

 Peranti teknologiAITajuk baharu: ADAPT: Penerokaan awal kebolehjelasan pemanduan autonomi hujung-ke-hujung
Peranti teknologiAITajuk baharu: ADAPT: Penerokaan awal kebolehjelasan pemanduan autonomi hujung-ke-hujungTajuk baharu: ADAPT: Penerokaan awal kebolehjelasan pemanduan autonomi hujung-ke-hujung

Artikel ini dicetak semula dengan kebenaran akaun awam Autonomous Driving Heart Sila hubungi sumber untuk mencetak semula. . kerana kebolehtafsiran yang rendah, latihan sukar untuk disatukan, dsb., sesetengah sarjana dalam bidang ini telah mula secara beransur-ansur mengalihkan perhatian mereka kepada kebolehtafsiran hujung ke hujung Hari ini saya akan berkongsi dengan anda karya terkini mengenai kebolehtafsiran hujung ke hujung. ADAPT. Kaedah ini adalah berdasarkan seni bina Transformer dan menggunakan pelbagai tugas Kaedah latihan bersama mengeluarkan penerangan tindakan kenderaan dan penaakulan untuk setiap keputusan hujung ke hujung. Beberapa pendapat penulis tentang ADAPT adalah seperti berikut:
Berikut adalah ramalan menggunakan ciri 2D video Berkemungkinan kesannya akan menjadi lebih baik selepas menukar ciri 2D kepada ciri bev mungkin lebih baik apabila digabungkan dengan LLM , contohnya, bahagian Penjanaan Teks digantikan dengan LLM.
Karya semasa menggunakan video sejarah sebagai input, dan tindakan yang diramalkan serta penerangannya juga mungkin lebih bermakna jika ada diubah untuk meramalkan tindakan masa depan dan sebab tindakan itu .Token
yang diperolehi dengan token imej adalah terlalu banyak, dan mungkin terdapat banyak maklumat yang tidak berguna. Mungkin anda boleh mencuba Token-Learner.- Apakah titik permulaan?
- Pemanduan autonomi hujung ke hujung mempunyai potensi besar dalam industri pengangkutan, dan penyelidikan dalam bidang ini sedang hangat. Contohnya, UniAD, kertas terbaik CVPR2023, melakukan pemanduan automatik hujung ke hujung. Walau bagaimanapun, kekurangan ketelusan dan kebolehjelasan proses membuat keputusan automatik akan menghalang pembangunannya Lagipun, keselamatan adalah keutamaan pertama untuk kenderaan sebenar di jalan raya. Terdapat beberapa percubaan awal untuk menggunakan peta perhatian atau volum kos untuk meningkatkan kebolehtafsiran model, tetapi kaedah ini sukar difahami. Jadi titik permulaan kerja ini adalah untuk mencari cara yang mudah difahami untuk menerangkan pembuatan keputusan. Gambar di bawah adalah perbandingan beberapa kaedah Jelas sekali ia lebih mudah difahami dalam perkataan.
Apakah kelebihan ADAPT?
Mampu mengeluarkan huraian tindakan kenderaan dan alasan untuk setiap keputusan hujung ke hujung
Kaedah ini berdasarkan struktur rangkaian transformer dan melakukan latihan bersama melalui kaedah pelbagai tugas 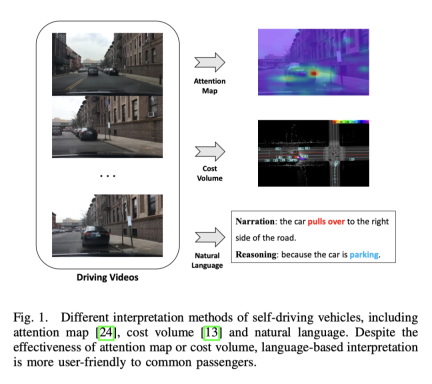
Untuk mengesahkan keberkesanan sistem dalam senario sebenar, sistem yang boleh digunakan telah diwujudkan untuk memasukkan video asal dan mengeluarkan penerangan dan alasan tindakan secara nyata masa. ;
- Paparan kesan
- Kesannya masih sangat baik, terutama adegan malam gelap ketiga, lampu isyarat diperhatikan.
Kemajuan semasa dalam bidang
Kapsyen Video
Matlamat utama penerangan video adalah untuk menerangkan objek dan hubungannya dengan video tertentu dalam bahasa semula jadi. Kerja-kerja penyelidikan awal menjana ayat dengan struktur sintaksis tertentu dengan mengisi elemen yang dikenal pasti dalam templat tetap, yang tidak fleksibel dan tidak mempunyai kekayaan.
Untuk menghasilkan ayat semula jadi dengan struktur sintaksis yang fleksibel, beberapa kaedah menggunakan teknik pembelajaran urutan. Secara khusus, kaedah ini menggunakan pengekod video untuk mengekstrak ciri dan penyahkod bahasa untuk mempelajari penjajaran teks visual. Untuk menjadikan huraian lebih kaya, kaedah ini juga menggunakan perwakilan peringkat objek untuk mendapatkan ciri interaksi sedar objek terperinci dalam videoWalaupun seni bina sedia ada telah mencapai hasil tertentu dalam arah kapsyen video umum, ia tidak boleh digunakan secara langsung pada perwakilan tindakan, kerana hanya memindahkan penerangan video kepada perwakilan tindakan pemanduan autonomi akan kehilangan beberapa maklumat penting, seperti kelajuan kenderaan, dsb., yang penting untuk tugas pemanduan autonomi. Cara menggunakan maklumat pelbagai mod ini dengan berkesan untuk menjana ayat masih diterokai. PaLM-E berfungsi dengan baik dalam ayat berbilang modal.
Pemandu autonomi hujung-ke-hujung
Pemacuan autonomi berasaskan pembelajaran ialah bidang penyelidikan yang aktif. UniAD kertas terbaik CVPR2023 baru-baru ini, termasuk FusionAD seterusnya, dan karya Wayve berdasarkan model Dunia MILE semuanya berfungsi ke arah ini. Format output termasuk titik trajektori, seperti UniAD, dan tindakan kenderaan secara langsung, seperti MILE.
Selain itu, beberapa kaedah memodelkan tingkah laku masa hadapan peserta trafik seperti kenderaan, penunggang basikal atau pejalan kaki untuk meramalkan titik laluan kenderaan, manakala kaedah lain meramalkan isyarat kawalan kenderaan secara langsung berdasarkan input sensor, serupa dengan subtugas ramalan isyarat kawalan dalam ini kerja
Kebolehtafsiran pemanduan autonomi
Dalam bidang pemanduan autonomi, kebanyakan kaedah kebolehtafsiran adalah berdasarkan penglihatan, dan ada yang berdasarkan kerja LiDAR. Sesetengah kaedah menggunakan peta perhatian untuk menapis kawasan imej yang tidak penting, menjadikan gelagat kenderaan autonomi kelihatan munasabah dan boleh dijelaskan. Walau bagaimanapun, peta perhatian mungkin mengandungi beberapa kawasan yang kurang penting. Terdapat juga kaedah yang menggunakan peta lidar dan berketepatan tinggi sebagai input, meramalkan kotak sempadan peserta trafik lain, dan menggunakan ontologi untuk menerangkan proses penaakulan membuat keputusan. Selain itu, terdapat cara untuk membina peta dalam talian melalui pembahagian untuk mengurangkan pergantungan pada peta HD. Walaupun kaedah berasaskan penglihatan atau lidar boleh memberikan hasil yang baik, kekurangan penjelasan lisan menjadikan keseluruhan sistem kelihatan rumit dan sukar untuk difahami. Satu kajian meneroka kemungkinan tafsiran teks untuk kenderaan autonomi buat kali pertama, dengan mengekstrak ciri video di luar talian untuk meramal isyarat kawalan dan melaksanakan tugas penerangan video
Berbilang tugas dalam pemanduan autonomi pembelajaran
Rangka kerja hujung ke hujung ini menggunakan pembelajaran berbilang tugas untuk bersama-sama melatih model menggunakan dua tugas penjanaan teks dan isyarat kawalan ramalan. Pembelajaran pelbagai tugas digunakan secara meluas dalam pemanduan autonomi. Oleh kerana penggunaan data yang lebih baik dan ciri yang dikongsi, latihan bersama tugas yang berbeza meningkatkan prestasi setiap tugasan Oleh itu, dalam kerja ini, latihan bersama dua tugas ramalan isyarat kawalan dan penjanaan teks digunakan.
kaedah ADAPT
Berikut ialah gambar rajah struktur rangkaian:
#🎜#🎜##🎜#🎜##🎜 #🎜 🎜#Keseluruhan struktur dibahagikan kepada dua tugas: 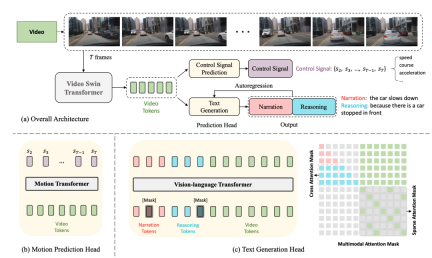
Driving Caption Generation (DCG): video input, output dua ayat, ayat pertama menerangkan aksi kereta, ayat kedua Huraikan alasan untuk mengambil tindakan ini, seperti "Kereta itu memecut, kerana lampu isyarat bertukar hijau." isyarat kawalan, seperti kelajuan , arah, pecutan.
- Antaranya, dua tugas DCG dan CSP berkongsi Pengekod Video, tetapi menggunakan kepala ramalan yang berbeza untuk menghasilkan output akhir yang berbeza.
- Untuk tugas DCG, pengekod pengubah bahasa penglihatan digunakan untuk menjana dua ayat bahasa semula jadi.
Pengekod Video
#🎜#🎜##🎜 di sini Video Swin Transformer digunakan untuk menukar bingkai video input kepada token ciri video. Input桢gambar, bentuknya
, saiz ciri yang keluar ialah#🎜🎜 inilah #🎜 🎜#
ialah dimensi saluran 🎜#Ciri di atas ditandakan untuk mendapatkan token video. 🎜🎜# , dan kemudian dilaraskan oleh MLP Dimensi diselaraskan dengan pembenaman token teks, dan kemudian token teks dan token video disalurkan kepada pengekod pengubah bahasa penglihatan bersama-sama untuk menjana penerangan dan penaakulan tindakan. Kepala Ramalan Isyarat Kawalan
dan input
video sepadan dengan isyarat kawalan #🎜 🎜🎜#, Output kepala CSP ialah, di mana setiap isyarat kawalan tidak semestinya satu dimensi, tetapi boleh berbilang dimensi, seperti termasuk kelajuan, pecutan, arah, dll. pada masa yang sama. Pendekatan di sini adalah untuk menandakan ciri video dan menjana satu siri isyarat keluaran melalui pengubah gerakan Fungsi kehilangan adalah MSE,
Sepatutnya. ambil perhatian bahawa , bingkai pertama tidak disertakan di sini kerana bingkai pertama memberikan terlalu sedikit maklumat dinamikLatihan Bersama
Dalam bingkai ini, kerana daripada pengekod video yang dikongsi, sebenarnya diandaikan bahawa kedua-dua tugas CSP dan DCG adalah sejajar pada tahap perwakilan video. Titik permulaan ialah perihalan tindakan dan isyarat kawalan ialah ungkapan berbeza bagi tindakan kenderaan berbutir halus, dan penjelasan penaakulan tindakan tertumpu terutamanya pada persekitaran pemanduan yang mempengaruhi tindakan kenderaan. Menggunakan latihan bersama untuk latihan
Perlu diingat bahawa walaupun ia adalah tempat latihan bersama, semasa inferens , tetapi boleh dilaksanakan secara bebas Tugasan CSP mudah difahami Hanya masukkan video secara terus mengikut carta alir dan keluarkan isyarat kawalan Untuk tugasan DCG, teruskan input video dan huraian dan penaakulan masa berdasarkan kaedah autoregresif Penjanaan perkataan bermula dari [CLS] dan berakhir dengan [SEP] atau mencapai ambang panjang.
Reka bentuk eksperimen dan perbandingan
Dataset
Set data yang digunakan ialah BDD-X ini mengandungi 7000 video berpasangan dan isyarat kawalan. Setiap video berdurasi kira-kira 40 saat, saiz imej ialah , dan kekerapannya ialah FPS Setiap video mempunyai 1 hingga 5 gelagat kenderaan, seperti memecut, membelok ke kanan dan bergabung. Semua tindakan ini dianotasi dengan teks, termasuk naratif tindakan (cth., "Kereta berhenti") dan penaakulan (cth., "Kerana lampu isyarat merah"). Terdapat kira-kira 29,000 pasangan anotasi tingkah laku secara keseluruhan.
Butiran pelaksanaan khusus
- video swin transformer telah dilatih terlebih dahulu pada Kinetics-600
- pengubah bahasa penglihatan dan motion transformer dimulakan secara rawak
- Tiada latihan tetap, jadi parameter swin tetap ke hujung Saiz bingkai video input
- diubah saiz dan dipotong, dan input akhir kepada rangkaian ialah 224x224
- Untuk penerangan dan penaakulan, pembenaman WordPiece [75] digunakan dan bukannya keseluruhan perkataan, (mis., "berhenti" ialah dipotong kepada "berhenti" dan "#s"), panjang maksimum setiap ayat ialah 15
- Semasa latihan, pemodelan bahasa bertopeng akan secara rawak menutup 50% daripada token, dan token setiap topeng mempunyai kebarangkalian 80% menjadi [MASK]. terdapat 10% kebarangkalian bahawa satu perkataan akan dipilih secara rawak, dan baki 10% kebarangkalian kekal tidak berubah.
- Pengoptimum AdamW digunakan, dan dalam 10% pertama langkah latihan, terdapat mekanisme memanaskan badan
- Ia mengambil masa kira-kira 13 jam untuk berlatih dengan 4 GPU V100
Impak latihan bersama
Tiga eksperimen dibandingkan di sini untuk menggambarkan keberkesanan latihan bersama tugasan masih belum wujud, tetapi apabila memasukkan modul DCG, selain tag video, tag isyarat kawalan juga perlu dimasukkan
Perbandingan kesan adalah seperti berikut
Berbanding dengan tugas DCG sahaja, Penaakulan ADAPT kesannya jauh lebih baik. Walaupun kesannya bertambah baik apabila terdapat input isyarat kawalan, ia masih tidak sebaik kesan penambahan tugasan CSP. Selepas menambah tugasan CSP, keupayaan untuk mewakili dan memahami video adalah lebih kuatSelain itu, jadual di bawah juga menunjukkan bahawa kesan latihan bersama terhadap CSP juga bertambah baik.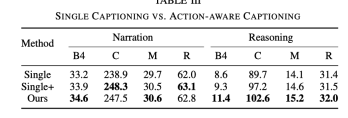
boleh difahami sebagai ketepatan, khususnya ia akan Isyarat kawalan yang diramalkan dipotong, dan formulanya adalah seperti berikut

Pengaruh pelbagai jenis isyarat kawalan
Dalam eksperimen, isyarat asas yang digunakan ialah kelajuan dan tajuk. Walau bagaimanapun, eksperimen mendapati bahawa apabila hanya satu daripada isyarat digunakan, kesannya tidak sebaik menggunakan kedua-dua isyarat pada masa yang sama Data khusus ditunjukkan dalam jadual berikut:
Ini menunjukkan bahawa kedua-dua isyarat. kepantasan dan hala tuju boleh membantu rangkaian Perihalan tindakan pembelajaran yang lebih baik dan penaakulan
Interaksi antara huraian tindakan dan penaakulan
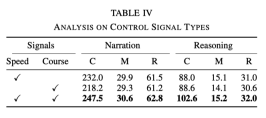 Berbanding dengan tugasan penerangan umum, penjanaan tugas huraian memandu ialah dua ayat iaitu huraian tindakan dan penaakulan. Ia boleh didapati daripada jadual berikut:
Berbanding dengan tugasan penerangan umum, penjanaan tugas huraian memandu ialah dua ayat iaitu huraian tindakan dan penaakulan. Ia boleh didapati daripada jadual berikut:
Garis 2 dan 3 pertukaran inferens Susunan huraian dan huraian juga akan menjadi tidak teratur, yang menunjukkan bahawa penaakulan bergantung pada huraian
Membandingkan tiga baris seterusnya, mengeluarkan hanya penerangan dan hanya mengeluarkan penaakulan tidak sebaik mengeluarkan kedua-duanya; Kesan Kadar Pensampelan Diperlukan Kandungan yang ditulis semula ialah: Pautan asal: https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQAtas ialah kandungan terperinci Tajuk baharu: ADAPT: Penerokaan awal kebolehjelasan pemanduan autonomi hujung-ke-hujung. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Let's Dance: Gerakan berstruktur untuk menyempurnakan jaring saraf manusia kitaApr 27, 2025 am 11:09 AM
Let's Dance: Gerakan berstruktur untuk menyempurnakan jaring saraf manusia kitaApr 27, 2025 am 11:09 AMPara saintis telah mengkaji secara meluas rangkaian saraf manusia dan mudah (seperti yang ada di C. elegans) untuk memahami fungsi mereka. Walau bagaimanapun, soalan penting timbul: Bagaimana kita menyesuaikan rangkaian saraf kita sendiri untuk berfungsi dengan berkesan bersama -sama dengan novel AI s
 New Google Leak mendedahkan perubahan langganan untuk Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak mendedahkan perubahan langganan untuk Gemini AIApr 27, 2025 am 11:08 AMGemini Google Advanced: Tahap Langganan Baru di Horizon Pada masa ini, mengakses Gemini Advanced memerlukan pelan premium AI $ 19.99/bulan. Walau bagaimanapun, laporan Pihak Berkuasa Android menunjukkan perubahan yang akan datang. Kod dalam google terkini p
 Bagaimana Pecutan Analisis Data Menyelesaikan Bots Tersembunyi AIApr 27, 2025 am 11:07 AM
Bagaimana Pecutan Analisis Data Menyelesaikan Bots Tersembunyi AIApr 27, 2025 am 11:07 AMWalaupun gembar -gembur di sekitar keupayaan AI maju, satu cabaran penting bersembunyi dalam perusahaan AI perusahaan: kesesakan pemprosesan data. Walaupun CEO merayakan kemajuan AI, jurutera bergelut dengan masa pertanyaan yang perlahan, saluran paip yang terlalu banyak, a
 Markitdown MCP boleh menukar mana -mana dokumen ke Markdowns!Apr 27, 2025 am 09:47 AM
Markitdown MCP boleh menukar mana -mana dokumen ke Markdowns!Apr 27, 2025 am 09:47 AMDokumen pengendalian tidak lagi hanya mengenai pembukaan fail dalam projek AI anda, ia mengenai mengubah kekacauan menjadi kejelasan. Dokumen seperti PDF, PowerPoints, dan perkataan banjir aliran kerja kami dalam setiap bentuk dan saiz. Mengambil semula berstruktur
 Bagaimana cara menggunakan Google ADK untuk ejen bangunan? - Analytics VidhyaApr 27, 2025 am 09:42 AM
Bagaimana cara menggunakan Google ADK untuk ejen bangunan? - Analytics VidhyaApr 27, 2025 am 09:42 AMMemanfaatkan kuasa Kit Pembangunan Ejen Google (ADK) untuk membuat ejen pintar dengan keupayaan dunia sebenar! Tutorial ini membimbing anda melalui membina ejen perbualan menggunakan ADK, menyokong pelbagai model bahasa seperti Gemini dan GPT. W
 Penggunaan SLM Over LLM untuk Penyelesaian Masalah Berkesan - Analisis VidhyaApr 27, 2025 am 09:27 AM
Penggunaan SLM Over LLM untuk Penyelesaian Masalah Berkesan - Analisis VidhyaApr 27, 2025 am 09:27 AMRingkasan: Model bahasa kecil (SLM) direka untuk kecekapan. Mereka lebih baik daripada model bahasa yang besar (LLM) dalam persekitaran yang kurang sensitif, masa nyata dan privasi. Terbaik untuk tugas-tugas berasaskan fokus, terutamanya di mana kekhususan domain, kawalan, dan tafsiran lebih penting daripada pengetahuan umum atau kreativiti. SLMs bukan pengganti LLM, tetapi mereka sesuai apabila ketepatan, kelajuan dan keberkesanan kos adalah kritikal. Teknologi membantu kita mencapai lebih banyak sumber. Ia sentiasa menjadi promoter, bukan pemandu. Dari era enjin stim ke era gelembung internet, kuasa teknologi terletak pada tahap yang membantu kita menyelesaikan masalah. Kecerdasan Buatan (AI) dan AI Generatif Baru -baru ini tidak terkecuali
 Bagaimana cara menggunakan model Google Gemini untuk tugas penglihatan komputer? - Analytics VidhyaApr 27, 2025 am 09:26 AM
Bagaimana cara menggunakan model Google Gemini untuk tugas penglihatan komputer? - Analytics VidhyaApr 27, 2025 am 09:26 AMMemanfaatkan kekuatan Google Gemini untuk Visi Komputer: Panduan Komprehensif Google Gemini, chatbot AI terkemuka, memanjangkan keupayaannya di luar perbualan untuk merangkumi fungsi penglihatan komputer yang kuat. Panduan ini memperincikan cara menggunakan
 Gemini 2.0 Flash vs O4-Mini: Bolehkah Google lebih baik daripada Openai?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini: Bolehkah Google lebih baik daripada Openai?Apr 27, 2025 am 09:20 AMLandskap AI pada tahun 2025 adalah elektrik dengan kedatangan Flash Gemini 2.0 Google dan Openai's O4-mini. Model-model canggih ini, yang dilancarkan minggu-minggu, mempunyai ciri-ciri canggih yang setanding dan skor penanda aras yang mengagumkan. Perbandingan mendalam ini


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

Dreamweaver CS6
Alat pembangunan web visual

