


Transformer Cross-modal: untuk pengesanan objek 3D yang pantas dan mantap


Pada masa ini, kenderaan pandu sendiri telah dilengkapi dengan pelbagai penderia pengumpulan maklumat, seperti lidar, radar gelombang milimeter dan penderia kamera. Dari sudut pandangan semasa, pelbagai penderia telah menunjukkan prospek pembangunan yang hebat dalam tugas persepsi pemanduan autonomi. Sebagai contoh, maklumat imej 2D yang dikumpul oleh kamera menangkap ciri semantik yang kaya, dan data awan titik yang dikumpul oleh lidar boleh memberikan maklumat kedudukan yang tepat dan maklumat geometri objek untuk model persepsi. Dengan menggunakan sepenuhnya maklumat yang diperolehi oleh penderia yang berbeza, kejadian faktor ketidakpastian dalam proses persepsi pemanduan autonomi dapat dikurangkan, manakala keteguhan pengesanan model persepsi dapat dipertingkatkan
Hari ini saya perkenalkan artikel dari Kuang Kertas kerja mengenai persepsi pemanduan autonomi berasaskan penglihatan telah dipilih untuk persidangan visi ICCV2023 tahun ini. Ciri utama artikel ini ialah algoritma persepsi BEV End-to-End seperti PETR (ia tidak lagi memerlukan penggunaan jawatan NMS. -memproses operasi untuk menapis hasil persepsi), dan pada masa yang sama tambahan menggunakan maklumat awan titik lidar untuk meningkatkan prestasi persepsi model pautan ke artikel dan pautan gudang sumber terbuka rasmi adalah seperti berikut: #🎜🎜 #
- Pautan kertas: https://arxiv.org/pdf/2301.01283.pdf
- #🎜🎜 Pautan #Kod: https://github.com/junjie18/CMT#🎜🎜 #
- Struktur keseluruhan model algoritma CMT
#🎜🎜 Seterusnya, kami akan memberikan pengenalan keseluruhan kepada struktur rangkaian model persepsi CMT, seperti yang ditunjukkan dalam rajah di bawah :
Ia boleh dilihat dari keseluruhan gambarajah blok algoritma yang keseluruhan model algoritma terutamanya merangkumi tiga bahagian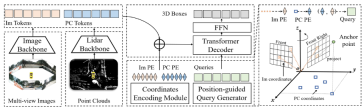
dan Image Token
(Im Token) **- Penjanaan kod kedudukan: Untuk maklumat data yang dikumpul oleh penderia yang berbeza, Im Token menjana kod kedudukan koordinat yang sepadan Im PE
- , Token PC menjana kod kedudukan #🎜🎜 yang sepadan PC PE, dan Pertanyaan Objek juga menjana kod kedudukan koordinat yang sepadan Pembenaman pertanyaan rangkaian Transformer Decoder: input ialah Pertanyaan Objek + Pembenaman pertanyaan dan #🎜 untuk melengkapkan pengekodan kedudukan 🎜#Im Token
- dan PC melakukan🎜 pengiraan perhatian silang, dan gunakan FFN untuk menjana Petak 3D akhir + ramalan kategori secara terperinci Selepas memperkenalkan struktur keseluruhan rangkaian, tiga sub-bahagian berikut yang dinyatakan di atas akan menjadi diperkenalkan secara terperinci Lidar Backbone + Camera Backbone (Image Backbone + Lidar Backbone) #🎜🎜 #Lidar backbone network The Lidar backbone biasa digunakan untuk mengekstrak rangkaian ciri data awan titik merangkumi lima bahagian berikut
Point cloud information body Voxelization
- Voxel feature encoding
- #🎜D🎜 Backbone (rangkaian VoxelResBackBone8x yang biasa digunakan) mengekstrak ciri 3D daripada hasil pengekodan ciri voxel
Ekstrak Tulang Belakang 3D ke paksi Z ciri dan mampatkannya untuk mendapatkan ciri dalam ruang BEV#🎜 🎜#
- Memandangkan bilangan saluran keluaran peta ciri oleh Tulang Belakang 2D tidak konsisten dengan bilangan saluran keluaran oleh Imej, lapisan konvolusi digunakan untuk menjajarkan bilangan saluran (untuk model dalam artikel ini, penjajaran bilangan saluran dibuat, tetapi ia bukan milik titik asal) Skop pengekstrakan maklumat awan )
- Rangkaian Tulang Belakang Kamera Rangkaian tulang belakang kamera yang biasanya digunakan untuk mengekstrak ciri imej 2D termasuk dua bahagian berikut:
- # 🎜🎜## 🎜🎜#Input: outsampled 16x dan 32x ciri peta output oleh 2D Backbone
- Output: downsampled 16x dan 32x Ciri imej digabungkan untuk mendapatkan ciri imej yang digabungkan 16 kali
Tensor([bs * N, 1024, H / 16, W / 16]) code><br># 🎜🎜#-
Tensor([bs * N, 2048, H/16, W/16])# 🎜🎜# - Tulis semula kandungan: Gunakan ResNet- 50 rangkaian untuk mengekstrak ciri imej sekeliling
Tensor([bs * N, 1024, H / 16, W / 16])Tensor([bs * N,2048,H / 16,W / 16])-
Output: Ciri imej output dikurangkan 16x dan 32x#🎜 🎜#需要重新写的内容是:张量([bs * N,256,H / 16,W / 16]) Tensor input:
Tensor([bs * N, 3, H, W])Tensor([bs * N,3,H,W])输出张量:
Tensor([bs * N,1024,H / 16,W / 16])输出张量:``Tensor([bs * N,2048,H / 32,W / 32])`
需要进行改写的内容是:2D骨架提取图像特征
Neck(CEFPN)
Kandungan yang perlu ditulis semula ialah: tensor ([bs * N, 256, H/16, W/16])位置编码的生成
根据以上介绍,位置编码的生成主要包括三个部分,分别是图像位置嵌入、点云位置嵌入和查询嵌入。下面将逐一介绍它们的生成过程
- Image Position Embedding(Im PE)
Image Position Embedding的生成过程与PETR中图像位置编码的生成逻辑是一样的(具体可以参考PETR论文原文,这里不做过多的阐述),可以总结为以下四个步骤:
- 在图像坐标系下生成3D图像视锥点云
- 3D图像视锥点云利用相机内参矩阵变换到相机坐标系下得到3D相机坐标点
- 相机坐标系下的3D点利用cam2ego坐标变换矩阵转换到BEV坐标系下
- 将转换后的BEV 3D 坐标利用MLP层进行位置编码得到最终的图像位置编码
- Point Cloud Position Embedding(PC PE)
Point Cloud Position Embedding的生成过程可以分为以下两个步骤 -
在BEV空间的网格坐标点利用
pos2embed()#🎜🎜 # Tensor output:Tensor([bs * N, 1024, H/16, W/16])
Tensor output: `` Tensor([ bs * N, 2048, H/32, W/32])` -
Kandungan yang perlu ditulis semula ialah: Ciri imej pengekstrakan rangka 2D#🎜🎜 #
Neck(CEFPN)
Penjanaan pengekodan kedudukan
Mengikut pengenalan di atas, kedudukan pengekodan Penjanaan terutamanya merangkumi tiga bahagian, iaitu pembenaman kedudukan imej, pembenaman kedudukan awan titik dan pembenaman pertanyaan. Berikut akan memperkenalkan proses penjanaan mereka satu demi satu
- Pembenaman Kedudukan Imej (Im PE)
- Proses penjanaan Pembenaman Kedudukan Imej adalah sama seperti logik penjanaan pengekodan kedudukan imej dalam PETR (khususnya Anda boleh merujuk kepada teks asal kertas PETR (saya tidak akan menghuraikan terlalu banyak di sini), yang boleh diringkaskan kepada empat langkah berikut:
-
Di bawah sistem koordinat imej Hasilkan awan titik frustum imej 3D
Awan titik frustum imej 3D menggunakan matriks parameter dalaman kamera untuk mengubahnya menjadi sistem koordinat kamera untuk mendapatkan Titik koordinat kamera 3D
3D dalam sistem koordinat kamera Titik ditukar kepada sistem koordinat BEV menggunakan matriks transformasi koordinat cam2ego
BEV 3D yang ditukar menggunakan koordinat adalah dikodkan kedudukan lapisan MLP untuk mendapatkan pengekodan kedudukan imej akhir
- Pembenaman Kedudukan Awan Titik (PC PE) Proses penjanaan Pembenaman Kedudukan Awan Titik boleh dibahagikan kepada mengikuti dua langkah
-
dalam ruang BEV Titik koordinat grid gunakan
# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
#🎜🎜🎜##🎜🎜 🎜# -
Dengan menggunakan multi-layer perceptron (MLP) Rangkaian melakukan transformasi spatial untuk memastikan penjajaran bilangan saluran Query Embedding#🎜 #
Untuk membuat pengiraan persamaan antara Pertanyaan Objek, Token Imej dan Token Lidar dengan lebih tepat, pembenaman pertanyaan dalam kertas akan menggunakan Lidar dan Kamera untuk menjana kod kedudukan Logik untuk menjana pembenaman pertanyaan secara khusus = Pembenaman Kedudukan Imej (sama seperti rv_query_embeds di bawah) + Point Cloud Position Embedding (sama seperti bev_query_embeds di bawah).bev_query_embedsGenerate logik#🎜##🎜🎜🎜🎜🎜 # Oleh kerana Pertanyaan Objek dalam kertas itu pada asalnya dimulakan dalam ruang BEV, anda boleh terus menggunakan semula pengekodan kedudukan dan fungsi bev_embedding() dalam logik penjanaan Point Cloud Position Embedding Kod kunci yang sepadan adalah seperti berikut:
def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
#. 🎜 🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜#rv_query_embeds logik generasi perlu ditulis semula#🎜🎜##🎜🎜##🎜🎜 di Dalam kandungan yang dinyatakan sebelum ini, Object Query ialah titik awal dalam sistem koordinat BEV. Untuk mengikuti proses penjanaan Pembenaman Kedudukan Imej, kertas itu perlu terlebih dahulu menayangkan titik ruang 3D dalam sistem koordinat BEV kepada sistem koordinat imej, dan kemudian menggunakan logik pemprosesan generasi sebelumnya bagi Pembenaman Kedudukan Imej untuk memastikan bahawa logik proses penjanaan adalah sama. Berikut ialah kod teras: #🎜🎜#def _rv_query_embed(self, ref_points, img_metas):pad_h, pad_w = pad_shape# 由归一化坐标点映射回正常的roi range下的3D坐标点ref_points = ref_points * (pc_range[3:] - pc_range[:3]) + pc_range[:3]points = torch.cat([ref_points, ref_points.shape[:-1]], dim=-1)points = bda_mat.inverse().matmul(points)points = points.unsqueeze(1)points = sensor2ego_mats.inverse().matmul(points)points =intrin_mats.matmul(points)proj_points_clone = points.clone() # 选择有效的投影点z_mask = proj_points_clone[..., 2:3, :].detach() > 0proj_points_clone[..., :3, :] = points[..., :3, :] / (points[..., 2:3, :].detach() + z_mask * 1e-6 - (~z_mask) * 1e-6)proj_points_clone = ida_mats.matmul(proj_points_clone)proj_points_clone = proj_points_clone.squeeze(-1)mask = ((proj_points_clone[..., 0] = 0)& (proj_points_clone[..., 1] = 0))mask &= z_mask.view(*mask.shape)coords_d = (1 + torch.arange(depth_num).float() * (pc_range[4] - 1) / depth_num)projback_points = (ida_mats.inverse().matmul(proj_points_clone))projback_points = torch.einsum("bvnc, d -> bvndc", projback_points, coords_d)projback_points = torch.cat([projback_points[..., :3], projback_points.shape[:-1]], dim=-1)projback_points = (sensor2ego_mats.matmul(intrin_mats).matmul(projback_points))projback_points = (bda_mat@ projback_points)projback_points = (projback_points[..., :3] - pc_range[:3]) / (pc_range[3:] - self.pc_range[:3])rv_embeds = self.rv_embedding(projback_points)rv_embeds = (rv_embeds * mask).sum(dim=1)return rv_embeds#🎜🎜#Melalui transformasi di atas, titik dalam sistem koordinat ruang BEV mula-mula diunjurkan ke sistem koordinat imej, dan kemudian proses menjana rv_query_embeds menggunakan logik pemprosesan untuk menjana Pembenaman Kedudukan Imej selesai . #🎜🎜##🎜🎜#Pembenaman pertanyaan terakhir = rv_query_embeds + bev_query_embeds#🎜🎜##🎜🎜##🎜🎜##🎜🎜#
Transformer Decoder+FFN Network
- Transformer Decoder
Logik pengiraan di sini adalah sama seperti Logicoder Transformer , tetapi dalam Data input adalah sedikit berbeza
- Titik pertama ialah Memori: Memori di sini adalah hasil daripada Concat antara Token Imej dan Token Lidar (boleh difahami sebagai dua modaliti Rong#🎜🎜 ## 🎜🎜#Titik kedua ialah pengekodan kedudukan: pengekodan kedudukan di sini ialah RV_QURY_EMBEDS dan bev_query_embeds untuk hasil confat ialah rv_query_embeds + bev_query_embeds;#🎜🎜🎜 #🎜🎜🎜. # Suram #FFNNETWORK Fungsi rangkaian FFN ini betul-betul sama seperti yang terdapat dalam PETR Hasil keluaran khusus boleh didapati dalam teks asal PETR, jadi saya tidak akan menjelaskan secara terperinci di sini #. 🎜🎜#
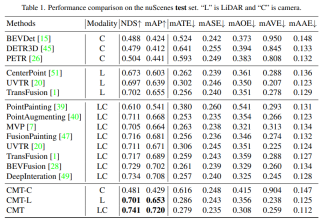
- # 🎜🎜# Hasil eksperimen kertas
- Pertama sekali, eksperimen perbandingan CMT dan algoritma lain yang dikeluarkan adalah persepsi pemanduan autonomi . set ujian nuScenes
Modaliti dalam jadual mewakili input kategori penderia kepada algoritma persepsi, dan C mewakili penderia Kamera, model hanya menyuap data kamera L mewakili penderia lidar dan model hanya menyuap data awan titik. LC mewakili penderia lidar dan kamera, dan model memasukkan data berbilang modal Ia boleh dilihat daripada hasil eksperimen bahawa prestasi model -C adalah lebih tinggi daripada prestasi CMT-. Model L lebih tinggi daripada model algoritma persepsi lidar tulen seperti CenterPoint dan UVTR Apabila CMT menggunakan data awan titik lidar dan data kamera, ia mengatasi semua kaedah mod tunggal yang sedia ada set nuScenes. Perbandingan hasil persepsi Dapat dilihat daripada hasil eksperimen bahawa prestasi model persepsi CMT-L mengatasi FUTR3D dan UVTR Apabila menggunakan kedua-dua data awan titik lidar dan data kamera, CMT sangat mengatasi arus model. Sesetengah menggunakan algoritma persepsi berbilang modal, seperti FUTR3D, UVTR, TransFusion, BEVFusion dan algoritma berbilang modal yang lain, dan telah mencapai keputusan SOTA pada set val
Seterusnya ialah bahagian percubaan ablasi Inovasi CMT
Pertama sekali, kami menjalankan satu siri eksperimen ablasi untuk menentukan Sama ada hendak menggunakan pengekodan kedudukan. Melalui keputusan eksperimen, didapati penunjuk NDS dan mAP mencapai keputusan terbaik apabila pengekodan kedudukan imej dan lidar digunakan secara serentak. Seterusnya, dalam bahagian (c) dan (f) percubaan ablasi, kami bereksperimen dengan pelbagai jenis dan saiz voxel bagi rangkaian tulang belakang awan titik. Dalam eksperimen ablasi dalam bahagian (d) dan (e), kami membuat percubaan yang berbeza pada jenis rangkaian tulang belakang kamera dan saiz resolusi input. Di atas hanyalah ringkasan ringkas kandungan eksperimen Jika anda ingin mengetahui eksperimen ablasi yang lebih terperinci, sila rujuk artikel asal- Akhir sekali, mari letakkan paparan hasil visual hasil persepsi CMT. pada set data nuScenes Melalui eksperimen Keputusan dapat dilihat bahawa CMT masih mempunyai hasil persepsi yang lebih baik.
-
Pada masa ini, pelbagai modaliti digabungkan bersama prestasi telah menjadi hala tuju penyelidikan yang popular (terutamanya dalam kereta pandu sendiri, dilengkapi dengan pelbagai sensor). Sementara itu, CMT ialah algoritma persepsi hujung ke hujung sepenuhnya yang tidak memerlukan langkah pasca pemprosesan tambahan dan mencapai ketepatan terkini pada set data nuScenes. Artikel ini memperkenalkan artikel ini secara terperinci, saya harap ia akan membantu semua orang
Atas ialah kandungan terperinci Transformer Cross-modal: untuk pengesanan objek 3D yang pantas dan mantap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Membina sistem automasi penyelidikan berstruktur menggunakan pydanticApr 24, 2025 am 10:32 AM
Membina sistem automasi penyelidikan berstruktur menggunakan pydanticApr 24, 2025 am 10:32 AMDalam bidang penyelidikan akademik yang dinamik, pengumpulan maklumat yang cekap, sintesis, dan persembahan adalah yang paling utama. Proses manual kajian literatur adalah memakan masa, menghalang analisis yang lebih mendalam. Sistem Pembantu Penyelidikan Multi-Agen Bui
 10 Generasi GPT-4O Generasi Mendapatkan Untuk Mencuba Hari Ini!Apr 24, 2025 am 10:26 AM
10 Generasi GPT-4O Generasi Mendapatkan Untuk Mencuba Hari Ini!Apr 24, 2025 am 10:26 AMBarang -barang liar yang benar -benar berlaku di dunia AI. Generasi imej asli Openai adalah gila sekarang. Kami bercakap visual rahang-menjatuhkan, terperinci yang menakutkan, dan output sehingga digilap mereka merasa buatan tangan dengan penuh
 Panduan pada pengekodan getaran dengan windsurfApr 24, 2025 am 10:25 AM
Panduan pada pengekodan getaran dengan windsurfApr 24, 2025 am 10:25 AMDengan mudah membawa penglihatan pengekodan anda ke kehidupan dengan Windsurf Codeium, teman pengekodan berkuasa AI anda. Windsurf menyelaraskan keseluruhan kitaran hayat pembangunan perisian, dari pengekodan dan debugging ke pengoptimuman, mengubah proses menjadi intu
 Meneroka Penyingkiran Latar Belakang Imej Menggunakan RMGB v2.0Apr 24, 2025 am 10:20 AM
Meneroka Penyingkiran Latar Belakang Imej Menggunakan RMGB v2.0Apr 24, 2025 am 10:20 AMBraiai's RMGB v2.0: Model penyingkiran latar belakang sumber terbuka yang kuat Model segmentasi imej merevolusi pelbagai bidang, dan penyingkiran latar belakang adalah bidang utama kemajuan. Braiai's RMGB v2.0 menonjol sebagai misal yang canggih, sumber terbuka m
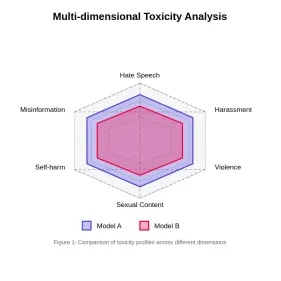 Menilai ketoksikan dalam model bahasa yang besarApr 24, 2025 am 10:14 AM
Menilai ketoksikan dalam model bahasa yang besarApr 24, 2025 am 10:14 AMArtikel ini menerangkan isu ketoksikan penting dalam model bahasa besar (LLMS) dan kaedah yang digunakan untuk menilai dan mengurangkannya. LLMS, Menghancurkan pelbagai aplikasi dari chatbots ke penjanaan kandungan, memerlukan metrik penilaian yang mantap, kecerdasan
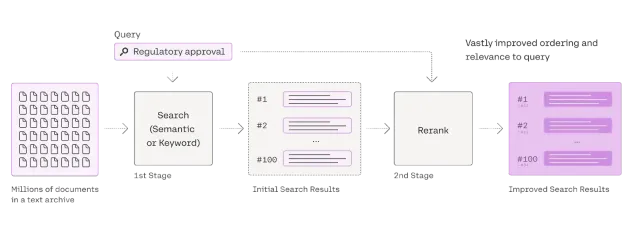 Panduan Komprehensif mengenai Reranker Untuk RagApr 24, 2025 am 10:10 AM
Panduan Komprehensif mengenai Reranker Untuk RagApr 24, 2025 am 10:10 AMSistem Generasi Tambahan (RAG) Pengambilan semula mengubah akses maklumat, tetapi keberkesanannya bergantung kepada kualiti data yang diambil. Di sinilah peniaga menjadi penting - bertindak sebagai penapis kualiti untuk hasil carian untuk memastikan sahaja
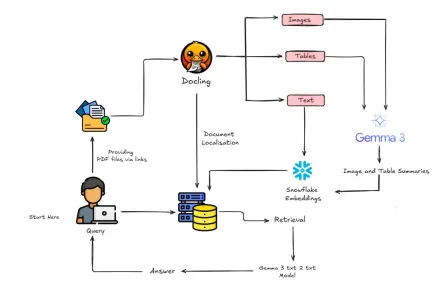 Bagaimana Membina Rag Multimodal Dengan Gemma 3 & Docling?Apr 24, 2025 am 10:04 AM
Bagaimana Membina Rag Multimodal Dengan Gemma 3 & Docling?Apr 24, 2025 am 10:04 AMTutorial ini membimbing anda melalui membina saluran paip generasi pengambilan semula multimodal (RAG) yang canggih di Google Colab. Kami akan menggunakan alat canggih seperti Gemma 3 (untuk bahasa dan penglihatan), docling (penukaran dokumen), Langchain
 Panduan Ray untuk Aplikasi Pembelajaran AI dan Mesin Skala dan MesinApr 24, 2025 am 10:01 AM
Panduan Ray untuk Aplikasi Pembelajaran AI dan Mesin Skala dan MesinApr 24, 2025 am 10:01 AMRay: Rangka kerja yang kuat untuk mengukur aplikasi AI dan Python Ray adalah rangka kerja sumber terbuka revolusioner yang direka untuk menggunakan aplikasi AI dan Python dengan mudah. API intuitifnya membolehkan penyelidik dan pemaju untuk memindahkan kod mereka


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

