
Rumah >Peranti teknologi >AI >Universiti Stanford mengeluarkan indeks ketelusan model asas AI, Llama 2 menduduki tempat pertama tetapi 'gagal'
Universiti Stanford mengeluarkan indeks ketelusan model asas AI, Llama 2 menduduki tempat pertama tetapi 'gagal'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-10-21 08:17:01917semak imbas
Berita Utama IT pada 20 Oktober, Universiti Stanford baru-baru ini mengeluarkan "Indeks Ketelusan" model asas AI Indeks yang paling tinggi dipaparkan ialah Meta's Lama 2, tetapi "ketelusan" yang berkaitan hanya 54%, jadi penyelidik. Dia percaya bahawa hampir semua model AI di pasaran "tidak mempunyai ketelusan."
Dilaporkan bahawa penyelidikan ini diketuai oleh Rishi Bommasani, ketua Pusat Penyelidikan Model Asas (CRFM) HAI, dan menyiasat 10 model asas paling popular di luar negara:
- Meta’s Llama 2,
- BigScience’s BloomZ,
- GPT-4 OpenAI,
- Resapan Stabil AI Kestabilan,
- Anthropic PBC’s Claude,
- Google’s PaLM 2,
- Arahan Cohere,
- AI21 Labs’ Jurassic-2,
- Infleksi AI's Inflection,
- Titan Amazon.
Rishi Bommasani percaya bahawa "kekurangan ketelusan" sentiasa menjadi masalah yang dihadapi oleh industri AI Dari segi "penunjuk ketelusan" model tertentu, IT House mendapati bahawa kandungan penilaian yang berkaitan terutamanya berkisar pada "latihan model. hak cipta set data", "latihan "Sumber pengkomputeran yang digunakan oleh model", "Kredibiliti kandungan yang dihasilkan oleh model", "Keupayaan model itu sendiri", "Risiko model terdorong untuk menjana kandungan berbahaya", "Privasi pengguna menggunakan model", dsb. telah dikembangkan, dengan jumlah 100 item.
Tinjauan akhir menunjukkan bahawa Meta Lama 2 mendahului senarai dengan 54% ketelusan, manakala OpenAI GPT-4 hanya mempunyai 48% ketelusan, dan Google PaLM 2 menduduki tempat kelima dengan 40%.
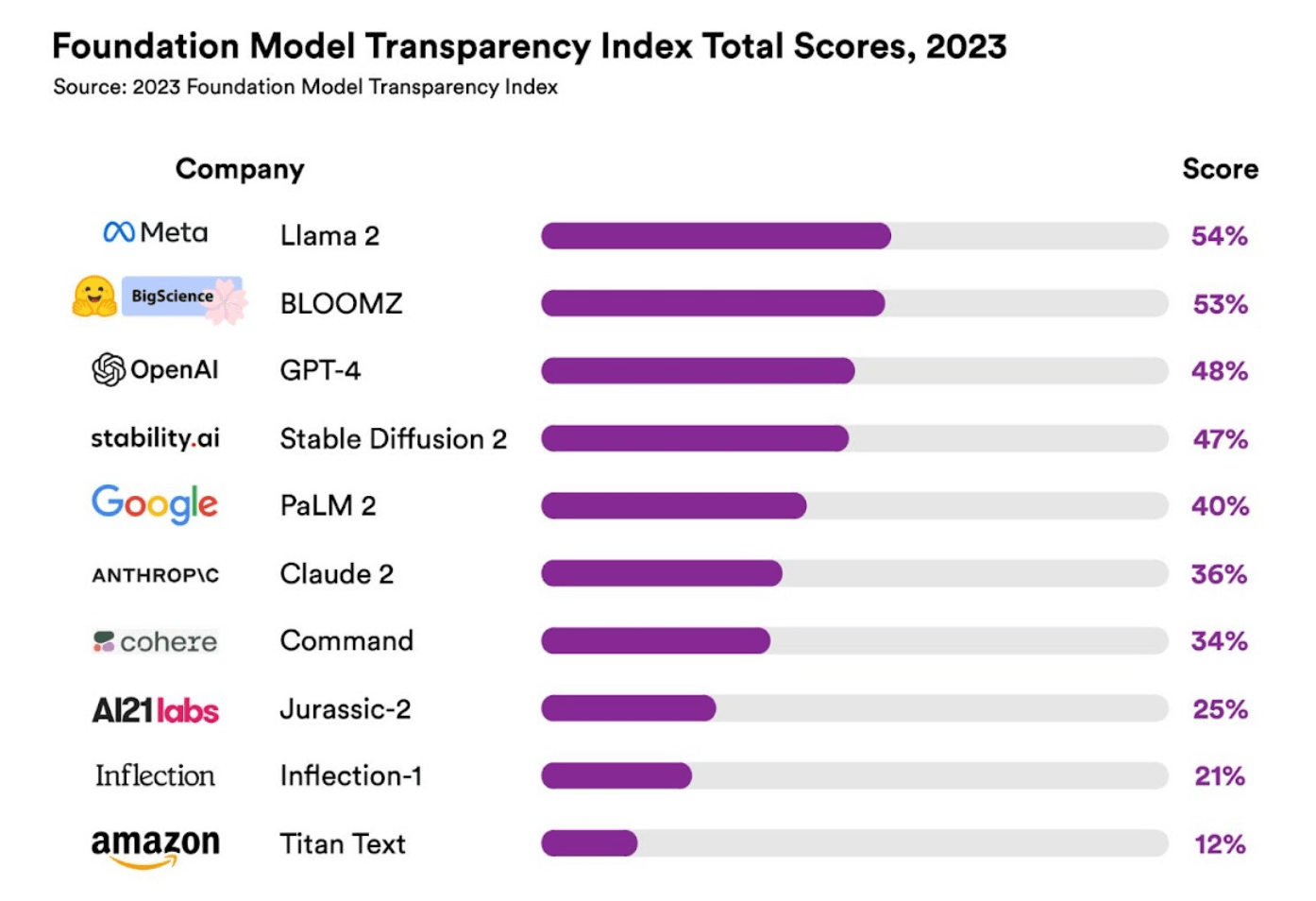
▲ Sumber gambar Universiti Stanford
Antara penunjuk khusus, sepuluh model teratas dengan prestasi skor "terbaik" ialah "Asas Model". Kandungan penilaian ini terutamanya termasuk "sama ada model dan skala model diperkenalkan dengan tepat semasa latihan model." ” dengan purata ketelusan 63%. Prestasi paling teruk ialah Impact, yang menilai terutamanya sama ada model asas akan "mendapatkan semula maklumat pengguna untuk penilaian", dengan purata ketelusan hanya 11%.
#🎜🎜 #Pengarah CRFM Percy Liang berkata bahawa "ketelusan" model asas perniagaan adalah sangat penting untuk mempromosikan perundangan AI, serta industri dan akademik yang berkaitan.Rishi Bommasani berkata bahawa ketelusan model yang lebih rendah menjadikannya lebih sukar bagi syarikat untuk mengetahui sama ada mereka boleh bergantung pada model yang berkaitan dengan selamat dan untuk penyelidik bergantung pada model ini untuk melakukan penyelidikan.
Rishi Bommasani akhirnya percaya bahawa sepuluh model asas di atas semuanya "gagal" dari segi ketelusan Walaupun Meta's Llama 2 mempunyai skor tertinggi, ia tidak dapat memenuhi keperluan dunia luar "Ketelusan model itu mesti dicapai sekurang-kurangnya 82% sebelum boleh digunakan oleh dunia luar." Diiktiraf".
Atas ialah kandungan terperinci Universiti Stanford mengeluarkan indeks ketelusan model asas AI, Llama 2 menduduki tempat pertama tetapi 'gagal'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI