
Rumah >Peranti teknologi >AI >Pecahkan kotak hitam model besar dan reput neuron sepenuhnya! Saingan OpenAI, Anthropic memecahkan halangan AI yang tidak dapat dijelaskan
Pecahkan kotak hitam model besar dan reput neuron sepenuhnya! Saingan OpenAI, Anthropic memecahkan halangan AI yang tidak dapat dijelaskan

- WBOYke hadapan
- 2023-10-08 23:13:011231semak imbas
Selama bertahun-tahun, kami tidak dapat memahami cara kecerdasan buatan membuat keputusan dan menjana output
Pembangun model hanya boleh memutuskan algoritma, data dan akhirnya mendapatkan output model, dan bahagian tengah - bagaimana model adalah berdasarkan Algoritma ini dan hasil output data menjadi "kotak hitam" yang tidak kelihatan.

Jadi ada jenaka seperti "latihan model seperti alkimia".
Tetapi kini, kotak hitam model akhirnya boleh ditafsirkan!
Pasukan penyelidik dari Anthropic mengekstrak ciri yang boleh ditafsirkan bagi neuron unit paling asas dalam rangkaian saraf model.

Ini akan menjadi langkah penting bagi manusia untuk mendedahkan kotak hitam AI.
Anthropic meluahkan rasa teruja:
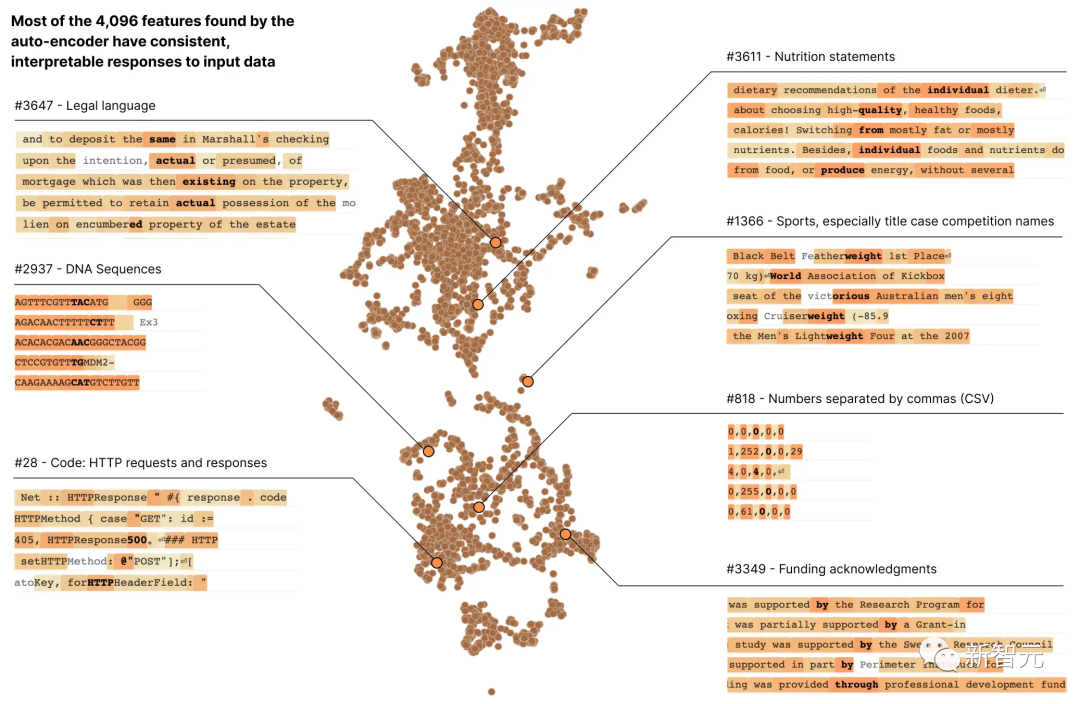
"Jika kita dapat memahami cara rangkaian saraf dalam model berfungsi, maka kita boleh mendiagnosis mod kegagalan model, pembetulan reka bentuk dan menjadikan model itu selamat diterima pakai oleh perusahaan dan masyarakat. Ia akan menjadi realiti dalam jangkauan! daripada 4000 ciri yang boleh ditafsir
Alamat laporan penyelidikan: https://transformer-circuits.pub/2023/monosemantic-features/index.html
 Ciri-ciri ini mewakili permintaan DNA, bahasa undang-undang, Teks Ibrani, dan kenyataan fakta pemakanan, dsb.
Ciri-ciri ini mewakili permintaan DNA, bahasa undang-undang, Teks Ibrani, dan kenyataan fakta pemakanan, dsb.
Kita tidak dapat melihat kebanyakan sifat model ini apabila kita melihat pengaktifan neuron tunggal secara berasingan
Kebanyakan neuron adalah "polisemantik," yang bermaksud di sana. tiada surat-menyurat yang konsisten antara neuron individu dan tingkah laku rangkaian
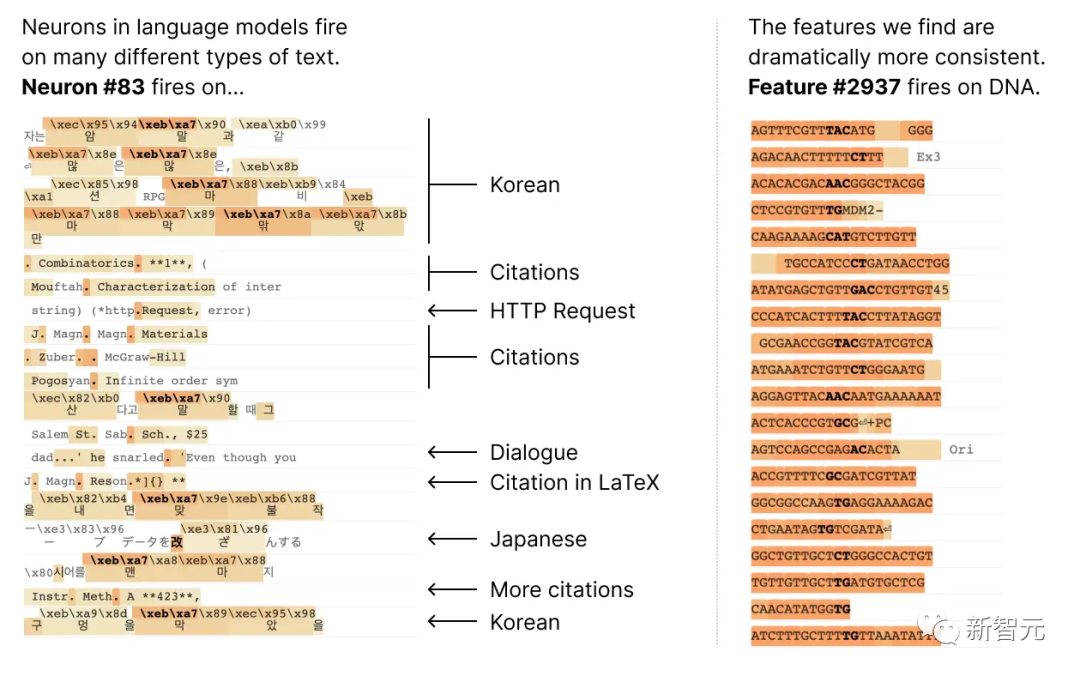
 Sebagai contoh, dalam model bahasa kecil, satu neuron Meta aktif dalam banyak konteks yang tidak berkaitan, termasuk: petikan akademik, perbualan bahasa Inggeris, permintaan HTTP dan teks Korea.
Sebagai contoh, dalam model bahasa kecil, satu neuron Meta aktif dalam banyak konteks yang tidak berkaitan, termasuk: petikan akademik, perbualan bahasa Inggeris, permintaan HTTP dan teks Korea.
Dan dalam model penglihatan klasik, neuron tunggal akan bertindak balas kepada muka kucing dan hadapan kereta.
Dalam konteks yang berbeza, banyak kajian telah membuktikan bahawa pengaktifan neuron boleh mempunyai makna yang berbeza
Salah satu sebab yang berpotensi ialah sifat polisemantik neuron adalah disebabkan oleh kesan superposisi. Ini adalah fenomena hipotesis bahawa rangkaian saraf mewakili ciri bebas data dengan memberikan setiap ciri gabungan linear neuronnya sendiri, dan bilangan ciri tersebut melebihi bilangan neuron
 Jika setiap ciri ditetapkan Jika ciri itu dianggap sebagai vektor pada neuron, maka set ciri membentuk asas linear yang terlalu lengkap untuk pengaktifan neuron rangkaian.
Jika setiap ciri ditetapkan Jika ciri itu dianggap sebagai vektor pada neuron, maka set ciri membentuk asas linear yang terlalu lengkap untuk pengaktifan neuron rangkaian.
Dalam kertas Model Mainan Superposisi ("Model Mainan Superposisi") Anthropic sebelum ini, telah terbukti bahawa kesederhanaan boleh menghapuskan kekaburan dalam latihan rangkaian saraf, membantu model lebih memahami hubungan antara ciri, dengan itu mengurangkan pengaktifan Ketidakpastian ciri sumber vektor menjadikan ramalan dan keputusan model lebih dipercayai.
Konsep ini sama dengan idea dalam penderiaan termampat, di mana keterlanjuran isyarat membolehkan isyarat lengkap dipulihkan daripada pemerhatian terhad.

Tetapi antara tiga strategi yang dicadangkan dalam Toy Models of Superposition:
(1) mencipta model tanpa superposisi, mungkin menggalakkan pengaktifan sparsity
pembelajaran, model dalam keadaan superposisi (2) digunakan untuk mencari ciri yang terlalu lengkap
(3) bergantung pada kaedah hibrid yang menggabungkan kedua-duanya.
Apa yang perlu ditulis semula ialah: kaedah (1) tidak dapat menyelesaikan masalah kekaburan, manakala kaedah (2) terdedah kepada overfitting teruk
Oleh itu, kali ini penyelidik Anthropic menggunakan Algoritma pembelajaran kamus yang lemah dipanggil jarang. autoencoder menjana ciri yang dipelajari daripada model terlatih yang menyediakan satu unit analisis semantik daripada neuron model itu sendiri.
Secara khusus, penyelidik menggunakan pengubah satu lapisan MLP dengan 512 neuron, dan akhirnya menguraikan pengaktifan MLP kepada yang agak boleh ditafsir dengan melatih pengekod automatik yang jarang pada pengaktifan MLP daripada 8 bilion ciri titik data, faktor pengembangan berjulat daripada 1 × (512 ciri) hingga 256× (131,072 ciri).
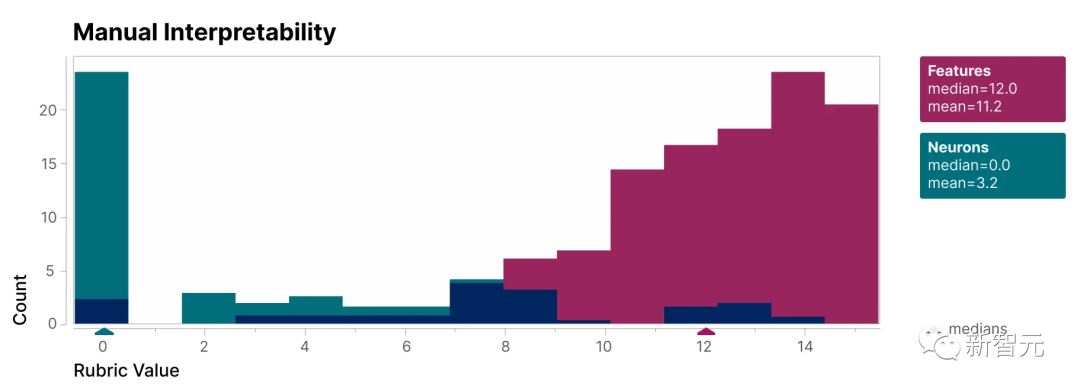
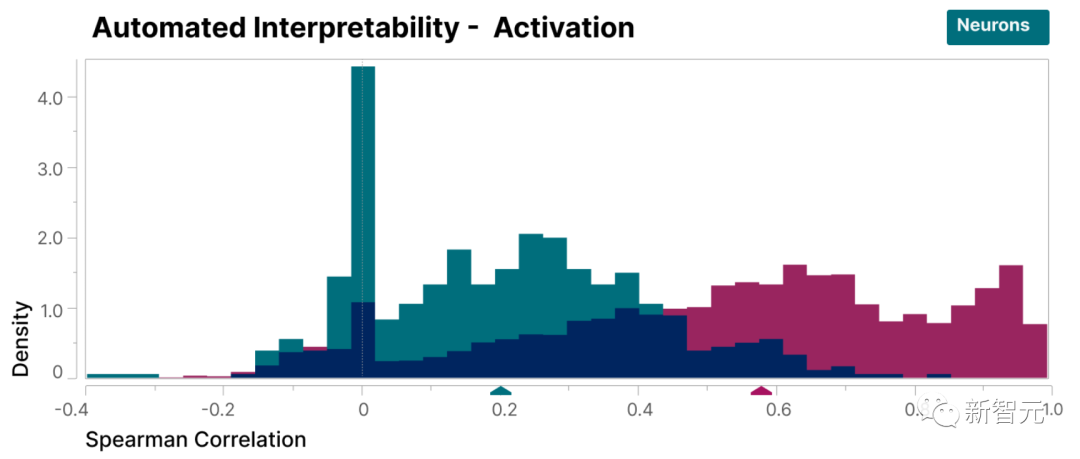
Untuk mengesahkan bahawa ciri-ciri yang terdapat dalam kajian ini lebih boleh ditafsirkan daripada neuron model, kami menjalankan penilaian semakan buta dan mempunyai penilai manusia menilai kebolehtafsirannya
boleh dilihat, ciri (merah) mempunyai lebih tinggi. skor daripada neuron (cyan).
Telah terbukti bahawa ciri-ciri yang ditemui oleh penyelidik lebih mudah difahami berbanding dengan neuron di dalam model
Selain itu, penyelidik juga menggunakan kaedah "automatic interpretability" dengan menggunakan The large model bahasa menjana penerangan ringkas tentang ciri model kecil dan membolehkan model lain menjaringkan huraian itu berdasarkan keupayaannya untuk meramalkan pengaktifan ciri.
Begitu juga, ciri skor lebih tinggi daripada neuron, menunjukkan tafsiran yang konsisten tentang pengaktifan ciri dan kesan hilirannya pada tingkah laku model.
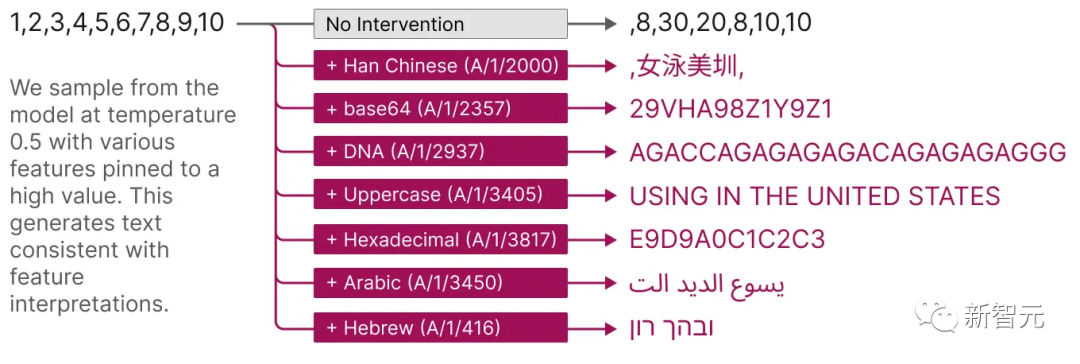
Selain itu, ciri yang diekstrak ini juga menyediakan kaedah yang disasarkan untuk membimbing model.
Seperti yang ditunjukkan dalam rajah di bawah, ciri pengaktifan buatan boleh menyebabkan tingkah laku model berubah dalam cara yang boleh diramal.
Berikut ialah visualisasi ciri kebolehtafsiran yang diekstrak:
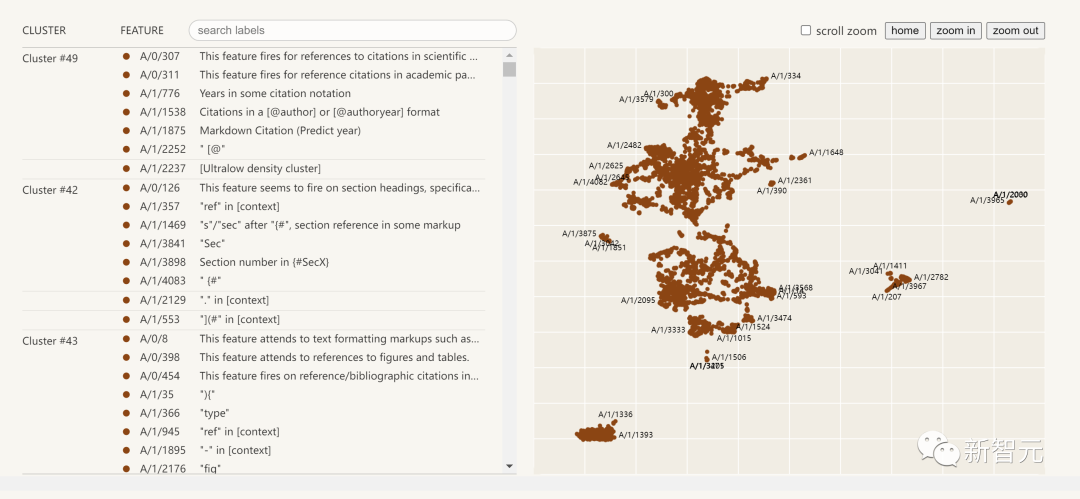
Klik pada senarai ciri di sebelah kiri dan anda boleh meneroka secara interaktif ruang ciri dalam rangkaian saraf
Ringkasan LaporanLaporan penyelidikan daripada Anthropic, Towards Monosemanticity: Decomposing Language Models With Dictionary Learning ini, boleh dibahagikan kepada empat bahagian.
Tetapan masalah, penyelidik memperkenalkan motivasi penyelidikan dan menghuraikan transfomer terlatih dan pengekod auto jarang.
Penyiasatan terperinci tentang ciri-ciri individu, membuktikan bahawa beberapa ciri yang ditemui dalam kajian adalah unit kausa yang khusus berfungsi.
Melalui analisis global, kami menyimpulkan bahawa ciri tipikal boleh ditafsir, dan ia dapat menerangkan komponen penting lapisan MLP
Analisis fenomena, menerangkan beberapa sifat ciri, termasuk pembahagian ciri, sifat kesejagatan dan bagaimana mereka membentuk sistem yang serupa dengan "automata keadaan terhingga" untuk mencapai tingkah laku yang kompleks.
Kesimpulannya termasuk 7 berikut:
Pengekod auto jarang mempunyai keupayaan untuk mengekstrak ciri semantik yang agak tunggal
Pengekod auto jarang boleh menjana ciri yang boleh ditafsirkan yang sebenarnya tidak kelihatan dalam asas neuron 3. Pengekod auto jarang boleh digunakan untuk campur tangan dan membimbing penjanaan transformer. 4. Pengekod auto jarang boleh menjana ciri yang agak umum. Apabila saiz pengekod auto bertambah, ciri cenderung untuk "berpecah".
Selepas menulis semula: Apabila saiz autoenkoder bertambah, ciri menunjukkan trend "pemisahan" 6 Hanya 512 neuron boleh mewakili beribu-ribu ciri 7 "automaton keadaan terhingga" mencapai gelagat yang kompleks, seperti yang ditunjukkan dalam rajah di bawah Untuk butiran khusus, sila lihat laporan. Anthropic percaya bahawa untuk meniru kejayaan model kecil dalam laporan penyelidikan ini kepada model yang lebih besar, cabaran yang kita hadapi pada masa hadapan bukan lagi masalah saintifik, tetapi masalah kejuruteraan Untuk mencapai matlamat ini pada model yang besar Kebolehtafsiran memerlukan lebih banyak usaha dan sumber dalam bidang kejuruteraan untuk mengatasi cabaran yang ditimbulkan oleh kerumitan dan skala model Termasuk pembangunan alat, teknik dan kaedah baharu untuk menghadapi cabaran kerumitan model dan skala data ; juga termasuk membina rangka kerja tafsiran berskala dan alatan untuk menampung keperluan model berskala besar. Ini akan menjadi trend terkini dalam bidang kecerdasan buatan tafsiran dan penyelidikan pembelajaran mendalam berskala besar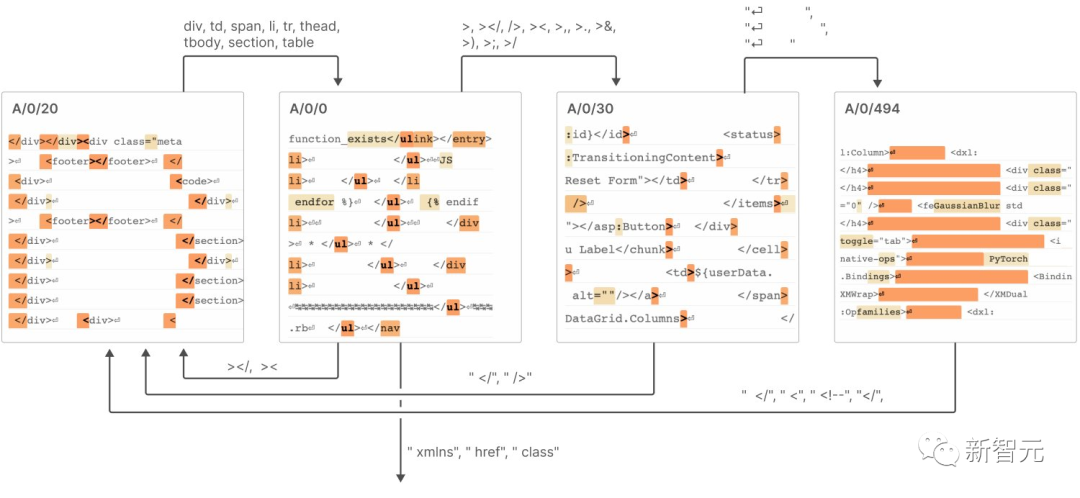
Atas ialah kandungan terperinci Pecahkan kotak hitam model besar dan reput neuron sepenuhnya! Saingan OpenAI, Anthropic memecahkan halangan AI yang tidak dapat dijelaskan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!