkan GPU H200 baharu dan mengemas kini barisan produk GH200 pada persidangan "Supercomputing 23" pada pagi waktu tempatan ke-13
Antaranya, H200 masih dibina pada seni bina Hopper H100 yang sedia ada, tetapi menambah lebih banyak memori jalur lebar tinggi (HBM3e) untuk mengendalikan set data besar yang diperlukan dengan lebih baik untuk membangun dan melaksanakan kecerdasan buatan, yang membolehkan untuk menjalankan model besar Prestasi keseluruhan bertambah baik sebanyak 60% hingga 90% berbanding generasi sebelumnya H100. GH200 yang dikemas kini juga akan memberi kuasa kepada superkomputer AI generasi seterusnya. Lebih daripada 200 exaflop kuasa pengkomputeran AI akan tersedia dalam talian pada tahun 2024.
H200: Kapasiti HBM meningkat sebanyak 76%, prestasi model besar meningkat sebanyak 90%
Secara khusus, H200 baharu menawarkan sehingga 141GB memori HBM3e, berjalan dengan berkesan pada kira-kira 6.25 Gbps, untuk jumlah lebar jalur 4.8 TB/s setiap GPU dalam enam tindanan HBM3e. Ini adalah peningkatan yang besar berbanding dengan H100 generasi sebelumnya (dengan lebar jalur 80GB HBM3 dan 3.35 TB/s), dengan peningkatan lebih daripada 76% dalam kapasiti HBM. Menurut data rasmi, apabila menjalankan model besar, H200 akan membawa peningkatan sebanyak 60% (GPT3 175B) kepada 90% (Llama 2 70B) berbanding H100


Walaupun beberapa konfigurasi H100 menawarkan lebih banyak memori, seperti H100 NVL yang menggandingkan kedua-dua papan dan menawarkan sejumlah 188GB memori (94GB setiap GPU), walaupun berbanding dengan varian H100 SXM, H200 SXM baharu Ia juga menyediakan 76% lebih kapasiti memori dan 43% lebih lebar jalur.
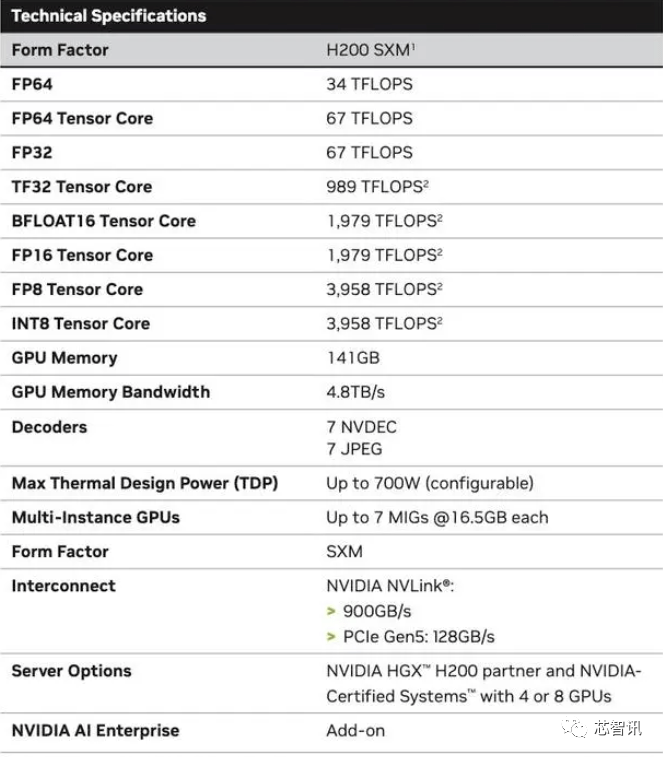
Perlu diingatkan bahawa prestasi pengkomputeran mentah H200 nampaknya tidak banyak berubah. Satu-satunya slaid Nvidia menunjukkan bahawa prestasi pengiraan yang dicerminkan adalah berdasarkan konfigurasi HGX 200 menggunakan lapan GPU, dengan jumlah prestasi "32 PFLOPS FP8." Walaupun H100 asal menyediakan 3,958 teraflop kuasa pengkomputeran FP8, lapan GPU sedemikian juga menyediakan kira-kira 32 PFLOPS kuasa pengkomputeran FP8
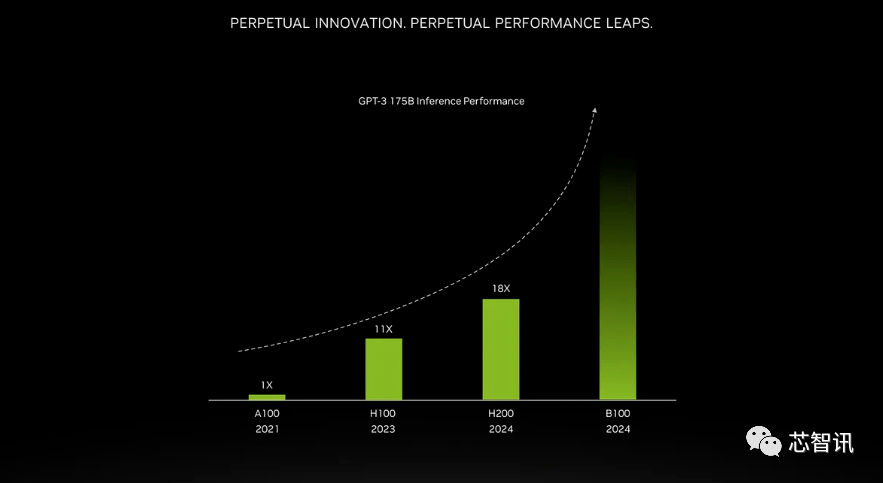
Peningkatan yang dibawa oleh memori lebar jalur yang lebih tinggi bergantung pada beban kerja. Model besar (seperti GPT-3) akan mendapat banyak manfaat daripada peningkatan kapasiti memori HBM. Menurut Nvidia, H200 akan berprestasi sehingga 18 kali lebih baik daripada A100 asal dan kira-kira 11 kali lebih pantas daripada H100 apabila menjalankan GPT-3. Selain itu, teaser untuk Blackwell B100 akan datang menunjukkan bahawa ia mengandungi bar yang lebih tinggi yang pudar kepada hitam, kira-kira dua kali lebih panjang daripada H200 paling tepat
Bukan itu sahaja, H200 dan H100 serasi antara satu sama lain. Dalam erti kata lain, syarikat AI yang menggunakan model latihan/inferens H100 boleh bertukar dengan lancar kepada cip H200 terkini. Pembekal perkhidmatan awan tidak perlu membuat sebarang pengubahsuaian apabila menambahkan H200 pada portfolio produk mereka.
Nvidia berkata dengan melancarkan produk baharu, mereka berharap dapat mengikuti pertumbuhan dalam saiz set data yang digunakan untuk mencipta model dan perkhidmatan kecerdasan buatan. Keupayaan memori yang dipertingkatkan akan menjadikan H200 lebih pantas dalam proses menyalurkan data kepada perisian, satu proses yang membantu melatih kecerdasan buatan untuk melaksanakan tugas seperti mengecam imej dan pertuturan.
“Menyepadukan memori HBM berkapasiti lebih pantas membantu meningkatkan prestasi untuk tugasan yang menuntut secara pengiraan, termasuk model AI generatif dan aplikasi pengkomputeran berprestasi tinggi, sambil mengoptimumkan penggunaan dan kecekapan GPU NVIDIA High Performance Computing kata Ian Buck, Naib Presiden Produk.
Dion Harris, ketua produk pusat data di NVIDIA, berkata: “Apabila anda melihat arah aliran dalam pembangunan pasaran, saiz model meningkat dengan pesat Ini adalah contoh bagaimana kami terus memperkenalkan teknologi terkini dan terhebat ”
Pengeluar komputer kerangka utama dan penyedia perkhidmatan awan dijangka mula menggunakan H200 pada suku kedua 2024. Rakan kongsi pembuatan pelayan NVIDIA (termasuk Evergreen, ASUS, Dell, Eviden, Gigabyte, HPE, Hongbai, Lenovo, Wenda, MetaVision, Wistron dan Wiwing) boleh menggunakan H200 untuk mengemas kini sistem sedia ada, manakala Amazon , Google, Microsoft, Oracle, dsb. akan menjadi penyedia perkhidmatan awan pertama yang mengguna pakai H200.
Memandangkan permintaan pasaran semasa yang kukuh untuk cip NVIDIA AI, dan H200 baharu menambah memori HBM3e yang lebih mahal, harga H200 pasti akan menjadi lebih mahal. Nvidia tidak menyenaraikan harga, tetapi H100 generasi sebelumnya berharga $25,000 hingga $40,000.
Jurucakap NVIDIA Kristin Uchiyama berkata bahawa harga akhir akan ditentukan oleh rakan kongsi pembuatan NVIDIA
Mengenai sama ada pelancaran H200 akan menjejaskan pengeluaran H100, Kristin Uchiyama berkata: "Kami menjangkakan jumlah bekalan sepanjang tahun akan meningkat
Cip AI mewah Nvidia sentiasa dianggap sebagai pilihan terbaik untuk memproses sejumlah besar data dan melatih model bahasa besar serta alatan penjanaan AI. Walau bagaimanapun, apabila cip H200 dilancarkan, syarikat AI masih terdesak mencari cip A100/H100 di pasaran. Tumpuan pasaran kekal sama ada Nvidia boleh menyediakan bekalan yang mencukupi untuk memenuhi permintaan pasaran. Oleh itu, NVIDIA tidak memberikan jawapan sama ada cip H200 akan kekurangan bekalan seperti cip H100
Namun, tahun depan mungkin tempoh yang lebih baik untuk pembeli GPU Menurut laporan dalam Financial Times pada bulan Ogos, NVIDIA merancang untuk menggandakan pengeluaran H100 pada tahun 2024, dan sasaran pengeluaran akan meningkat daripada kira-kira 500,000 pada tahun 2023. akan meningkat kepada. 2 juta pada 2024. Tetapi AI generatif masih berkembang pesat, dan permintaan mungkin lebih besar pada masa hadapan.
Sebagai contoh, GPT-4 yang baru dilancarkan dilatih pada kira-kira 10,000-25,000 blok A100. Model AI besar Meta memerlukan kira-kira 21,000 blok A100 untuk latihan. AI kestabilan menggunakan kira-kira 5,000 A100. Latihan Falcon-40B memerlukan 384 A100
Menurut Musk, GPT-5 mungkin memerlukan 30,000-50,000 H100. Petikan Morgan Stanley ialah 25,000 GPU.
Sam Altman menafikan latihan GPT-5, tetapi menyebut bahawa "OpenAI mengalami kekurangan GPU yang serius, dan semakin sedikit orang yang menggunakan produk kami, semakin baik."
Sudah tentu, selain NVIDIA, AMD dan Intel juga sedang giat memasuki pasaran AI untuk bersaing dengan NVIDIA. MI300X yang sebelum ini dilancarkan oleh AMD dilengkapi dengan lebar jalur memori 192GB HBM3 dan 5.2TB/s, yang akan menjadikannya jauh melebihi H200 dari segi kapasiti dan lebar jalur.
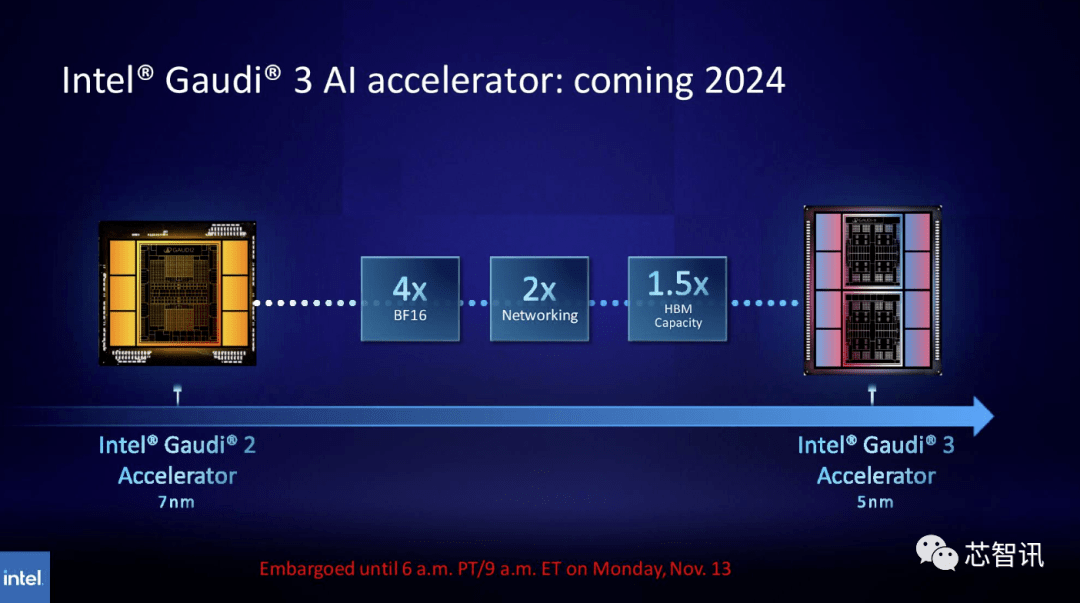
Begitu juga, Intel merancang untuk meningkatkan kapasiti HBM cip Gaudi AI. Menurut maklumat terkini yang dikeluarkan, Gaudi 3 menggunakan proses 5nm, dan prestasinya dalam beban kerja BF16 akan menjadi empat kali ganda daripada Gaudi 2, dan prestasi rangkaiannya juga akan dua kali ganda daripada Gaudi 2 (Gaudi 2 mempunyai 24 terbina dalam 100 GbE RoCE NICs ). Selain itu, Gaudi 3 mempunyai 1.5 kali ganda kapasiti HBM Gaudi 2 (Gaudi 2 mempunyai 96 GB HBM2E). Seperti yang dapat dilihat daripada gambar di bawah, Gaudi 3 menggunakan reka bentuk berasaskan chiplet dengan dua kelompok pengkomputeran, tidak seperti Gaudi 2 yang menggunakan penyelesaian cip tunggal Intel
Cip super GH200 baharu: menjana tenaga superkomputer AI generasi seterusnya
Selain mengeluarkan GPU H200 baharu, NVIDIA turut melancarkan versi cip super GH200 yang dinaik taraf. Cip ini menggunakan teknologi sambung cip NVIDIA NVLink-C2C, menggabungkan GPU H200 terkini dan CPU Grace (tidak pasti sama ada ia adalah versi yang dinaik taraf). Setiap cip super GH200 juga akan membawa sejumlah 624GB memori

Sebagai perbandingan, GH200 generasi sebelumnya adalah berdasarkan GPU H100 dan CPU Grace 72-teras, menyediakan 96GB HBM3 dan 512 GB LPDDR5X bersepadu dalam pakej yang sama.
Walaupun NVIDIA tidak memperkenalkan butiran CPU Grace dalam cip super GH200, NVIDIA memberikan beberapa perbandingan antara GH200 dan "CPU x86 dwi-soket moden". Dapat dilihat bahawa GH200 telah membawa peningkatan 8 kali ganda dalam prestasi ICON, dan MILC, Quantum Fourier Transform, RAG LLM Inference, dll. telah membawa berpuluh-puluh atau bahkan ratusan kali peningkatan.
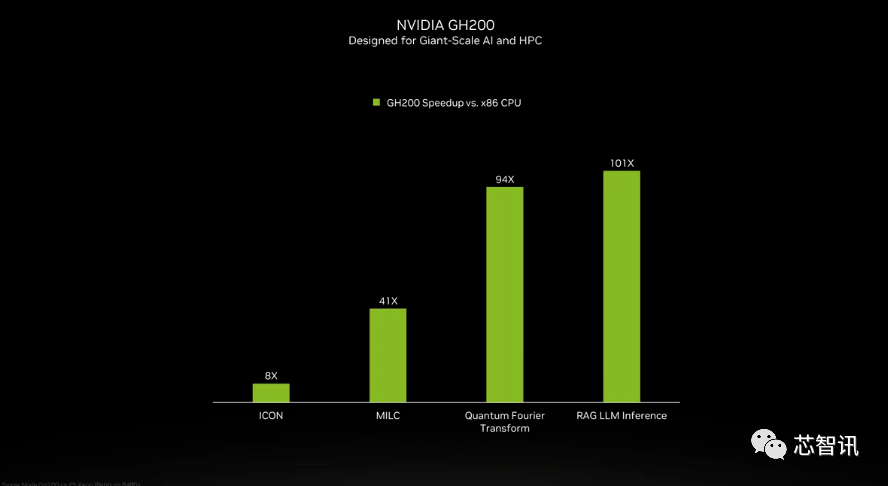
Tetapi perlu diingatkan bahawa dipercepatkan dan "sistem tidak dipercepatkan" disebut. apa maksudnya? Kami hanya boleh menganggap bahawa pelayan x86 menjalankan kod yang tidak dioptimumkan sepenuhnya, terutamanya memandangkan dunia kecerdasan buatan berkembang pesat dan kemajuan baharu dalam pengoptimuman nampaknya muncul secara tetap.
GH200 baharu juga akan digunakan dalam sistem HGX H200 baharu. Ini dikatakan "serasi dengan lancar" dengan sistem HGX H100 sedia ada, bermakna HGX H200 boleh digunakan dalam pemasangan yang sama untuk meningkatkan prestasi dan kapasiti memori tanpa perlu mereka bentuk semula infrastruktur.
Menurut laporan, superkomputer Alpine Pusat Pengkomputeran Kebangsaan Switzerland mungkin merupakan salah satu kumpulan pertama superkomputer Grace Hopper berasaskan GH100 yang mula digunakan tahun depan. Sistem GH200 pertama yang memasuki perkhidmatan di Amerika Syarikat ialah superkomputer Venado di Los Alamos National Laboratory. Sistem Vista Texas Advanced Computing Center (TACC) juga akan menggunakan cip besar Grace CPU dan Grace Hopper yang baru diumumkan, tetapi tidak jelas sama ada ia akan berasaskan H100 atau H200

Pada masa ini, superkomputer terbesar yang akan dipasang ialah superkomputer Jupiter di Pusat Pengkomputeran Besar Jϋlich. Ia akan menempatkan "hampir" 24,000 supercip GH200, berjumlah 93 exaflops pengkomputeran AI (mungkin menggunakan FP8, walaupun kebanyakan AI masih menggunakan BF16 atau FP16). Ia juga akan menyampaikan 1 exaflop pengkomputeran FP64 tradisional. Ia akan menggunakan papan "Quad GH200" dengan empat cip super GH200.
Superkomputer baharu ini yang dijangka dipasang oleh Nvidia pada tahun hadapan atau lebih akan, secara kolektif, mencapai lebih daripada 200 exaflop kuasa pengkomputeran kecerdasan buatan
Jika maksud asal tidak perlu diubah, isinya perlu ditulis semula ke dalam bahasa Cina, dan ayat asal tidak perlu muncul
Atas ialah kandungan terperinci Tajuk baharu: NVIDIA H200 dikeluarkan: Kapasiti HBM meningkat sebanyak 76%, cip AI paling berkuasa yang meningkatkan prestasi model besar sebanyak 90% dengan ketara. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 小程序:使用 wx:key 提升 wx:for 的渲染效率
- 程序员工作以后该如何提升?
- Apakah php-fpm? Bagaimana untuk mengoptimumkan untuk meningkatkan prestasi?
- Kejayaan besar, diumumkan oleh Akademi Sains China! 1.5 hingga 10 kali lebih pantas daripada Nvidia, adakah cip AI akan mengubah dunia? Had harian lurus pemimpin konsep
- IBM mempertimbangkan untuk menggunakan cip AInya sendiri dalam perkhidmatan awan baharu [Dengan analisis prospek pembangunan cip AI global]