
Rumah >Peranti teknologi >AI >Lebih serba boleh dan berkesan, WSAM pengoptimum yang dibangunkan sendiri oleh Ant telah dipilih ke dalam KDD Oral
Lebih serba boleh dan berkesan, WSAM pengoptimum yang dibangunkan sendiri oleh Ant telah dipilih ke dalam KDD Oral

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-10-10 12:13:09841semak imbas
Keupayaan generalisasi rangkaian saraf dalam (DNN) berkait rapat dengan kerataan titik ekstrem, jadi algoritma Sharpness-Aware Minimization (SAM) muncul untuk mencari titik ekstrem yang lebih rata untuk meningkatkan keupayaan generalisasi. Kertas kerja ini mengkaji semula fungsi kehilangan SAM dan mencadangkan kaedah yang lebih umum dan berkesan, WSAM, untuk meningkatkan kerataan latihan mata ekstrem dengan menggunakan kerataan sebagai istilah regularisasi. Percubaan pada pelbagai set data awam menunjukkan bahawa WSAM mencapai prestasi generalisasi yang lebih baik dalam kebanyakan kes berbanding dengan pengoptimum asal, SAM dan variannya. WSAM juga telah diterima pakai secara meluas dalam pembayaran digital dalaman Ant, kewangan digital dan senario lain dan telah mencapai hasil yang luar biasa. Kertas kerja ini diterima sebagai Kertas Lisan oleh KDD '23.

- Alamat kertas: https://arxiv.org/pdf/2305.15817.pdf
- /intelli gent - machine-learning/dlrover/tree/master/torch/torch/optimizers
Penyelidikan terkini menunjukkan bahawa keupayaan generalisasi berkait rapat dengan kerataan titik ekstrem. Dalam erti kata lain, kehadiran titik ekstrem rata dalam "landskap" fungsi kehilangan membolehkan ralat generalisasi yang lebih kecil. Sharpness-Aware Minimization (SAM) [1] ialah teknik untuk mencari titik ekstrem yang lebih rata dan dianggap sebagai salah satu arah teknikal yang paling menjanjikan pada masa ini. Teknologi SAM digunakan secara meluas dalam banyak bidang seperti penglihatan komputer, pemprosesan bahasa semula jadi, dan pembelajaran dua lapisan, dan dengan ketara mengatasi kaedah terkini yang terkini dalam bidang ini
Untuk meneroka minima yang lebih rata, SAM mentakrifkan fungsi kehilangan Kerataan
L pada w adalah seperti berikut:
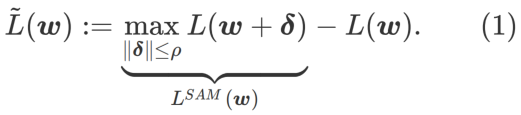
ialah anggaran nilai eigeniks maksimum bagi maksima ekstrem Hessian yang Artikel ini memikirkan semula pembinaan SAM ialah teknik untuk menyelesaikan masalah pengoptimuman minimax Pertama, SAM menggunakan pengembangan Taylor tertib pertama di sekitar w untuk menganggarkan masalah pemaksimuman lapisan dalam, iaitu, , Kedua, SAM kemas kini Pengiraan kedua adalah untuk mempercepatkan pengiraan. Pengoptimum berasaskan kecerunan lain (dipanggil pengoptimum asas) boleh dimasukkan ke dalam rangka kerja umum SAM, lihat Algoritma 1 untuk butiran. Dengan menukar Antaranya dan # yang berbeza 🎜 🎜# Rajah 1 menunjukkan proses kemas kini WSAM di bawah nilai 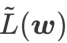 memang rata (curam) Pengukuran berkesan. Walau bagaimanapun, hanya boleh digunakan untuk mencari kawasan yang lebih rata dan bukannya titik minimum, yang mungkin menyebabkan fungsi kehilangan menumpu ke titik di mana nilai kerugian masih besar (walaupun kawasan sekitar rata). Oleh itu, SAM menggunakan
memang rata (curam) Pengukuran berkesan. Walau bagaimanapun, hanya boleh digunakan untuk mencari kawasan yang lebih rata dan bukannya titik minimum, yang mungkin menyebabkan fungsi kehilangan menumpu ke titik di mana nilai kerugian masih besar (walaupun kawasan sekitar rata). Oleh itu, SAM menggunakan 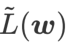
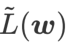 , iaitu
, iaitu 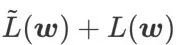 sebagai fungsi kerugian. Ia boleh dilihat sebagai kompromi antara mencari permukaan yang lebih rata dan nilai kerugian yang lebih kecil antara
sebagai fungsi kerugian. Ia boleh dilihat sebagai kompromi antara mencari permukaan yang lebih rata dan nilai kerugian yang lebih kecil antara 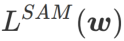 dan
dan 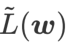 , di mana kedua-duanya diberi berat yang sama.
, di mana kedua-duanya diberi berat yang sama. 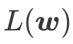
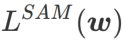 dan menganggap
dan menganggap 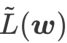 sebagai istilah regularisasi. Kami membangunkan algoritma yang lebih umum dan berkesan yang dipanggil WSAM (Pengurangan Ketajaman Berwajaran) menambah istilah kerataan berwajaran
sebagai istilah regularisasi. Kami membangunkan algoritma yang lebih umum dan berkesan yang dipanggil WSAM (Pengurangan Ketajaman Berwajaran) menambah istilah kerataan berwajaran 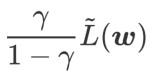 sebagai istilah penyelarasan, di mana hiperparameter
sebagai istilah penyelarasan, di mana hiperparameter 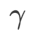 mengawal kerataan. Dalam bab pengenalan kaedah, kami menunjukkan cara menggunakan
mengawal kerataan. Dalam bab pengenalan kaedah, kami menunjukkan cara menggunakan 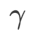 untuk membimbing fungsi kehilangan untuk mencari titik ekstrem yang lebih rata atau lebih kecil. Sumbangan utama kami boleh diringkaskan seperti berikut.
untuk membimbing fungsi kehilangan untuk mencari titik ekstrem yang lebih rata atau lebih kecil. Sumbangan utama kami boleh diringkaskan seperti berikut.
Pengetahuan awal
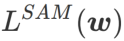 yang ditakrifkan oleh formula (1).
yang ditakrifkan oleh formula (1). 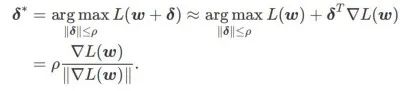
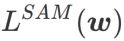 ximate w dengan mengambil kira-kira gradient iaitu
ximate w dengan mengambil kira-kira gradient iaitu 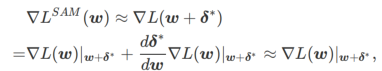
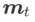 dan
dan 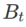 dalam Algoritma 1, kita boleh mendapatkan pengoptimum asas yang berbeza, seperti SGD, SGDM dan Adam, lihat Tab 1. Ambil perhatian bahawa Algoritma 1 kembali kepada SAM asal daripada kertas SAM [1] apabila pengoptimum asas ialah SGD. . Daripada formula (1), kami ada
dalam Algoritma 1, kita boleh mendapatkan pengoptimum asas yang berbeza, seperti SGD, SGDM dan Adam, lihat Tab 1. Ambil perhatian bahawa Algoritma 1 kembali kepada SAM asal daripada kertas SAM [1] apabila pengoptimum asas ialah SGD. . Daripada formula (1), kami ada 
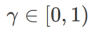 . Apabila
. Apabila 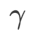 =0 ,
=0 , 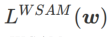 merosot menjadi kerugian biasa; Apabila 2, bersamaan dengan
merosot menjadi kerugian biasa; Apabila 2, bersamaan dengan 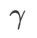 ; apabila
; apabila 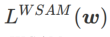
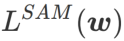 >1/2, memberi perhatian lebih kepada kerataan, jadi lebih mudah untuk dibandingkan dengan SAM Cari mata dengan kelengkungan yang lebih kecil daripada nilai kerugian yang lebih kecil dan sebaliknya.
>1/2, memberi perhatian lebih kepada kerataan, jadi lebih mudah untuk dibandingkan dengan SAM Cari mata dengan kelengkungan yang lebih kecil daripada nilai kerugian yang lebih kecil dan sebaliknya. 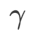
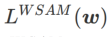 Rangka kerja biasa untuk WSAM yang mengandungi pengoptimum asas yang berbeza boleh dibuat dengan memilih
Rangka kerja biasa untuk WSAM yang mengandungi pengoptimum asas yang berbeza boleh dibuat dengan memilih 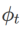 untuk dilaksanakan, lihat Algoritma 2. Contohnya, apabila
untuk dilaksanakan, lihat Algoritma 2. Contohnya, apabila 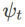 dan
dan  , kita mendapat WSAM yang pengoptimum asasnya ialah SGD, lihat Algoritma 3. Di sini, kami menggunakan teknik "penyahgandingan berat", iaitu istilah kerataan tidak disepadukan dengan pengoptimum asas untuk mengira kecerunan dan mengemas kini pemberat, tetapi dikira secara bebas (baris terakhir Algoritma 2 baris 7 item). Dengan cara ini, kesan regularisasi hanya mencerminkan kerataan langkah semasa tanpa maklumat tambahan. Sebagai perbandingan, Algoritma 4 memberikan WSAM tanpa "penyahgandingan berat" (dipanggil Coupled-WSAM). Contohnya, jika pengoptimum asas ialah SGDM, istilah regularisasi Coupled-WSAM ialah purata bergerak eksponen bagi kerataan. Seperti yang ditunjukkan dalam bahagian percubaan, "penyahgandingan berat" boleh meningkatkan prestasi generalisasi dalam kebanyakan kes.
, kita mendapat WSAM yang pengoptimum asasnya ialah SGD, lihat Algoritma 3. Di sini, kami menggunakan teknik "penyahgandingan berat", iaitu istilah kerataan tidak disepadukan dengan pengoptimum asas untuk mengira kecerunan dan mengemas kini pemberat, tetapi dikira secara bebas (baris terakhir Algoritma 2 baris 7 item). Dengan cara ini, kesan regularisasi hanya mencerminkan kerataan langkah semasa tanpa maklumat tambahan. Sebagai perbandingan, Algoritma 4 memberikan WSAM tanpa "penyahgandingan berat" (dipanggil Coupled-WSAM). Contohnya, jika pengoptimum asas ialah SGDM, istilah regularisasi Coupled-WSAM ialah purata bergerak eksponen bagi kerataan. Seperti yang ditunjukkan dalam bahagian percubaan, "penyahgandingan berat" boleh meningkatkan prestasi generalisasi dalam kebanyakan kes. 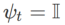
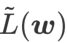

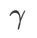 yang berbeza. Apabila
yang berbeza. Apabila 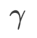 ,
, 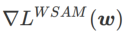 berada di antara
berada di antara 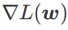 dan #🎜 🎜🎜# dan secara beransur-ansur menyimpang daripada
dan #🎜 🎜🎜# dan secara beransur-ansur menyimpang daripada 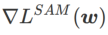
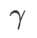 apabila meningkat.
apabila meningkat. 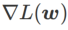

#🎜🎜🎜 Untuk saya #🎜🎜 Untuk lebih baik saya##🎜 kesan dan kelebihan γ dalam WSAM, kami menyediakan contoh dua dimensi yang mudah. Seperti yang ditunjukkan dalam Rajah 2, fungsi kerugian mempunyai titik ekstrem yang agak tidak sekata di sudut kiri bawah (kedudukan: (-16.8, 12.8), nilai kerugian: 0.28), dan titik ekstrem rata di sudut kanan atas (kedudukan: (19.8, 29.9), nilai kerugian: 0.36). Fungsi kehilangan ditakrifkan sebagai:
, di mana 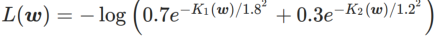 ialah perbezaan KL antara model Gaussian univariate dan dua taburan normal, iaitu
ialah perbezaan KL antara model Gaussian univariate dan dua taburan normal, iaitu 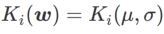 , antaranya
, antaranya 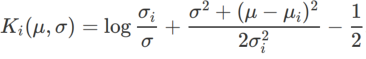 dan
dan 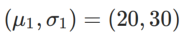 .
.  Kami menggunakan SGDM dengan momentum 0.9 sebagai pengoptimum asas dan menetapkan
Kami menggunakan SGDM dengan momentum 0.9 sebagai pengoptimum asas dan menetapkan
=2 untuk SAM dan WSAM. Bermula dari titik awal (-6, 10), fungsi kehilangan dioptimumkan dalam 150 langkah menggunakan kadar pembelajaran 5. SAM menumpu ke titik ekstrem dengan nilai kerugian yang lebih rendah tetapi lebih tidak sekata, dan WSAM dengan 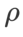 =0.6 adalah serupa. Walau bagaimanapun,
=0.6 adalah serupa. Walau bagaimanapun, 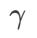 =0.95 menyebabkan fungsi kehilangan menumpu ke titik ekstrem rata, menunjukkan bahawa regularisasi kerataan yang lebih kuat memainkan peranan.
=0.95 menyebabkan fungsi kehilangan menumpu ke titik ekstrem rata, menunjukkan bahawa regularisasi kerataan yang lebih kuat memainkan peranan. 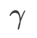
Eksperimen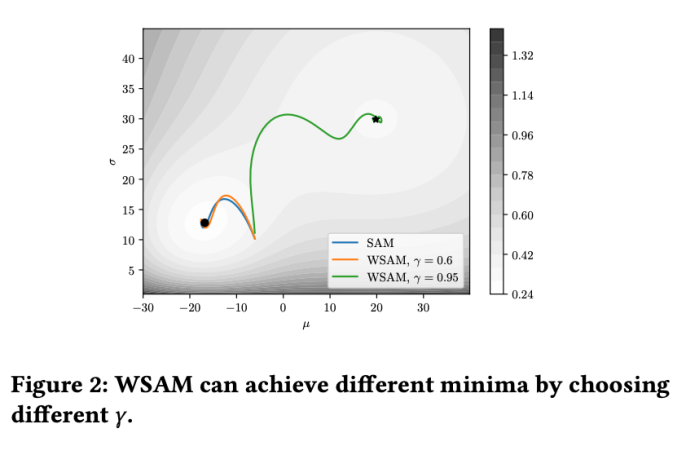
#🎜🎜 sedang mengusahakan pelbagai tugasan Eksperimen telah dijalankan untuk mengesahkan keberkesanan WSAM.
Klasifikasi Imej
Kami mula-mula mempelajari latihan WSAM dari awal pada set data Cifar10 dan Cifar100 Model yang kami pilih termasuk ResNet18 dan WideResNet-28-10. Kami melatih model pada Cifar10 dan Cifar100 menggunakan saiz kelompok yang dipratentukan masing-masing 128, 256 untuk ResNet18 dan WideResNet-28-10. Pengoptimum asas yang digunakan di sini ialah SGDM dengan momentum 0.9. Menurut tetapan SAM [1], setiap pengoptimum asas menjalankan dua kali bilangan zaman sebagai pengoptimum kelas SAM. Kami melatih kedua-dua model untuk 400 zaman (200 zaman untuk pengoptimum kelas SAM) dan menggunakan penjadual kosinus untuk mereputkan kadar pembelajaran. Di sini kami tidak menggunakan kaedah penambahan data lanjutan lain seperti potongan dan AutoAugment.
Untuk kedua-dua model, kami menggunakan carian grid bersama untuk menentukan kadar pembelajaran dan pekali pereputan berat bagi pengoptimum asas dan memastikannya tetap untuk eksperimen pengoptimum kelas SAM berikut. Julat carian kadar pembelajaran dan pekali pereputan berat ialah {0.05, 0.1} dan {1e-4, 5e-4, 1e-3} masing-masing. Memandangkan semua pengoptimum kelas SAM mempunyai satu hiperparameter 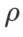 (saiz kejiranan), kami seterusnya mencari
(saiz kejiranan), kami seterusnya mencari 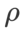 terbaik pada pengoptimum SAM dan menggunakan nilai yang sama untuk pengoptimum kelas SAM yang lain. Julat carian
terbaik pada pengoptimum SAM dan menggunakan nilai yang sama untuk pengoptimum kelas SAM yang lain. Julat carian 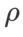 ialah {0.01, 0.02, 0.05, 0.1, 0.2, 0.5}. Akhir sekali, kami mencari hiperparameter unik pengoptimum kelas SAM yang lain, dan julat carian datang daripada julat yang disyorkan artikel asal masing-masing. Untuk GSAM [2], kami mencari dalam julat {0.01, 0.02, 0.03, 0.1, 0.2, 0.3}. Untuk ESAM [3], kami mencari
ialah {0.01, 0.02, 0.05, 0.1, 0.2, 0.5}. Akhir sekali, kami mencari hiperparameter unik pengoptimum kelas SAM yang lain, dan julat carian datang daripada julat yang disyorkan artikel asal masing-masing. Untuk GSAM [2], kami mencari dalam julat {0.01, 0.02, 0.03, 0.1, 0.2, 0.3}. Untuk ESAM [3], kami mencari  dalam julat {0.4, 0.5, 0.6},
dalam julat {0.4, 0.5, 0.6}, 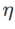 dalam julat {0.4, 0.5, 0.6} dan
dalam julat {0.4, 0.5, 0.6} dan 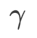 dalam julat {0.4, 0. , 0.6}. . Untuk WSAM, kami mencari
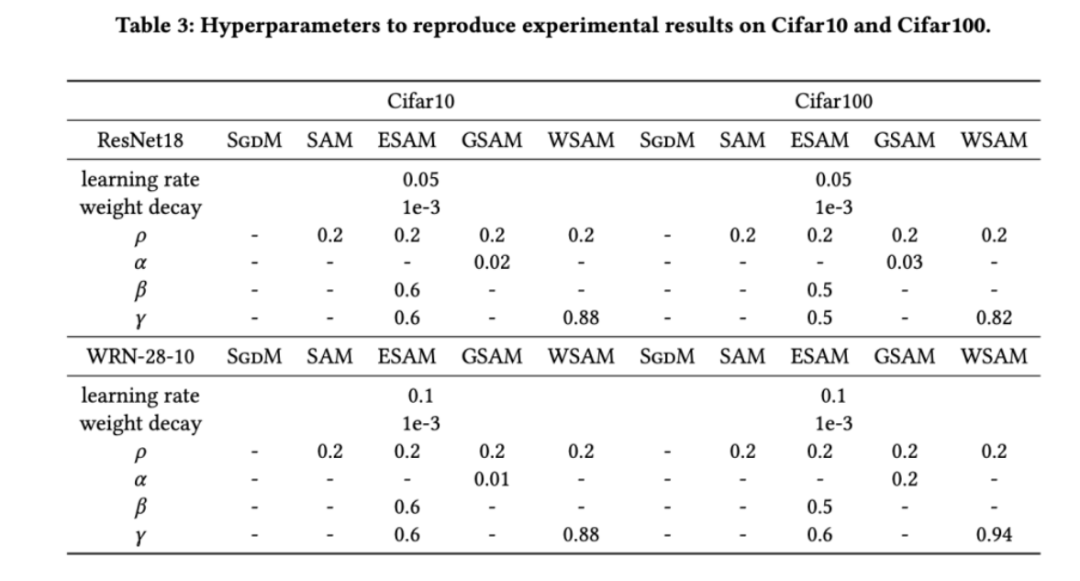
dalam julat {0.4, 0. , 0.6}. . Untuk WSAM, kami mencari 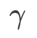 dalam julat {0.5, 0.6, 0.7, 0.8, 0.82, 0.84, 0.86, 0.88, 0.9, 0.92, 0.94, 0.96}. Kami mengulangi eksperimen 5 kali menggunakan benih rawak yang berbeza dan mengira ralat min dan sisihan piawai. Kami menjalankan percubaan pada GPU NVIDIA A100 kad tunggal. Hiperparameter pengoptimum untuk setiap model diringkaskan dalam Tab 3.
dalam julat {0.5, 0.6, 0.7, 0.8, 0.82, 0.84, 0.86, 0.88, 0.9, 0.92, 0.94, 0.96}. Kami mengulangi eksperimen 5 kali menggunakan benih rawak yang berbeza dan mengira ralat min dan sisihan piawai. Kami menjalankan percubaan pada GPU NVIDIA A100 kad tunggal. Hiperparameter pengoptimum untuk setiap model diringkaskan dalam Tab 3.
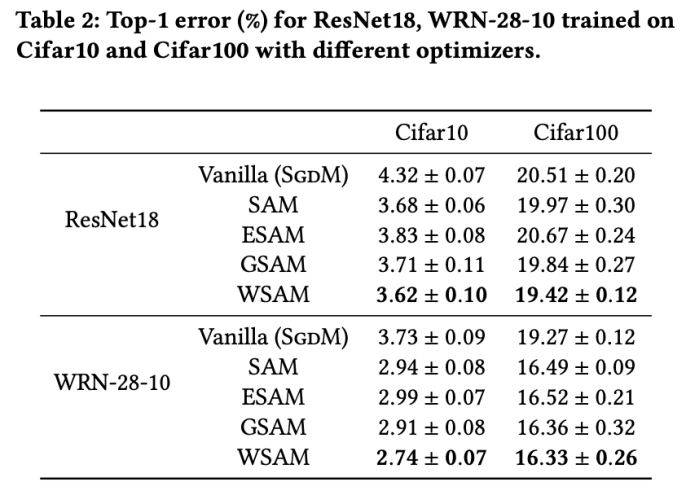
Tab 2 memberikan kadar ralat 1 teratas ResNet18, WRN-28-10 pada set ujian pada Cifar10 dan Cifar100 di bawah pengoptimum yang berbeza. Berbanding dengan pengoptimum asas, pengoptimum kelas SAM dengan ketara meningkatkan prestasi Pada masa yang sama, WSAM jauh lebih baik daripada pengoptimum kelas SAM yang lain.
Latihan tambahan pada ImageNet
Kami selanjutnya menjalankan eksperimen pada dataset ImageNet menggunakan struktur rangkaian Transformers Imej Cekap Data. Kami menyambung semula pusat pemeriksaan pangkalan DeiT yang telah terlatih dan kemudian meneruskan latihan selama tiga zaman. Model ini dilatih menggunakan saiz kelompok 256, pengoptimum asas ialah SGDM dengan momentum 0.9, pekali pengecilan berat ialah 1e-4, dan kadar pembelajaran ialah 1e-5. Kami mengulangi larian 5 kali pada GPU NVIDIA A100 empat kad dan mengira ralat purata dan sisihan piawai
Kami mencari 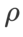 terbaik SAM dalam {0.05, 0.1, 0.5, 1.0,⋯} ,
terbaik SAM dalam {0.05, 0.1, 0.5, 1.0,⋯} , 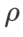 terbaik .
terbaik .  =5.5 yang optimum digunakan secara langsung dalam pengoptimum kelas SAM yang lain. Selepas itu, kami mencari
=5.5 yang optimum digunakan secara langsung dalam pengoptimum kelas SAM yang lain. Selepas itu, kami mencari 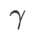 GSAM terbaik dalam {0.01, 0.02, 0.03, 0.1, 0.2, 0.3} dan
GSAM terbaik dalam {0.01, 0.02, 0.03, 0.1, 0.2, 0.3} dan
terbaik WSAM antara 0.80 dan 0.98 dengan saiz langkah 0.02
Kadar ralat top-1 awal model ialah 18.2%, dan selepas tiga zaman tambahan, kadar ralat ditunjukkan dalam Tab 4. Kami tidak menemui perbezaan ketara antara tiga pengoptimum seperti SAM, tetapi semuanya mengatasi pengoptimuman asas, menunjukkan bahawa mereka boleh menemui titik ekstrem yang lebih rata dan mempunyai keupayaan generalisasi yang lebih baik. 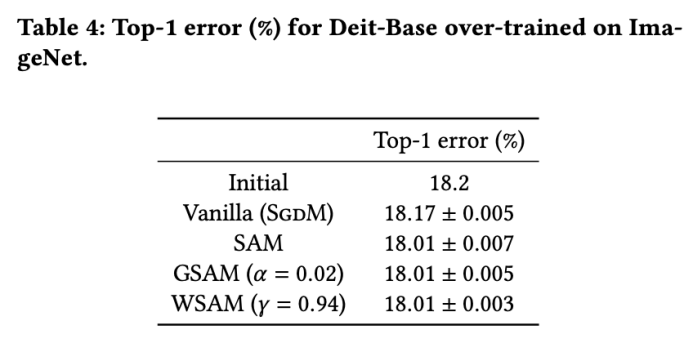
Keteguhan untuk melabel bunyi
Seperti yang ditunjukkan dalam kajian terdahulu [1, 4, 5], pengoptimum kelas SAM dilatih Set menunjukkan keteguhan yang baik dengan kehadiran bunyi label. Di sini, kami membandingkan kekukuhan WSAM dengan SAM, ESAM dan GSAM. Kami melatih ResNet18 pada set data Cifar10 untuk 200 zaman dan menyuntik hingar label simetri dengan tahap hingar sebanyak 20%, 40%, 60% dan 80%. Kami menggunakan SGDM dengan momentum 0.9 sebagai pengoptimum asas, saiz kelompok 128, kadar pembelajaran 0.05, pekali pereputan berat 1e-3 dan penjadual kosinus untuk mereput kadar pembelajaran. Untuk setiap tahap hingar label, kami melakukan carian grid pada SAM dalam julat {0.01, 0.02, 0.05, 0.1, 0.2, 0.5} untuk menentukan nilai  universal. Kami kemudian secara individu mencari hiperparameter khusus pengoptimum lain untuk mencari prestasi generalisasi optimum. Kami menyenaraikan hiperparameter yang diperlukan untuk menghasilkan semula keputusan kami dalam Tab 5. Kami membentangkan keputusan ujian kekukuhan dalam Tab 6. WSAM umumnya mempunyai kekukuhan yang lebih baik daripada SAM, ESAM dan GSAM.
universal. Kami kemudian secara individu mencari hiperparameter khusus pengoptimum lain untuk mencari prestasi generalisasi optimum. Kami menyenaraikan hiperparameter yang diperlukan untuk menghasilkan semula keputusan kami dalam Tab 5. Kami membentangkan keputusan ujian kekukuhan dalam Tab 6. WSAM umumnya mempunyai kekukuhan yang lebih baik daripada SAM, ESAM dan GSAM.
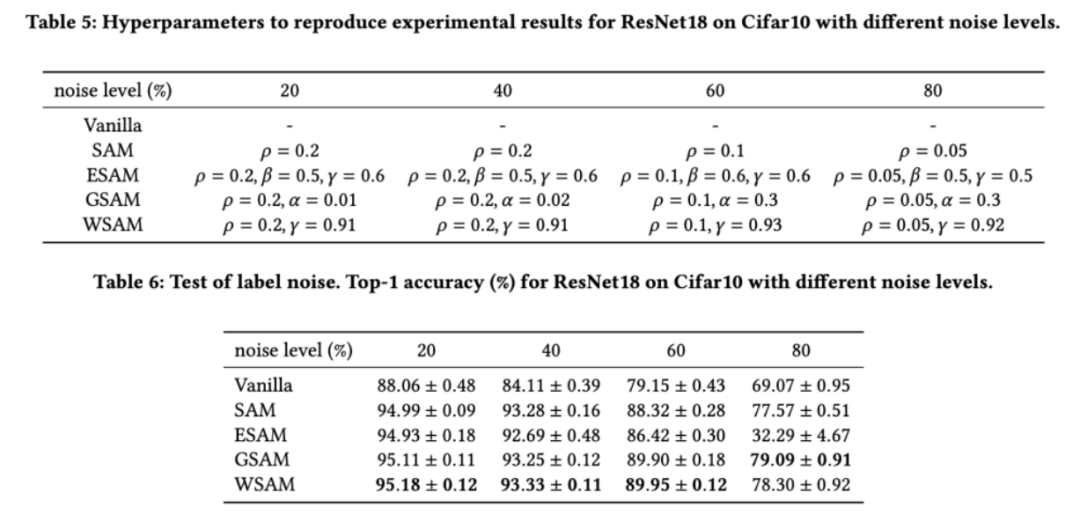
Meneroka kesan struktur geometri
#🎜🎜 Pengoptimum Kelas SAM boleh digabungkan dengan teknik seperti ASAM [4] dan Fisher SAM [5] untuk menyesuaikan bentuk kejiranan yang diterokai secara adaptif. Kami menjalankan eksperimen pada WRN-28-10 pada Cifar10 untuk membandingkan prestasi SAM dan WSAM apabila menggunakan kaedah maklumat adaptif dan Fisher, masing-masing, untuk memahami cara geometri kawasan penerokaan mempengaruhi prestasi generalisasi pengoptimum seperti SAM.
Kecuali parameter selain daripada 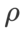 dan
dan 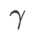 , kami menggunakan semula konfigurasi dalam pengelasan imej. Menurut kajian terdahulu [4, 5],
, kami menggunakan semula konfigurasi dalam pengelasan imej. Menurut kajian terdahulu [4, 5], 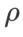 biasanya lebih besar untuk ASAM dan Fisher SAM. Kami mencari
biasanya lebih besar untuk ASAM dan Fisher SAM. Kami mencari 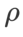 terbaik dalam {0.1, 0.5, 1.0,…, 6.0}, ASAM dan Fisher SAM untuk yang terbaik
terbaik dalam {0.1, 0.5, 1.0,…, 6.0}, ASAM dan Fisher SAM untuk yang terbaik 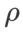 Kedua-duanya ialah 5.0. Selepas itu, kami mencari
Kedua-duanya ialah 5.0. Selepas itu, kami mencari 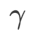 terbaik daripada WSAM antara 0.80 dan 0.94 dengan saiz langkah 0.02, dan kedua-dua kaedah adalah yang terbaik
terbaik daripada WSAM antara 0.80 dan 0.94 dengan saiz langkah 0.02, dan kedua-dua kaedah adalah yang terbaik 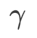 #🎜🎜 # ialah 0.88.
#🎜🎜 # ialah 0.88.
Anehnya, seperti yang ditunjukkan dalam Tab 7, garis dasar WSAM menunjukkan generalisasi yang lebih baik walaupun di kalangan berbilang calon. Oleh itu, kami mengesyorkan terus menggunakan WSAM dengan garis dasar 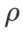 tetap.
tetap.

Eksperimen Ablasi#🎟#🎜🎜🎜🎜🎜🎜🎜 ini Kami menjalankan eksperimen ablasi untuk mendapatkan pemahaman yang lebih mendalam tentang kepentingan teknik "penyahgandingan berat" dalam WSAM. Seperti yang diterangkan dalam butiran reka bentuk WSAM, kami membandingkan varian WSAM tanpa "penyahgandingan berat" (Algoritma 4) Coupled-WSAM dengan kaedah asal.
Hasilnya ditunjukkan dalam Tab 8. Coupled-WSAM menghasilkan hasil yang lebih baik daripada SAM dalam kebanyakan kes, dan WSAM menambah baik lagi keputusan dalam kebanyakan kes, menunjukkan keberkesanan teknik "penyisihan gandingan berat".
Analisis titik ekstrem
Di sini, kami memperdalam lagi pemahaman kami tentang pengoptimum WSAM dengan membandingkan perbezaan antara titik ekstrem yang ditemui oleh pengoptimum WSAM dan SAM. Kerataan (kecuraman) pada titik ekstrem boleh diterangkan oleh nilai eigen maksimum matriks Hessian. Semakin besar nilai eigen, semakin kurang rata. Kami menggunakan algoritma Lelaran Kuasa untuk mengira nilai eigen maksimum ini.
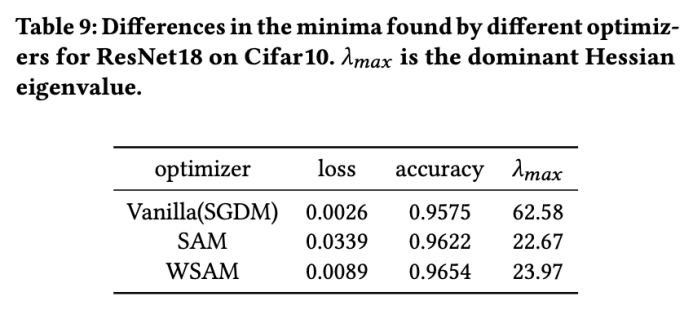
Tab 9 menunjukkan perbezaan antara titik ekstrem yang ditemui oleh pengoptimum SAM dan WSAM. Kami mendapati bahawa titik ekstrem yang ditemui oleh pengoptimum vanila mempunyai nilai kerugian yang lebih kecil tetapi kurang rata, manakala titik ekstrem yang ditemui oleh SAM mempunyai nilai kerugian yang lebih besar tetapi lebih rata, sekali gus meningkatkan prestasi generalisasi. Menariknya, titik ekstrem yang ditemui oleh WSAM bukan sahaja mempunyai nilai kerugian yang jauh lebih kecil daripada SAM, tetapi juga mempunyai kerataan yang sangat hampir dengan SAM. Ini menunjukkan bahawa dalam proses mencari titik ekstrem, WSAM mengutamakan memastikan nilai kerugian yang lebih kecil semasa cuba mencari kawasan yang lebih rata.
Sensitiviti Hiperparameter
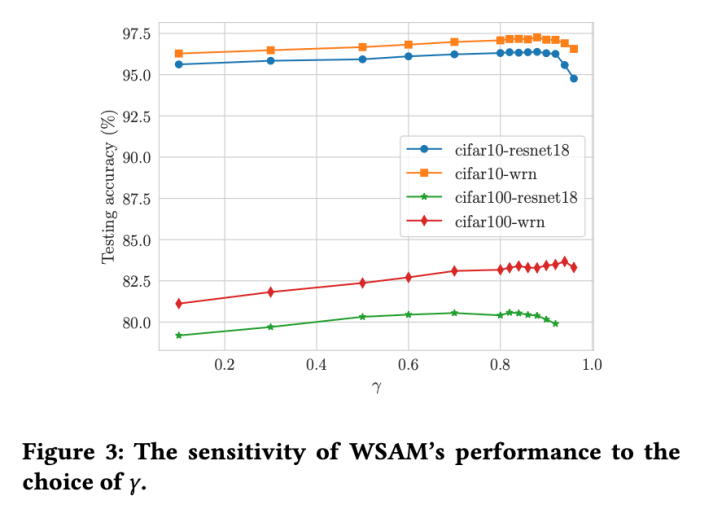
Berbanding SAM, WSAM mempunyai hiperparameter tambahan 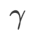 untuk menskalakan saiz istilah darjah rata (curam). Di sini, kami menguji sensitiviti prestasi generalisasi WSAM kepada hiperparameter ini. Kami melatih model ResNet18 dan WRN-28-10 menggunakan WSAM pada Cifar10 dan Cifar100, menggunakan pelbagai nilai
untuk menskalakan saiz istilah darjah rata (curam). Di sini, kami menguji sensitiviti prestasi generalisasi WSAM kepada hiperparameter ini. Kami melatih model ResNet18 dan WRN-28-10 menggunakan WSAM pada Cifar10 dan Cifar100, menggunakan pelbagai nilai 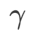 . Seperti yang ditunjukkan dalam Rajah 3, keputusan menunjukkan bahawa WSAM tidak sensitif terhadap pilihan hiperparameter
. Seperti yang ditunjukkan dalam Rajah 3, keputusan menunjukkan bahawa WSAM tidak sensitif terhadap pilihan hiperparameter 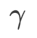 . Kami juga mendapati bahawa prestasi generalisasi optimum WSAM hampir selalu antara 0.8 dan 0.95.
. Kami juga mendapati bahawa prestasi generalisasi optimum WSAM hampir selalu antara 0.8 dan 0.95.
Atas ialah kandungan terperinci Lebih serba boleh dan berkesan, WSAM pengoptimum yang dibangunkan sendiri oleh Ant telah dipilih ke dalam KDD Oral. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!