
Rumah >Peranti teknologi >AI >GPT-4 membuat 'model dunia', membenarkan LLM belajar daripada 'soalan yang salah' dan meningkatkan keupayaan penaakulannya dengan ketara
GPT-4 membuat 'model dunia', membenarkan LLM belajar daripada 'soalan yang salah' dan meningkatkan keupayaan penaakulannya dengan ketara

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-11-03 14:17:301164semak imbas
Baru-baru ini, model bahasa besar telah membuat penemuan penting dalam pelbagai tugas pemprosesan bahasa semula jadi, terutamanya dalam masalah matematik yang memerlukan penaakulan rantaian pemikiran (CoT) yang kompleks
Sebagai contoh, dalam GSM8K, MATH, dll. Model proprietari termasuk GPT -4 dan PaLM-2 telah mencapai keputusan yang luar biasa pada set data tugasan matematik yang sukar. Dalam hal ini, model besar sumber terbuka masih mempunyai ruang yang besar untuk penambahbaikan. Untuk meningkatkan lagi keupayaan inferens CoT bagi model besar sumber terbuka untuk tugasan matematik, pendekatan biasa adalah untuk memperhalusi model ini menggunakan pasangan data inferens soalan beranotasi/dijana (data CoT) yang secara langsung mengajar model cara melaksanakan tugasan pada ini. Lakukan inferens CoT semasa menjalankan tugas.
Baru-baru ini, penyelidik dari Universiti Xi'an Jiaotong, Microsoft dan Universiti Peking meneroka idea penambahbaikan dalam kertas kerja, iaitu untuk meningkatkan lagi keupayaan penaakulannya melalui proses pembelajaran terbalik (iaitu, belajar daripada kesilapan LLM)
Sama seperti pelajar yang mula belajar matematik, dia akan terlebih dahulu meningkatkan pemahamannya dengan mengkaji perkara-perkara ilmu dan contoh-contoh dalam buku teks. Tetapi pada masa yang sama, dia juga melakukan latihan untuk menyatukan apa yang telah dipelajarinya. Apabila dia menghadapi kesukaran atau gagal dalam menyelesaikan masalah, dia akan menyedari kesilapan yang telah dia lakukan dan belajar bagaimana untuk membetulkannya, sekali gus membentuk "buku masalah yang salah". Dengan belajar daripada kesilapan, kebolehan penaakulannya dipertingkatkan lagi
Diilhamkan oleh proses ini, karya ini meneroka bagaimana kebolehan penaakulan LLM mendapat manfaat daripada memahami dan membetulkan kesilapan.

Alamat kertas: https://arxiv.org/pdf/2310.20689.pdf
Secara khusus, penyelidik mula-mula menghasilkan pasangan data pembetulan ralat), untuk (dipanggil data pembetulan) memperhalusi LLM. Apabila menjana data pembetulan: perkara yang perlu ditulis semula, mereka menggunakan berbilang LLM (termasuk LLaMA dan keluarga model GPT) untuk mengumpul laluan inferens yang tidak tepat (iaitu, jawapan akhir tidak betul), dan kemudiannya menggunakan GPT-4 sebagai " "Pembetul. " untuk menjana pembetulan bagi laluan penaakulan yang tidak tepat ini
Pembetulan yang dijana mengandungi tiga maklumat: (1) langkah yang salah dalam penyelesaian asal; (2) penjelasan mengapa langkah itu tidak betul; (3) bagaimana Betul penyelesaian asal untuk mendapatkan jawapan akhir yang betul. Selepas menapis pembetulan dengan jawapan akhir yang salah, penilaian manual menunjukkan bahawa data pembetulan menunjukkan kualiti yang mencukupi untuk fasa penalaan halus berikutnya. Para penyelidik menggunakan QLoRA untuk memperhalusi LLM pada data CoT dan data pembetulan, dengan itu melaksanakan "belajar daripada ralat" (LEMA).
Penyelidikan menunjukkan bahawa LLM semasa boleh menggunakan pendekatan langkah demi langkah untuk menyelesaikan masalah, tetapi proses penjanaan pelbagai langkah ini tidak bermakna LLM itu sendiri mempunyai keupayaan penaakulan yang kukuh. Ini kerana mereka mungkin hanya meniru tingkah laku permukaan penaakulan manusia tanpa benar-benar memahami logik dan peraturan asas yang diperlukan
Kekurangan pemahaman ini akan membawa kepada kesilapan dalam proses penaakulan, jadi bantuan "model dunia" diperlukan . Kerana "model dunia" mempunyai kesedaran apriori tentang logik dan peraturan dunia sebenar. Daripada perspektif ini, rangka kerja LEMA dalam artikel ini boleh dilihat sebagai menggunakan GPT-4 sebagai "model dunia" untuk mengajar model yang lebih kecil untuk mengikuti logik dan peraturan ini, dan bukannya hanya meniru tingkah laku langkah demi langkah.
Sekarang, mari kita lihat langkah-langkah pelaksanaan khusus kajian ini
Tinjauan Metodologi
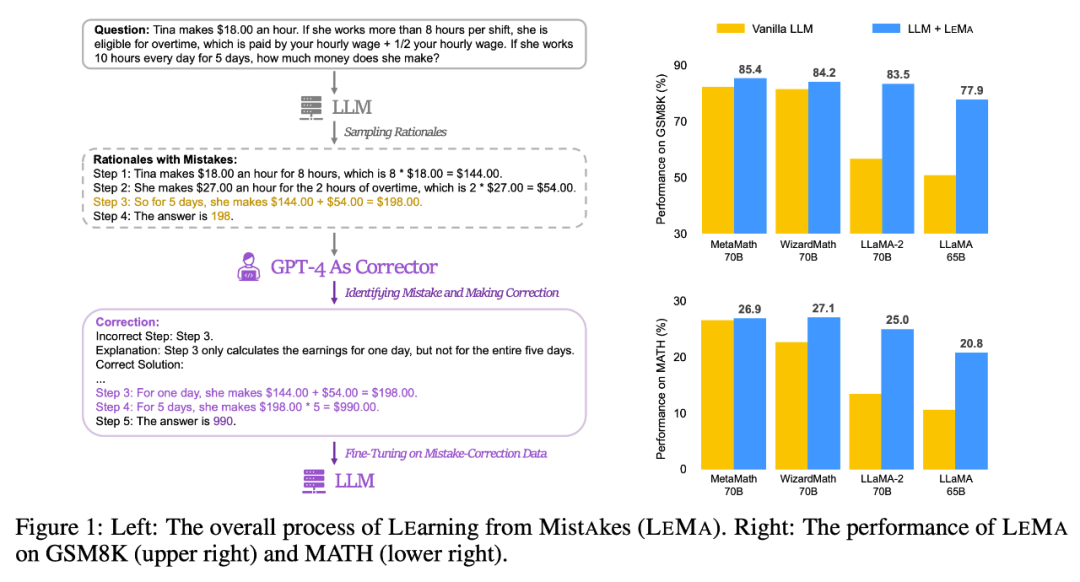
Sila lihat Rajah 1 (kiri) di bawah, yang menunjukkan proses keseluruhan LEMA data yang diperbetulkan: Diperlukan Terdapat dua fasa utama: menulis semula kandungan dan LLM menyempurnakan. Rajah 1 (kanan) menunjukkan prestasi LEMA pada set data GSM8K dan MATH
Jana data yang diperbetulkan: Perkara yang perlu ditulis semula
Memandangkan contoh soal jawab 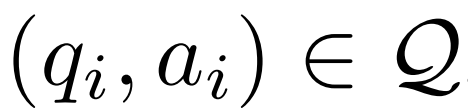 , model pembetul M_c dan model inferens M_r, penyelidik menjana pasangan data pembetulan ralat
, model pembetul M_c dan model inferens M_r, penyelidik menjana pasangan data pembetulan ralat 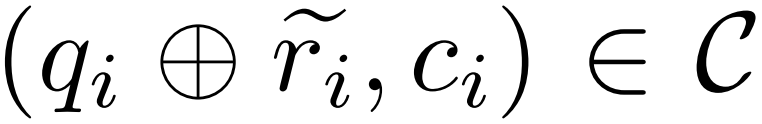 , di mana
, di mana 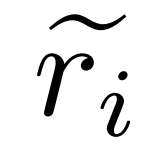 mewakili inferens dan laluan c_i yang tidak tepat Pembetulan
mewakili inferens dan laluan c_i yang tidak tepat Pembetulan 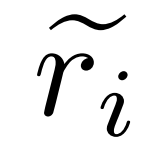 .
.
Pembetulan laluan penaakulan yang tidak tepat . Penyelidik mula-mula menggunakan model inferens M_r untuk mengambil sampel berbilang laluan inferens bagi setiap soalan q_i, dan kemudian hanya mengekalkan laluan tersebut yang akhirnya tidak membawa kepada jawapan yang betul a_i, seperti yang ditunjukkan dalam formula berikut (1).
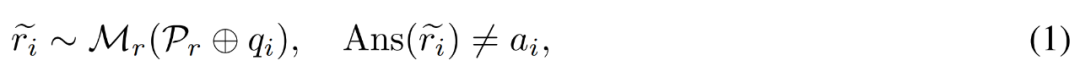
Jana pembetulan untuk pepijat. Untuk soalan q_i dan laluan penaakulan yang tidak tepat 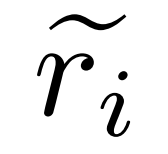 , penyelidik menggunakan model pembetulan M_c untuk menjana pembetulan, dan kemudian menyemak jawapan yang betul dalam pembetulan, seperti ditunjukkan dalam persamaan (2) di bawah. .
, penyelidik menggunakan model pembetulan M_c untuk menjana pembetulan, dan kemudian menyemak jawapan yang betul dalam pembetulan, seperti ditunjukkan dalam persamaan (2) di bawah. .
Langkah ralat: langkah mana dalam laluan penaakulan asal yang salah. 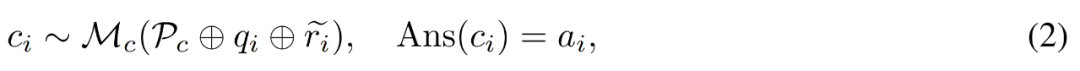
Penjelasan: Apakah jenis ralat yang berlaku dalam langkah ini;
Penyelesaian yang betul: Bagaimana untuk membetulkan laluan penaakulan yang tidak tepat untuk menyelesaikan masalah asal dengan lebih baik.
- Sila lihat imej di bawah, Ilustrasi 1 menunjukkan secara ringkas gesaan yang digunakan untuk menjana pembetulan
- Jana penilaian manual pembetulan
Sebelum menjana data yang lebih besar, kami terlebih dahulu menilai kualiti pembetulan yang dihasilkan secara manual. Mereka menggunakan LLaMA-2-70B sebagai M_r dan GPT-4 sebagai M_c, dan menghasilkan 50 pasangan data yang diperbetulkan ralat berdasarkan set latihan GSM8K.
Penyelidik mengelaskan pembetulan kepada tiga tahap kualiti: cemerlang, baik dan buruk. Berikut ialah contoh tiga tahap 
Penilaian mendapati 35 daripada 50 pembetulan binaan mencapai kualiti yang sangat baik, 11 adalah baik dan 4 adalah lemah. Berdasarkan penilaian ini, penyelidik membuat kesimpulan bahawa kualiti keseluruhan pembetulan yang dijana menggunakan GPT-4 adalah mencukupi untuk peringkat penalaan lebih lanjut. Oleh itu, mereka menghasilkan lebih banyak pembetulan berskala besar dan menggunakan semua pembetulan yang akhirnya membawa kepada jawapan yang betul kepada LLM yang memerlukan penalaan halus.

LLM yang memerlukan penalaan halus
Selepas menjana data pembetulan: perkara yang perlu ditulis semula, para penyelidik memperhalusi LLM untuk menilai sama ada model boleh belajar daripada kesilapan mereka. Mereka terutamanya melakukan perbandingan prestasi di bawah dua tetapan penalaan halus berikut.
Yang pertama ialah memperhalusi pada data Chain of Thought (CoT). Penyelidik memperhalusi model hanya pada data rasional soalan. Walaupun terdapat data beranotasi dalam setiap tugas, mereka juga menggunakan penambahan data CoT. Para penyelidik menggunakan GPT-4 untuk menjana lebih banyak laluan penaakulan bagi setiap soalan dalam set latihan dan menapis laluan dengan jawapan akhir yang salah. Mereka memanfaatkan penambahan data CoT untuk membina garis dasar penalaan halus yang teguh yang hanya menggunakan data CoT dan memudahkan kajian ablasi tentang saiz data yang mengawal penalaan halus.
Yang kedua ialah penalaan halus pada data CoT + data yang diperbetulkan. Selain data CoT, penyelidik juga menghasilkan data pembetulan ralat untuk penalaan halus (iaitu, LEMA). Mereka juga menjalankan eksperimen ablasi dengan saiz data terkawal untuk mengurangkan kesan kenaikan pada saiz data.
Contoh 5 dan Contoh 6 dalam Lampiran A menunjukkan format input-output bagi data CoT dan data pembetulan masing-masing untuk penalaan halus LEMA pada lima LLM sumber terbuka dan dua tugasan penaakulan matematik yang mencabar

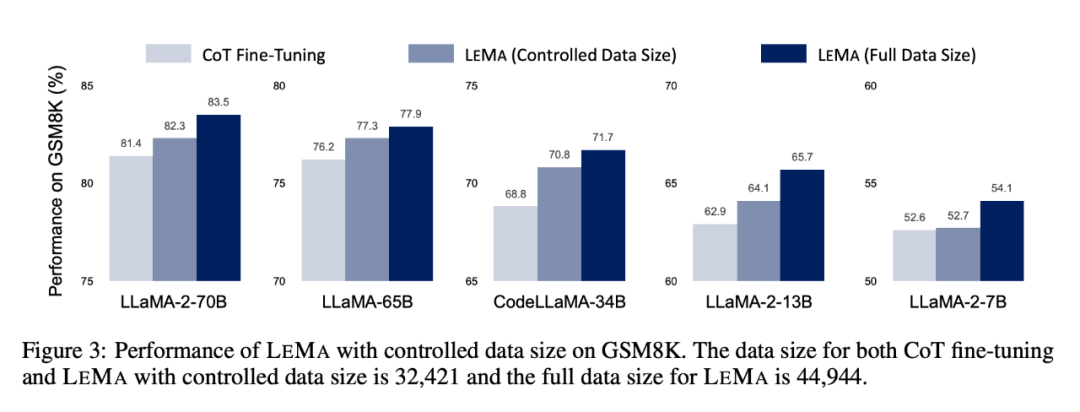
LEMA secara konsisten meningkatkan prestasi merentas pelbagai LLM dan tugasan, berbanding dengan penalaan halus hanya pada data CoT Bandingkan. Sebagai contoh, LEMA menggunakan LLaMA-2-70B mencapai keputusan masing-masing sebanyak 83.5% dan 25.0% pada GSM8K dan MATH, manakala penalaan halus hanya pada data CoT mencapai keputusan masing-masing sebanyak 81.4% dan 23.6%
, LEMA serasi dengan LLM proprietari: LEMA dengan WizardMath-70B/MetaMath-70B mencapai 84.2%/85.4% ketepatan pass@1 pada GSM8K dan 27.1%/26.9% pada MATH Kadar ketepatan pass@1 melebihi prestasi SOTA yang dicapai oleh ramai model sumber terbuka pada tugasan yang mencabar ini.
Kajian ablasi seterusnya menunjukkan bahawa LEMA masih mengatasi penalaan halus CoT sahaja di bawah jumlah data yang sama. Ini menunjukkan bahawa data CoT dan data yang diperbetulkan tidak sama berkesan, kerana menggabungkan kedua-dua sumber data menghasilkan lebih banyak peningkatan berbanding menggunakan satu sumber data. Keputusan dan analisis eksperimen ini menyerlahkan potensi pembelajaran daripada ralat untuk meningkatkan keupayaan inferens LLM. 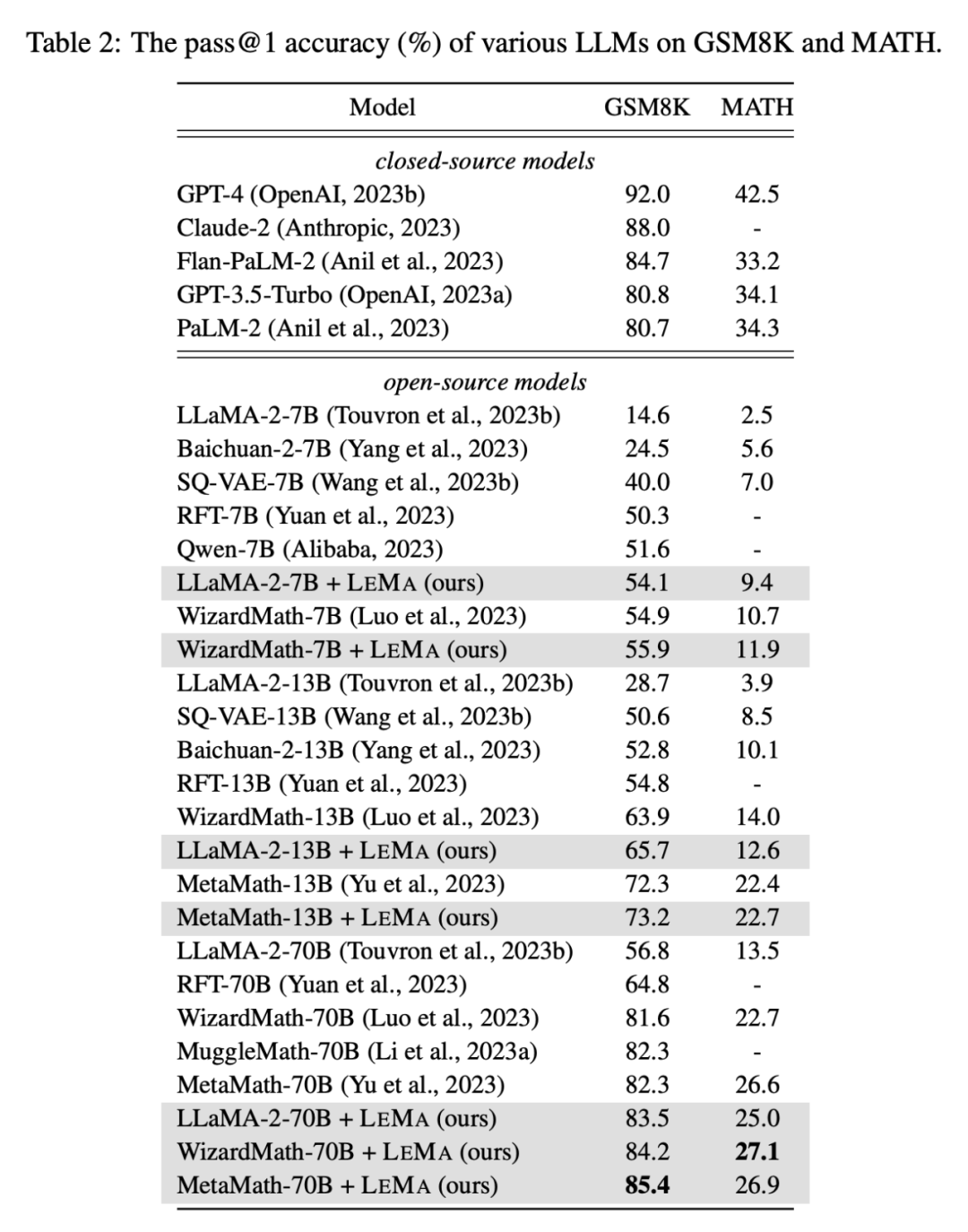
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal
Atas ialah kandungan terperinci GPT-4 membuat 'model dunia', membenarkan LLM belajar daripada 'soalan yang salah' dan meningkatkan keupayaan penaakulannya dengan ketara. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!