
Rumah >Peranti teknologi >AI >Semakan paling komprehensif tentang model besar multimodal ada di sini! 7 penyelidik Microsoft bekerjasama bersungguh-sungguh, 5 tema utama, 119 halaman dokumen
Semakan paling komprehensif tentang model besar multimodal ada di sini! 7 penyelidik Microsoft bekerjasama bersungguh-sungguh, 5 tema utama, 119 halaman dokumen

- 王林ke hadapan
- 2023-09-25 16:49:06963semak imbas
Model besar berbilang modalulasan paling lengkap ada di sini!
ditulis oleh 7 penyelidik Cina daripada Microsoft, ialah sejumlah 119 muka surat——
#🎜🎜 🎜🎜# Ia bermula daripada
Ia bermula daripada
dan masih berada di barisan hadapan dua jenis penyelidikan model besar berbilang mod , dan meringkaskan secara komprehensif Lima topik penyelidikan khusus:
Pemahaman Visual- Visual Generation
- #🎜🎜 Model Visi Bersatu 🎜#LLM Model besar berbilang modal yang diberkati
- agen berbilang modal
- #🎜# dan fokus kepada satu fenomena :
 Model asas pelbagai modal telah beralih daripada khusus kepada
Model asas pelbagai modal telah beralih daripada khusus kepada
.
Siapa yang sesuai membaca ulasan iniPs.Inilah sebabnya penulis melukis secara langsung imej Doraemon di awal kertas.
(laporan) ?
Dalam perkataan asal Microsoft:Selagi anda berminat untuk mempelajari pengetahuan asas dan kemajuan terkini model asas pelbagai mod, sama ada anda seorang penyelidik profesional atau pelajar sekolah , kandungan ini sangat sesuai untuk anda
Jom tengok~Satu artikel untuk mengetahui situasi semasa model besar pelbagai mod#🎜🎜 #Lima topik khusus ini Dua yang pertama adalah bidang matang, manakala tiga yang terakhir adalah bidang termaju
1 Pemahaman visual
Isu teras dalam bahagian ini ialah cara untuk melatih tulang belakang pemahaman Imej yang kuat.
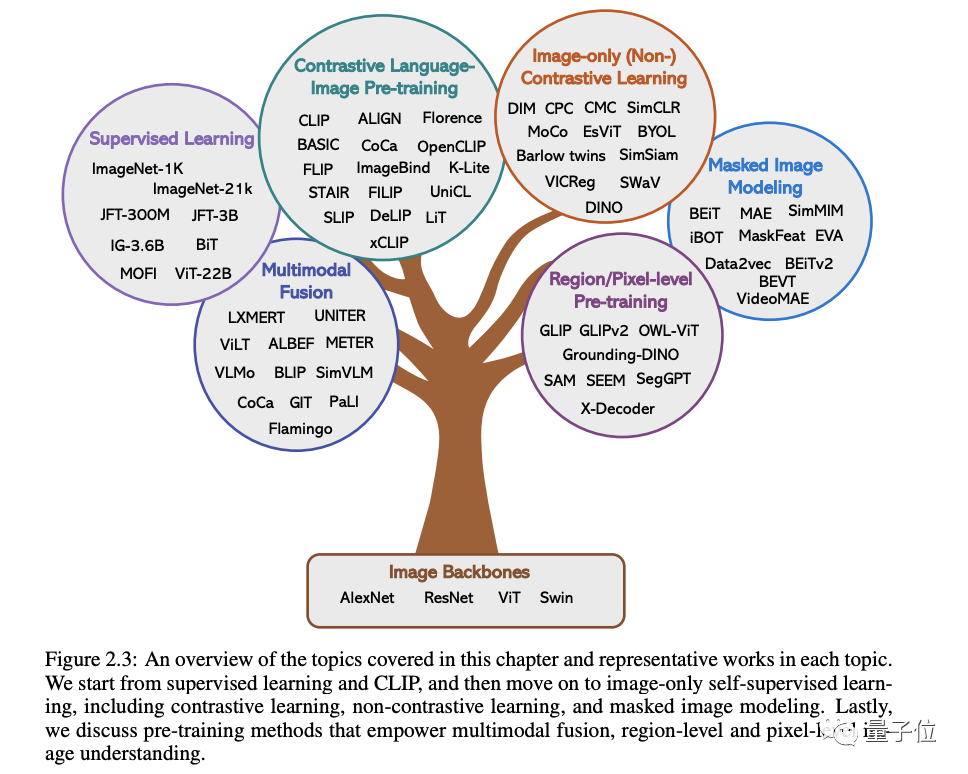
Seperti yang ditunjukkan dalam rajah di bawah, mengikut isyarat penyeliaan berbeza yang digunakan untuk melatih model, kita boleh membahagikan kaedah kepada tiga kategori:
Penyeliaan label, penyeliaan bahasa( dengan CLIP sebagai Mewakili)
dan pengawasan diri imej sahaja. Yang terakhir menunjukkan bahawa isyarat penyeliaan dilombong daripada imej itu sendiri termasuk pembelajaran kontras, pembelajaran bukan kontras dan pemodelan imej bertopeng.
Selain kaedah ini, artikel ini membincangkan lebih lanjut kaedah pra-latihan untuk kategori seperti gabungan pelbagai mod, pemahaman imej peringkat wilayah dan piksel#🎜 🎜## 🎜🎜#
2 Penjanaan visual 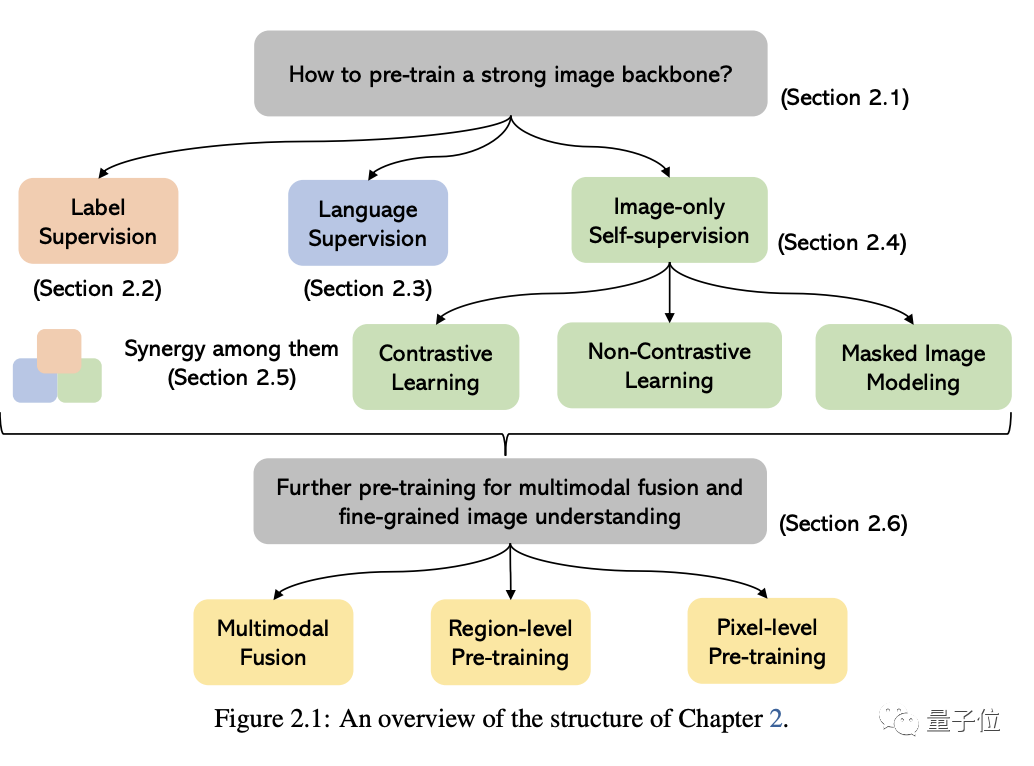
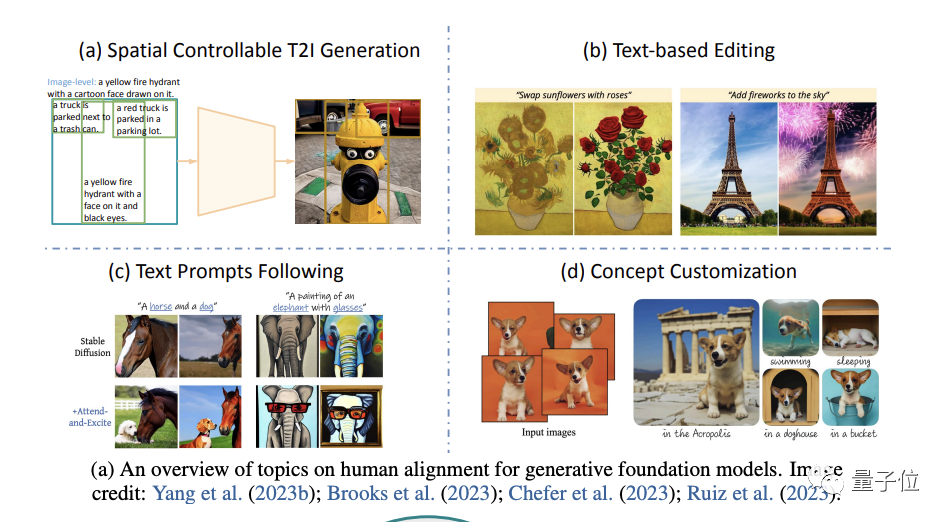
 Dalam bahagian ini, penulis memfokuskan kepada kepentingan dan kaedah menghasilkan kesan yang benar-benar konsisten dengan niat manusia
Dalam bahagian ini, penulis memfokuskan kepada kepentingan dan kaedah menghasilkan kesan yang benar-benar konsisten dengan niat manusia
.
Secara khusus, ia bermula daripada empat aspek: penjanaan ruang yang boleh dikawal, penyuntingan semula berasaskan teks, lebih baik mengikuti gesaan teks dan penyesuaian konsep penjanaan
(penyesuaian konsep).
Di akhir bahagian ini, penulis juga berkongsi pandangan mereka tentang trend penyelidikan semasa dan hala tuju penyelidikan akan datang
#🎜🎜 #Dalam Untuk mengikuti niat manusia dengan lebih baik dan menjadikan empat arah di atas lebih fleksibel dan boleh diganti, kita perlu membangunkan model penjanaan teks umumKarya wakil masing-masing dari empat arah disenaraikan seperti berikut: #🎜🎜 #
Sebagai contoh, kos pelbagai jenis anotasi label sangat berbeza-beza, dan kos pengumpulan jauh lebih tinggi daripada data teks Ini menyebabkan skala data visual biasanya jauh lebih kecil daripada korpora teks.
Namun, walaupun menghadapi banyak cabaran, penulis menegaskan:
Bidang CV semakin berminat untuk membangunkan sistem penglihatan umum dan bersatu, dan tiga trend telah muncul: # 🎜🎜#
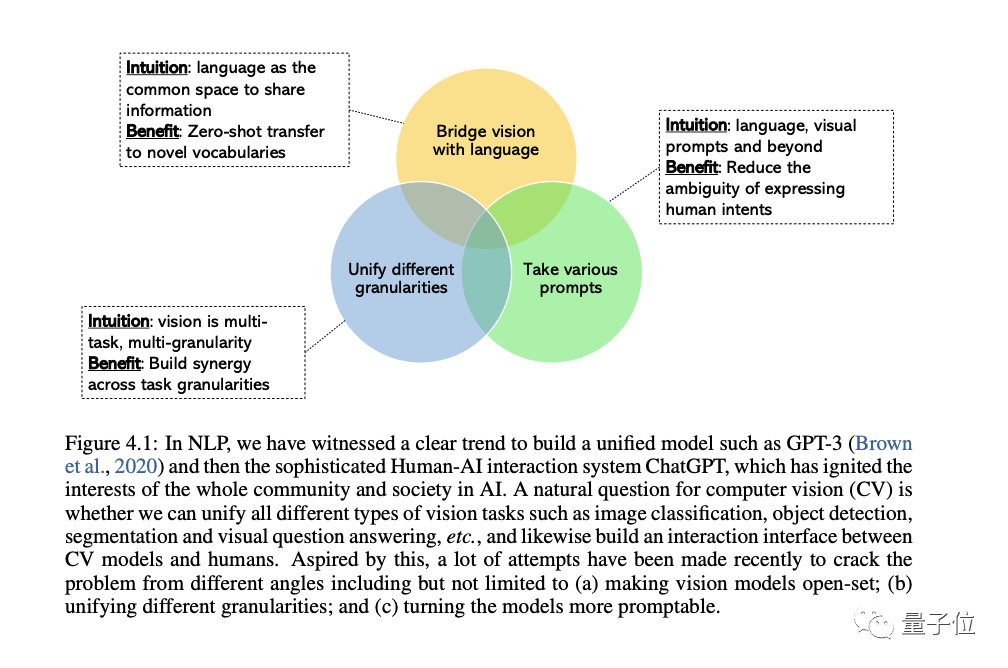
(set tertutup) hingga set buka # (set terbuka) 🎜🎜#, yang boleh memadankan teks dan visual dengan lebih baik. Sebab paling penting untuk peralihan daripada tugas khusus kepada keupayaan umum ialah kos membangunkan model baharu untuk setiap tugasan baharu adalah terlalu tinggi
Yang ketiga adalah daripada statik model kepada model pantas Model, LLM boleh mengambil bahasa yang berbeza dan isyarat kontekstual sebagai input dan menghasilkan output yang dikehendaki oleh pengguna tanpa penalaan halus. Model visi umum yang ingin kita bina harus mempunyai keupayaan pembelajaran kontekstual yang sama.
4. Model besar berbilang modal yang disokong oleh LLM
Bahagian ini membincangkan model besar berbilang modal secara menyeluruh.
Pertama, kami menjalankan kajian mendalam tentang latar belakang dan contoh yang mewakili, membincangkan kemajuan penyelidikan pelbagai mod OpenAI, dan mengenal pasti jurang penyelidikan sedia ada dalam bidang ini.
Seterusnya, penulis meneliti secara terperinci kepentingan penalaan halus arahan dalam model bahasa besar.
Kemudian, penulis membincangkan penalaan halus arahan dalam model besar berbilang modal, termasuk prinsip, kepentingan dan aplikasi.
Akhirnya, kami juga akan membincangkan beberapa topik lanjutan dalam bidang model multimodal untuk pemahaman yang lebih mendalam, termasuk:
Lebih banyak model di luar penglihatan dan mod bahasa, konteks multi-modal pembelajaran, latihan parameter yang cekap dan Penanda Aras.
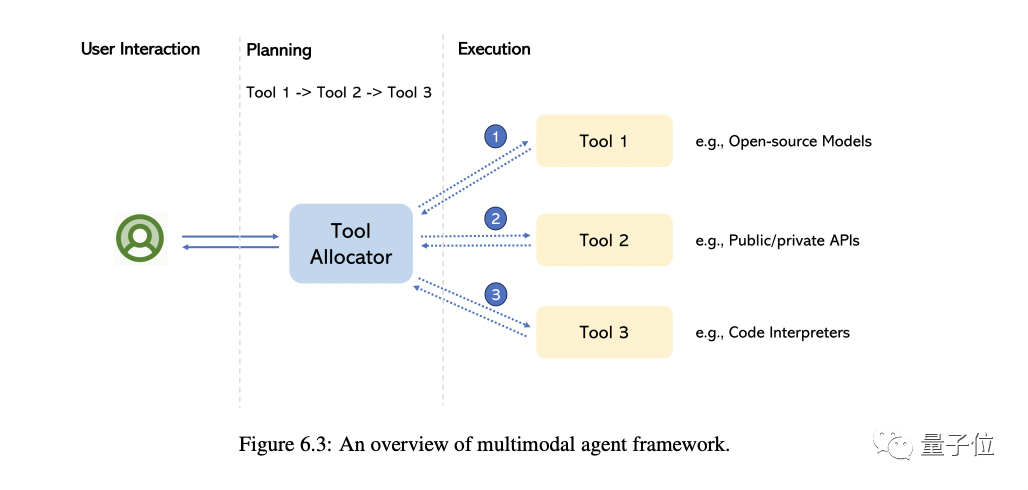
5. Agen multimodal
Agen multimodal yang dipanggil adalah kaedah yang menghubungkan pakar multimodal yang berbeza dengan LLM untuk menyelesaikan masalah pemahaman multimodal yang kompleks.
Dalam bahagian ini, penulis terutamanya membawa anda menyemak transformasi model ini dan merumuskan perbezaan asas antara kaedah ini dan kaedah tradisional.
Mengambil MM-REACT sebagai contoh, kami akan memperincikan cara pendekatan ini berfungsi
Kami meringkaskan lagi pendekatan komprehensif tentang cara membina ejen multimodal, dan apakah keupayaan yang muncul dalam pemahaman multimodal. Pada masa yang sama, kami juga merangkumi cara meluaskan keupayaan ini dengan mudah, termasuk LLM terkini dan paling berkuasa dan berpotensi berjuta-juta alat
Sudah tentu, terdapat juga beberapa topik lanjutan yang dibincangkan pada penghujungnya, termasuk bagaimana untuk Meningkatkan/menilai ejen pelbagai modal, pelbagai aplikasi yang dibina daripadanya, dsb.
 Pengenalan Pengarang
Pengenalan Pengarang
Terdapat 7 pengarang dalam laporan ini
#🎜🎜🎜##🎜🎜🎜##🎜🎜 🎜🎜#Pemula dan keseluruhan orang yang bertanggungjawab ialah Chunyuan Li.Beliau ialah penyelidik utama di Microsoft Redmond dan memegang Ph.D dari Universiti Duke, termasuk latihan pra-latihan berskala besar dalam CV dan NLP . Beliau bertanggungjawab untuk pengenalan pembukaan, rumusan penutup, dan penulisan bab "Model Besar Berbilang Modal Dilatih Menggunakan LLM". Kandungan yang ditulis semula: Dia bertanggungjawab untuk menulis pengenalan dan kesimpulan artikel, serta bab tentang "Model besar berbilang mod yang dilatih menggunakan LLM"
#🎜 🎜#
Terdapat 4 pengarang teras:
Zhe Gan#🎜🎜🎜#🎜🎜 sedang bekerja dalam Apple AI/ML, bertanggungjawab untuk penglihatan berskala besar dan penyelidikan model asas berbilang modal. Sebelum ini, beliau adalah penyelidik utama Microsoft Azure AI. Beliau lulus dari Universiti Peking dengan ijazah sarjana muda dan Ph.D dari Universiti Duke.
Zhengyuan Yang- Beliau ialah penyelidik kanan di Microsoft, lulus dari Universiti Rochester dan menerima penghormatan seperti ACM SIGMM Kedoktoran Cemerlang Anugerah. Beliau belajar di Universiti Sains dan Teknologi China untuk ijazah sarjana mudanya. PhD dari Institut Teknologi Georgia.
- (Perempuan)
- Mereka masing-masing bertanggungjawab untuk menulis baki empat bab tema.
Alamat ringkasan: https://arxiv.org/abs/2309.10020
Atas ialah kandungan terperinci Semakan paling komprehensif tentang model besar multimodal ada di sini! 7 penyelidik Microsoft bekerjasama bersungguh-sungguh, 5 tema utama, 119 halaman dokumen. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!