
 Peranti teknologiAILeCun sekali lagi memburukkan LLM autoregresif: Keupayaan penaakulan GPT-4 sangat terhad, seperti yang dibuktikan oleh dua kertas
Peranti teknologiAILeCun sekali lagi memburukkan LLM autoregresif: Keupayaan penaakulan GPT-4 sangat terhad, seperti yang dibuktikan oleh dua kertas
"Sesiapa yang berpendapat bahawa LLM auto-regresif sudah menghampiri AI peringkat manusia, atau ia hanya perlu meningkatkan untuk mencapai AI peringkat manusia, mesti membaca ini. Penaakulan dan perancangan AR-LLM keupayaan Sangat terhad. Untuk menyelesaikan masalah ini, ia tidak boleh diselesaikan dengan menjadikannya lebih besar dan berlatih dengan lebih banyak data # Pemenang Anugerah Turing Yann LeCun sentiasa menjadi "penyoal" LLM, dan model autoregresif ialah pembelajaran. paradigma yang bergantung kepada siri GPT model LLM. Beliau telah menyatakan secara terbuka kritikannya terhadap autoregresi dan LLM lebih daripada sekali, dan telah menghasilkan banyak ayat emas, seperti:
"Model Generatif Auto-Regresif menyebalkan!"
#🎜 🎜#"LLM mempunyai pemahaman yang sangat cetek tentang dunia."
"LLM benar-benar boleh mengkritik diri sendiri (dan berulang) seperti yang dikatakan oleh kesusasteraan Improve) penyelesaiannya? Dua kertas kerja baharu daripada kumpulan kami periksa dakwaan ini dalam tugas penaakulan (https://arxiv.org/abs/2310.12397) dan perancangan (https://arxiv.org/abs/2310.08118) yang disiasat (dan disoal "#🎜🎜 #
Nampaknya topik kedua-dua kertas kerja ini yang menyiasat keupayaan pengesahan dan kritikan diri GPT-4 telah menarik perhatian ramai.Pengarang kertas itu berkata bahawa mereka juga percaya bahawa LLM adalah "penjana idea" yang hebat (sama ada dalam bentuk bahasa atau kod), tetapi mereka tidak dapat menjamin mereka sendiri kemahiran merancang/ menaakul. Oleh itu, ia paling sesuai digunakan dalam persekitaran LLM-Modulo (sama ada penaakulan yang boleh dipercayai atau pakar manusia dalam gelung). Kritikan diri memerlukan pengesahan, dan pengesahan ialah satu bentuk penaakulan (jadi terkejut dengan semua dakwaan tentang keupayaan LLM untuk mengkritik diri).

Pada masa yang sama, keraguan juga wujud: "Keupayaan penaakulan rangkaian konvolusi adalah lebih terhad, tetapi ini tidak menghalang kerja AlphaZero daripada muncul. Ini semua tentang proses penaakulan dan gelung maklum balas yang mantap (RL) Saya fikir keupayaan model membolehkan inferens yang sangat mendalam (mis. Ini dilakukan melalui carian pokok Monte Carlo, menggunakan rangkaian konvolusi untuk menghasilkan tindakan yang baik dan rangkaian konvolusi lain untuk menilai kedudukan. Masa yang dihabiskan untuk meneroka pokok itu boleh menjadi tidak terhingga, itu semua penaakulan dan perancangan. "
Pada masa hadapan, topik sama ada LLM autoregresif mempunyai keupayaan penaakulan dan perancangan mungkin tidak dimuktamadkan.
Seterusnya, kita boleh lihat perkara yang dibincangkan oleh kedua-dua kertas kerja baharu ini.
Kertas 1: GPT-4 Tidak Tahu Ia Salah: Satu Analisis Terhadap Masalah Penaakulan Berulang#🎜🎜 🎜🎜#
Kertas pertama menyebabkan penyelidik mempersoalkan keupayaan mengkritik diri LLM yang paling maju, termasuk GPT-4. 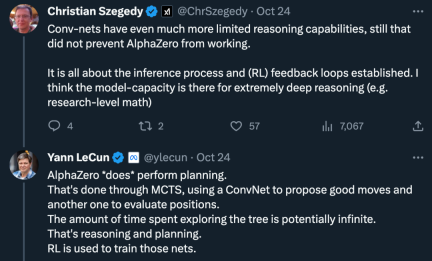
Alamat kertas: https://arxiv.org/pdf/2310.12397.pdf#🎜🎜 🎜#Seterusnya mari lihat pengenalan kertas kerja.
Selalu ada perselisihan pendapat tentang keupayaan inferens model bahasa besar (LLMs) Pada mulanya, penyelidik optimis bahawa keupayaan inferens LLM meningkat dengan saiz model. Penskalaan akan berlaku secara automatik, bagaimanapun, apabila lebih banyak kes kegagalan muncul, jangkaan menjadi kurang sengit. Selepas itu, penyelidik secara amnya percaya bahawa LLM mempunyai keupayaan untuk mengkritik sendiri dan menambah baik penyelesaian LLM secara berulang, dan pandangan ini telah disebarkan secara meluas.
Namun, adakah ini benar-benar berlaku?
Penyelidik dari Arizona State University menguji keupayaan penaakulan LLM dalam kajian baharu. Secara khusus, mereka menumpukan pada keberkesanan gesaan berulang dalam masalah pewarnaan graf, salah satu masalah lengkap NP yang paling terkenal.
Kajian ini menunjukkan bahawa (i) LLM tidak pandai menyelesaikan kejadian pewarnaan graf (ii) LLM tidak pandai mengesahkan penyelesaian dan oleh itu tidak berkesan dalam mod lelaran. Hasil kertas kerja ini menimbulkan persoalan tentang keupayaan kritikal diri LLM yang canggih. . Lebih teruk lagi, sistem gagal mengenali warna yang betul dan berakhir dengan warna yang salah.
Rajah di bawah ialah penilaian masalah pewarnaan graf Dalam tetapan ini, GPT-4 boleh meneka warna dalam mod bebas dan kritikal kendiri. Di luar gelung kritikal diri terdapat pengesah suara luaran.
Hasilnya menunjukkan bahawa GPT4 kurang daripada 20% tepat pada meneka warna, dan lebih mengejutkan, mod kritikan diri (lajur kedua dalam rajah di bawah) mempunyai ketepatan yang paling rendah. Makalah ini juga mengkaji persoalan berkaitan sama ada GPT-4 akan menambah baik penyelesaiannya jika pengesah vokal luaran memberikan kritikan yang terbukti betul terhadap warna yang diduganya. Dalam kes ini, pembayang terbalik benar-benar boleh meningkatkan prestasi. 
Walaupun GPT-4 secara tidak sengaja meneka warna yang sah, kritikan kendirinya mungkin menyebabkan ia berhalusinasi bahawa tiada pelanggaran. Secara kebetulan, penulis memberikan ringkasan, mengenai masalah pewarna graf: 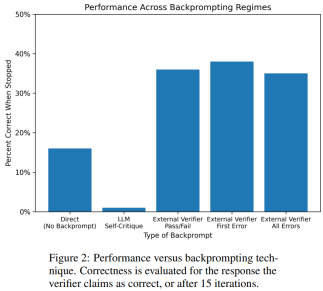
diri-kritikan sebenarnya akan membahayakan prestasi LLM, kerana GPT-4 adalah mengerikan pada pengesahan; Maklum balas Pengesah luar sememangnya boleh meningkatkan prestasi LLM. . pasukan Keupayaan LLM untuk mengesahkan/mengkritik sendiri dalam situasi perancangan telah diterokai.

- Alamat kertas: https://arxiv.org/abs/2310.08118
- Anehnya, hasil penyelidikan menunjukkan bahawa kritikan kendiri boleh mengurangkan prestasi penjanaan pengesahan pelan, terutamanya dengan LLM penjanaan pengesahan pelan. sistem pengesah. LLM boleh menghasilkan sejumlah besar mesej ralat, dengan itu menjejaskan kebolehpercayaan sistem.
Penilaian empirikal penyelidik terhadap domain perancangan AI klasik Blocksworld menyerlahkan bahawa fungsi kritikan kendiri LLM tidak berkesan dalam merancang masalah. Pengesah boleh menghasilkan sejumlah besar ralat, yang memudaratkan kebolehpercayaan keseluruhan sistem, terutamanya di kawasan di mana ketepatan perancangan adalah kritikal. Menariknya, sifat maklum balas (maklum balas binari atau terperinci) tidak mempunyai kesan ketara ke atas prestasi penjanaan rancangan, menunjukkan bahawa isu teras terletak pada keupayaan pengesahan binari LLM dan bukannya butiran maklum balas.
Seperti yang ditunjukkan dalam rajah di bawah, seni bina penilaian kajian ini merangkumi 2 LLM - penjana LLM + pengesah LLM. Untuk contoh tertentu, penjana LLM bertanggungjawab menjana pelan calon, manakala pengesah LLM menentukan ketepatannya. Jika rancangan didapati tidak betul, pengesah memberikan maklum balas yang memberi sebab kesilapannya. Maklum balas ini kemudiannya dipindahkan ke penjana LLM, yang menggesa penjana LLM untuk menjana pelan calon baharu. Semua eksperimen dalam kajian ini menggunakan GPT-4 sebagai LLM lalai.

Kajian ini menguji dan membandingkan beberapa kaedah penjanaan pelan di Blocksworld. Secara khusus, kajian ini menghasilkan 100 contoh rawak untuk penilaian pelbagai kaedah. Untuk memberikan penilaian yang realistik tentang ketepatan perancangan LLM akhir, kajian ini menggunakan pengesah luaran VAL.
Seperti yang ditunjukkan dalam Jadual 1, kaedah backprompt LLM+LLM adalah lebih baik sedikit daripada kaedah bukan backprompt dari segi ketepatan.

Daripada 100 kejadian, pengesah mengenal pasti 61 (61%) dengan tepat.
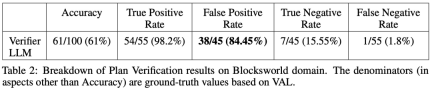
Jadual di bawah menunjukkan prestasi LLM apabila menerima tahap maklum balas yang berbeza (termasuk tiada maklum balas).

Atas ialah kandungan terperinci LeCun sekali lagi memburukkan LLM autoregresif: Keupayaan penaakulan GPT-4 sangat terhad, seperti yang dibuktikan oleh dua kertas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Apakah graf pemikiran dalam kejuruteraan segeraApr 13, 2025 am 11:53 AM
Apakah graf pemikiran dalam kejuruteraan segeraApr 13, 2025 am 11:53 AMPengenalan Dalam kejuruteraan segera, "Grafik Pemikiran" merujuk kepada pendekatan baru yang menggunakan teori graf untuk struktur dan membimbing proses penalaran AI. Tidak seperti kaedah tradisional, yang sering melibatkan linear
 Mengoptimumkan pemasaran e -mel organisasi anda dengan agen genaiApr 13, 2025 am 11:44 AM
Mengoptimumkan pemasaran e -mel organisasi anda dengan agen genaiApr 13, 2025 am 11:44 AMPengenalan Tahniah! Anda menjalankan perniagaan yang berjaya. Melalui laman web anda, kempen media sosial, webinar, persidangan, sumber percuma, dan sumber lain, anda mengumpul 5000 ID e -mel setiap hari. Langkah jelas seterusnya adalah
 Pemantauan Prestasi Aplikasi Masa Nyata dengan Apache PinotApr 13, 2025 am 11:40 AM
Pemantauan Prestasi Aplikasi Masa Nyata dengan Apache PinotApr 13, 2025 am 11:40 AMPengenalan Dalam persekitaran pembangunan perisian pantas hari ini, memastikan prestasi aplikasi yang optimum adalah penting. Memantau metrik masa nyata seperti masa tindak balas, kadar ralat, dan penggunaan sumber dapat membantu utama
 Chatgpt mencecah 1 bilion pengguna? 'Dua kali ganda dalam beberapa minggu' kata Ketua Pegawai Eksekutif OpenaiApr 13, 2025 am 11:23 AM
Chatgpt mencecah 1 bilion pengguna? 'Dua kali ganda dalam beberapa minggu' kata Ketua Pegawai Eksekutif OpenaiApr 13, 2025 am 11:23 AM"Berapa banyak pengguna yang anda ada?" Dia ditakdirkan. "Saya fikir kali terakhir yang kami katakan ialah 500 juta aktif mingguan, dan ia berkembang dengan pesat," jawab Altman. "Anda memberitahu saya bahawa ia seperti dua kali ganda dalam beberapa minggu sahaja," kata Anderson. "Saya mengatakan bahawa priv
 Pixtral -12b: Model Multimodal Pertama Mistral Ai 'Apr 13, 2025 am 11:20 AM
Pixtral -12b: Model Multimodal Pertama Mistral Ai 'Apr 13, 2025 am 11:20 AMPengenalan Mistral telah mengeluarkan model multimodal yang pertama, iaitu Pixtral-12B-2409. Model ini dibina atas parameter 12 bilion Mistral, NEMO 12B. Apa yang membezakan model ini? Ia kini boleh mengambil kedua -dua gambar dan Tex
 Rangka Kerja Agentik untuk Aplikasi AI Generatif - Analytics VidhyaApr 13, 2025 am 11:13 AM
Rangka Kerja Agentik untuk Aplikasi AI Generatif - Analytics VidhyaApr 13, 2025 am 11:13 AMBayangkan mempunyai pembantu berkuasa AI yang bukan sahaja memberi respons kepada pertanyaan anda tetapi juga mengumpulkan maklumat, melaksanakan tugas, dan juga mengendalikan pelbagai jenis teks, imej, dan kod. Bunyi futuristik? Dalam ini a
 Aplikasi AI Generatif di Sektor KewanganApr 13, 2025 am 11:12 AM
Aplikasi AI Generatif di Sektor KewanganApr 13, 2025 am 11:12 AMPengenalan Industri kewangan adalah asas kepada mana -mana pembangunan negara, kerana ia memacu pertumbuhan ekonomi dengan memudahkan urus niaga yang cekap dan ketersediaan kredit. The ease with which transactions occur and credit
 Panduan untuk pembelajaran dalam talian dan algoritma pasif-agresifApr 13, 2025 am 11:09 AM
Panduan untuk pembelajaran dalam talian dan algoritma pasif-agresifApr 13, 2025 am 11:09 AMPengenalan Data dijana pada kadar yang belum pernah terjadi sebelumnya dari sumber seperti media sosial, urus niaga kewangan, dan platform e-dagang. Mengendalikan aliran maklumat yang berterusan ini adalah satu cabaran, tetapi ia menawarkan


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Dreamweaver Mac版
Alat pembangunan web visual

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

