
Rumah >Peranti teknologi >AI >Mari kita bercakap tentang pengekstrakan pengetahuan Adakah anda telah mempelajarinya?
Mari kita bercakap tentang pengekstrakan pengetahuan Adakah anda telah mempelajarinya?

- PHPzke hadapan
- 2023-11-13 20:13:02791semak imbas
1. Pengenalan
Pengestrakan pengetahuan biasanya merujuk kepada perlombongan maklumat berstruktur daripada teks tidak berstruktur, seperti tag dan frasa yang mengandungi maklumat semantik yang kaya. Ini digunakan secara meluas dalam senario seperti pemahaman kandungan dan pemahaman produk dalam industri Dengan mengekstrak tag berharga daripada maklumat teks yang dijana pengguna, ia digunakan pada kandungan atau produk
Pengestrakan pengetahuan biasanya disertai dengan pengekstrakan tag atau frasa yang diekstrak. Pengelasan biasanya dimodelkan sebagai tugas pengecaman entiti bernama Tugas pengecaman entiti bernama biasa adalah untuk mengenal pasti komponen entiti yang dinamakan dan mengelaskan komponen ke dalam nama tempat, nama orang, nama organisasi, dll perkataan terbahagi kepada kategori yang disesuaikan dengan medan, seperti siri (Air Force One, Sonic 9), jenama (Nike, Li Ning), jenis (kasut, pakaian, digital), gaya (gaya INS, gaya retro, gaya Nordic), dll.
Untuk kemudahan penerangan, tag atau frasa yang kaya maklumat akan secara kolektif dirujuk sebagai perkataan tag di bawah
2. Klasifikasi pengekstrakan pengetahuan
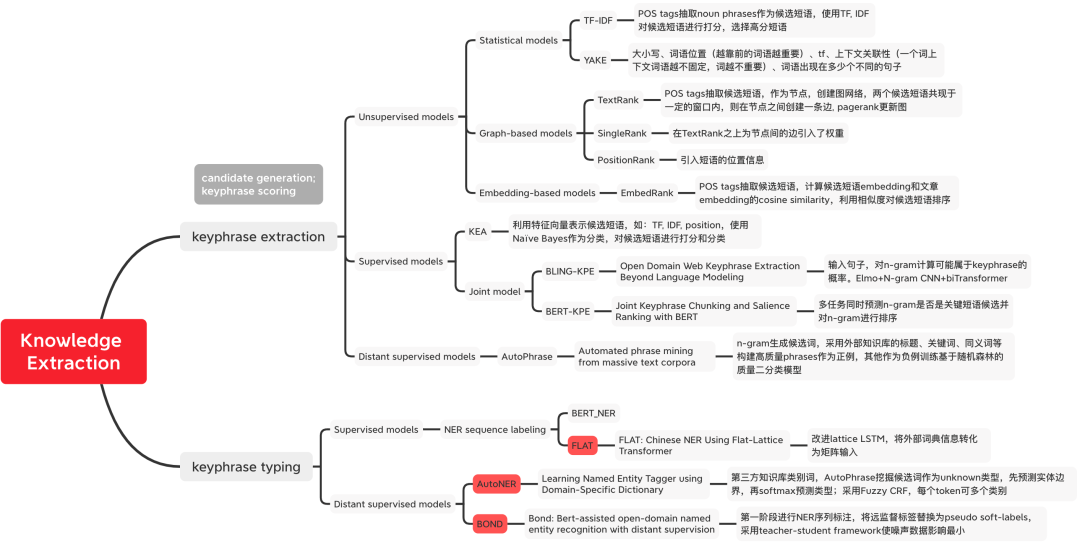 Figure 1 Klasifikasi Kaedah Pengekstrakan Pengetahuan
Figure 1 Klasifikasi Kaedah Pengekstrakan Pengetahuan
3. Tag Word Mining
Unsupervised Method
Statistics berasaskan Kaedah
- TF-IDF (Kekerapan Jangka-Kekerapan Dokumen Songsang): Kira skor TF-IDF setiap perkataan Semakin tinggi skor, semakin besar jumlah maklumat yang terkandung.
Kandungan yang ditulis semula: Kaedah pengiraan: tfidf(t, d, D) = tf(t, d) * idf(t, D), dengan tf(t, d) = log(1 + freq(t) , d )), freq(t,d) mewakili bilangan kali perkataan calon t muncul dalam dokumen semasa d, idf(t,D) = log(N/count(d∈D:t∈D)) mewakili perkataan calon t Dalam berapa banyak dokumen ia digunakan untuk menunjukkan kelangkaan sesuatu perkataan Jika perkataan hanya muncul dalam satu dokumen, ini bermakna perkataan itu jarang dan mempunyai maklumat yang lebih kaya Dalam senario perniagaan tertentu, alat luaran boleh digunakan untuk menganalisis perkataan calon Mula-mula menjalankan satu pusingan saringan, seperti menggunakan penanda sebahagian daripada pertuturan untuk menapis kata nama.
YAKE[1]: Lima ciri ditakrifkan untuk menangkap ciri kata kunci, yang digabungkan secara heuristik untuk memberikan markah kepada setiap kata kunci. Semakin rendah skor, semakin penting kata kunci itu. 1) Huruf besar: Istilah dalam huruf besar (kecuali perkataan permulaan setiap ayat) adalah lebih penting daripada Istilah dalam huruf kecil, sepadan dengan bilangan perkataan tebal dalam bahasa Cina 2) Kedudukan perkataan: setiap perenggan teks Beberapa perkataan di permulaan adalah lebih penting daripada perkataan berikutnya; berlaku, semakin rendah kepentingan perkataan; 5) Bilangan kali perkataan muncul dalam ayat yang berbeza, perkataan muncul dalam lebih banyak ayat, semakin penting ia.Model Berasaskan Grafik
TextRank[2]: Mula-mula lakukan pembahagian perkataan dan penandaan sebahagian daripada pertuturan pada teks, dan tapis kata henti, hanya tinggalkan perkataan dengan bahagian-speech yang ditentukan untuk membina graf. Setiap nod ialah perkataan, dan tepi mewakili hubungan antara perkataan, yang dibina dengan mentakrifkan kejadian bersama perkataan dalam tetingkap bergerak dengan saiz yang telah ditetapkan. Gunakan PageRank untuk mengemas kini berat nod sehingga penumpuan; mengisih pemberat nod dalam susunan terbalik untuk mendapatkan kata kunci yang paling penting sebagai kata kunci calon, dan jika ia membentuk frasa bersebelahan, gabungkan mereka menjadi berbilang Kata Kunci frasa untuk frasa. .- EmbedRank[3]: Pilih perkataan calon melalui pembahagian perkataan dan penandaan sebahagian daripada pertuturan, gunakan Doc2Vec dan Sent2vec yang telah terlatih sebagai perwakilan vektor bagi perkataan dan dokumen calon, dan hitung persamaan kosinus kepada kata kedudukan calon. Begitu juga, KeyBERT[4] menggantikan perwakilan vektor EmbedRank dengan BERT.
- Perkataan calon skrin pertama dan kemudian gunakan pengelasan perkataan tag: model klasik KEA[5] menggunakan Naive Bayes sebagai pengelas untuk menjaringkan perkataan calon N-gram pada empat ciri yang direka bentuk.
- Latihan bersama saringan kata calon dan pengecaman perkataan label: BLING-KPE[6] mengambil ayat asal sebagai input, menggunakan CNN dan Transformer untuk mengekod frasa N-gram ayat tersebut dan mengira sama ada frasa ialah label Kebarangkalian perkataan, sama ada perkataan label, dilabel secara manual Label. BERT-KPE[7] Berdasarkan idea BLING-KPE, ELMO digantikan dengan BERT untuk mewakili vektor ayat dengan lebih baik.
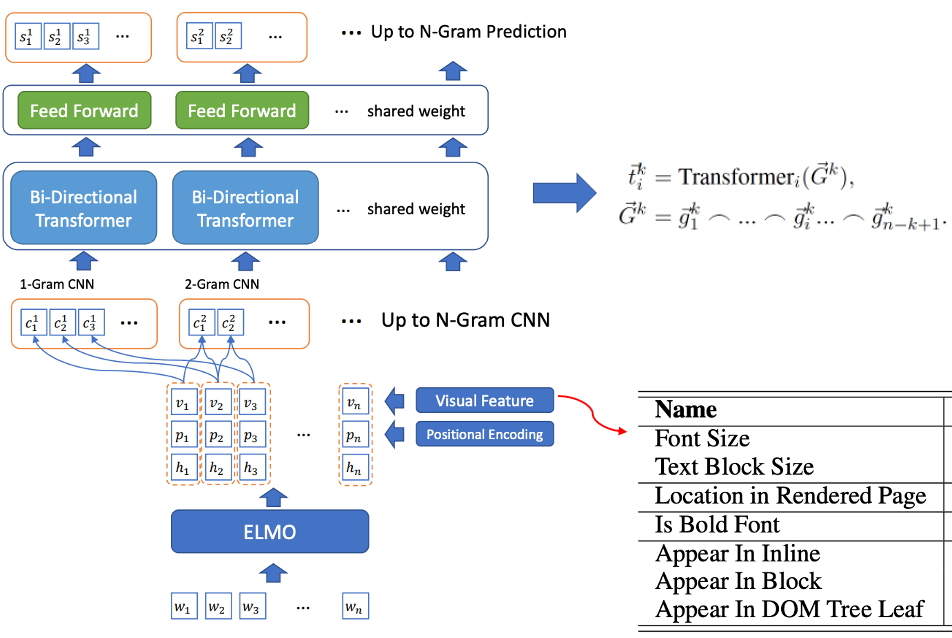 Rajah 2 Struktur model BLING-KPE
Rajah 2 Struktur model BLING-KPE
#🎜#
#🎜##🎜🎜🎜🎜 # Kaedah Pengawasan Jauh
AutoFrasa
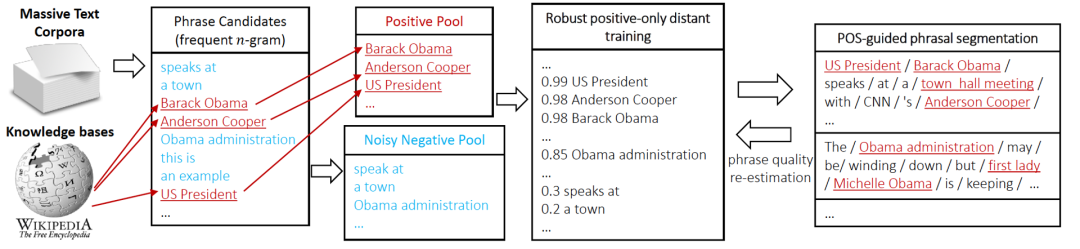
#🎜 seliaan kaedah Wakilnya ialah AutoFrasa [10], yang digunakan secara meluas dalam perlombongan perkataan tag dalam industri. AutoFrasa menggunakan pangkalan pengetahuan berkualiti tinggi sedia ada untuk menjalankan latihan penyeliaan jauh untuk mengelakkan anotasi manual. Dalam artikel ini, kami mentakrifkan frasa berkualiti tinggi sebagai perkataan dengan semantik lengkap, apabila empat syarat berikut dipenuhi pada masa yang samaPopularit: Kekerapan kejadian dalam dokumen adalah cukup tinggi; #
Bermaklumat: Terdapat maklumat Kuantiti, penunjuk yang jelas, seperti "ini" adalah contoh negatif tanpa maklumat- Kelengkapan: Frasa dan subfrasanya mesti mempunyai kesempurnaan.
- #🎜🎜 #Proses perlombongan tag AutoFrasa ditunjukkan dalam Rajah 3. Pertama, kami menggunakan penandaan sebahagian daripada pertuturan untuk menapis perkataan N-gram frekuensi tinggi sebagai calon. Kemudian, kami mengklasifikasikan perkataan calon melalui pengawasan jauh. Akhir sekali, kami menggunakan empat syarat di atas untuk menapis frasa berkualiti tinggi (anggaran semula kualiti frasa)
- Rajah 3 Proses perlombongan teg AutoFrasa #🎜 🎜#
 Rajah 4 Kaedah pengelasan kata teg AutoFrasa
Rajah 4 Kaedah pengelasan kata teg AutoFrasa
#🎜 🎜#
kaedah diselia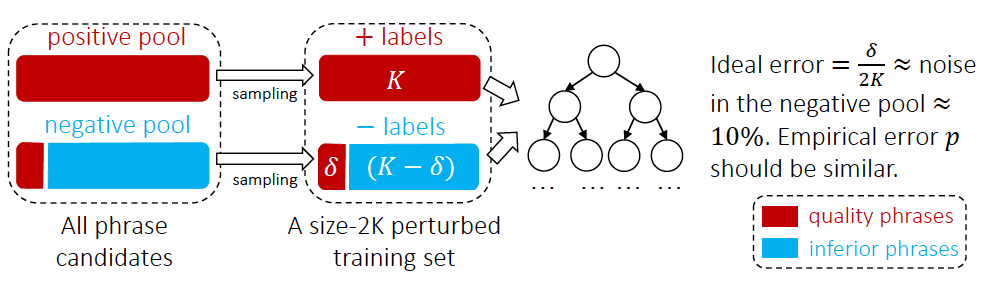
Model anotasi jujukan NER
Lattice LSTM[8] ialah kerja pertama untuk memperkenalkan maklumat perbendaharaan kata untuk tugasan NER Bahasa Cina ialah graf akiklik berarah Huruf permulaan dan akhir perbendaharaan kata apabila memadankan ayat melalui maklumat perbendaharaan kata. , struktur seperti kekisi boleh diperolehi, seperti yang ditunjukkan dalam Rajah 5(a). Struktur LSTM Lattice menggabungkan maklumat perbendaharaan kata ke dalam LSTM asli, seperti yang ditunjukkan dalam 5(b) Untuk aksara semasa, semua maklumat kamus luaran yang berakhir dengan aksara itu sebagai contoh, "kedai" menggabungkan "orang dan kedai ubat". Maklumat "Farmasi". Untuk setiap aksara, Lattice LSTM menggunakan mekanisme perhatian untuk menggabungkan bilangan unit perkataan yang berubah-ubah. Walaupun Lattice-LSTM meningkatkan prestasi tugas NER secara berkesan, struktur RNN tidak dapat menangkap kebergantungan jarak jauh, dan memperkenalkan maklumat leksikal adalah lossy Pada masa yang sama, struktur Lattice dinamik tidak dapat melaksanakan model GPU The Flat[9] sepenuhnya telah menambah baik kedua-dua soalan ini dengan berkesan. Seperti yang ditunjukkan dalam Rajah 5(c), model Flat menangkap kebergantungan jarak jauh melalui struktur Transformer, dan mereka bentuk Pengekodan Kedudukan untuk menyepadukan struktur Lattice Selepas menyambung perkataan yang dipadankan dengan aksara ke dalam ayat, setiap aksara dan perkataan adalah Bina dua Pengekodan Kedudukan Kepala dan Pengekodan Kedudukan Ekor, ratakan struktur Kekisi daripada graf akiklik terarah kepada struktur Pengubah Kekisi Rata.
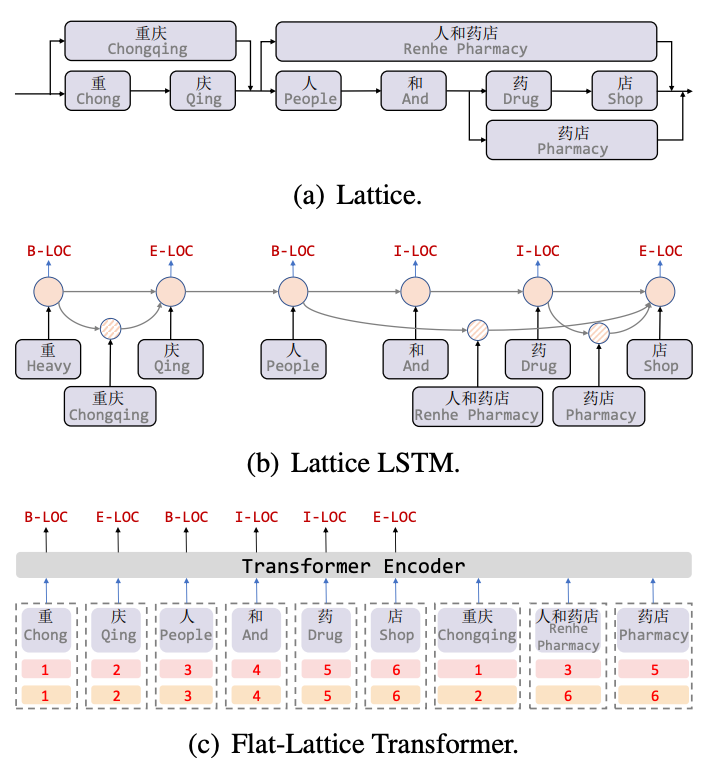 Figure 5 Model NER Memperkenalkan Maklumat Perbendaharaan Kata
Figure 5 Model NER Memperkenalkan Maklumat Perbendaharaan Kata
far-Supervised Method
Autoner
Untuk menyelesaikan masalah bunyi dalam pengawasan jauh, kami menggunakan skema pengenalan sempadan entiti Tie atau Break untuk menggantikan kaedah pelabelan BIOE. Antaranya, Tie bermaksud perkataan semasa dan perkataan sebelumnya tergolong dalam entiti yang sama, dan Break bermaksud perkataan semasa dan perkataan sebelumnya tidak lagi berada dalam entiti yang sama Dalam peringkat pengelasan entiti, Fuzzy CRF digunakan untuk berurusan dengan pelbagai ciri sesuatu entiti. Pelbagai jenis situasi
Rajah 6 Gambar rajah struktur model AutoNER 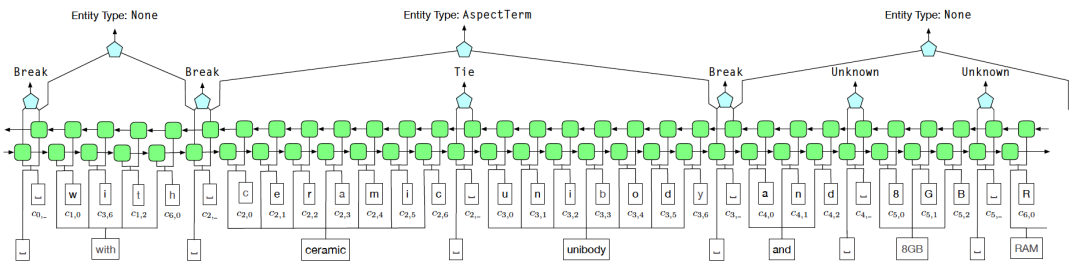
BOND
BOND [12] ialah pembelajaran berasaskan model dua peringkat pengecaman jauh. Pada peringkat pertama, label jarak jauh digunakan untuk menyesuaikan model bahasa pra-latihan kepada tugas NER pada peringkat kedua, model Pelajar dan model Guru mula-mula dimulakan dengan model yang dilatih dalam Peringkat 1, dan kemudian pseudo; -label yang dijana oleh model Guru digunakan untuk menggandingkan model Pelajar Menjalankan latihan untuk meminimumkan kesan masalah bunyi yang disebabkan oleh penyeliaan jauh.
Gambar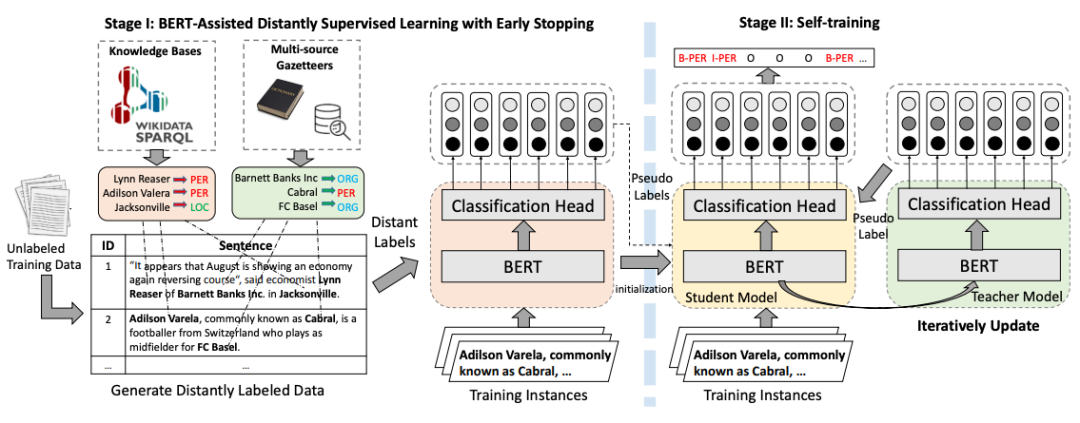 Kandungan yang perlu ditulis semula ialah: Rajah 7 Carta aliran latihan BOND
Kandungan yang perlu ditulis semula ialah: Rajah 7 Carta aliran latihan BOND
V. Artikel ini memperkenalkan kaedah klasik pengekstrakan pengetahuan daripada dua perspektif perkataan dan tag perkataan klasifikasi, termasuk Kaedah klasik TF-IDF dan TextRank yang tidak diselia dan diselia jauh yang bergantung pada data beranotasi manual, AutoFrasa, AutoNER, dsb., yang digunakan secara meluas dalam industri, boleh memberikan rujukan untuk pemahaman kandungan industri, pembinaan kamus dan NER untuk pemahaman pertanyaan.
Rujukan
【2】Mihalcea R, Tarau P. Textrank: Membawa susunan ke dalam teks[C]//Prosiding persidangan 2004 mengenai kaedah empirikal dalam pemprosesan bahasa semula jadi 2004: 404-411.
#🎜🎜🎜. #【3】Bennani-Smires K, Musat C, Hossmann A, et al. Pengekstrakan frasa kunci tanpa pengawasan yang mudah menggunakan benam ayat [J]. https://github.com/MaartenGr/KeyBERT【5】Witten I H, Paynter G W, Frank E, et al: Pengekstrakan frasa kunci automatik praktikal[C]//Prosiding ACM keempat persidangan mengenai perpustakaan Digital 1999: 254-255. Kandungan terjemahan: [6] Xiong L, Hu C, Xiong C, et al. Pengekstrakan kata kunci Web domain terbuka melangkaui model bahasa[J]. arXiv pracetak arXiv:1911.02671, 2019 【7】Sun, S., Xiong, C., Liu, Z., Liu, Z., & Bao, J. (2020 Joint Keyphrase Chunking). dan Kedudukan Salience dengan BERT arXiv pracetak arXiv:2004.13639.Kandungan yang perlu ditulis semula ialah: [8] Zhang Y, Yang J. Cina menamakan pengiktirafan entiti menggunakan kekisi LSTM[C]. ACL 2018【9】Li X, Yan H, Qiu X, et al: NER Cina menggunakan pengubah kekisi rata[C].#🎜#【. 10】Shang J, Liu J, Jiang M, et al. Perlombongan frasa automatik daripada korpora teks besar-besaran[J]. 🎜#【11】 Shang J, Liu L, Ren X, et al Pembelajaran dinamakan penanda entiti menggunakan kamus khusus domain[C].
【12】Liang C, Yu Y. , Jiang H, et al.: Pengiktirafan entiti dengan bantuan Bert dengan pengawasan jauh[C]//Prosiding persidangan antarabangsa ACM SIGKDD ke-26 tentang penemuan pengetahuan & perlombongan data 2020: 1054-1064.#🎜🎜 #
[13] Penerokaan dan amalan teknologi NER dalam Meituan Search, https://zhuanlan.zhihu.com/p/163256192Atas ialah kandungan terperinci Mari kita bercakap tentang pengekstrakan pengetahuan Adakah anda telah mempelajarinya?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!