
Rumah >Peranti teknologi >AI >Amalkan dan fikirkan platform model besar berbilang modal Jiuzhang Yunji DataCanvas
Amalkan dan fikirkan platform model besar berbilang modal Jiuzhang Yunji DataCanvas

- 王林ke hadapan
- 2023-10-20 08:45:011564semak imbas
. menjadi permulaan kecerdasan buatan, dan peserta terutamanya adalah perintis logik simbolik (kecuali ahli neurobiologi Peter Milner di tengah-tengah barisan hadapan).

Walau bagaimanapun, teori logik simbolik ini tidak dapat direalisasikan untuk masa yang lama, malah tempoh musim sejuk AI yang pertama datang pada tahun 1980-an dan 1990-an. Sehingga pelaksanaan model bahasa besar baru-baru ini, kami mendapati bahawa rangkaian saraf benar-benar membawa pemikiran logik ini. Kerja ahli neurobiologi Peter Milner memberi inspirasi kepada pembangunan rangkaian saraf tiruan kemudiannya, dan atas sebab inilah dia dijemput untuk mengambil bahagian. dalam seminar akademik ini.

Pada tahun 2012, pengarah memandu sendiri Tesla Andrew menyiarkan gambar di atas di blognya, menunjukkan Presiden AS ketika itu Obama bergurau dengan orang bawahannya. Untuk kecerdasan buatan memahami gambar ini, ia bukan sahaja tugas persepsi visual, kerana selain mengenal pasti objek, ia juga perlu memahami hubungan antara mereka hanya dengan mengetahui prinsip fizikal skala kita boleh mengetahui cerita yang diterangkan dalam gambar: Obama pijak Lelaki di atas penimbang itu bertambah berat, menyebabkan dia membuat ekspresi pelik ini manakala yang lain ketawa. Pemikiran logik sedemikian jelas telah melampaui skop persepsi visual yang tulen Oleh itu, kognisi visual dan pemikiran logik mesti digabungkan untuk menghilangkan rasa malu "terencat akal buatan" Kepentingan dan kesukaran model besar berbilang modal ia adalah.
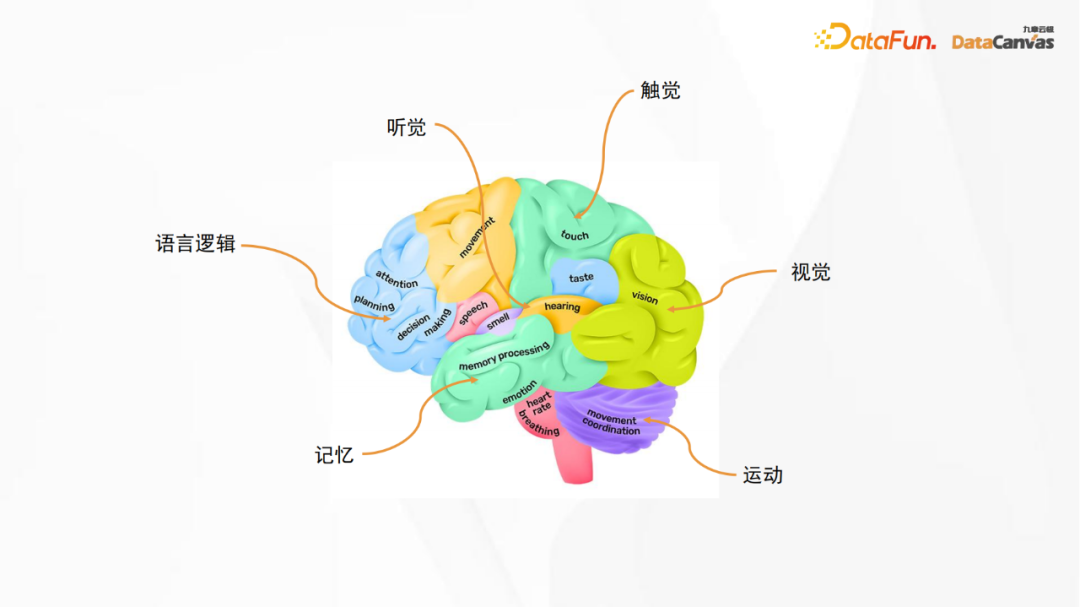
Gambar di atas adalah gambar rajah struktur anatomi otak manusia Kawasan logik bahasa dalam gambar sepadan dengan model bahasa yang besar, manakala kawasan lain sepadan dengan deria yang berbeza, termasuk penglihatan, pendengaran, sentuhan, dan. pergerakan, ingatan, dll. Walaupun rangkaian saraf tiruan bukanlah rangkaian saraf otak dalam erti kata sebenar, kita masih boleh mendapat inspirasi daripadanya, iaitu, apabila membina model besar, fungsi yang berbeza boleh digabungkan bersama. Ini juga merupakan idea asas pembinaan model pelbagai modal.

1. Apa yang boleh dilakukan oleh model besar berbilang modal?
Model besar berbilang modal boleh melakukan banyak perkara untuk kita, seperti pemahaman video model besar boleh membantu kami meringkaskan ringkasan dan maklumat penting video, dengan itu menjimatkan masa menonton video yang besar juga boleh membantu kami Menjalankan analisis pasca video, seperti klasifikasi program, statistik penilaian program, dsb. Selain itu, graf Vincentian juga merupakan bidang aplikasi penting bagi model besar berbilang modal.
Jika model besar digabungkan dengan pergerakan manusia atau robot, kecerdasan yang diwujudkan akan dijana, sama seperti seseorang, kaedah merancang laluan terbaik berdasarkan pengalaman lepas akan diterapkan pada model baru senario, selesaikan beberapa masalah yang belum pernah dihadapi sebelum ini sambil mengelakkan risiko; anda juga boleh mengubah suai pelan asal semasa proses pelaksanaan sehingga anda akhirnya mencapai kejayaan. Ini juga merupakan senario aplikasi dengan prospek yang luas.
2. Model besar berbilang modal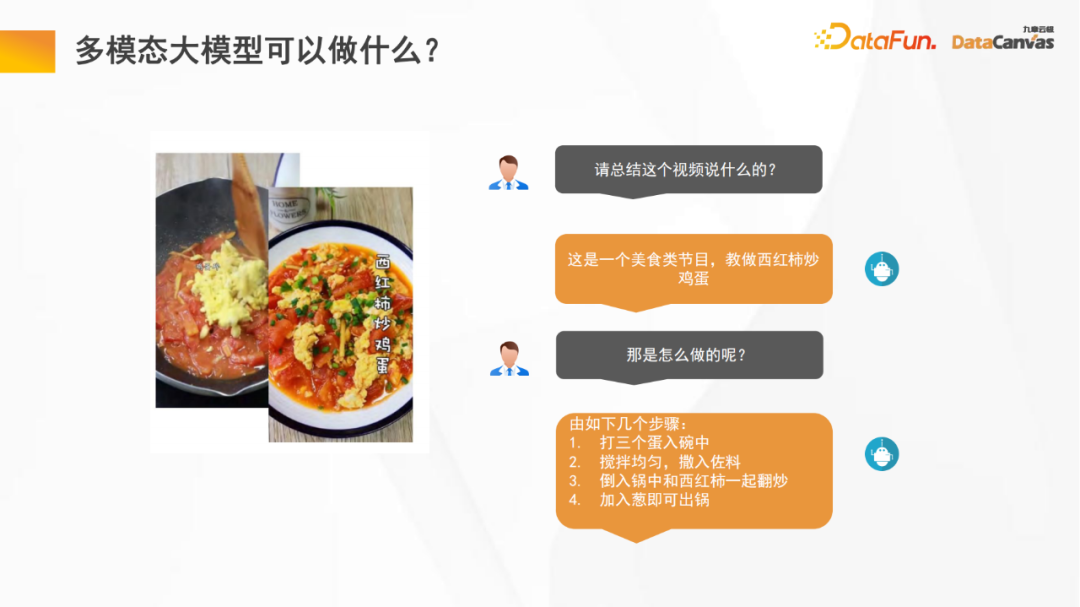
Gambar di atas menunjukkan beberapa nod penting dalam proses pembangunan model besar berbilang modal:
- Model ViT 2020 (Vision Transformer) adalah permulaan kepada model besar Buat pertama kalinya, seni bina Transformer digunakan untuk jenis data lain (data visual) sebagai tambahan kepada pemprosesan bahasa dan logik, dan ia menunjukkan. keupayaan generalisasi yang baik;
- Kemudian melalui model CLIP sumber terbuka OpenAI, sekali lagi terbukti bahawa melalui penggunaan ViT dan model bahasa yang besar, tugas visual mencapai keupayaan generalisasi ekor panjang yang kuat, iaitu, membuat kesimpulan kategori yang sebelum ini tidak kelihatan melalui akal
- Menjelang 2023, pelbagai model besar berbilang modal akan muncul secara beransur-ansur, daripada PaLM-E (robot), kepada bisikan (pengecaman pertuturan), kepada ImageBind (penjajaran imej), kepada Sam ( pembahagian semantik) ), dan akhirnya kepada imej geografi juga termasuk seni bina berbilang modal bersatu Microsoft Kosmos2, model besar berbilang modal sedang berkembang pesat.
- Tesla juga mencadangkan visi model dunia universal di CVPR pada bulan Jun.
Seperti yang anda lihat dari gambar di atas, dalam masa setengah tahun sahaja, banyak perubahan telah berlaku dalam model besar, dan kelajuan lelarannya sangat pantas.
3. Seni bina penjajaran modal
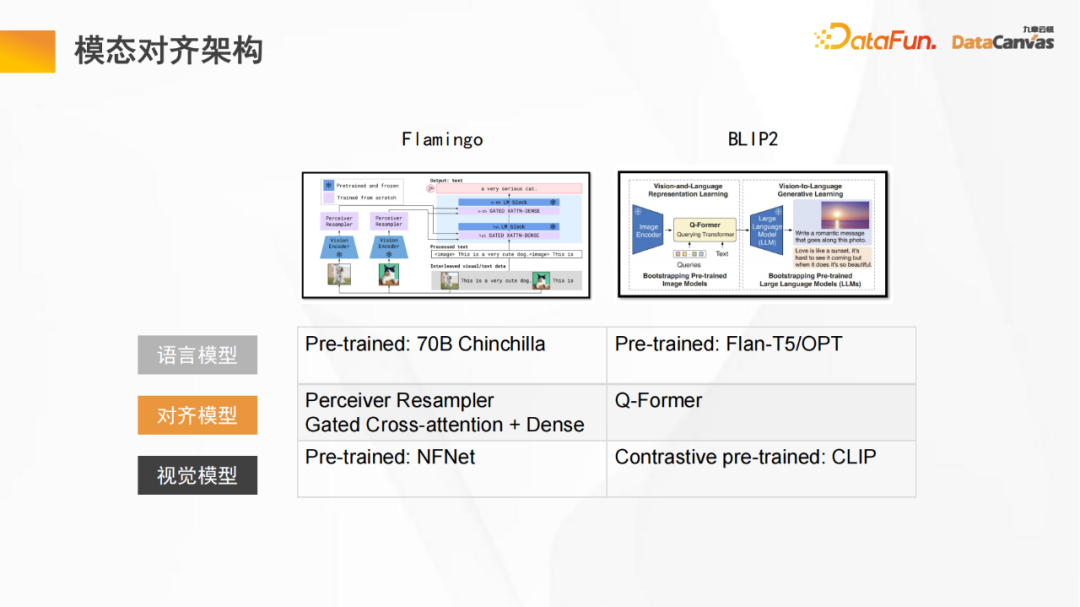
Gambar di atas ialah gambar rajah seni bina umum model berbilang modal yang besar, termasuk model bahasa dan model visual, melalui model bahasa tetap dan model visual tetap. Belajar menjajarkan model adalah untuk menggabungkan ruang vektor model visual dan ruang vektor model bahasa, dan kemudian melengkapkan pemahaman hubungan logik dalaman antara kedua-duanya dalam ruang vektor bersatu.
Kedua-dua model Flamingo dan model BLIP2 yang ditunjukkan dalam gambar menggunakan struktur yang sama (model Flamingo menggunakan seni bina Perceiver, manakala model BLIP2 menggunakan versi seni bina Transformer yang dipertingkatkan); melalui pelbagai kaedah pembelajaran kontras Sebilangan besar token digunakan untuk sejumlah besar pembelajaran untuk mendapatkan kesan penjajaran yang lebih baik, akhirnya, model diperhalusi mengikut tugasan tertentu.
2. Platform model besar berbilang mod Jiuzhang Yunji DataCanvas
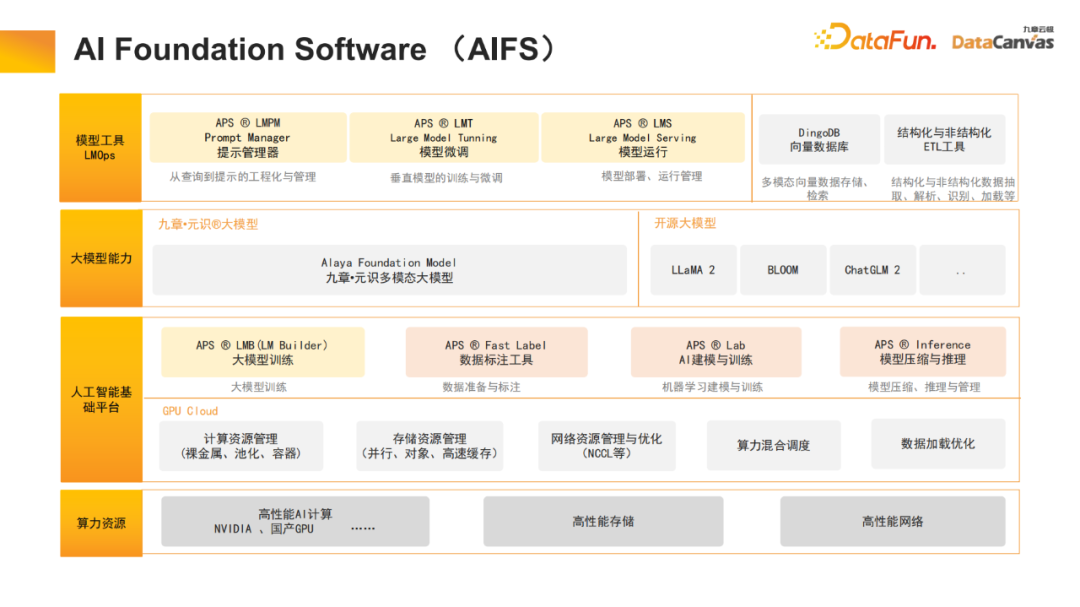
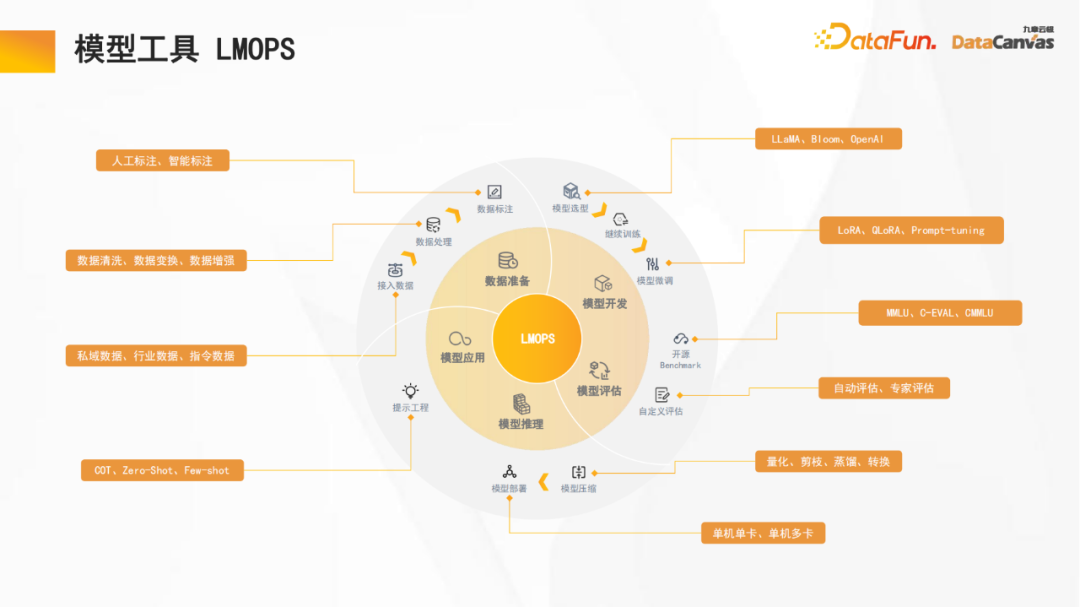
1. Perisian Yayasan AI (AIFS)
Jiuzhang Yunji DataCanvas juga menyediakan sumber asas pengkomputeran manusia dan sumber kecerdasan buatan. Kelompok GPU) digunakan untuk melaksanakan storan berprestasi tinggi dan pengoptimuman rangkaian Atas dasar ini, alat latihan model besar disediakan, termasuk kotak pasir eksperimen pemodelan anotasi, dsb. Jiuzhang Yunji DataCanvas bukan sahaja menyokong model besar sumber terbuka biasa di pasaran, tetapi juga membangunkan model besar berbilang modal Yuanshi secara bebas. Pada lapisan aplikasi, alatan disediakan untuk mengurus perkataan segera, memperhalusi model dan menyediakan mekanisme operasi dan penyelenggaraan model. Pada masa yang sama, pangkalan data vektor berbilang modal juga sumber terbuka untuk memperkayakan seni bina perisian asas. . penilaian (termasuk penilaian mendatar dan penilaian menegak), penaakulan model (kuantifikasi model sokongan, penyulingan pengetahuan dan mekanisme penaakulan dipercepatkan lain), aplikasi model, dsb.
 3. LMB – Pembina Model Besar
3. LMB – Pembina Model Besar
 Semasa membina model, banyak kerja pengoptimuman yang diedarkan dan cekap telah dijalankan, termasuk selari data, selari Tensor, saluran paip dll. Tugas pengoptimuman yang diedarkan ini diselesaikan dengan satu klik dan menyokong kawalan visual, yang boleh mengurangkan kos buruh dan meningkatkan kecekapan pembangunan.
Semasa membina model, banyak kerja pengoptimuman yang diedarkan dan cekap telah dijalankan, termasuk selari data, selari Tensor, saluran paip dll. Tugas pengoptimuman yang diedarkan ini diselesaikan dengan satu klik dan menyokong kawalan visual, yang boleh mengurangkan kos buruh dan meningkatkan kecekapan pembangunan.
4、LMB –Pembina Model Besar
Penalaan model besar juga telah dioptimumkan, termasuk latihan berterusan biasa, penalaan penyelia dan maklum balas manusia dalam pembelajaran pengukuhan. Di samping itu, banyak pengoptimuman telah dibuat untuk bahasa Cina, seperti pengembangan automatik perbendaharaan kata bahasa Cina. Oleh kerana banyak perkataan Cina tidak disertakan dalam model sumber terbuka yang besar, perkataan ini mungkin dibahagikan kepada berbilang token dengan mengembangkan perkataan ini secara automatik boleh membolehkan model menggunakan perkataan ini dengan lebih baik.
5. LMS – Penyajian Model Besar
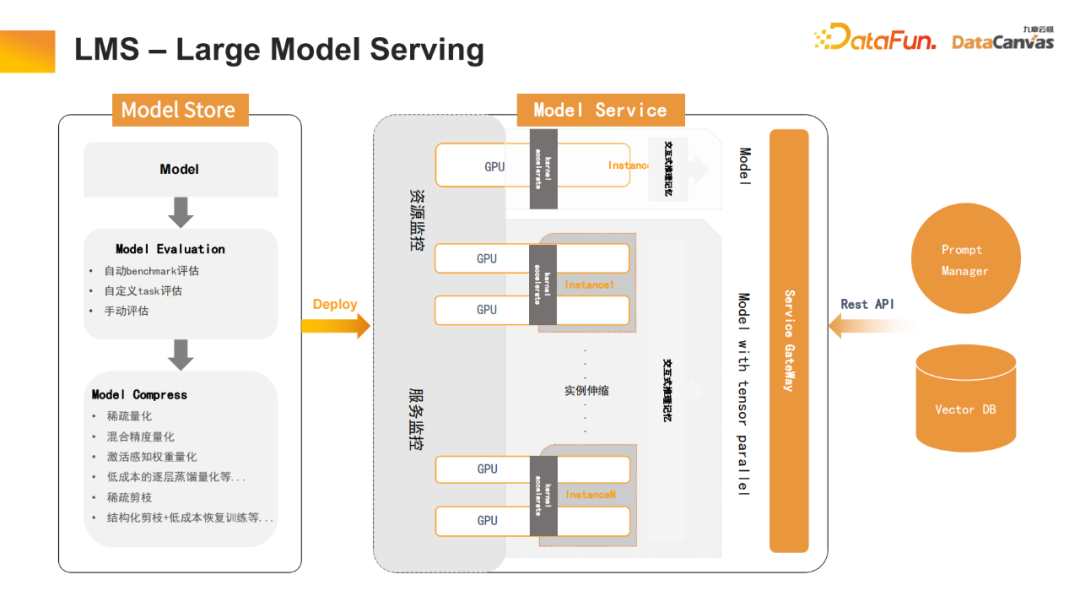
Penyajian model besar juga merupakan komponen yang sangat penting. Platform ini juga telah membuat banyak pengoptimuman dalam kuantiti model, penyulingan pengetahuan dan aspek lain sangat mengurangkan masa pengiraan, dan mempercepatkan pengubah melalui penyulingan pengetahuan lapisan demi lapisan untuk mengurangkan jumlah pengiraannya. Pada masa yang sama, banyak kerja pemangkasan telah dilakukan (termasuk pemangkasan berstruktur, pemangkasan jarang, dll.), yang telah meningkatkan kelajuan inferens model besar.
Selain itu, proses dialog interaktif juga telah dioptimumkan. Sebagai contoh, dalam Transformer dialog berbilang pusingan, kunci dan nilai setiap tensor boleh diingati tanpa pengiraan berulang. Oleh itu, ia boleh disimpan dalam Vector DB untuk merealisasikan fungsi ingatan sejarah perbualan dan meningkatkan pengalaman pengguna semasa proses interaksi.
6. Pengurus Prompt
Pengurus Prompt, alat reka bentuk dan pembinaan kata cepat model besar, membantu pengguna mereka bentuk perkataan pantas yang lebih baik dan membimbing model besar untuk menjana kandungan output yang lebih tepat, boleh dipercayai dan dijangka. Alat ini bukan sahaja boleh menyediakan mod pembangunan kit alat pembangunan untuk kakitangan teknikal, tetapi juga menyediakan mod operasi interaksi manusia-komputer untuk kakitangan bukan teknikal, memenuhi keperluan kumpulan orang yang berbeza untuk menggunakan model besar.
Fungsi utamanya termasuk: pengurusan model AI, pengurusan pemandangan, pengurusan templat kata segera, pembangunan kata segera dan aplikasi perkataan segera, dsb.

Platform ini menyediakan alatan pengurusan perkataan segera yang biasa digunakan untuk mencapai kawalan versi dan menyediakan templat yang biasa digunakan untuk mempercepatkan pelaksanaan perkataan segera.
3. Amalan model besar berbilang modal Jiuzhang Yunji DataCanvas
1 Model besar berbilang modal - dengan memori
Selepas memperkenalkan fungsi platform seterusnya, Imodal akan berkongsi. Amalan pembangunan model besar. Gambar di atas adalah rangka asas Jiuzhang Yunji DataCanvas Multi-Modal Model Besar. Kemahiran menaakul.
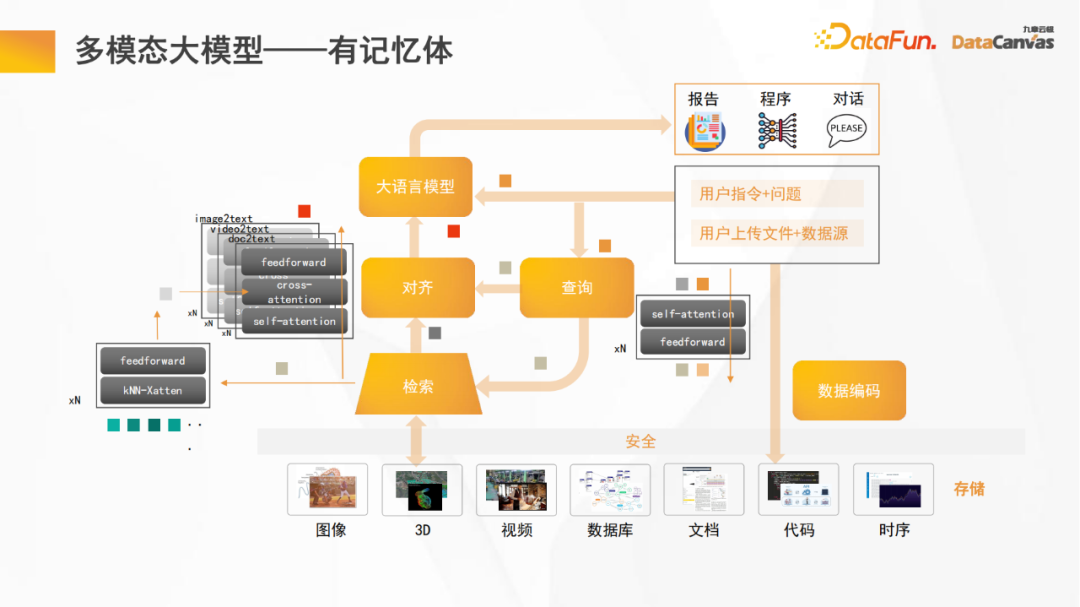 Secara amnya, bilangan parameter model sumber terbuka yang besar adalah agak rendah Jika sebahagian daripada parameter digunakan untuk ingatan, keupayaan penaakulannya akan berkurangan dengan ketara. Jika ingatan ditambahkan pada model sumber terbuka yang besar, keupayaan penaakulan dan ingatan akan dipertingkatkan pada masa yang sama.
Secara amnya, bilangan parameter model sumber terbuka yang besar adalah agak rendah Jika sebahagian daripada parameter digunakan untuk ingatan, keupayaan penaakulannya akan berkurangan dengan ketara. Jika ingatan ditambahkan pada model sumber terbuka yang besar, keupayaan penaakulan dan ingatan akan dipertingkatkan pada masa yang sama.
2. Data tidak berstruktur ETL Pipeline
Oleh kerana pangkalan data vektor pelbagai mod DingoDB kami menggabungkan fungsi berbilang modal dan ETL, ia boleh menyediakan keupayaan pengurusan data tidak berstruktur yang baik. Platform ini menyediakan fungsi ETL saluran paip dan telah membuat banyak pengoptimuman, termasuk kompilasi operator, pemprosesan selari dan pengoptimuman cache.
Selain itu, platform ini menyediakan Hab yang boleh menggunakan semula saluran paip untuk mencapai pengalaman pembangunan yang paling cekap. Pada masa yang sama, ia menyokong banyak pengekod pada Huggingface, yang boleh mencapai pengekodan optimum data modal yang berbeza.
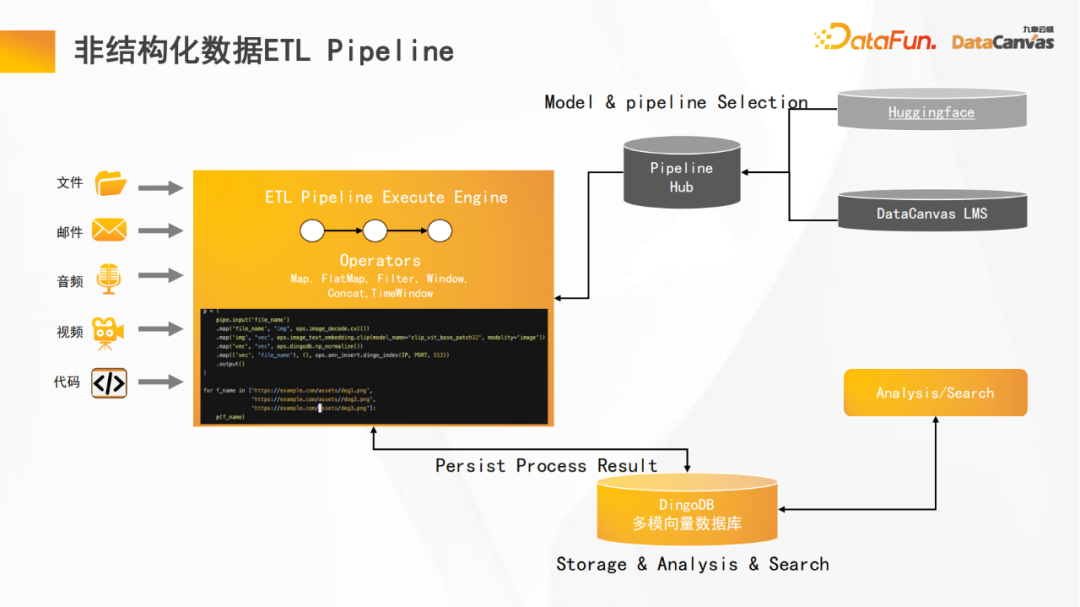
Jiuzhang Yunji DataCanvas menggunakan model besar berbilang modal Yuanshi sebagai asas untuk menyokong pengguna memilih model besar sumber terbuka lain dan juga menyokong pengguna menggunakan modal mereka sendiri data Menjalankan latihan.
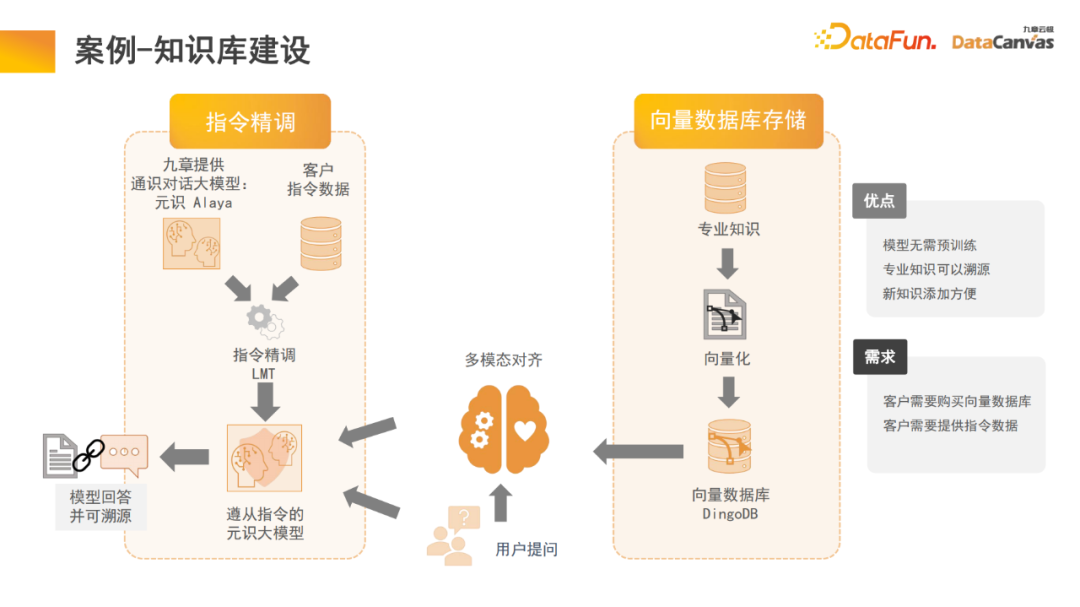
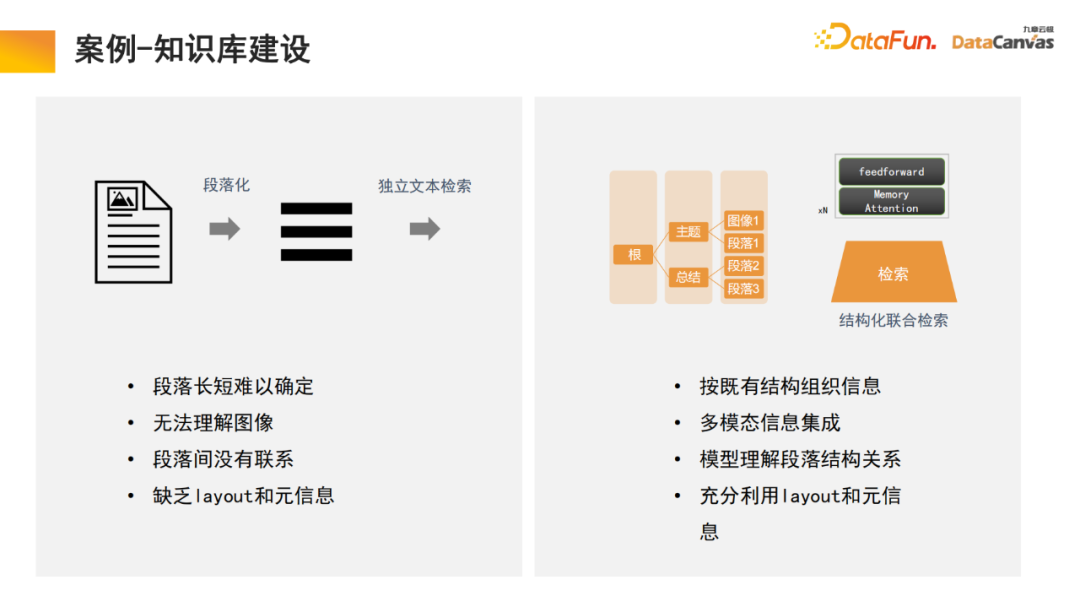
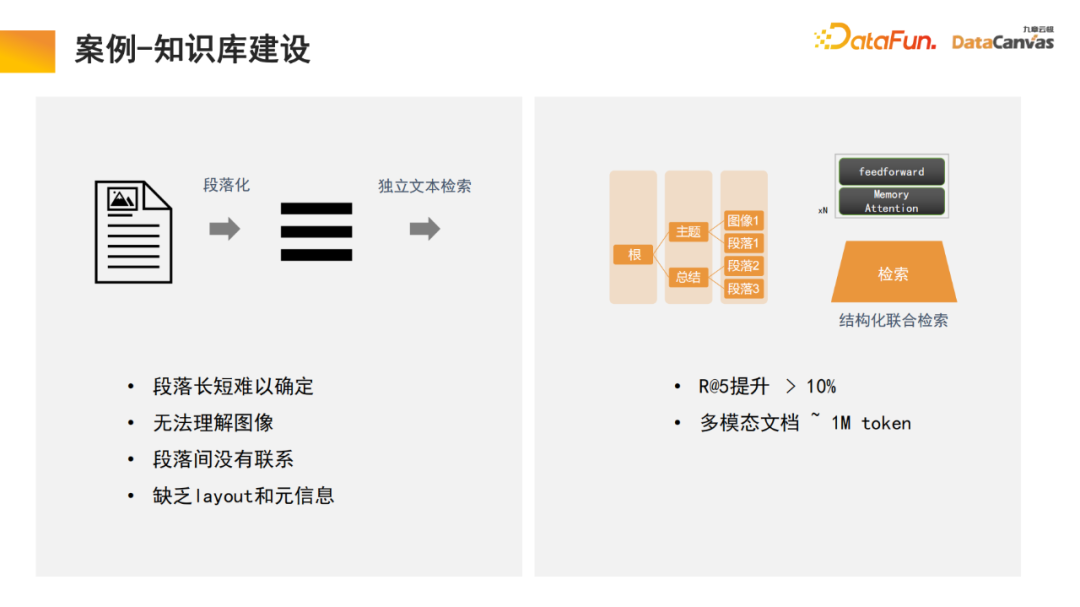
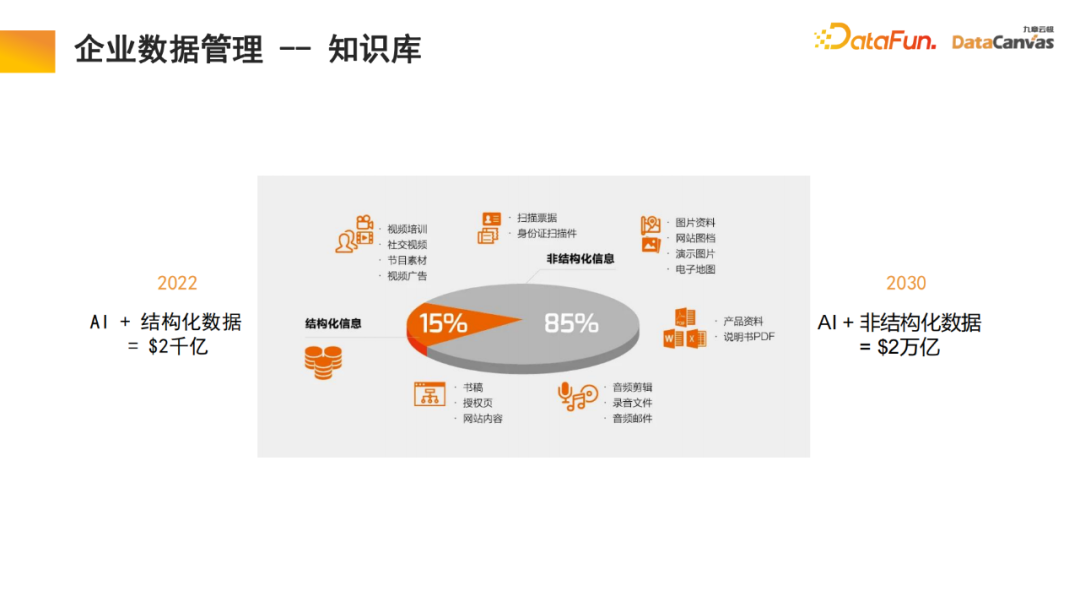
Pembinaan model berbilang modal besar dibahagikan secara kasar kepada tiga peringkat: Seni bina memori dalam model besar boleh membantu kita merealisasikan pembinaan asas model pelbagai mod, yang sebenarnya merupakan asas pengetahuan model. Zhihu ialah modul aplikasi asas pengetahuan berbilang modal biasa, dan pengetahuan profesionalnya boleh dikesan. Untuk memastikan kepastian dan keselamatan pengetahuan, selalunya perlu mengesan sumber pengetahuan profesional Pangkalan pengetahuan boleh membantu kita merealisasikan fungsi ini, lebih mudah untuk menambah pengetahuan baru . Tidak perlu mengubah suai parameter model dan terus menambahnya Pengetahuan boleh ditambah ke pangkalan data. Secara khusus, pengetahuan profesional digunakan untuk membuat pilihan pengekodan yang berbeza melalui pengekod, dan pada masa yang sama, penilaian bersatu dijalankan berdasarkan kaedah penilaian yang berbeza, dan pemilihan pengekod direalisasikan melalui penilaian satu klik. Akhir sekali, vektorisasi pengekod digunakan dan disimpan dalam pangkalan data vektor pelbagai mod DingoDB, dan kemudian maklumat yang berkaitan diekstrak melalui modul berbilang modal model besar, dan penaakulan dilakukan melalui model bahasa. Bahagian terakhir model selalunya memerlukan penalaan halus kerana keperluan pengguna yang berbeza adalah berbeza, keseluruhan model besar berbilang modal perlu diperhalusi. Disebabkan kelebihan istimewa asas pengetahuan pelbagai mod dalam menyusun maklumat, model ini mempunyai keupayaan untuk mendapatkan semula pembelajaran Ini juga merupakan inovasi yang kami buat dalam proses perengganan teks. Pangkalan pengetahuan am ialah membahagikan dokumen kepada perenggan, dan kemudian membuka kunci setiap perenggan secara berasingan. Kaedah ini mudah diganggu oleh bunyi bising, dan untuk banyak dokumen besar, sukar untuk menentukan piawaian untuk pembahagian perenggan. Dalam model kami, modul dapatkan semula melaksanakan pembelajaran, dan model secara automatik mencari organisasi maklumat berstruktur yang sesuai. Untuk produk tertentu, mulakan dari manual produk, mula-mula cari perenggan katalog besar, dan kemudian cari perenggan khusus. Pada masa yang sama, disebabkan penyepaduan maklumat berbilang mod, sebagai tambahan kepada teks, ia sering juga termasuk imej, jadual, dll., yang juga boleh divektorkan dan digabungkan dengan maklumat Meta untuk mencapai perolehan bersama, sekali gus meningkatkan kecekapan perolehan semula. Perlu dinyatakan bahawa modul mendapatkan semula menggunakan mekanisme perhatian memori, yang boleh meningkatkan kadar ingat semula sebanyak 10% berbanding dengan algoritma yang sama pada masa yang sama, mekanisme perhatian memori boleh digunakan untuk pemprosesan dokumen berbilang modal , yang juga merupakan satu aspek yang sangat berfaedah. data sahaja 15% adalah data berstruktur. Dalam 20 tahun yang lalu, kecerdasan buatan terutamanya berkisar pada data berstruktur adalah sangat sukar untuk digunakan dan memerlukan banyak tenaga dan kos untuk menukarnya kepada data berstruktur. Dengan bantuan model besar berbilang modal dan pangkalan pengetahuan berbilang modal, dan melalui paradigma baharu kecerdasan buatan, penggunaan data tidak berstruktur dalam pengurusan dalaman perusahaan boleh dipertingkatkan dengan banyak, yang mungkin membawa peningkatan 10 kali ganda dalam nilai pada masa hadapan. Pangkalan pengetahuan multimodal berfungsi sebagai asas ejen, dengan ejen R&D, ejen perkhidmatan pelanggan, ejen jualan, ejen sah, fungsi sumber manusia seperti sumber ejen dan ejen operasi dan penyelenggaraan perusahaan semuanya boleh dikendalikan melalui pangkalan pengetahuan. 🎜🎜 Ambil ejen jualan sebagai contoh Seni bina biasa termasuk dua ejen yang wujud pada masa yang sama, satu daripadanya bertanggungjawab untuk membuat keputusan dan satu lagi bertanggungjawab untuk analisis peringkat jualan. Kedua-dua modul boleh mencari maklumat yang berkaitan melalui pangkalan pengetahuan pelbagai mod, termasuk maklumat produk, statistik jualan sejarah, potret pelanggan, pengalaman jualan lepas, dll. Maklumat ini disepadukan untuk membantu kedua-dua ejen ini melakukan kerja yang terbaik dan paling betul Keputusan ini dalam membantu pengguna mendapatkan maklumat jualan terbaik, yang kemudiannya direkodkan ke dalam pangkalan data berbilang modal Kitaran ini terus meningkatkan prestasi jualan. Kami percaya bahawa syarikat yang paling berharga pada masa hadapan adalah mereka yang mempraktikkan risikan. Saya harap Jiuzhang Yunji DataCanvas dapat menemani anda sepanjang perjalanan dan membantu antara satu sama lain.
4. Kes - Pembinaan Pangkalan Pengetahuan
4. Pemikiran dan prospek untuk masa depan
1. Pengurusan data perusahaan - pangkalan pengetahuan
2. Pangkalan pengetahuan --> Ejen
Atas ialah kandungan terperinci Amalkan dan fikirkan platform model besar berbilang modal Jiuzhang Yunji DataCanvas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!