
Rumah >Peranti teknologi >AI >Penyelidik dadah AI menyertai sub-jurnal Nature: menggunakan pengetahuan profesional untuk mempercepatkan pembangunan dadah
Penyelidik dadah AI menyertai sub-jurnal Nature: menggunakan pengetahuan profesional untuk mempercepatkan pembangunan dadah

- 王林ke hadapan
- 2023-11-02 17:45:231219semak imbas
Penemuan dadah adalah proses kompleks, pelbagai langkah yang melibatkan persilangan banyak sub-disiplin kimia dan biologi. Ahli kimia perubatan manusia memainkan peranan penting dalam proses ini dengan kepakaran terkumpul mereka selama bertahun-tahun
Jadi, bolehkah kecerdasan buatan (AI) mengisi peranan yang dimainkan oleh ahli kimia perubatan dalam penemuan dadah? Jawapannya mungkin ya.
Baru-baru ini, pasukan penyelidik dari Institut Penyelidikan Bioperubatan Novartis (NIBR) dan Pusat Penyelidikan Microsoft untuk Kecerdasan Saintifik (AI4Science) bersama-sama mencadangkan model pembelajaran mesin yang boleh menghasilkan semula sebahagian pengetahuan kolektif yang terkumpul oleh ahli kimia profesional dalam kerja mereka , pengetahuan jenis ini sering dipanggil "intuisi kimia".
Pasukan penyelidik percaya bahawa kaedah ini boleh digunakan sebagai pelengkap kepada pemodelan molekul untuk meningkatkan kecekapan pembangunan ubat masa depan
Kertas penyelidikan bertajuk "Mengekstrak Intuisi dalam Kimia Perubatan melalui Pembelajaran Mesin Keutamaan" dan telah diterbitkan dalam Nature Communications, sub-jurnal Nature

Pembelajaran mesin mencipta semula kepakaran ahli kimia perubatan
Ahli kimia perubatan, kedua-dua makmal basah dan pengiraan, memainkan peranan penting dalam fasa "pengoptimuman plumbum" penemuan ubat, kerana mereka sering diminta untuk menentukan sebatian yang perlu disintesis dan digunakan dalam pusingan pengoptimuman berikutnya untuk dinilai.
Untuk melakukan ini, ahli kimia perubatan biasanya menyemak data termasuk sifat kompaun seperti aktiviti, ADMET2 atau maklumat struktur sasaran. Oleh itu, kejayaan sesuatu projek bergantung bukan sahaja pada kualiti data eksperimen yang dihasilkan, tetapi juga pada keteguhan dan rasional keputusan yang dibuat oleh pasukan yang bekerja dalam kimia perubatan.
Ahli kimia perubatan dapat membuat keputusan dengan lebih cekap kerana mereka sering menggunakan kepakaran untuk mempunyai pemahaman intuitif tentang apa yang berjaya dalam lelaran berbeza penemuan ubat peringkat awal.
Walaupun terdapat percubaan sebelum ini untuk memformalkan pengetahuan ini menggunakan pendekatan berasaskan peraturan atau skor kebolehlaksanaan kemoinformatik mudah, menangkap kehalusan dan kerumitan yang terlibat dalam pemarkahan oleh ahli kimia perubatan kekal sebagai cabaran asas
Untuk mencapai matlamat ini, penyelidikan bertujuan untuk mengubah kepakaran menjadi sebahagian daripada model pembelajaran mesin. Model ini boleh digunakan sebagai alat bantu, seperti sistem pengesyoran lain yang telah dilaporkan dalam industri, untuk menggunakan proses membuat keputusan dalam pengoptimuman plumbum atau aspek penemuan dadah yang lain
Memandangkan kimia perubatan pada masa ini bergantung terutamanya pada kerja manual, ia pasti dipengaruhi oleh berat sebelah subjektif. Beberapa kajian telah melaporkan persetujuan yang rendah dalam penilaian antara dan dalam ahli kimia perubatan. Dalam kajian ini, penyelidik berharap dapat menyelesaikan beberapa masalah dengan meminjam strategi daripada permainan berbilang pemain.
Mereka menganggap tugas menyusun satu set molekul sebagai masalah pembelajaran keutamaan dan kemudian menggunakan rangkaian saraf mudah untuk memodelkan pilihan individu
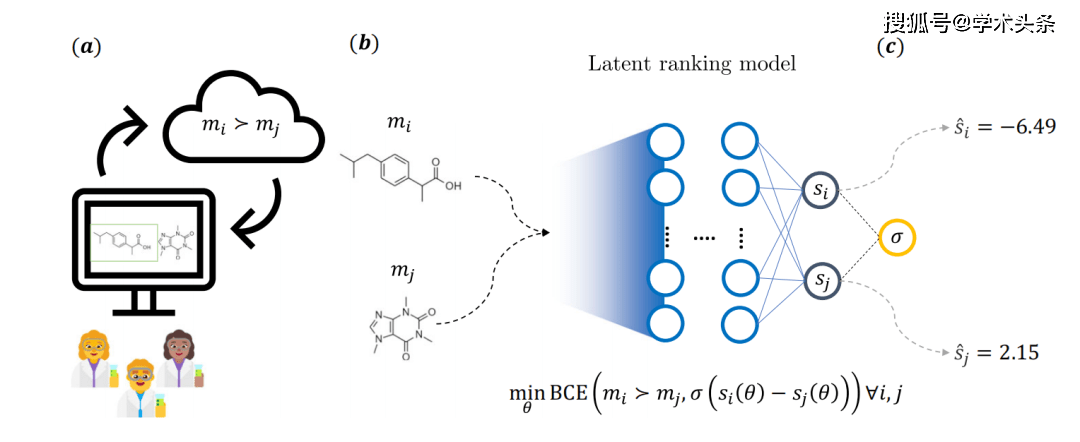 Rajah |. Gambarajah skematik keseluruhan idea utama penyelidikan (sumber: kertas kerja)
Rajah |. Gambarajah skematik keseluruhan idea utama penyelidikan (sumber: kertas kerja)
Secara khusus, seperti yang ditunjukkan dalam rajah di atas, molekul dilihat sebagai peserta dalam permainan kompetitif, dengan kebarangkalian satu pihak menang ditentukan oleh maklum balas yang diberikan oleh ahli kimia. Untuk melakukan ini, ahli kimia perubatan menjawab gesaan soalan yang telah ditetapkan pada aplikasi web dan pilih satu daripada dua molekul. Seramai 35 ahli kimia perubatan Novartis terlibat dalam proses itu, yang menghasilkan pengumpulan lebih daripada 5,000 anotasi.
Maklum balas ini membawa kepada model pemarkahan tersirat, yang menggunakan model dengan dua struktur rangkaian saraf bebas. Setiap cawangan mempunyai berat tetap dan molekul dicirikan menggunakan deskriptor kemoinformatik biasa. Semasa latihan, parameter model dioptimumkan melalui kehilangan rentas entropi binari (kehilangan SM), yang bergantung pada perbezaan skor asas sepasang molekul dan maklum balas yang diberikan oleh ahli kimia
Setelah latihan selesai, markah untuk sebarang molekul sewenang-wenangnya boleh disimpulkan, yang kemudiannya boleh digunakan untuk tugasan kimia hiliran.
Selain itu, model boleh menentukan persamaan antara ubat yang berbeza dengan lebih tepat. Fungsi pemarkahan pembelajaran yang dicadangkan dalam kajian adalah lebih tepat daripada indeks penilaian kesamaan ubat tradisional (QED)
Terutama, Untuk menggalakkan kebolehulangan kajian dan pembangunan lanjut bidang, penyelidik juga menyediakan pakej perisian yang dipanggil "MolSkill" yang mengandungi model dan data tindak balas tanpa nama.
Masalah dan aplikasi pembelajaran mesin dalam bidang kimia perubatan
Namun, walaupun model ini boleh menghasilkan semula pengetahuan yang dikumpul oleh ahli kimia perubatan dalam kerja mereka, ia juga mempunyai beberapa batasan. Pertama, untuk menangkap intuisi kimia, soalan yang ditanya semasa pengumpulan data sentiasa kabur.
Selain itu, walaupun reka bentuk kajian yang dicadangkan menghasilkan persetujuan yang lebih besar antara peserta berbanding kajian terdahulu, kaedah perbandingan berpasangan tidak sempurna.
Selain itu, "Flatland Fallacy" menyebabkan manusia cenderung untuk memudahkan masalah berdimensi tinggi menjadi satu set kecil pembolehubah yang boleh dijejaki secara kognitif, dan penyederhanaan ini mungkin dipengaruhi oleh ciri peribadi setiap ahli kimia perubatan
Walau bagaimanapun, pasukan penyelidik menyatakan bahawa model yang dicadangkan dalam kajian ini tidak terhad kepada skop aplikasi kajian semasa. Secara khusus, rangka kerja yang dibincangkan boleh diperluaskan kepada pemerhatian lain yang boleh diukur tetapi mahal dalam bidang penemuan dadah. Tambahan pula, ia boleh memberikan pandangan tentang kawasan ruang kimia yang belum diterokai.
Dengan mengambil kira perkara ini, pasukan penyelidik percaya bahawa seni bina yang serupa boleh dibina dengan membenarkan beberapa penapis berasaskan peraturan popular belajar daripada data latihan yang dijana secara buatan. Model ini boleh mengatasi had utama untuk menapis sebatian secara manual sebelum membuat inferens
Pendekatan yang sama juga boleh digunakan untuk menjana skor kompaun dengan mengutamakan kombinasi dalam perpustakaan kimia sintetik di mana, disebabkan kebaharuan semula jadi, mereka sukar untuk disaring menggunakan kaedah berasaskan peraturan sedia ada
Perkara lain yang perlu dinyatakan semula ialah: dalam senario pengoptimuman utama yang prospektif untuk sasaran tertentu, pelbagai sumber maklumat (seperti sifat biologi, ADMET, dll.) perlu dipertimbangkan secara menyeluruh untuk menguji kepraktisan rangka kerja penyelidikan
Pasukan penyelidik menulis dalam kertas itu: "Kaedah pembelajaran mesin boleh mereka bentuk beribu-ribu sebatian, dan teknologi seperti penapisan pemprosesan tinggi boleh menyerlahkan sejumlah besar sebatian calon pada peringkat awal proses penemuan dadah. Kaedah pemarkahan mencadangkan ini masa adalah Diharapkan bahawa permohonan ini akan mempercepatkan penggunaan kaedah dan kepercayaan pada tahun-tahun akan datang
Atas ialah kandungan terperinci Penyelidik dadah AI menyertai sub-jurnal Nature: menggunakan pengetahuan profesional untuk mempercepatkan pembangunan dadah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!