
Rumah >Peranti teknologi >AI >Pilih GPT-3.5 atau perhalusi model sumber terbuka seperti Llama 2? Selepas perbandingan menyeluruh, jawapannya ialah
Pilih GPT-3.5 atau perhalusi model sumber terbuka seperti Llama 2? Selepas perbandingan menyeluruh, jawapannya ialah

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-10-16 14:17:06957semak imbas
Seperti yang kita sedia maklum, penalaan halus GPT-3.5 adalah sangat mahal. Kertas ini menggunakan percubaan untuk mengesahkan sama ada model yang diperhalusi secara manual boleh mendekati prestasi GPT-3.5 pada sebahagian kecil daripada kos. Menariknya, artikel ini melakukan perkara itu.
Membandingkan keputusan pada tugas SQL dan tugas perwakilan berfungsi, artikel ini menemui:
- #🎜 #GPT-3.5 berprestasi lebih baik sedikit daripada Kod Llama 34B yang diperhalusi oleh Lora pada kedua-dua set data (subset set data Spider dan set data perwakilan fungsi Viggo).
- GPT-3.5 adalah 4-6 kali lebih mahal untuk dilatih dan lebih mahal untuk digunakan.
Salah satu kesimpulan eksperimen ini ialah penalaan halus GPT-3.5 sesuai untuk kerja pengesahan awal, tetapi selepas itu, model seperti Llama 2 mungkin Pilihan terbaik, untuk meringkaskan secara ringkas:
- Jika anda ingin mengesahkan bahawa penalaan halus ialah cara yang betul untuk menyelesaikan tugasan/set data tertentu, atau mahukan persekitaran Dihoskan yang lengkap, kemudian perhalusi GPT-3.5.
- Jika anda ingin menjimatkan wang, dapatkan prestasi maksimum daripada set data anda, mempunyai fleksibiliti yang lebih besar dalam melatih dan menggunakan infrastruktur, atau ingin mengekalkan Beberapa data peribadi, maka baiklah -tala model sumber terbuka seperti Llama 2.
Seterusnya mari kita lihat bagaimana artikel ini dilaksanakan.
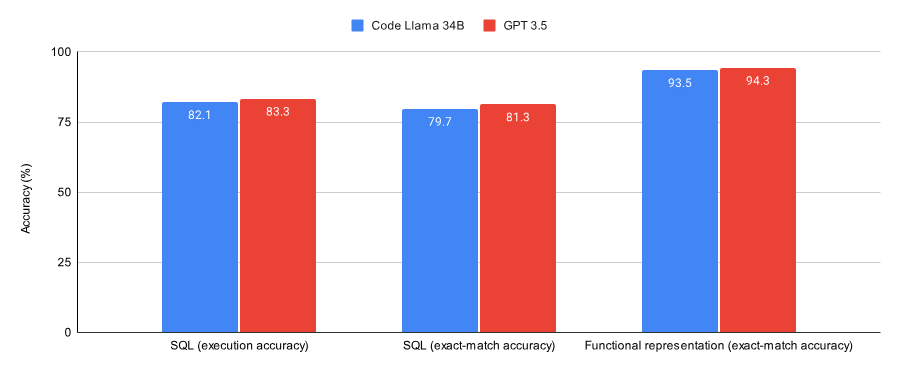
Rajah berikut menunjukkan prestasi Kod Llama 34B dan GPT-3.5 yang dilatih untuk menumpu pada tugas SQL dan tugas perwakilan berfungsi. Keputusan menunjukkan bahawa GPT-3.5 mencapai ketepatan yang lebih baik pada kedua-dua tugas.
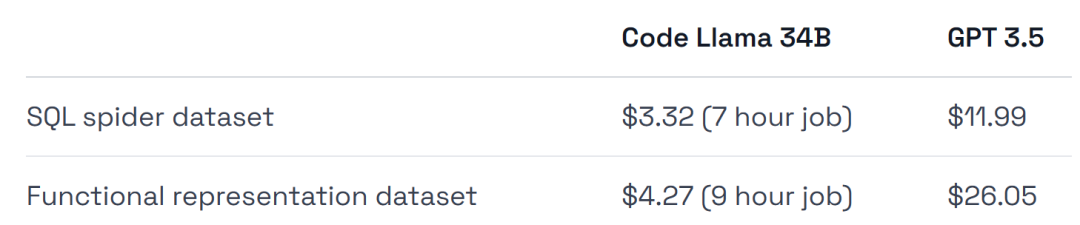
Dari segi penggunaan perkakasan, percubaan menggunakan GPU A40, yang berharga kira-kira $0.475 sejam.
Selain itu, eksperimen memilih dua set data yang sangat sesuai untuk penalaan halus , subset set data Spider dan set data perwakilan fungsi Viggo.
Untuk membuat perbandingan yang saksama dengan model GPT-3.5, percubaan melakukan penalaan halus hiperparameter minimum pada Llama.
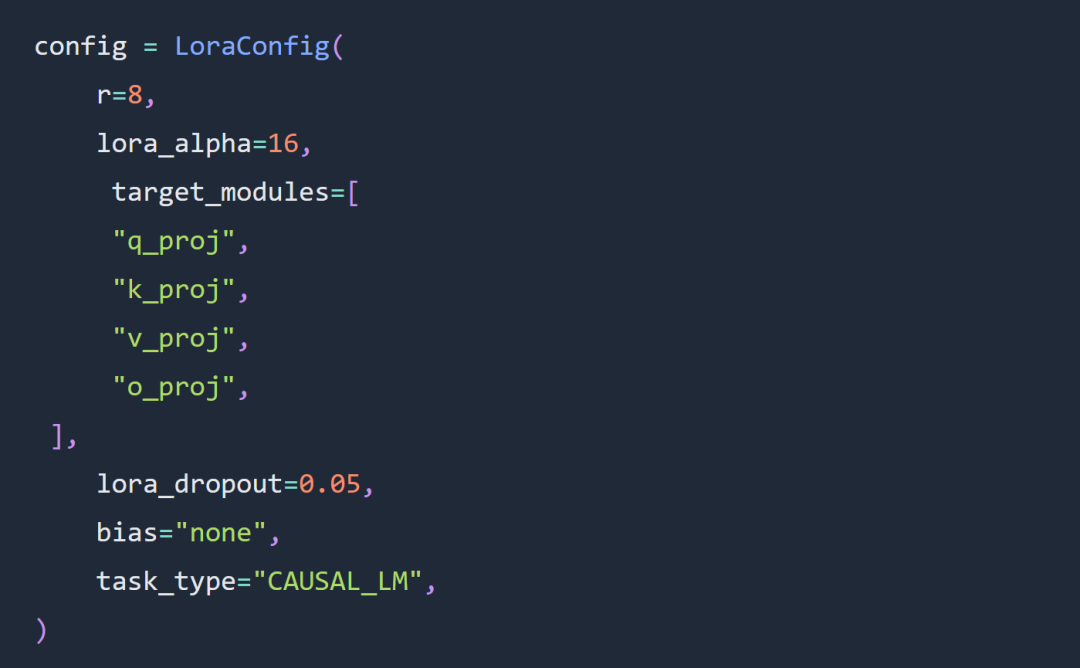
Dua pilihan utama untuk percubaan artikel ini ialah menggunakan penalaan halus Kod Llama 34B dan Lora dan bukannya penalaan halus parameter penuh.
Percubaan mengikut peraturan tentang penalaan hiperparameter Lora pada tahap yang besar Penyesuai Lora telah dikonfigurasikan seperti berikut: #🎜. 🎜## 🎜🎜#
 SQL contoh segera adalah seperti berikut:
SQL contoh segera adalah seperti berikut:
#🎜🎜🎜##🎜🎜🎜##🎜🎜 🎜🎜##🎜 🎜#
Gesaan SQL dipaparkan sebahagiannya Untuk petua lengkap, sila semak blog asal#🎜#🎜##🎜. Percubaan tidak menggunakan set data Spider yang lengkap Bentuk khusus adalah seperti berikut 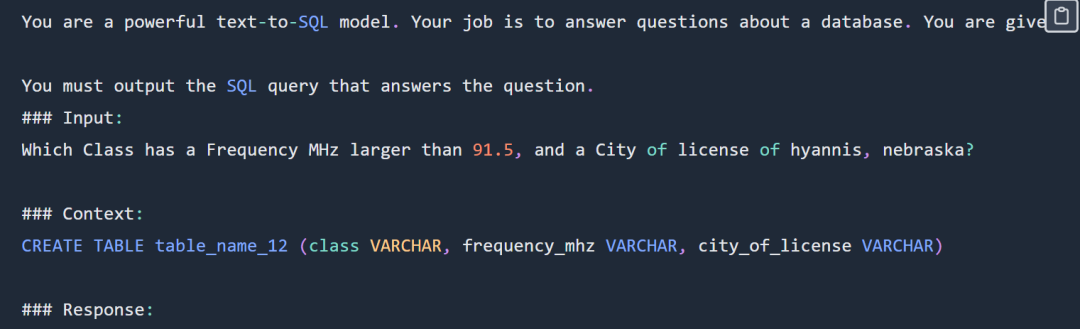
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
Percubaan memilih untuk menggunakan persilangan set data sql-create-context dan Set data labah-labah. Konteks yang disediakan untuk model ialah arahan penciptaan SQL seperti berikut:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
Kod dan alamat data tugas SQL: https://github.com/samlhuillier / spider-sql-finetune
Contoh gesaan perwakilan berfungsi kelihatan seperti ini:
# 🎜🎜#
pewakilan berfungsi Petua dipaparkan sebahagiannya Untuk petua lengkap, sila semak blog asal#🎜🎜🎜🎜🎜🎜 #Output adalah seperti berikut:# 🎜🎜#
verify_attribute(name[Little Big Adventure], rating[average], has_multiplayer[no], platforms[PlayStation])
Semasa fasa penilaian, kedua-dua eksperimen cepat bertumpu: 🎜#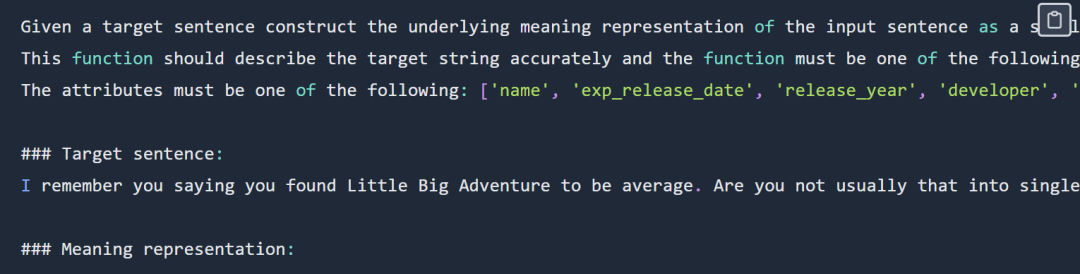 perwakilan berfungsi Kod tugas dan alamat data: https ://github.com/samlhuillier/viggo-finetune
perwakilan berfungsi Kod tugas dan alamat data: https ://github.com/samlhuillier/viggo-finetune
Untuk maklumat lanjut, sila semak Blog Asal.
Atas ialah kandungan terperinci Pilih GPT-3.5 atau perhalusi model sumber terbuka seperti Llama 2? Selepas perbandingan menyeluruh, jawapannya ialah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!