
Rumah >Peranti teknologi >AI >Adakah model besar mengambil jalan pintas untuk 'menewaskan ranking'? Masalah pencemaran data wajar diberi perhatian
Adakah model besar mengambil jalan pintas untuk 'menewaskan ranking'? Masalah pencemaran data wajar diberi perhatian

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-11-09 14:25:111375semak imbas
Pada tahun pertama AI generatif, kadar kerja semua orang telah menjadi lebih pantas.
Terutama pada tahun ini, semua orang bekerja keras untuk melancarkan model besar: Baru-baru ini, syarikat gergasi teknologi dalam dan luar negara telah bergilir-gilir untuk melancarkan model besar sebaik sahaja sidang akhbar bermula, kesemuanya kejayaan besar, dan setiap satu menyegarkan senarai Penanda Aras yang penting, sama ada di kedudukan pertama atau di peringkat pertama.
Selepas teruja dengan kemajuan pesat teknologi, ramai orang mendapati seolah-olah ada sesuatu yang tidak kena: Mengapa semua orang mempunyai bahagian dalam ranking nombor satu? Apakah mekanisme ini?
Sejak itu, isu "list-swiping" juga mula menarik perhatian.
Baru-baru ini, kami mendapati semakin banyak perbincangan dalam WeChat Moments dan komuniti Zhihu mengenai isu "meleret kedudukan" model besar. Khususnya, siaran di Zhihu: Bagaimanakah anda menilai fenomena yang Laporan Teknikal Model Besar Tiangong menunjukkan bahawa banyak model besar menggunakan data dalam lapangan untuk meningkatkan kedudukan? Ia membangkitkan perbincangan semua orang.
Pautan: https://www.zhihu.com/question/628957425
Banyak mekanisme ranking model besar telah didedahkan pasukan penyelidik mengeluarkan laporan teknikal mengenai platform kertas pracetak arXiv pada akhir bulan lepas.
Pautan kertas: https://arxiv.org/abs/2310.19341
Makalah itu sendiri adalah pengenalan kepada Skywork-13B, model bahasa besar (LLM) siri Tiangong. Penulis memperkenalkan kaedah latihan dua peringkat menggunakan korpora tersegmentasi, masing-masing menyasarkan latihan am dan latihan dipertingkatkan khusus domain.
Seperti biasa dengan penyelidikan baharu ke atas model besar, penulis menyatakan bahawa pada penanda aras ujian popular, model mereka bukan sahaja berprestasi baik, tetapi juga mencapai tahap terkini (yang terbaik dalam industri) dalam banyak tugas cawangan Cina . baik).
Intinya ialah laporan itu juga mengesahkan kesan sebenar banyak model besar dan menunjukkan bahawa beberapa model domestik besar yang lain disyaki bersifat oportunistik. Ini ialah Jadual 8:
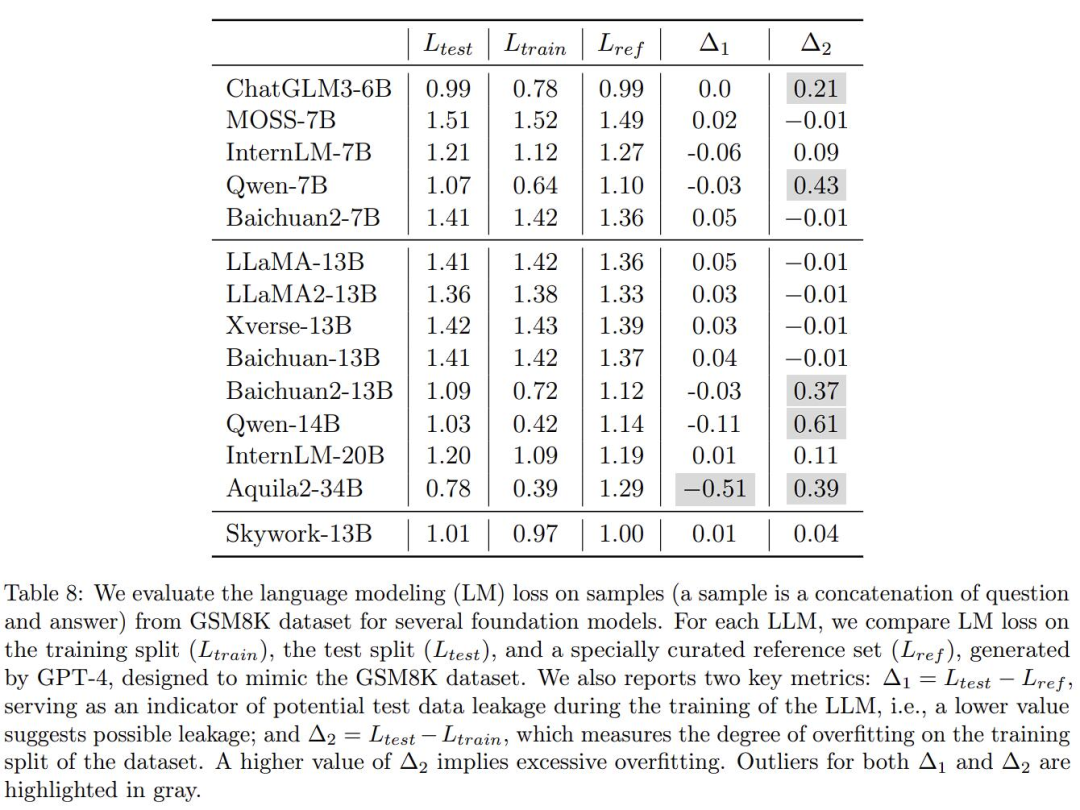 Di sini, untuk mengesahkan tahap overfitting beberapa model besar biasa dalam industri pada penanda aras masalah aplikasi matematik GSM8K, penulis menggunakan GPT-4 untuk menjana beberapa sampel GSM8K dengan bentuk yang sama telah diperiksa secara manual untuk ketepatannya, dan model ini dibandingkan pada set data yang dijana dengan set latihan dan set ujian asal GSM8K, dan kerugian dikira. Kemudian terdapat dua metrik:
Di sini, untuk mengesahkan tahap overfitting beberapa model besar biasa dalam industri pada penanda aras masalah aplikasi matematik GSM8K, penulis menggunakan GPT-4 untuk menjana beberapa sampel GSM8K dengan bentuk yang sama telah diperiksa secara manual untuk ketepatannya, dan model ini dibandingkan pada set data yang dijana dengan set latihan dan set ujian asal GSM8K, dan kerugian dikira. Kemudian terdapat dua metrik:
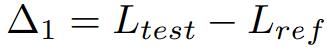 Δ1 berfungsi sebagai penunjuk potensi kebocoran data ujian semasa latihan model, dengan nilai yang lebih rendah menunjukkan kemungkinan kebocoran. Tanpa latihan pada set ujian, nilainya hendaklah sifar.
Δ1 berfungsi sebagai penunjuk potensi kebocoran data ujian semasa latihan model, dengan nilai yang lebih rendah menunjukkan kemungkinan kebocoran. Tanpa latihan pada set ujian, nilainya hendaklah sifar.
Δ2 mengukur tahap overfitting pembahagian latihan set data. Nilai Δ2 yang lebih tinggi bermakna overfitting. Jika ia belum dilatih pada set latihan, nilainya hendaklah sifar. 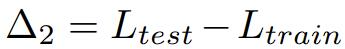
Untuk menerangkannya secara ringkas: jika model secara langsung menggunakan "soalan sebenar" dan "jawapan" dalam ujian penanda aras sebagai bahan pembelajaran semasa latihan, dan ingin menggunakannya untuk mendapatkan mata, maka di sini akan menjadi tidak normal.
Baiklah, kawasan bermasalah Δ1 dan Δ2 diserlahkan dengan teliti dalam warna kelabu di atas.
Netizen memberi komen bahawa seseorang akhirnya memberitahu rahsia terbuka "pencemaran set data".
Sesetengah netizen juga berkata tahap kecerdasan model besar masih bergantung kepada keupayaan sifar pukulan, yang tidak boleh dicapai oleh penanda aras ujian sedia ada.
Gambar: Tangkapan skrin dari komen netizen Zhihu
Semasa interaksi antara penulis dan pembaca, penulis juga berkata bahawa dia berharap untuk "membiarkan semua orang melihat isu ranking dengan lebih rasional. Masih terdapat jurang yang besar antara banyak model dan GPT4."
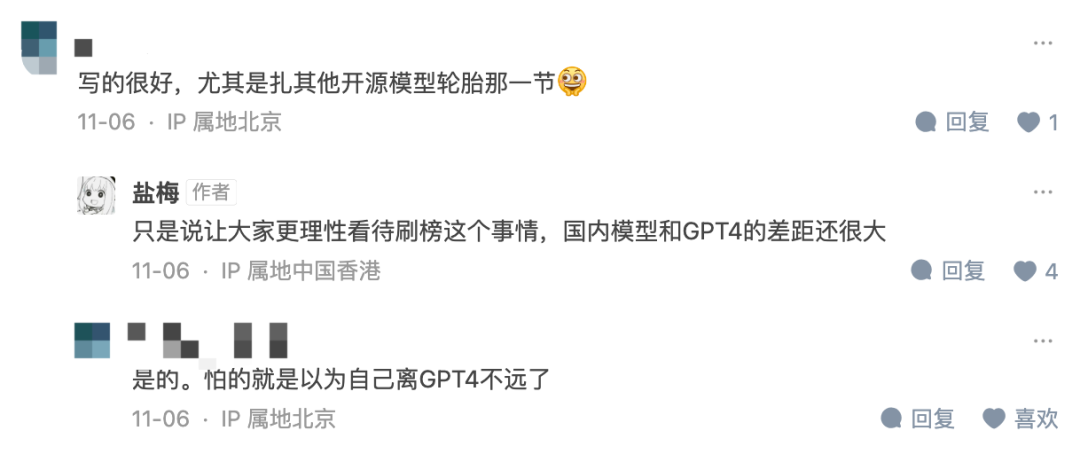
Gambar: Tangkapan skrin daripada artikel Zhihu https://zhuanlan.zhihu.com/p/61#98🎜5899 #
Masalah pencemaran data wajar diberi perhatian
Malah, ini bukan fenomena sementara. Sejak pengenalan Penanda Aras, masalah sedemikian telah berlaku dari semasa ke semasa, kerana tajuk artikel yang sangat ironis mengenai arXiv pada September tahun ini menegaskan: Pralatihan pada Set Ujian Adalah Semua yang Anda Perlukan.

Selain itu, kajian rasmi baru-baru ini dari Renmin University dan University of Illinois di Urbana-Champaign juga menunjukkan bahawa masalah penilaian model besar yang wujud di. Tajuknya sangat menarik perhatian "Jangan Jadikan LLM Anda Penipu Penanda Aras Penilaian":

pautan kertas : https:/// /arxiv.org/abs/2311.01964
Makalah itu menunjukkan bahawa medan panas semasa model besar telah membuatkan orang mengambil berat tentang kedudukan penanda aras, tetapi keadilan dan kebolehpercayaannya terjejas. Isu utama ialah pencemaran dan kebocoran data, yang mungkin dicetuskan secara tidak sengaja kerana kami mungkin tidak mengetahui set data penilaian masa depan semasa menyediakan korpus pra-latihan. Sebagai contoh, GPT-3 mendapati bahawa korpus pra-latihan mengandungi set data Ujian Buku Kanak-kanak, dan kertas LLaMA-2 menyebut mengekstrak kandungan halaman web kontekstual daripada set data BoolQ.
Set data memerlukan banyak usaha daripada ramai orang untuk mengumpul, menyusun dan melabel Jika set data berkualiti tinggi cukup baik untuk digunakan untuk penilaian, ia secara semula jadi boleh digunakan oleh orang lain untuk melatih model besar.
Sebaliknya, apabila menilai menggunakan penanda aras sedia ada, hasil model besar yang kami nilai kebanyakannya diperoleh dengan berjalan pada pelayan tempatan atau melalui panggilan API. Semasa proses ini, sebarang cara yang tidak wajar (seperti pencemaran data) yang boleh membawa kepada peningkatan yang tidak normal dalam prestasi penilaian tidak diperiksa dengan teliti.
Apa yang lebih teruk ialah komposisi terperinci korpus latihan (seperti sumber data) sering dianggap sebagai "rahsia" teras model besar sedia ada. Ini menjadikannya lebih sukar untuk meneroka masalah pencemaran data.
Maksudnya, jumlah data yang sangat baik adalah terhad Llama-2 pun tak semestinya okay. Sebagai contoh, GSM8K telah disebut dalam kertas pertama, dan GPT-4 menyebut menggunakan set latihannya dalam laporan teknikal rasmi.
Tidakkah anda mengatakan bahawa data adalah sangat penting, adakah prestasi model besar yang menggunakan "soalan sebenar" untuk mendapatkan mata menjadi lebih baik kerana latihan? data lebih baik? Jawapannya tidak.
Penyelidik secara eksperimen mendapati bahawa kebocoran penanda aras akan menyebabkan model besar menjalankan hasil yang berlebihan: contohnya, model 1.3B boleh melebihi saiz 10 kali ganda pada beberapa Model. Tetapi kesan sampingannya ialah jika kita hanya menggunakan data yang bocor ini untuk memperhalusi atau melatih model, prestasi model khusus ujian besar ini pada tugas ujian biasa yang lain mungkin terjejas.
Oleh itu, penulis mencadangkan bahawa pada masa hadapan, apabila penyelidik menilai model besar atau mengkaji teknologi baharu, mereka harus:
- Gunakan lebih banyak penanda aras daripada sumber yang berbeza meliputi keupayaan asas (cth. penjanaan teks) dan keupayaan lanjutan (cth. penaakulan kompleks) untuk menilai sepenuhnya keupayaan LLM.
- Apabila menggunakan penanda aras penilaian, adalah penting untuk melakukan semakan sanitasi data antara data pra-latihan dan sebarang data berkaitan (seperti set latihan dan ujian). Selain itu, keputusan analisis pencemaran untuk garis dasar penilaian perlu dilaporkan sebagai rujukan. Jika boleh, adalah disyorkan untuk membuat komposisi terperinci data pra-latihan awam.
- Adalah disyorkan bahawa gesaan ujian yang pelbagai harus digunakan untuk mengurangkan kesan sensitiviti segera. Ia juga masuk akal untuk menjalankan analisis pencemaran antara data asas dan korpora pra-latihan sedia ada untuk memberi amaran tentang sebarang potensi risiko pencemaran. Untuk tujuan penilaian, adalah disyorkan bahawa setiap penyerahan disertakan dengan laporan analisis pencemaran khas. .
Apakah pendapat anda dan cadangan berkesan mengenai perkara ini?
Atas ialah kandungan terperinci Adakah model besar mengambil jalan pintas untuk 'menewaskan ranking'? Masalah pencemaran data wajar diberi perhatian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!