
Rumah >Peranti teknologi >AI >Bagaimanakah Agen AI dilaksanakan? 6 foto 4090 sihir diubah suai Llama2: membahagikan tugas dan memanggil fungsi dengan satu arahan
Bagaimanakah Agen AI dilaksanakan? 6 foto 4090 sihir diubah suai Llama2: membahagikan tugas dan memanggil fungsi dengan satu arahan

- 王林ke hadapan
- 2023-09-25 19:49:051351semak imbas
AI Ejen kini menjadi medan hangat Dalam artikel panjang [1] yang ditulis oleh LilianWeng, pengarah penyelidikan aplikasi OpenAI, beliau mencadangkan konsep Ejen = LLM + ingatan + kemahiran merancang + penggunaan alat# Rajah. 1 Gambaran keseluruhan sistem ejen autonomi berkuasa LLM
Peranan Ejen ialah menggunakan pemahaman bahasa yang berkuasa LLM dan keupayaan penaakulan logik untuk memanggil alatan untuk membantu manusia menyelesaikan tugas. Walau bagaimanapun, ini juga membawa beberapa cabaran Sebagai contoh, keupayaan model asas menentukan kecekapan alat panggilan Ejen, tetapi model asas itu sendiri mempunyai masalah seperti ilusi model besar
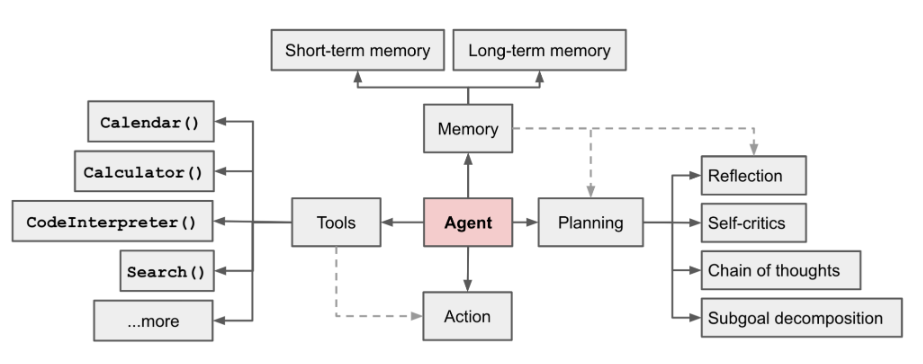 .
.
" Tunggu sehingga modul "Task Splitting" dan "Function Calling" berjaya dibina.
Kandungan yang ditulis semula ialah: Alamat:
#🎜 #https://sota.jiqizhixin.com/project/smart_agent
GitHub Repo: #🎜# #🎜##🎜 🎜🎜#
Kandungan yang perlu ditulis semula ialah: https://github.com/zzlgreat/smart_agent#🎜 # Pembahagian tugas & panggilan fungsi Proses ejen
Untuk pelaksanaan "memasukkan perintah untuk melaksanakan pemisahan tugas dan panggilan fungsi secara automatik", proses Ejen dibina oleh projek Seperti berikut:
planner:
Split tasks berdasarkan #Split tasks dimasukkan oleh pengguna. Tentukan kit alat senarai alat yang anda ada, dan beritahu perancang, model besar yang membahagikan tugas, alat yang anda ada dan tugasan yang perlu anda selesaikan Perancang membahagikan tugas kepada pelan 1, 2, 3...#🎜🎜. ##🎜🎜 #pengedar:
bertanggungjawab untuk memilih alatan yang sesuai untuk rancangan pelaksanaan toolkit. Model panggilan fungsi memerlukan pemilihan alat yang sepadan mengikut pelan yang berbeza.
- worker: Bertanggungjawab untuk memanggil tugas dalam kotak alat dan mengembalikan hasil panggilan tugas.
- solver: Pelan pengedaran yang diisih dan hasil yang sepadan digabungkan menjadi cerita panjang, yang kemudiannya diringkaskan oleh penyelesai.
- Rajah 1 "ReWOO: Penaakulan Penyahgandingan" #Pemerhatian🎜 Bahasa yang Dipertingkatkan untuk Cekap #Untuk merealisasikan proses di atas, dalam modul "Task Splitting" dan "Function Calling", projek itu mereka bentuk dua model penalaan halus masing-masing untuk membahagikan tugas yang kompleks dan mengaturnya mengikut keperluan Fungsi yang memerlukan panggilan fungsi tersuai. Penyelesai model yang diringkaskan boleh sama dengan model tugas berpecah
- Pecahan tugasan yang ditala halus & model panggilan fungsi # 🎜🎜#
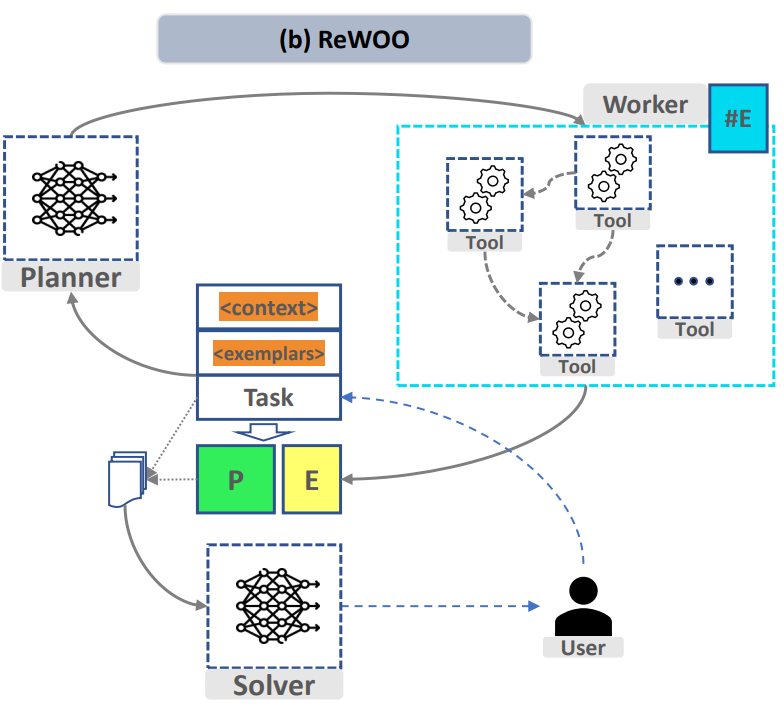
Dalam modul "Task Splitting", model besar perlu boleh dinyahkomikan tugasan kompleks kepada tugasan mudah keupayaan tugas. Kejayaan "pembahagian tugas" terutamanya bergantung kepada dua faktor:
Pemilihan model asas: #🎜 🎜 Untuk membahagikan tugas yang rumit, model asas yang dipilih untuk penalaan halus perlu mempunyai kebolehan pemahaman dan generalisasi yang baik, iaitu, pembahagian tugas yang tidak dilihat dalam set latihan mengikut arahan segera. Pada masa ini, lebih mudah untuk melakukan ini dengan memilih model besar dengan parameter tinggi.
Prompt Design
#🎜 sama ada model boleh dipanggil: berjaya Satu rantaian pemikiran yang membahagikan tugas kepada subtugas.
- Pada masa yang sama, kami berharap format output model pemisahan tugas di bawah templat gesaan yang diberikan boleh ditetapkan secara relatifnya seboleh-bolehnya, tetapi ia tidak akan berlebihan kerana kehilangan keupayaan penaakulan dan generalisasi model Di sini, lapisan qv penalaan halus digunakan untuk membuat sedikit perubahan struktur pada model asal.
- Dalam modul "Panggilan Fungsi", model besar perlu mempunyai keupayaan untuk memanggil alatan secara stabil untuk menyesuaikan diri dengan keperluan tugasan pemprosesan: #🎜 🎜#
- Pelarasan fungsi kehilangan: Sebagai tambahan kepada kebolehan generalisasi dan reka bentuk segera model asas yang dipilih itu sendiri, untuk mencapai output model yang ditetapkan sebaik mungkin dan untuk memanggil fungsi yang diperlukan secara stabil mengikut output, "prompt loss-mask" digunakan Kaedah [2] melaksanakan latihan qlora (lihat butiran di bawah), dan menggunakan helah memasukkan token eos dalam penalaan halus qlora untuk menstabilkan output model dengan menukar perhatian secara ajaib topeng.
Selain itu, dari segi penggunaan kuasa pengkomputeran, penalaan halus dan inferens model bahasa besar di bawah keadaan kuasa pengkomputeran rendah dicapai melalui penalaan halus lora/qlora, dan penggunaan kuantitatif diguna pakai untuk menurunkan lagi ambang untuk inferens.
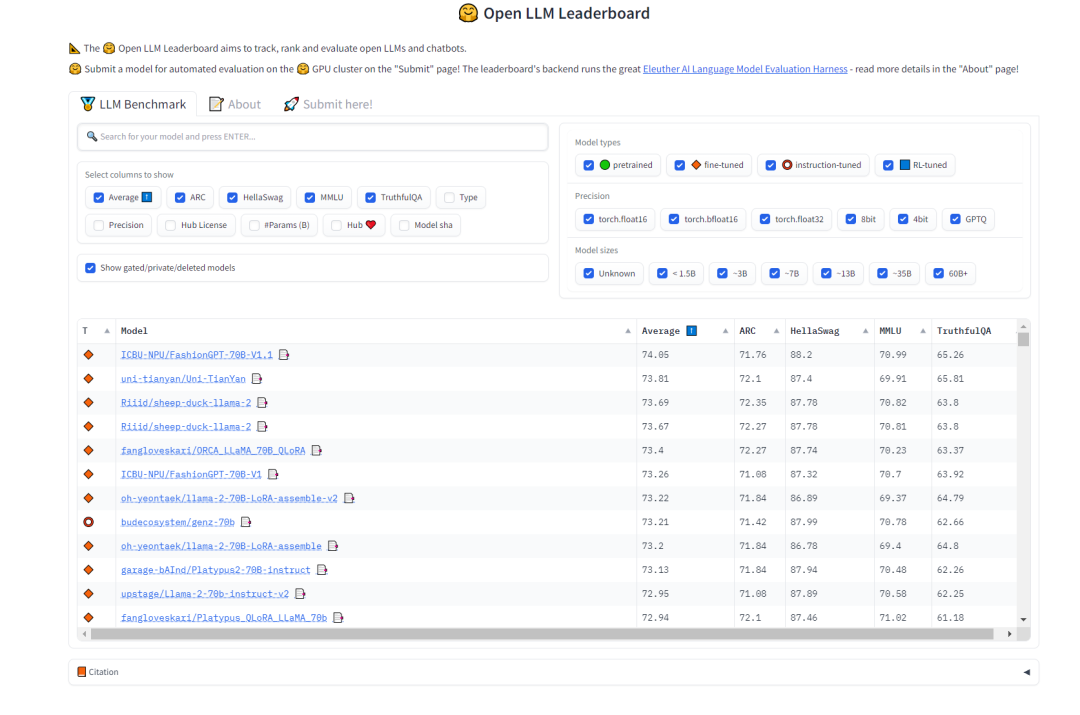
2.2 Pemilihan model asas
Untuk memilih model "pemecahan tugas", kami berharap model tersebut mempunyai keupayaan generalisasi yang kukuh dan keupayaan rantai pemikiran tertentu. Dalam hal ini, kami boleh merujuk kepada pemeringkatan LLM Terbuka di HuggingFace untuk memilih model Kami lebih mengambil berat tentang ujian MMLU dan Purata skor komprehensif yang mengukur ketepatan pelbagai tugas model teks

. Perlu ditulis semula Kandungannya ialah: Rajah 2 Huggingface Terbuka LLM Kedudukan (0921)
Tugas model pemisahan tugas yang dipilih untuk projek ini adalah:
- AIDC-AI-Business/Marcoroni -70B: Model ini berdasarkan penalaan halus Llama2 70B dan bertanggungjawab untuk membahagikan tugas. Menurut Papan Pendahulu LLM Terbuka pada HuggingFace, MMLU dan purata model ini agak tinggi, dan sejumlah besar data gaya Orca ditambahkan pada proses latihan model ini, yang sesuai untuk beberapa pusingan dialog Dalam pelan -agih-rancang-kerja-kerja ...prestasi akan lebih baik dalam proses rumusan.
Untuk memilih model "panggilan fungsi", data latihan asal versi Llama2 sumber terbuka meta model pengaturcaraan CodeLlama mengandungi sejumlah besar data kod, jadi anda boleh cuba menggunakan qlora untuk skrip tersuai halus- penalaan. Untuk model panggilan fungsi, pilih model CodeLlama (34b/13b/7b boleh diterima) sebagai penanda aras
Projek ini memilih model model panggilan fungsi:
- bertanggungjawab untukb/codellama 3 panggilan fungsi Model dilatih menggunakan sejumlah besar data kod Data kod mesti mengandungi sejumlah besar perihalan bahasa semula jadi bagi fungsi, dan mempunyai keupayaan sifar tangkapan yang baik untuk menerangkan fungsi tertentu.
🎜Untuk memperhalusi model "panggilan fungsi", projek ini menggunakan kaedah latihan topeng kehilangan segera untuk menstabilkan output model. Berikut ialah cara fungsi kehilangan dilaraskan: 🎜🎜
- #🎜🎜 #topeng_kerugian:
- Contohnya, jika sesetengah label berlapik (biasanya kerana urutan dalam kelompok adalah berbeza panjang), anda tidak mahu kehilangan Label berpenduduk ini diambil kira dalam pengiraan. Dalam kes ini, loss_mask memberikan 0 untuk lokasi ini, dengan itu menutup kerugian di lokasi ini.
- #🎜🎜🎜##🎜🎜🎜##🎜🎜🎜##🎜🎜 #
- Pertama, CrossEntropyLoss digunakan untuk mengira kerugian tidak bertopeng.
- Tetapkan reductinotallow='tiada' untuk memastikan nilai kerugian dikembalikan untuk setiap kedudukan dalam jujukan, bukannya jumlah atau purata.
Kemudian, gunakan loss_mask untuk menutup kerugian. Masked_loss diperoleh dengan mendarab loss_mask dengan kerugian. Dengan cara ini, nilai kerugian kedudukan yang 0 dalam loss_mask juga 0 dalam masked_loss. - Agregasi kerugian:
- # #
- Jika semua nilai loss_mask ialah 0 (iaitu loss_mask.sum() == 0), maka terus kembali nilai kerugian 0.
- 2.3 Keperluan perkakasan:
#🎜🎜🎜##🎜🎜🎜##🎜🎜🎜 4090 untuk lora 16bit Marcoroni-70B
- 2*4090 untuk qlora codellama 34b / 1*4090 untuk codellama 13/7b#🎜 ##🎜 qlora ##🎜 🎜 🎜#
- 2.4 Reka bentuk format segera
- Dari segi pembahagian tugas, projek menggunakan kerangka kerja penaakulan cekap model bahasa besar ReWOO (Reasoning WithOut Pemerhatian ) Format segera yang direka oleh perancang. Hanya gantikan fungsi seperti 'Wikipedia[input]' dengan fungsi dan huraian yang sepadan Berikut adalah contoh gesaan:
For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following: Wikipedia[input]: Worker that search for similar page contents from Wikipedia. Useful when you need to get holistic knowledge about people, places, companies, historical events, or other subjects.The response are long and might contain some irrelevant information. Input should be a search query. LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense. Prioritize it when you are confident in solving the problem yourself. Input can be any instruction.
Untuk panggilan fungsi, kerana Qlora seterusnya baik-. penalaan akan dilakukan, jadi gaya gesaan dalam set data panggilan fungsi sumber terbuka [3] pada muka peluk digunakan secara langsung. Lihat di bawah.
Penyediaan Set Data Arahan
3.1 Sumber Data#🎜🎜🎜🎜🎜🎜🎜🎜🎜 #Model misi pembongkaran: Marcoroni-70B menggunakan templat segera alpaca. Model ini diperhalusi dengan arahan pada Llama2 70B Untuk menyelaraskan dengan templat model asal, set data dalam format alpaka diperlukan. Format set data perancang rewoo digunakan di sini, tetapi dalam set data asal hanya terdapat pilihan untuk memanggil wiki dan wikinya sendiri, jadi anda boleh menggunakan templat ini dan menggunakan antara muka gpt4 untuk mencipta set data gaya ini.
Model panggilan fungsi: Walaupun set data panggilan fungsi sumber terbuka HuggingFace yang dipilih mempunyai jumlah data yang kecil (55 baris), qlora sangat berkesan dalam set data ini Kod templat latihan juga disertakan.
3.2 Format set data
- #🎜🎜 format data: model split alpaca
### Instruction:<prompt> (without the )### Response:如:### Instruction:For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following:get_current_time[input]: Get the current time for now. search_bing[input]: Search the web for content on Bing, and return the top 10 results. Remember, the results may not as good as Wikipedia. If you think the result will not exist in wikipedia, use it. search_wiki[input]: Search the web for content on Wikipedia, and return the top 3 results. If you think the result can exist in wikipedia, use it. search_bilibili[input]: Search for videos on Bilibili, which is a website full of ACG. It can return top 10 search results. save_file[input]: save a file in the target dir which contains the data. query_mysql[input]: Execute the sql in the local mysql database. And return the result. What movies did the director of 'Oppenheim' direct? List the top 10 best.### Response:Step 1: Identify the director of "Oppenheimer" movie.#E1 = search_wiki("Director of Oppenheimer")Step 2: Retrieve information about the director's other works.If the retrieved name exists in Wikipedia, proceed with searching their filmography using search_wiki. Otherwise, try searching through Bing or another source like IMDb.For example, if Christopher Nolan is found as the director of "Oppenheimer":#E2 = search_bing("Filmography of Christopher Nolan")Step 3: Extract the list of films directed by this person from the retrieved information.From the returned results, extract the titles of the top 10 best movies according to critics/audience ratings or personal preference.</prompt>
Format data model panggilan #fungsi ##🎜: 🎜#
- menggunakan format set data trelis. Set data adalah kecil, dengan hanya 55 baris. Strukturnya sebenarnya serupa dengan format alpaca. Dibahagikan kepada systemPrompt, userPrompt dan assistantResponse, sepadan dengan Arahan alpaca, prompt dan Response masing-masing. Berikut ialah contoh:
- #🎜 #
微调过程说明
4.1 微调环境
在Ubuntu 22.04系统上,使用了CUDA 11.8和Pytorch 2.0.1,并采用了LLaMA-Efficient-Tuning框架。此外,还使用了Deepspeed 0.10.4
4.2 微调步骤
需要进行针对 Marcoroni-70B 的 lora 微调
- LLaMA-Efficient-Tuning 框架支持 deepspeed 集成,在训练开始前输入 accelerate config 进行设置,根据提示选择 deepspeed zero stage 3,因为是 6 卡总计 144G 的 VRAM 做 lora 微调,offload optimizer states 可以选择 none, 不卸载优化器状态到内存。
- offload parameters 需要设置为 cpu,将参数量卸载到内存中,这样内存峰值占用最高可以到 240G 左右。gradient accumulation 需要和训练脚本保持一致,这里选择的是 4。gradient clipping 用来对误差梯度向量进行归一化,设置为 1 可以防止梯度爆炸。
- zero.init 可以进行 partitioned 并转换为半精度,加速模型初始化并使高参数的模型能够在 CPU 内存中全部进行分配。这里也可以选 yes。
全部选择完成后,新建一个训练的 bash 脚本,内容如下:
accelerate launch src/train_bash.py \--stage sft \--model_name_or_path your_model_path \--do_train \--dataset rewoo \--template alpaca \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir your_output_path \--overwrite_cache \--per_device_train_batch_size 1 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-6 \--num_train_epochs 4.0 \--plot_loss \--flash_attn \--bf16
这样的设置需要的内存峰值最高可以到 240G,但还是保证了 6 卡 4090 可以进行训练。开始的时候可能会比较久,这是因为 deepspeed 需要对模型进行 init。之后训练就开始了。
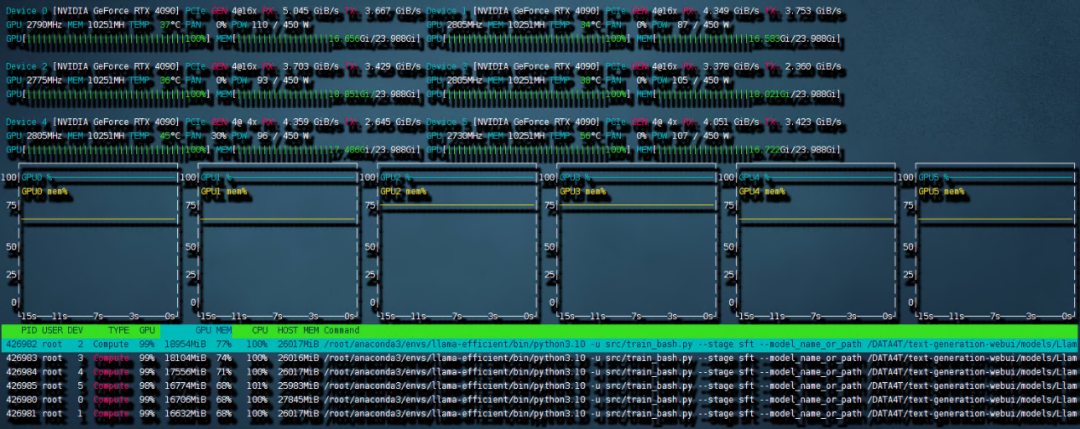
需要重新写的内容是:图4 6 卡 4090 训练带宽速度
共计用时 8:56 小时。本次训练中因为主板上的 NVME 插槽会和 OCULINK 共享一路 PCIE4.0 x16 带宽。所以 6 张中的其中两张跑在了 pcie4.0 X4 上,从上图就可以看出 RX 和 TX 都只是 PCIE4.0 X4 的带宽速度。这也成为了本次训练中最大的通讯瓶颈。如果全部的卡都跑在 pcie 4.0 x16 上,速度应该是比现在快不少的。
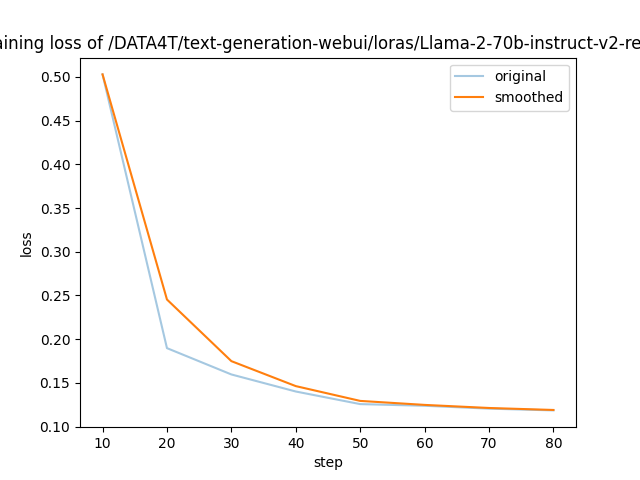
需要进行改写的内容是:图5展示了LLaMA-Efficient-Tuning生成的损失曲线
以上是 LLaMA-Efficient-Tuning 自动生成的 loss 曲线,可以看到 4 个 epoch 后收敛效果还是不错的。
2)针对 codellama 的 qlora 微调
根据前文所述的 prompt loss mask 方法,我们对 trainer 类进行了重构(请参考项目代码仓库中的 func_caller_train.py)。由于数据集本身较小(共55行),所以仅需两分钟即可完成4个epoch的训练,模型迅速收敛
4.3微调完成后的测试效果
在项目代码仓库中,提供了一个简短可用的 toolkit 示例。里面的函数包括:
- 必应搜索
- 维基搜索
- bilibili 搜索
- 获取当前时间
- 保存文件
- ...
现在有一个70B和一个34B的模型,在实际使用中,用6张4090同时以bf16精度运行这两个模型是不现实的。但是可以通过量化的方法压缩模型大小,同时提升模型推理速度。这里采用高性能LLM推理库exllamav2运用flash_attention特性来对模型进行量化并推理。在项目页面中作者介绍了一种独特的量化方式,本文不做赘述。按照其中的转换机制可以将70B的模型按照2.5-bit量化为22G的大小,这样一张显卡就可以轻松加载
需要重新编写的内容是:1)测试方法
Diberi penerangan tugas yang kompleks yang tiada dalam set latihan, tambahkan fungsi dan penerangan yang sepadan yang tidak termasuk dalam set latihan pada kit alat. Jika perancang boleh menyelesaikan pembahagian tugas, pengedar boleh memanggil fungsi, dan penyelesai boleh meringkaskan keputusan berdasarkan keseluruhan proses.
Kandungan yang perlu ditulis semula ialah: 2) Keputusan ujian
Pembahagian tugas: Mula-mula gunakan text-generation-webui untuk menguji dengan cepat kesan model pemisahan tugas, seperti yang ditunjukkan dalam rajah berikut :

Rajah 6 Keputusan ujian pembahagian tugas
Di sini anda boleh menulis antara muka restful_api yang mudah untuk memudahkan panggilan dalam persekitaran ujian ejen (lihat kod projek fllama_api.py).
Panggilan fungsi: Logik perancang-pengedar-pekerja-penyelesai mudah telah ditulis dalam projek. Seterusnya mari kita uji tugasan ini. Masukkan arahan: apakah filem yang diarahkan oleh pengarah 'Killers of the Flower Moon'? Senaraikan salah satu daripadanya dan cari dalam bilibili.
「Search bilibili」Fungsi ini tidak termasuk dalam set latihan panggilan fungsi projek. Pada masa yang sama, filem ini juga merupakan filem baru yang masih belum dikeluarkan. Anda boleh melihat bahawa model membahagikan arahan input dengan baik:
- Cari pengarah filem dari Wikipedia
- Berdasarkan keputusan 1, cari hasil filem Goodfellas dari bing
- di Mencari filem Goodfellas
pada bilibili dan memanggil fungsi pada masa yang sama mendapat keputusan berikut: Hasil yang diklik ialah Goodfellas, yang sepadan dengan pengarah filem itu.
Ringkasan
Projek ini mengambil senario "memasukkan arahan untuk melaksanakan secara automatik pemisahan tugas yang kompleks dan panggilan fungsi" sebagai contoh, dan mereka bentuk proses ejen asas: toolkit-plan-distribute-worker-solver kepada melaksanakan Agen yang boleh melaksanakan tugas kompleks asas yang tidak dapat diselesaikan dalam satu langkah. Melalui pemilihan model asas dan penalaan halus lora, penalaan halus dan inferens model besar boleh diselesaikan di bawah keadaan kuasa pengkomputeran yang rendah. Dan mengguna pakai kaedah penggunaan kuantitatif untuk merendahkan lagi ambang penaakulan. Akhir sekali, contoh mencari kerja lain pengarah filem telah dilaksanakan melalui saluran paip ini, dan tugasan kompleks asas telah diselesaikan.
Had: Artikel ini hanya mereka bentuk panggilan fungsi dan pemisahan tugas berdasarkan kit alat untuk carian dan operasi asas. Set alat yang digunakan adalah sangat mudah dan tidak mempunyai banyak reka bentuk. Tidak banyak pertimbangan untuk mekanisme toleransi kesalahan. Melalui projek ini, semua orang boleh terus meneroka aplikasi dalam bidang RPA, menambah baik lagi proses ejen, dan mencapai tahap automasi pintar yang lebih tinggi untuk meningkatkan kebolehurusan proses.
Atas ialah kandungan terperinci Bagaimanakah Agen AI dilaksanakan? 6 foto 4090 sihir diubah suai Llama2: membahagikan tugas dan memanggil fungsi dengan satu arahan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!