

 Peranti teknologiAIPembelajaran pengukuhan Q-pembelajaran mendalam menggunakan simulasi lengan robot Panda-Gym
Peranti teknologiAIPembelajaran pengukuhan Q-pembelajaran mendalam menggunakan simulasi lengan robot Panda-GymPembelajaran pengukuhan Q-pembelajaran mendalam menggunakan simulasi lengan robot Panda-Gym

Pembelajaran Pengukuhan (RL) ialah kaedah pembelajaran mesin yang membolehkan ejen mempelajari cara berkelakuan dalam persekitarannya melalui percubaan dan kesilapan. Ejen diberi ganjaran atau dihukum kerana mengambil tindakan yang membawa kepada hasil yang diingini. Lama kelamaan, ejen belajar untuk mengambil tindakan yang memaksimumkan ganjaran yang diharapkan
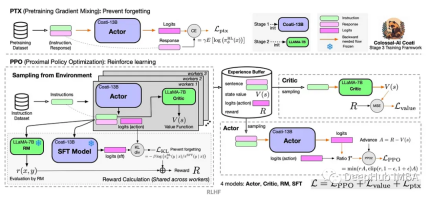
Ejen RL biasanya dilatih menggunakan Proses Keputusan Markov (MDP), yang memodelkan rangka kerja matematik masalah keputusan berurutan. MDP terdiri daripada empat bahagian:
- Keadaan: satu set kemungkinan keadaan persekitaran.
- Tindakan: Satu set tindakan yang boleh diambil oleh ejen.
- Fungsi peralihan: Fungsi yang meramalkan kebarangkalian peralihan kepada keadaan baharu memandangkan keadaan dan tindakan semasa.
- Fungsi ganjaran: Fungsi yang memberikan ganjaran kepada ejen untuk setiap penukaran.
Matlamat ejen adalah untuk mempelajari fungsi dasar yang memetakan keadaan kepada tindakan. Maksimumkan pulangan jangkaan ejen dari semasa ke semasa melalui fungsi polisi.
Pembelajaran Q mendalam ialah algoritma pembelajaran pengukuhan yang menggunakan rangkaian saraf dalam untuk mempelajari fungsi dasar. Rangkaian saraf dalam mengambil keadaan semasa sebagai input dan output vektor nilai, di mana setiap nilai mewakili tindakan yang mungkin. Ejen kemudiannya mengambil tindakan berdasarkan nilai tertinggi
Pembelajaran Q mendalam ialah algoritma pembelajaran pengukuhan berasaskan nilai, bermakna ia mempelajari nilai setiap pasangan tindakan keadaan. Nilai pasangan tindakan keadaan ialah ganjaran yang dijangkakan untuk ejen mengambil tindakan tersebut dalam keadaan tersebut.
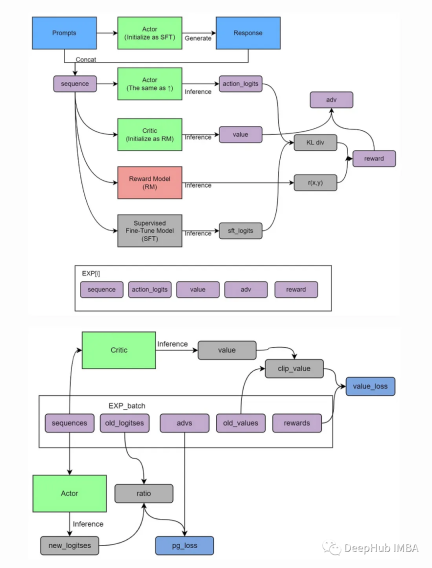
Actor-Critic ialah algoritma RL yang menggabungkan berasaskan nilai dan berasaskan dasar. Terdapat dua komponen:
Pelakon: Pelakon bertanggungjawab untuk memilih operasi.
Pengkritik: Bertanggungjawab untuk menilai tingkah laku Pelakon.
Pelakon dan pengkritik dilatih pada masa yang sama. Pelakon dilatih untuk memaksimumkan ganjaran yang dijangkakan dan pengkritik dilatih untuk meramalkan ganjaran yang dijangkakan dengan tepat untuk setiap pasangan tindakan keadaan
Algoritma Actor-Critic mempunyai beberapa kelebihan berbanding algoritma pembelajaran pengukuhan yang lain. Pertama, ia adalah lebih stabil, yang bermaksud bahawa berat sebelah kurang berkemungkinan berlaku semasa latihan. Kedua, ia lebih cekap, yang bermaksud ia boleh belajar lebih cepat. Ketiga, ia lebih berskala dan boleh digunakan untuk masalah dengan keadaan dan ruang tindakan yang besar
Jadual di bawah meringkaskan perbezaan utama antara Deep Q-learning dan Actor-Critic:

Kelebihan Actor Critic (A2C)
Actor-Critic ialah seni bina pembelajaran pengukuhan popular yang menggabungkan pendekatan berasaskan dasar dan berasaskan nilai. Ia mempunyai banyak kelebihan yang menjadikannya pilihan yang kukuh untuk menyelesaikan pelbagai tugasan pembelajaran pengukuhan:
1 varians rendah
Berbanding kaedah kecerunan dasar tradisional, A2C biasanya mempunyai prestasi yang lebih rendah semasa melatih varians. Ini kerana A2C menggunakan kedua-dua kecerunan dasar dan fungsi nilai, dan menggunakan fungsi nilai untuk mengurangkan varians dalam pengiraan kecerunan. Varians yang rendah bermakna proses latihan adalah lebih stabil dan boleh menumpu kepada dasar yang lebih baik dengan lebih cepat
2 Kelajuan pembelajaran yang lebih pantas
Disebabkan ciri-ciri varians yang rendah, A2C biasanya boleh mempelajari polisi pada kelajuan yang lebih cepat Baik. strategi. Ini amat penting untuk tugasan yang memerlukan simulasi yang meluas, kerana kelajuan pembelajaran yang lebih pantas menjimatkan masa dan sumber pengkomputeran yang berharga.
3. Menggabungkan fungsi dasar dan nilai
Ciri ketara A2C ialah ia mempelajari dasar dan fungsi nilai secara serentak. Gabungan ini membolehkan ejen memahami dengan lebih baik kaitan antara persekitaran dan tindakan, dengan itu membimbing penambahbaikan dasar dengan lebih baik. Kewujudan fungsi nilai juga membantu mengurangkan ralat dalam pengoptimuman dasar dan meningkatkan kecekapan latihan.
4. Menyokong ruang tindakan berterusan dan diskret
A2C boleh menyesuaikan diri dengan pelbagai jenis ruang tindakan, termasuk tindakan berterusan dan diskret, dan sangat serba boleh. Ini menjadikan A2C sebagai algoritma pembelajaran pengukuhan yang boleh digunakan secara meluas yang boleh digunakan untuk pelbagai tugas, daripada kawalan robot kepada pengoptimuman permainan
5. Latihan selari
A2C boleh diselaraskan dengan mudah untuk memanfaatkan sepenuhnya pelbagai teras pelayan pemprosesan dan sumber pengkomputeran yang diedarkan. Ini bermakna lebih banyak data empirikal boleh dikumpul dalam masa yang lebih singkat, sekali gus meningkatkan kecekapan latihan.
Walaupun kaedah Pelakon-Pengkritik mempunyai beberapa kelebihan, mereka juga menghadapi beberapa cabaran, seperti penalaan hiperparameter dan potensi ketidakstabilan dalam latihan. Walau bagaimanapun, dengan penalaan dan teknik yang sesuai seperti main semula pengalaman dan rangkaian sasaran, cabaran ini boleh dikurangkan sebahagian besarnya, menjadikan Actor-Critic kaedah yang berharga dalam pembelajaran pengukuhan
🎜
panda-gym
panda-gym dibangunkan berdasarkan enjin PyBullet dan merangkumi 6 tugasan seperti capaian, tolak, gelongsor, pilih&letak, susun, dan selak di sekeliling lengan robot panda. Ia diilhamkan terutamanya oleh OpenAI Fetch.
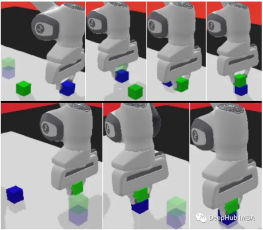
Kami akan menggunakan panda-gym sebagai contoh untuk menunjukkan kod di bawah
1. Pasang perpustakaan
Pertama, kita perlu mengukuhkan persekitaran untuk pembelajaran.
!apt-get install -y \libgl1-mesa-dev \libgl1-mesa-glx \libglew-dev \xvfb \libosmesa6-dev \software-properties-common \patchelf !pip install \free-mujoco-py \pytorch-lightning \optuna \pyvirtualdisplay \PyOpenGL \PyOpenGL-accelerate\stable-baselines3[extra] \gymnasium \huggingface_sb3 \huggingface_hub \ panda_gym
2. Import perpustakaanimport os import gymnasium as gym import panda_gym from huggingface_sb3 import load_from_hub, package_to_hub from stable_baselines3 import A2C from stable_baselines3.common.evaluation import evaluate_policy from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize from stable_baselines3.common.env_util import make_vec_env
3. Wujudkan persekitaran berjalanenv_id = "PandaReachDense-v3" # Create the env env = gym.make(env_id) # Get the state space and action space s_size = env.observation_space.shape a_size = env.action_space print("\n _____ACTION SPACE_____ \n") print("The Action Space is: ", a_size) print("Action Space Sample", env.action_space.sample()) # Take a random action
4. Kami mengira min berjalan dan sisihan piawai bagi ciri input melalui pembalut. Normalkan ganjaran dengan menambah norm_reward = Trueenv = make_vec_env(env_id, n_envs=4) env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
5 Cipta model A2C
Kami menggunakan ejen rasmi yang dilatih oleh pasukan Stable-Baselines3rreee
, Penilaian Ejenmodel = A2C(policy = "MultiInputPolicy",env = env,verbose=1)
Ringkasan
Dalam "panda-gym", gabungan berkesan lengan robotik Panda dan persekitaran GYM membolehkan kami melakukan pembelajaran pengukuhan lengan robotik secara tempatan dengan mudah,
Seni bina Aktor-Critik di mana ejen belajar membuat penambahbaikan tambahan pada setiap kali langkah berbeza dengan fungsi ganjaran yang jarang (yang hasilnya adalah binari), menjadikan kaedah Actor-Critic amat sesuai untuk jenis tugasan ini.
Dengan menggabungkan pembelajaran dasar dan anggaran nilai dengan lancar, ejen robot dapat memanipulasi pengesan hujung lengan robotik dengan mahir dan mencapai kedudukan sasaran yang ditentukan dengan tepat. Ini bukan sahaja menyediakan penyelesaian praktikal untuk tugas seperti kawalan robot, tetapi juga berpotensi untuk mengubah pelbagai bidang yang memerlukan pembuatan keputusan yang tangkas dan bermaklumat
Atas ialah kandungan terperinci Pembelajaran pengukuhan Q-pembelajaran mendalam menggunakan simulasi lengan robot Panda-Gym. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajariApr 13, 2025 am 01:14 AM
10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajariApr 13, 2025 am 01:14 AMHei ada, pengekodan ninja! Apa tugas yang berkaitan dengan pengekodan yang anda telah merancang untuk hari itu? Sebelum anda menyelam lebih jauh ke dalam blog ini, saya ingin anda memikirkan semua kesengsaraan yang berkaitan dengan pengekodan anda-lebih jauh menyenaraikan mereka. Selesai? - Let ’
 Memasak Inovasi: Bagaimana Kecerdasan Buatan Mengubah Perkhidmatan MakananApr 12, 2025 pm 12:09 PM
Memasak Inovasi: Bagaimana Kecerdasan Buatan Mengubah Perkhidmatan MakananApr 12, 2025 pm 12:09 PMAI Menambah Penyediaan Makanan Walaupun masih dalam penggunaan baru, sistem AI semakin digunakan dalam penyediaan makanan. Robot yang didorong oleh AI digunakan di dapur untuk mengautomasikan tugas penyediaan makanan, seperti membuang burger, membuat pizza, atau memasang SA
 Panduan Komprehensif mengenai Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PM
Panduan Komprehensif mengenai Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PMPengenalan Memahami ruang nama, skop, dan tingkah laku pembolehubah dalam fungsi Python adalah penting untuk menulis dengan cekap dan mengelakkan kesilapan runtime atau pengecualian. Dalam artikel ini, kami akan menyelidiki pelbagai ASP
 Panduan Komprehensif untuk Model Bahasa Visi (VLMS)Apr 12, 2025 am 11:58 AM
Panduan Komprehensif untuk Model Bahasa Visi (VLMS)Apr 12, 2025 am 11:58 AMPengenalan Bayangkan berjalan melalui galeri seni, dikelilingi oleh lukisan dan patung yang terang. Sekarang, bagaimana jika anda boleh bertanya setiap soalan dan mendapatkan jawapan yang bermakna? Anda mungkin bertanya, "Kisah apa yang anda ceritakan?
 MediaTek meningkatkan barisan premium dengan Kompanio Ultra dan Dimensity 9400Apr 12, 2025 am 11:52 AM
MediaTek meningkatkan barisan premium dengan Kompanio Ultra dan Dimensity 9400Apr 12, 2025 am 11:52 AMMeneruskan irama produk, bulan ini MediaTek telah membuat satu siri pengumuman, termasuk Kompanio Ultra dan Dimensity 9400 yang baru. Produk ini mengisi bahagian perniagaan MediaTek yang lebih tradisional, termasuk cip untuk telefon pintar
 Minggu ini di AI: Walmart menetapkan trend fesyen sebelum mereka pernah berlakuApr 12, 2025 am 11:51 AM
Minggu ini di AI: Walmart menetapkan trend fesyen sebelum mereka pernah berlakuApr 12, 2025 am 11:51 AM#1 Google melancarkan Agent2Agent Cerita: Ia Isnin pagi. Sebagai perekrut berkuasa AI, anda bekerja lebih pintar, tidak lebih sukar. Anda log masuk ke papan pemuka syarikat anda di telefon anda. Ia memberitahu anda tiga peranan kritikal telah diperolehi, dijadualkan, dan dijadualkan untuk
 AI Generatif Bertemu PsychobabbleApr 12, 2025 am 11:50 AM
AI Generatif Bertemu PsychobabbleApr 12, 2025 am 11:50 AMSaya akan meneka bahawa anda mesti. Kita semua seolah -olah tahu bahawa psychobabble terdiri daripada pelbagai perbualan yang menggabungkan pelbagai terminologi psikologi dan sering akhirnya menjadi tidak dapat difahami atau sepenuhnya tidak masuk akal. Semua yang anda perlu lakukan untuk memuntahkan fo
 Prototaip: saintis menjadikan kertas menjadi plastikApr 12, 2025 am 11:49 AM
Prototaip: saintis menjadikan kertas menjadi plastikApr 12, 2025 am 11:49 AMHanya 9.5% plastik yang dihasilkan pada tahun 2022 dibuat daripada bahan kitar semula, menurut satu kajian baru yang diterbitkan minggu ini. Sementara itu, plastik terus menumpuk di tapak pelupusan sampah -dan ekosistem -sekitar dunia. Tetapi bantuan sedang dalam perjalanan. Pasukan Engin


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Dreamweaver Mac版
Alat pembangunan web visual

