
Rumah >Peranti teknologi >AI >Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt
Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt

- 王林ke hadapan
- 2023-10-07 12:13:011761semak imbas
Pada tahun 2018, Google mengeluarkan BERT Setelah ia dikeluarkan, ia mengalahkan keputusan terkini (Sota) bagi 11 tugasan NLP dalam satu masa, menjadi tonggak baharu dalam dunia NLP ditunjukkan dalam rajah di bawah. Di sebelah kiri ialah proses pra-latihan Model BERT, sebelah kanan ialah proses penalaan halus untuk tugasan tertentu. Antaranya, peringkat penalaan halus adalah untuk penalaan halus apabila ia kemudiannya digunakan dalam beberapa tugas hiliran, seperti klasifikasi teks, penandaan sebahagian daripada pertuturan, sistem soal jawab, dsb. BERT boleh diperhalusi pada pelbagai tugas tanpa melaraskan struktur. Melalui reka bentuk tugasan "model bahasa pra-latihan + penalaan halus tugas hiliran", ia telah membawa kesan model yang hebat. Sejak itu, "model bahasa pra-latihan + penalaan tugas hiliran" telah menjadi paradigma latihan arus perdana dalam bidang NLP.
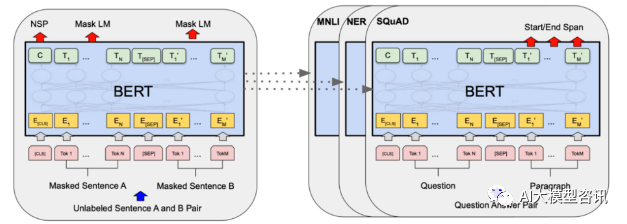 Gambarajah struktur BERT, sebelah kiri ialah proses pra-latihan, dan sebelah kanan ialah proses penalaan halus tugas khusus
Gambarajah struktur BERT, sebelah kiri ialah proses pra-latihan, dan sebelah kanan ialah proses penalaan halus tugas khusus
Selain itu, sepenuhnya penalaan halus model juga akan menyebabkan kehilangan kepelbagaian dan mengalami masalah lupa yang serius. Oleh itu, cara melakukan penalaan halus model dengan cekap telah menjadi tumpuan penyelidikan industri, yang turut menyediakan ruang penyelidikan untuk pembangunan pesat teknologi penalaan halus parameter yang cekap 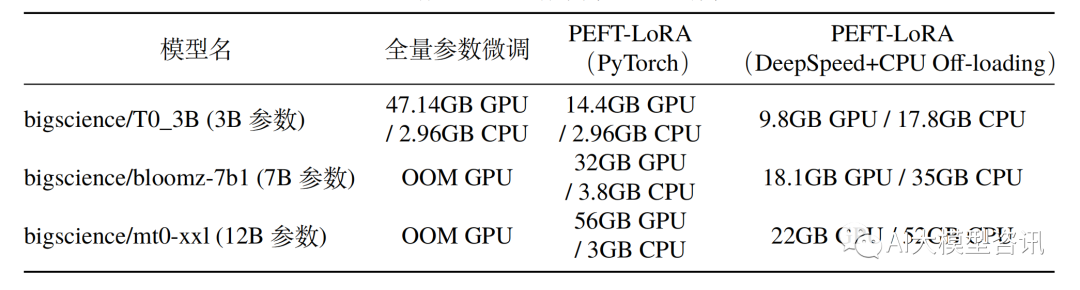 Penalaan halus parameter yang cekap merujuk kepada penalaan halus dalam jumlah yang kecil atau parameter model tambahan dan menetapkan kebanyakan parameter model pra-latihan (LLM), sekali gus mengurangkan kos pengkomputeran dan penyimpanan Pada masa yang sama, ia juga boleh mencapai prestasi yang setanding dengan penalaan halus parameter penuh. Kaedah penalaan halus yang cekap parameter adalah lebih baik daripada penalaan halus penuh dalam beberapa kes, dan boleh digeneralisasikan dengan lebih baik kepada senario luar domain.
Penalaan halus parameter yang cekap merujuk kepada penalaan halus dalam jumlah yang kecil atau parameter model tambahan dan menetapkan kebanyakan parameter model pra-latihan (LLM), sekali gus mengurangkan kos pengkomputeran dan penyimpanan Pada masa yang sama, ia juga boleh mencapai prestasi yang setanding dengan penalaan halus parameter penuh. Kaedah penalaan halus yang cekap parameter adalah lebih baik daripada penalaan halus penuh dalam beberapa kes, dan boleh digeneralisasikan dengan lebih baik kepada senario luar domain.
Teknologi dan kaedah penalaan halus cekap parameter biasa
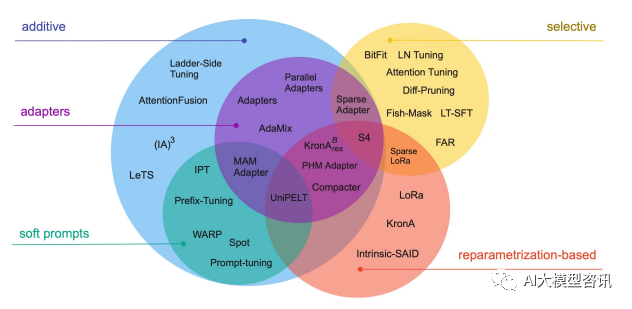 BitFit/Prefix/Prompt siri penalaan halus
BitFit/Prefix/Prompt siri penalaan halus
untuk semua Penalaan penuh untuk setiap tugas adalah sangat berkesan, tetapi ia juga menghasilkan model besar yang unik untuk setiap tugasan yang telah dilatih, yang menjadikannya sukar untuk membuat kesimpulan tentang perubahan yang berlaku semasa proses penalaan halus dan sukar untuk digunakan, terutamanya apabila bilangan tugas meningkat meningkat, ia adalah sukar untuk mengekalkan.
Sebaik-baiknya, kami ingin mempunyai kaedah penalaan halus yang cekap yang memenuhi syarat berikut: Persoalan di atas bergantung kepada sejauh mana proses penalaan halus dapat membimbing pembelajaran kebolehan baharu dan kebolehan yang dipelajari melalui pendedahan kepada LM pra-latihan. Walaupun, kaedah penalaan halus yang cekap sebelum ini Adapter-Tuning dan Diff-Pruning juga boleh memenuhi sebahagian keperluan di atas. BitFit, kaedah penalaan halus yang jarang dengan parameter yang lebih kecil, boleh memenuhi semua keperluan di atas. BitFit ialah kaedah penalaan halus yang jarang Ia hanya mengemas kini parameter berat sebelah atau sebahagian daripada parameter berat sebelah semasa latihan. Untuk model Transformer, kebanyakan parameter pengubah-pengekod dibekukan, dan hanya parameter bias dan parameter lapisan pengelasan tugas tertentu dikemas kini. Parameter bias yang terlibat termasuk bias yang terlibat dalam mengira pertanyaan, kunci, nilai dan menggabungkan hasil perhatian berbilang dalam modul perhatian, bias dalam lapisan MLP, parameter bias dalam lapisan Layernormalization dan parameter bias dalam model pra-latihan. seperti yang ditunjukkan dalam rajah di bawah. Picture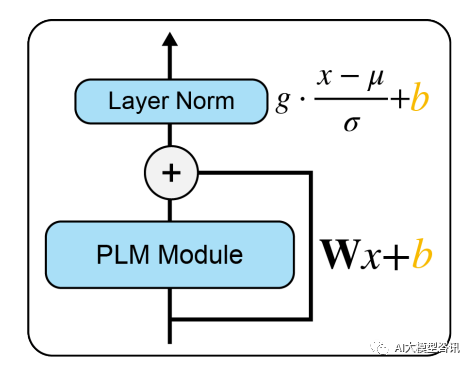 Modul PLM mewakili sub-lapisan PLM tertentu, seperti perhatian atau FFN Blok oren dalam gambar mewakili vektor pembayang boleh dilatih, dan blok biru mewakili parameter model pra-latihan beku.
Modul PLM mewakili sub-lapisan PLM tertentu, seperti perhatian atau FFN Blok oren dalam gambar mewakili vektor pembayang boleh dilatih, dan blok biru mewakili parameter model pra-latihan beku.
Dalam model seperti Bert-Base/Bert-Large, parameter bias hanya menyumbang 0.08%~0.09% daripada jumlah parameter model. Walau bagaimanapun, dengan membandingkan kesan BitFit, Adapter dan Diff-Pruning pada model Bert-Large berdasarkan set data GLUE, didapati bahawa BitFit mempunyai kesan yang sama seperti Adapter dan Diff-Pruning apabila bilangan parameter jauh lebih kecil. daripada Adapter dan Diff-Pruning , malah lebih baik sedikit daripada Adapter dan Diff-Pruning dalam beberapa tugas.
Ia dapat dilihat daripada keputusan percubaan bahawa berbanding dengan penalaan halus parameter penuh, penalaan halus BitFit hanya mengemas kini bilangan parameter yang sangat kecil dan telah mencapai keputusan yang baik pada beberapa set data. Walaupun ia tidak sebaik menala halus semua parameter, ia jauh lebih baik daripada kaedah Frozen untuk menetapkan semua parameter model. Pada masa yang sama, dengan membandingkan parameter sebelum dan selepas latihan BitFit, didapati banyak parameter bias tidak banyak berubah, seperti parameter berat sebelah yang berkaitan dengan pengiraan kunci. Didapati bahawa parameter bias lapisan FFN yang mengira pertanyaan dan membesarkan dimensi ciri dari N kepada 4N mempunyai perubahan yang paling jelas Hanya mengemas kini kedua-dua jenis parameter bias ini juga boleh mencapai keputusan yang baik. Sebaliknya, jika salah satu daripadanya diperbaiki, kesan model akan hilang dengan ketara
Pelajaran Awalan
Sebelum Penalaan Awalan, kerjanya adalah untuk mereka bentuk templat diskret secara manual atau mencari templat diskret secara automatik. Untuk templat yang direka secara manual, perubahan dalam templat amat sensitif terhadap prestasi akhir model Menambah perkataan, kehilangan perkataan atau menukar kedudukan akan menyebabkan perubahan yang agak besar. Untuk templat carian automatik, kosnya agak tinggi pada masa yang sama, hasil carian token diskret sebelumnya mungkin tidak optimum. Selain itu, paradigma penalaan halus tradisional menggunakan model yang telah dilatih untuk memperhalusi tugas hiliran yang berbeza, dan berat model yang ditala halus mesti disimpan untuk setiap tugasan, dalam satu tangan, penalaan halus keseluruhan model mengambil masa yang lama masa; sebaliknya, ia juga akan mengambil banyak ruang penyimpanan. Berdasarkan dua perkara di atas, Penalaan Awalan mencadangkan LM pra-latihan tetap, menambahkan awalan khusus tugasan yang boleh dilatih pada LM, supaya awalan yang berbeza boleh disimpan untuk tugasan yang berbeza, dan kos penalaan halus juga kecil; Pada masa yang sama, Prefix jenis ini sebenarnya boleh dilatih secara berterusan Micro Virtual Token (Soft Prompt/Continuous Prompt) adalah lebih baik dioptimumkan dan mempunyai kesan yang lebih baik daripada Token diskret.
Jadi, apa yang perlu ditulis semula ialah: Jadi apakah maksud awalan? Peranan awalan adalah untuk membimbing model untuk mengekstrak maklumat yang berkaitan dengan x, supaya dapat menjana y dengan lebih baik. Sebagai contoh, jika kita ingin melakukan tugasan ringkasan, maka selepas penalaan halus, awalan boleh memahami bahawa tugasan semasa ialah tugasan "bentuk ringkasan", dan kemudian membimbing model untuk mengekstrak maklumat utama daripada x jika kita mahu lakukan klasifikasi emosi Tugas, awalan boleh membimbing model untuk mengekstrak maklumat semantik yang berkaitan dengan emosi dalam x, dan sebagainya. Penjelasan ini mungkin tidak begitu ketat, tetapi anda boleh memahami secara kasar peranan awalan
Penalaan Awalan adalah untuk membina token maya berkaitan tugasan sebagai Awalan sebelum memasukkan token, dan kemudian hanya mengemas kini parameter bahagian Awalan semasa latihan, manakala dalam PLM Parameter lain ditetapkan. Untuk struktur model yang berbeza, Awalan yang berbeza perlu dibina:
- Untuk model seni bina autoregresif: tambahkan awalan di hadapan ayat untuk mendapatkan z = [Awalan x; konteks (contohnya: pembelajaran konteks GPT3).
- Untuk model seni bina pengekod-penyahkod: awalan ditambahkan pada Pengekod dan Penyahkod, menghasilkan z = [PREFIX y]. Awalan ditambahkan pada bahagian Pengekod untuk membimbing pengekodan bahagian input, dan awalan ditambah pada bahagian Penyahkod untuk membimbing penjanaan token berikutnya.
 Gambar
Gambar
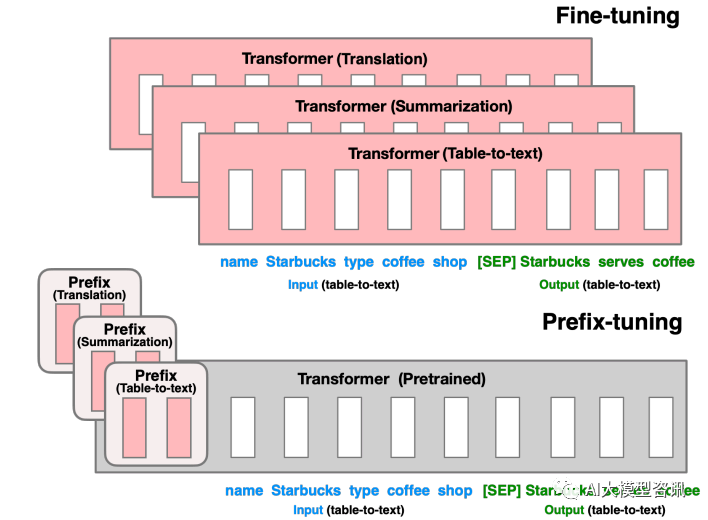
Tulis semula kandungan tanpa mengubah maksud asal, dan tulis semula dalam bahasa Cina: Untuk penalaan halus di bahagian sebelumnya, kami mengemas kini semua parameter Transformer (kotak merah) dan perlu menyimpan salinan lengkap model untuk setiap tugas. Pelarasan awalan di bahagian bawah akan membekukan parameter Transformer dan hanya mengoptimumkan awalan (kotak merah)
Kaedah ini sebenarnya serupa dengan membina Prompt, kecuali Prompt ialah gesaan "eksplisit" yang dibina secara buatan dan parameter tidak boleh dikemas kini, dan Awalan ialah petunjuk "tersirat" yang boleh dipelajari. Pada masa yang sama, untuk mengelakkan kemas kini langsung parameter Prefix daripada menyebabkan latihan tidak stabil dan kemerosotan prestasi, struktur MLP ditambah di hadapan lapisan Prefix Selepas latihan selesai, hanya parameter Prefix dikekalkan. Selain itu, eksperimen ablasi telah membuktikan bahawa melaraskan lapisan pembenaman sahaja tidak cukup ekspresif dan akan membawa kepada penurunan prestasi yang ketara Oleh itu, parameter segera ditambahkan pada setiap lapisan dan perubahannya adalah besar.
Walaupun Penalaan Awalan kelihatan mudah, ia juga mempunyai dua kelemahan penting berikut:Penalaan Pantas
Penalaan penuh model besar melatih model untuk setiap tugas, yang mempunyai kos overhed dan penggunaan yang agak tinggi. Pada masa yang sama, kaedah gesaan diskret (merujuk kepada gesaan reka bentuk secara manual dan menambah gesaan pada model) agak mahal dan kesannya tidak begitu baik. Prompt Tuning mempelajari gesaan dengan menyebarkan balik parameter yang dikemas kini dan bukannya mereka bentuk gesaan secara manual pada masa yang sama, ia membekukan pemberat asal model dan hanya melatih parameter gesaan Selepas latihan, model yang sama boleh digunakan untuk inferens berbilang tugas.
 Gambar
Gambar
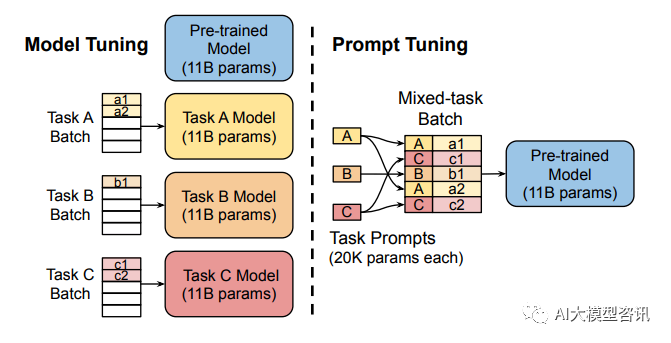
Penalaan model memerlukan membuat salinan khusus tugasan bagi keseluruhan model pra-latihan untuk setiap tugasan hiliran dan inferens mestilah dalam kelompok yang berasingan. Penalaan Gesaan hanya memerlukan menyimpan gesaan khusus tugasan kecil untuk setiap tugasan dan mendayakan inferens tugas bercampur menggunakan model asal yang telah dilatih.
Penalaan Pantas boleh dilihat sebagai versi Penalaan Awalan yang dipermudahkan Ia mentakrifkan gesaannya sendiri untuk setiap tugasan dan kemudian menyambungkannya ke dalam data sebagai input, tetapi hanya menambah token gesaan pada lapisan input dan tidak perlu menambah MLP. untuk pelarasan untuk menyelesaikan masalah latihan yang sukar.
Telah didapati melalui eksperimen bahawa apabila bilangan parameter model pra-latihan meningkat, kaedah Prompt Tuning akan menghampiri hasil penalaan halus parameter penuh. Pada masa yang sama, Prompt Tuning juga mencadangkan Prompt Ensembling, yang bermaksud melatih gesaan yang berbeza untuk tugas yang sama pada masa yang sama dalam satu kelompok (iaitu, bertanya soalan yang sama dalam pelbagai cara yang berbeza). Contohnya Kos integrasi model adalah jauh lebih kecil. Selain itu, kertas Prompt Tuning juga membincangkan kesan kaedah permulaan dan panjang token Prompt pada prestasi model. Melalui keputusan eksperimen ablasi, didapati Prompt Tuning menggunakan label kelas untuk memulakan model dengan lebih baik daripada pengamulaan rawak dan permulaan menggunakan kosa kata sampel. Walau bagaimanapun, apabila skala parameter model meningkat, jurang ini akhirnya akan hilang. Prestasi sudah baik apabila panjang token Prompt adalah sekitar 20 (selepas melebihi 20, peningkatan panjang token Prompt tidak akan meningkatkan prestasi model dengan ketara. Begitu juga, jurang ini juga akan berkurangan apabila skala parameter model meningkat (). Iaitu, untuk model berskala sangat besar, walaupun panjang token Prompt sangat pendek, ia tidak akan memberi banyak kesan kepada prestasi).
Atas ialah kandungan terperinci Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Untuk pemahaman yang menyeluruh tentang model bahasa besar, berikut ialah senarai bacaan
- Meta AI membuka 600 juta+ peta struktur protein metagenomik, dan 15 bilion model bahasa telah disiapkan dalam masa dua minggu
- Syarikat domestik pertama, 360 Intelligent Brain lulus penilaian fungsi model bahasa besar AIGC yang dipercayai oleh Akademi Teknologi Maklumat dan Komunikasi China.