
Rumah >Peranti teknologi >AI >Bolehkah GPU anda menjalankan model besar seperti Llama 2? Cubalah dengan projek sumber terbuka ini
Bolehkah GPU anda menjalankan model besar seperti Llama 2? Cubalah dengan projek sumber terbuka ini

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-10-23 14:29:011533semak imbas
Dalam era kuasa pengkomputeran adalah raja, bolehkah GPU anda menjalankan model besar (LLM) dengan lancar?
Ramai orang mengalami kesukaran untuk memberikan jawapan yang tepat kepada soalan ini dan tidak tahu cara mengira memori GPU. Kerana melihat LLM yang boleh dikendalikan oleh GPU tidak semudah melihat saiz model, model boleh mengambil banyak memori semasa inferens (cache KV), cth. llama-2-7b mempunyai panjang jujukan 1000 dan memerlukan 1GB ingatan tambahan. Bukan itu sahaja, semasa latihan model, cache KV, pengaktifan dan kuantisasi akan menduduki banyak memori.
Kami tidak boleh tidak tertanya-tanya sama ada kami boleh mengetahui penggunaan memori di atas lebih awal. Dalam beberapa hari kebelakangan ini, projek baharu telah muncul di GitHub, yang boleh membantu anda mengira jumlah memori GPU yang diperlukan semasa latihan atau inferens LLM Bukan itu sahaja, dengan bantuan projek ini, anda juga boleh mengetahui pengedaran memori terperinci dan kaedah penilaian, panjang konteks maksimum diproses dan isu lain untuk membantu pengguna memilih konfigurasi GPU yang sesuai dengan mereka.
Alamat projek: https://github.com/RahulSChand/gpu_poor
Bukan itu sahaja, projek ini juga interaktif, seperti yang ditunjukkan di bawah, ia boleh mengira memori GPU yang diperlukan untuk menjalankan LLM , semudah mengisi tempat kosong, pengguna hanya perlu memasukkan beberapa parameter yang diperlukan, dan akhirnya klik butang biru, dan jawapan akan keluar. . pengarang Rahul Shiv Chand berkata bahawa terdapat sebab berikut:
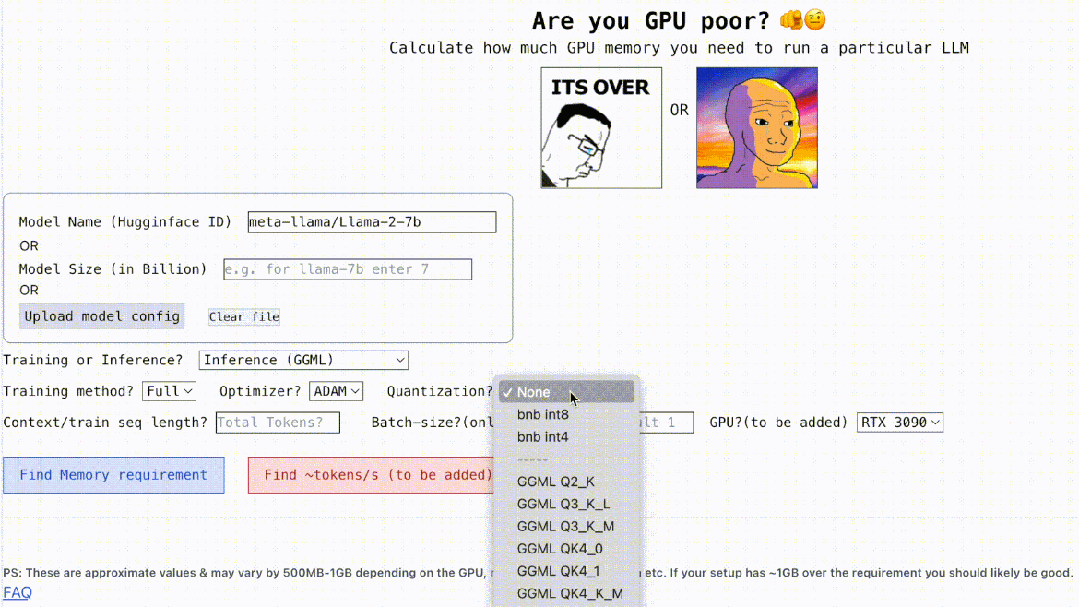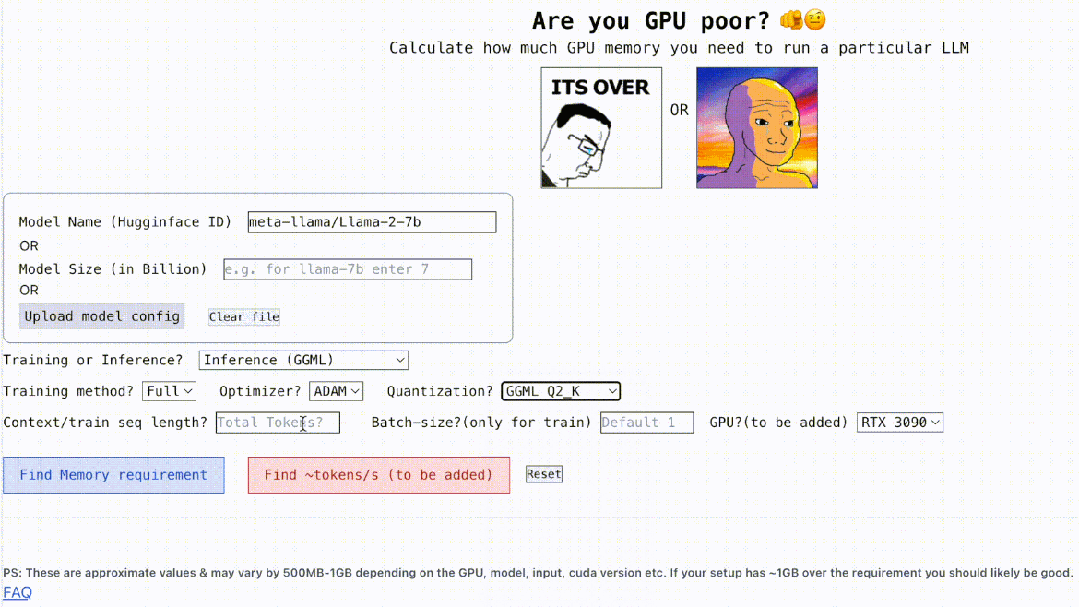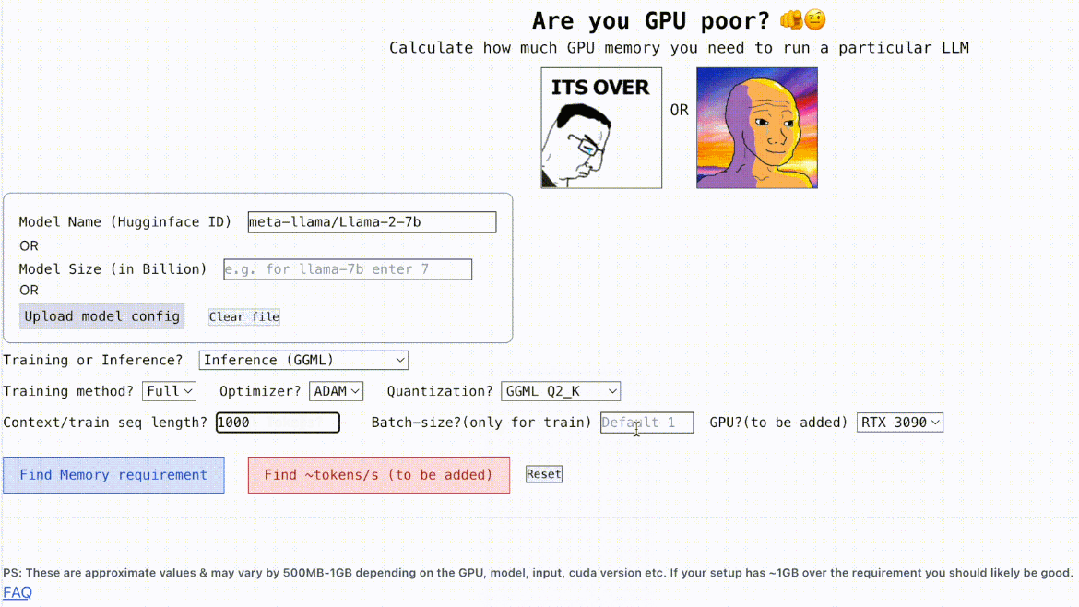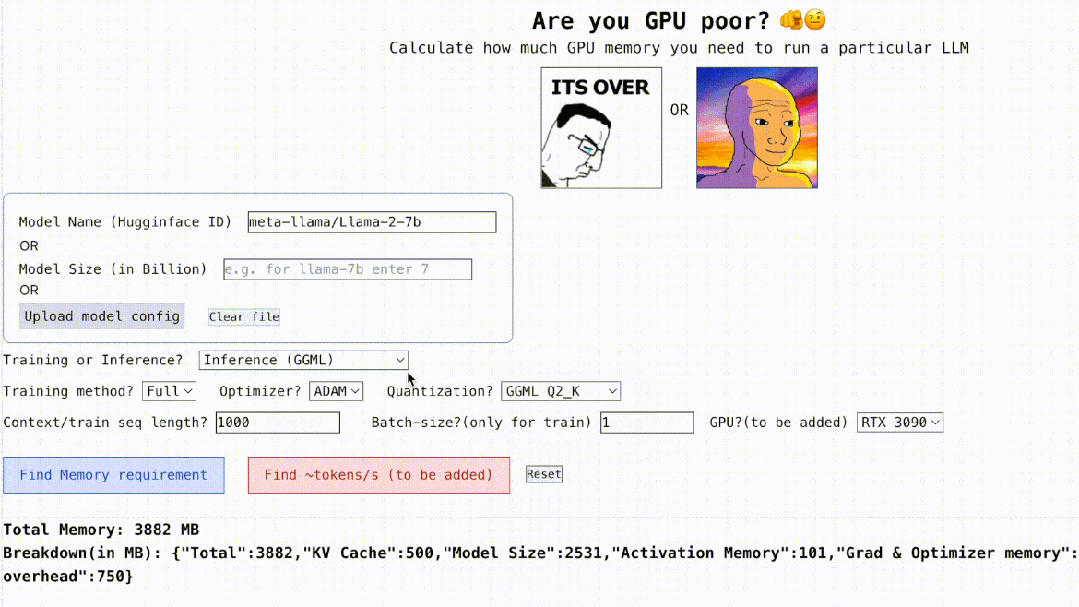
Berapa panjang konteks maksimum yang boleh dikendalikan oleh GPU;
Apakah jenis Kaedah penalaan halus manakah yang lebih sesuai untuk anda? Penuh? Atau QLoRA?
Apakah kumpulan maksimum yang boleh digunakan semasa penalaan halus?
- Jadi, bagaimana cara kita menggunakannya?
- Langkah pertama ialah memproses nama model, ID dan saiz model. Anda boleh memasukkan ID model pada Huggingface (cth. meta-llama/Llama-2-7b). Pada masa ini, projek itu mempunyai konfigurasi model yang dikod keras dan disimpan untuk 3000 LLM teratas yang paling banyak dimuat turun di Huggingface.
- Jika anda menggunakan model tersuai atau ID Hugginface tidak tersedia, maka anda perlu memuat naik konfigurasi json (rujuk contoh projek) atau masukkan sahaja saiz model (contohnya, llama-2-7b ialah 7 bilion ).
- Kemudian datang pengkuantitian, pada masa ini projek menyokong bitsandbytes (bnb) int8/int4 dan GGML (QK_8, QK_6, QK_5, QK_4, QK_2). Yang terakhir hanya digunakan untuk inferens, manakala bnb int8/int4 boleh digunakan untuk kedua-dua latihan dan inferens.
- Langkah terakhir ialah inferens dan latihan Semasa proses inferens, gunakan pelaksanaan HuggingFace atau gunakan kaedah vLLM atau GGML untuk mencari vRAM yang digunakan untuk inferens semasa proses latihan, cari vRAM untuk penalaan halus atau penggunaan model penuh LoRA (projek semasa telah dikod keras konfigurasi LoRA r=8), QLoRA untuk penalaan halus.
Walau bagaimanapun, pengarang projek menyatakan bahawa keputusan akhir mungkin berbeza-beza bergantung pada model pengguna, data input, versi CUDA, alat kuantifikasi, dll. Dalam percubaan, penulis cuba mengambil kira faktor-faktor ini dan memastikan keputusan akhir berada dalam lingkungan 500MB. Jadual di bawah adalah tempat pengarang menyemak silang penggunaan memori model 3b, 7b dan 13b yang disediakan di tapak web berbanding dengan apa yang penulis perolehi pada GPU RTX 4090 dan 2060. Semua nilai berada dalam 500MB. .
Atas ialah kandungan terperinci Bolehkah GPU anda menjalankan model besar seperti Llama 2? Cubalah dengan projek sumber terbuka ini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!