
Rumah >Peranti teknologi >AI >Kepentingan pengesahan silang tidak boleh diabaikan!
Kepentingan pengesahan silang tidak boleh diabaikan!

- 王林ke hadapan
- 2023-11-06 20:17:191665semak imbas
Untuk tidak mengubah maksud asal, apa yang perlu dinyatakan semula ialah: Pertama, kita perlu memikirkan mengapa pengesahan silang diperlukan?
Pengesahan silang ialah teknik yang biasa digunakan dalam pembelajaran mesin dan statistik untuk menilai prestasi dan keupayaan generalisasi model ramalan, terutamanya apabila data terhad atau untuk menilai keupayaan model untuk membuat generalisasi kepada data baru yang tidak kelihatan.

Dalam keadaan apakah pengesahan silang akan digunakan?
- Penilaian prestasi model: Pengesahan silang membantu menganggar prestasi model pada data yang tidak kelihatan. Dengan melatih dan menilai model pada berbilang subset data, pengesahan silang memberikan anggaran prestasi model yang lebih mantap daripada pemisahan ujian kereta api tunggal.
- Kecekapan data: Apabila data terhad, pengesahan silang menggunakan sepenuhnya semua sampel yang tersedia, memberikan penilaian prestasi model yang lebih dipercayai dengan menggunakan semua data secara serentak untuk latihan dan penilaian.
- Penalaan Hiperparameter: Pengesahan silang sering digunakan untuk memilih hiperparameter terbaik untuk model. Dengan menilai prestasi model anda menggunakan tetapan hiperparameter berbeza pada subset data yang berbeza, anda boleh mengenal pasti nilai hiperparameter yang berprestasi terbaik dari segi prestasi keseluruhan.
- Kesan overfitting: Pengesahihan silang membantu mengesan sama ada model melakukan overfitting data latihan. Jika model menunjukkan prestasi yang lebih baik dengan ketara pada set latihan berbanding set pengesahan, ia mungkin menunjukkan overfitting dan memerlukan pelarasan, seperti regularization atau memilih model yang lebih mudah.
- Penilaian keupayaan generalisasi: Pengesahan silang menyediakan penilaian keupayaan model untuk membuat generalisasi kepada data yang tidak kelihatan. Dengan menilai model pada berbilang pemisahan data, ia membantu menilai keupayaan model untuk menangkap corak asas dalam data tanpa bergantung pada rawak atau pemisahan ujian kereta api tertentu.
Idea umum pengesahan silang boleh ditunjukkan dalam Rajah 5-lipat silang Dalam setiap lelaran, model baharu dilatih pada empat sub-set data dan diuji pada sub-set data terakhir yang disimpan untuk memastikan semua data. diperolehi kegunaan. Melalui penunjuk seperti skor purata dan sisihan piawai, ukuran sebenar prestasi model disediakan
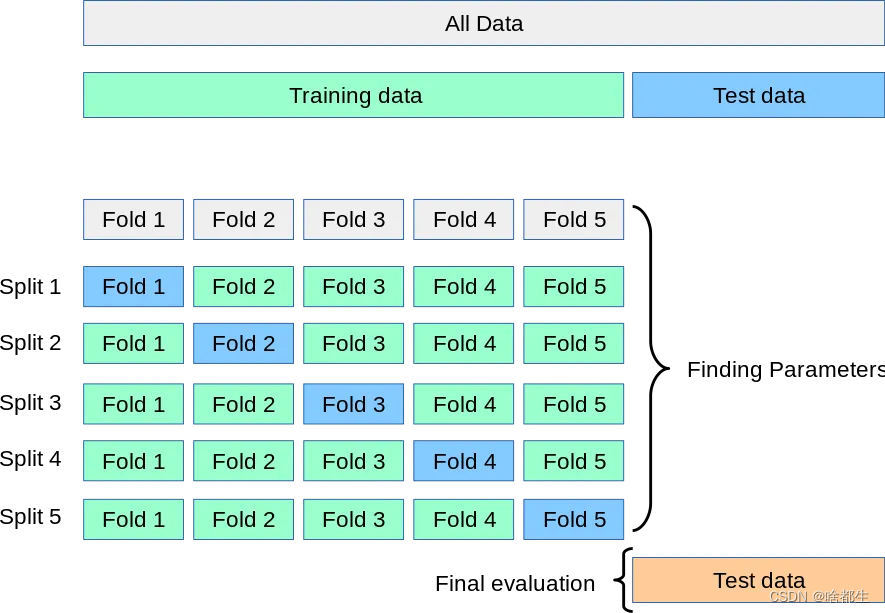
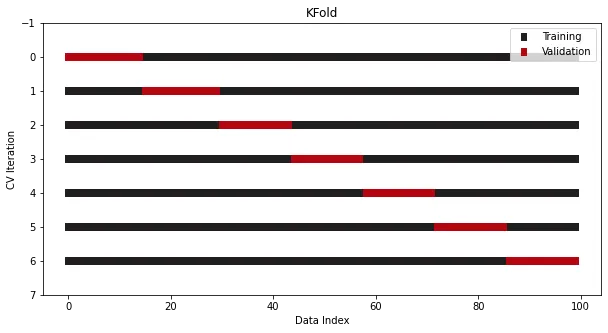
Semuanya perlu bermula dengan silang K-lipatan. . Meminimumkan risiko overfitting:
from sklearn.datasets import make_regressionfrom sklearn.model_selection import KFoldx, y = make_regression(n_samples=100)# Init the splittercross_validation = KFold(n_splits=7)Dengan cara ini, pengesahan silang lipatan k yang mudah boleh diselesaikan, sila pastikan anda menyemak kod sumber! Pastikan anda menyemak kod sumber! Pastikan anda menyemak kod sumber!
 StratifiedKFold
StratifiedKFold
StratifiedKFold direka khas untuk masalah klasifikasi.
Dalam beberapa masalah klasifikasi, walaupun data dibahagikan kepada beberapa set, pengedaran sasaran harus kekal tidak berubah. Sebagai contoh, dalam kebanyakan kes, sasaran binari dengan nisbah kelas 30 hingga 70 masih harus mengekalkan nisbah yang sama dalam set latihan dan set ujian Dalam KFold biasa, peraturan ini dilanggar kerana data dikocok sebelum dipecahkan. perkadaran kategori tidak akan dikekalkan. 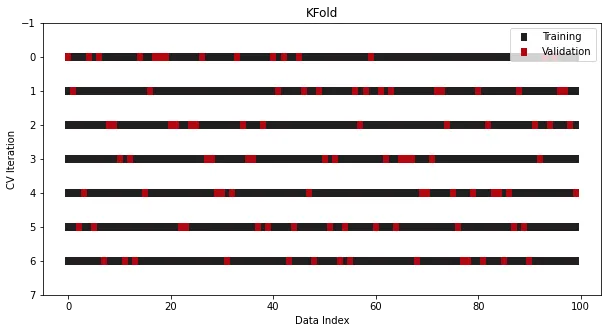
cross_validation = KFold(n_splits=7, shuffle=True)
Walaupun ia kelihatan serupa dengan KFold, kini dalam semua pemisahan dan lelaran, perkadaran Kelas kekal konsisten
ShuffleStimes
ShuffleStimes proses pemisahan set latihan/ujian hanya diulang beberapa kali, dengan cara yang hampir sama dengan pengesahan silang
Secara logiknya, dengan menggunakan benih rawak yang berbeza untuk menjana beberapa set latihan/ujian Set ujian hendaklah serupa dengan silang yang teguh- proses pengesahan dalam lelaran yang mencukupi. Antara muka yang sepadan juga disediakan dalam perpustakaan Scikit-learn: 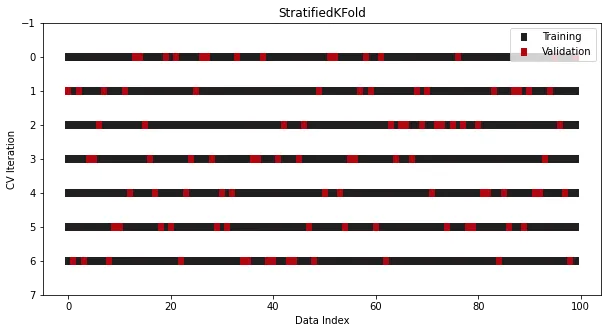
from sklearn.datasets import make_classificationfrom sklearn.model_selection import StratifiedKFoldx, y = make_classification(n_samples=100, n_classes=2)cross_validation = StratifiedKFold(n_splits=7, shuffle=True, random_state=1121218)
TimeSeriesSplit
Apabila set data ialah siri masa, Pengesahan silang tradisional tidak boleh digunakan, yang akan mengganggu sepenuhnya Untuk menyelesaikan masalah ini, rujuk Sklearn menyediakan splitter-TimeSeriesSplit yang lain,
from sklearn.model_selection import ShuffleSplitcross_validation = ShuffleSplit(n_splits=7, train_size=0.75, test_size=0.25)Situasi di mana set pengesahan sentiasa terletak selepas indeks set latihan Di bawah, kita boleh lihat graf. Ini disebabkan oleh fakta bahawa indeks ialah tarikh, yang bermaksud kita tidak boleh secara tidak sengaja melatih model siri masa pada tarikh akan datang dan membuat ramalan untuk tarikh sebelumnya
Pengesahan silang data teragih bukan bebas dan identik (bukan IID)
Kaedah di atas diproses untuk set data teragih bebas dan serupa, iaitu proses penjanaan data tidak akan terjejas oleh sampel lain
Walau bagaimanapun , dalam beberapa kes, data tidak memenuhi syarat taburan bebas dan serupa (IID), iaitu, terdapat hubungan pergantungan antara beberapa sampel. Keadaan ini juga berlaku dalam pertandingan Kaggle, seperti pertandingan Tekanan Ventilator Otak Google. Data ini merekodkan nilai tekanan udara paru-paru buatan semasa beribu-ribu nafas (penyedutan dan pernafasan), dan direkodkan pada setiap saat setiap nafas. Terdapat kira-kira 80 baris data untuk setiap proses pernafasan, dan baris ini berkaitan antara satu sama lain. Dalam kes ini, kaedah pengesahan silang tradisional tidak boleh digunakan kerana pembahagian data mungkin "berlaku betul-betul di tengah-tengah proses pernafasan"
Ini boleh difahami sebagai keperluan untuk "menghimpun" data ini kerana dalam- data kumpulan Ia berkaitan. Contohnya, apabila mengumpul data perubatan daripada berbilang pesakit, setiap pesakit mempunyai berbilang sampel. Walau bagaimanapun, data ini berkemungkinan dipengaruhi oleh perbezaan individu di kalangan pesakit, dan oleh itu juga perlu dikumpulkan
Selalunya kami berharap model yang dilatih pada kumpulan tertentu dapat digeneralisasikan dengan baik kepada kumpulan ghaib lain, jadi Apabila melakukan pengesahan silang, berikan kumpulan data ini "tag" dan beritahu mereka cara membezakannya.
Beberapa antara muka disediakan dalam Sklearn untuk mengendalikan situasi ini:
- GroupKFold
- StratifiedGroupKFold
- LeaveOneGroupOut
- LeavePGroupOut LeavePGroupOut
- Adalah sangat disyorkan untuk memahami idea pengesahan silang, dan bagaimana untuk laksanakannya, lihat kod sumber Sklearn: Bukan cara yang buruk untuk menggemukkan usus anda. Di samping itu, anda perlu mempunyai definisi yang jelas tentang set data anda sendiri, dan prapemprosesan data adalah sangat penting.
Atas ialah kandungan terperinci Kepentingan pengesahan silang tidak boleh diabaikan!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!