
Rumah >Peranti teknologi >AI >1 token menamatkan masalah pengekodan digital LLM! Sembilan institusi utama bersama-sama mengeluarkan xVal: Nombor yang tidak termasuk dalam set latihan juga boleh diramalkan!
1 token menamatkan masalah pengekodan digital LLM! Sembilan institusi utama bersama-sama mengeluarkan xVal: Nombor yang tidak termasuk dalam set latihan juga boleh diramalkan!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-10-19 14:25:01998semak imbas
Walaupun prestasi model bahasa besar (LLM) sangat berkuasa dalam analisis teks dan tugas penjanaan, apabila berhadapan dengan masalah yang melibatkan nombor, seperti pendaraban berbilang digit, kerana kekurangan mekanisme pembahagian kata nombor yang bersatu dan lengkap dalam model, ia akan Akibatnya, LLM tidak dapat memahami semantik nombor dan membuat jawapan rawak.
Pada masa ini, salah satu halangan yang LLM belum digunakan secara meluas dalam analisis data dalam bidang saintifik ialah masalah pengekodan digital.
Baru-baru ini, sembilan institusi penyelidikan termasuk Institut Flatiron, Makmal Kebangsaan Lawrence Berkeley, Universiti Cambridge, Universiti New York dan Universiti Princeton bersama-sama mengeluarkan skema pengekodan digital baharu xVal, yang hanya memerlukan satu token Encode semua nombor.

Pautan kertas: https://arxiv.org/pdf/2310.02989.pdf
xVal mewakili nilai sebenar sasaran dengan menskalakan skala berangka (vektor benam bagi] khusus), dan token kemudian Digabungkan dengan kaedah penaakulan berangka yang diubah suai, strategi xVal berjaya menjadikan model hujung ke hujung berterusan apabila memetakan antara nombor rentetan input dan nombor output, menjadikannya lebih sesuai untuk aplikasi dalam bidang saintifik.
Hasil penilaian pada set data sintetik dan dunia nyata menunjukkan bahawa xVal bukan sahaja berprestasi lebih baik dan menyimpan lebih banyak token daripada skim pengekodan berangka sedia ada, tetapi juga mempamerkan sifat generalisasi interpolasi yang lebih baik.
Terobosan baharu dalam pengekodan digital
Skema pembahagian perkataan LLM standard tidak membezakan antara nombor dan teks, jadi adalah mustahil untuk mengukur nilai.
Telah ada kerja sebelum ini untuk memetakan semua nombor kepada set nombor prototaip terhad dalam bentuk tatatanda saintifik, menggunakan 10 sebagai asas, atau untuk mengira jarak kosinus antara benam nombor untuk mencerminkan nombor itu sendiri Perbezaan berangka ada telah berjaya digunakan untuk menyelesaikan masalah algebra linear seperti pendaraban matriks.
Namun, bagi masalah berterusan atau lancar dalam bidang saintifik, model bahasa masih tidak dapat menangani masalah interpolasi dan generalisasi luar taburan dengan baik, kerana selepas mengekod nombor ke dalam teks, LLM masih bersifat diskret dalam pengekodan dan penyahkodan. peringkat , sukar untuk mempelajari anggaran fungsi berterusan. Idea
xVal adalah untuk mendarabkan saiz berangka dan mengarahkannya ke arah yang boleh dipelajari dalam ruang pembenaman, yang banyak mengubah cara nombor diproses dan ditafsirkan dalam seni bina Transformer.
xVal menggunakan satu token untuk pengekodan digital, yang mempunyai kelebihan kecekapan token dan jejak perbendaharaan kata yang minimum.
Digabungkan dengan paradigma penaakulan berangka yang diubah suai, nilai model Transformer adalah berterusan (licin) apabila memetakan antara nombor input dan nombor rentetan output Apabila fungsi anggaran berterusan atau lancar, ia boleh membawa lebih banyak bias induktif yang baik.
xVal: Pengekodan nombor berterusan
xVal tidak menggunakan token yang berbeza untuk nombor yang berbeza, tetapi secara langsung membenamkan nilai di sepanjang arah tertentu yang boleh dipelajari dalam ruang benam.
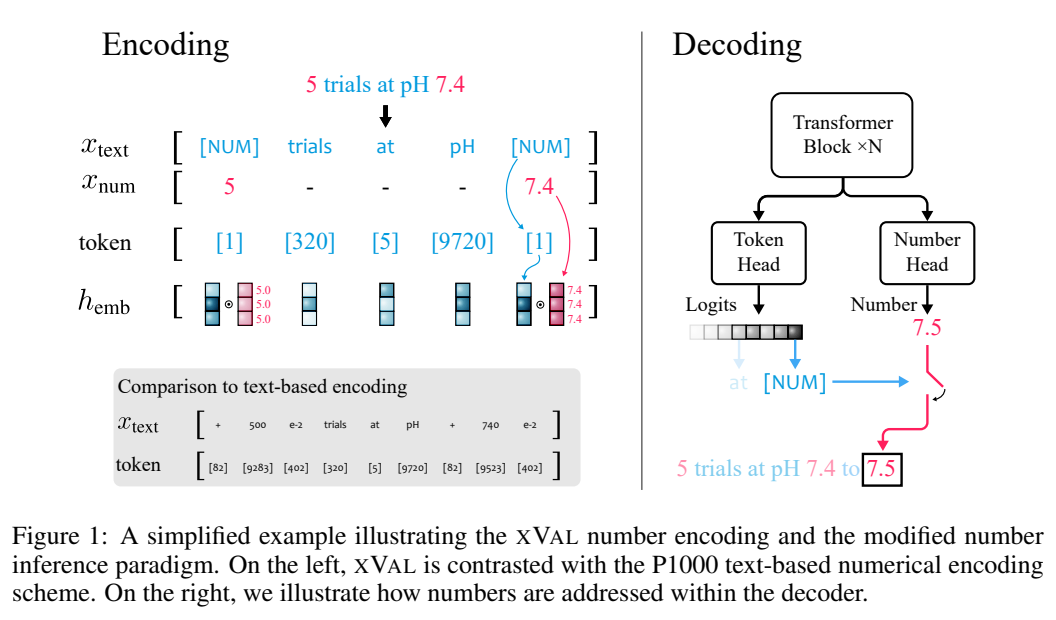
Dengan mengandaikan bahawa rentetan input mengandungi kedua-dua nombor dan teks, sistem akan menghuraikan input, mengekstrak semua nilai, dan kemudian membina rentetan baharu di mana nombor digantikan dengan simbol bit [NUM]. , dan kemudian darabkan vektor benam [NUM] dengan nilai yang sepadan.
Keseluruhan proses pengekodan boleh digunakan untuk pemodelan bahasa topeng (MLM) dan penjanaan autoregresif (AR).
Penormalan tersirat melalui norma lapisan berdasarkan penormalan lapisan
Dalam pelaksanaan khusus, pembenaman gandaan xVal dalam blok Transformer pertama perlu ditambah selepas Vektor pengekodan kedudukan atas, dan norma lapisan, menormalkan pembenaman setiap token berdasarkan sampel input.
Apabila pembenaman kedudukan tidak sejajar dengan pembenaman berteg [NUM], nilai skalar boleh dihantar melalui fungsi penskalaan semula bukan linear.
Andaikan bahawa u ialah pembenaman [NUM], p ialah pembenaman kedudukan, dan x ialah nilai skalar yang dikodkan Untuk memudahkan pengiraan, u · p=0 boleh diandaikan, di mana ∥u∥ =∥p. ∥ = 1, anda boleh Dapat
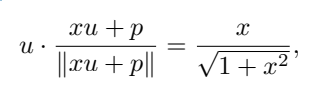
Iaitu, nilai x dikodkan untuk berada dalam arah yang sama dengan u, dan harta ini masih boleh dikekalkan selepas latihan.
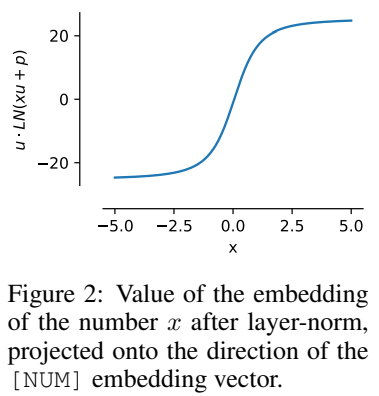
Ciri penormalan ini bermakna julat dinamik xVal adalah lebih kecil daripada skim pengekodan berasaskan teks lain, yang ditetapkan kepada [-5, 5] dalam eksperimen sebagai langkah Pemprosesan pra-latihan.
Penaakulan berangka
xVal mentakrifkan pembenaman berterusan dalam nilai input, tetapi jika tugasan berbilang klasifikasi digunakan sebagai output dan algoritma latihan mengambil kira pemetaan daripada nilai input kepada nilai output, model secara keseluruhan Ia bukan berterusan hujung ke hujung, dan nombor perlu diproses secara berasingan pada lapisan keluaran.
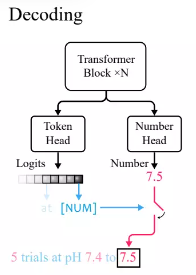
Mengikut amalan standard dalam model bahasa Transformer, penyelidik menentukan kepala token untuk mengeluarkan taburan kebarangkalian token perbendaharaan kata.
Oleh kerana xVal menggunakan [NUM] untuk menggantikan nombor, kepala tidak membawa sebarang maklumat tentang nilai berangka, jadi kepala nombor baharu dengan keluaran skalar perlu diperkenalkan dan dilatih melalui kehilangan min kuasa dua (MSE) kepada Memulihkan nilai angka tertentu yang dikaitkan dengan [NUM].
Selepas diberi input, perhatikan dahulu output kepala token Jika token yang dihasilkan ialah [NUM], kemudian lihat kepala nombor untuk mengisi nilai token.
Dalam eksperimen, kerana model Transformer adalah berterusan hujung ke hujung apabila membuat kesimpulan nilai, ia berprestasi lebih baik apabila menginterpolasi kepada nilai yang tidak kelihatan.
Bahagian eksperimen
Perbandingan dengan kaedah pengekodan digital lain
Para penyelidik membandingkan prestasi XVAL dengan empat pengekodan digital lain, yang kesemuanya memerlukan nombor diproses menjadi ±ddd E.±d terlebih dahulu , dan kemudian panggil token tunggal atau berbilang mengikut format untuk menentukan pengekodan.

Kaedah yang berbeza mempunyai perbezaan besar dalam bilangan token dan perbendaharaan kata yang diperlukan untuk mengekod setiap nombor, tetapi secara keseluruhan, xVal mempunyai kecekapan pengekodan tertinggi dan saiz perbendaharaan kata terkecil.
Para penyelidik juga menilai xVal pada tiga set data, termasuk data operasi aritmetik sintetik, data suhu global dan data simulasi orbit planet. ARITHMETIK BELIA UNTUK LLM terbesar, "Multiplikasi Multi-Digit" masih merupakan tugas yang sangat mencabar. -masalah pendaraban digit dan lima digit hanya 4% dan 0%
Daripada eksperimen perbandingan, pengekodan digital lain biasanya juga boleh berfungsi dengan baik, tetapi hasil ramalannya daripada xVal adalah lebih stabil daripada P10 dan FP15 dan tidak akan menghasilkan nilai ramalan yang tidak normal.
Untuk meningkatkan kesukaran tugasan, penyelidik menggunakan pokok binari rawak untuk membina set data menggunakan operator binari penambahan, penolakan dan pendaraban untuk menggabungkan nombor tetap operan (2, 3 atau 4), dalam yang mana setiap sampel ialah ungkapan aritmetik, contohnya ((1.32 * 32.1) + (1.42-8.20)) = 35.592
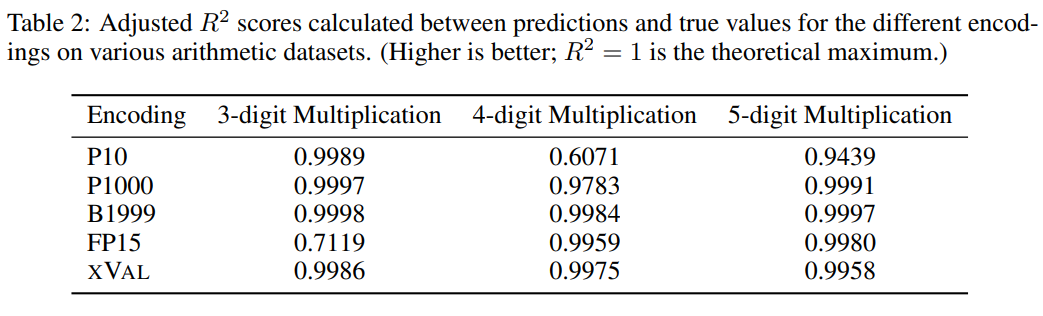
Berdasarkan keputusan, xVal melakukan tugasan ini dengan sangat baik, tetapi eksperimen aritmetik sahaja tidak mencukupi untuk menilai sepenuhnya keupayaan matematik model bahasa, kerana sampel dalam operasi aritmetik biasanya adalah urutan pendek dan manifold data asas adalah rendah -dimensi , masalah ini tidak menembusi kesesakan pengiraan LLM, dan aplikasi dalam dunia nyata adalah lebih kompleks.
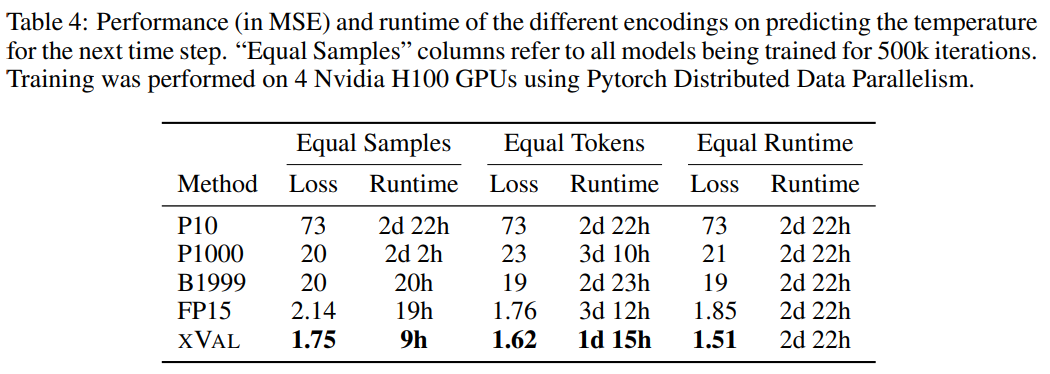
Temperature Ramalan -penyelidik menggunakan subset data iklim global ERA5 untuk penilaian. maka sampel adalah partition, di mana setiap sampel termasuk 2-4 hari data suhu permukaan (dinormalkan untuk mempunyai varians unit) dan latitud dan longitud daripada 60-90 stesen pelaporan yang dipilih secara rawak. Enkod sinus latitud dan sinus dan kosinus longitud koordinat, dengan itu mengekalkan periodicity data, dan kemudian menggunakan operasi yang sama untuk mengekod kedudukan dalam tempoh 24 jam dan 365 hari .
Koordinat (koordinat), titik mula (mula) dan data (data) sepadan dengan koordinat stesen pelaporan, masa sampel pertama dan data suhu ternormal, dan kemudian gunakan kaedah MLM untuk melatih model bahasa.

Daripada keputusan, xVal mempunyai prestasi terbaik, dan masa pengiraan juga berkurangan dengan ketara.
Tugas ini juga menggambarkan kelemahan skim pengekodan berasaskan teks, model boleh mengeksploitasi korelasi palsu dalam data, iaitu P10, P1000 dan B1999 mempunyai kecenderungan untuk meramalkan nombor 1, suhu biasa ±0. muncul paling kerap dalam set data.
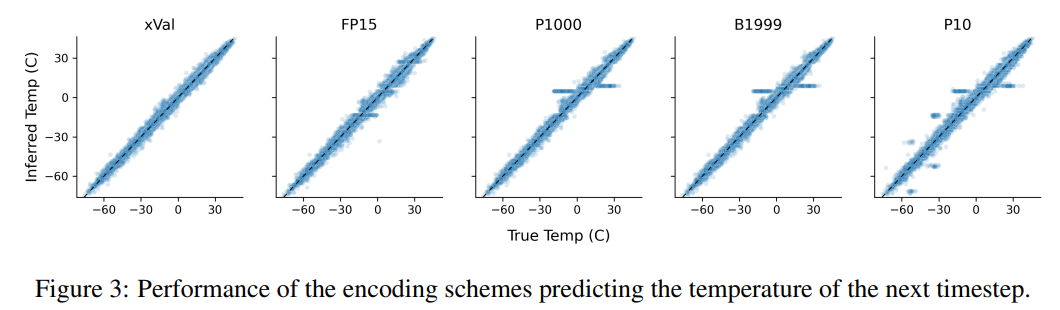
Untuk skim P1000 dan P10, output pengekodan kedua-dua skim adalah kira-kira 8000 dan 5000 token masing-masing (berbanding dengan purata FP15 dan xVal kira-kira 1800 token yang disebabkan oleh prestasi buruk model), kepada isu pemodelan jarak jauh.
Atas ialah kandungan terperinci 1 token menamatkan masalah pengekodan digital LLM! Sembilan institusi utama bersama-sama mengeluarkan xVal: Nombor yang tidak termasuk dalam set latihan juga boleh diramalkan!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!