
Rumah >pembangunan bahagian belakang >Tutorial Python >Bagaimana untuk mengira sisa pelajar dalam Python?
Bagaimana untuk mengira sisa pelajar dalam Python?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-24 18:45:021317semak imbas
Sisa terpelajar sering digunakan dalam analisis regresi untuk mengenal pasti kemungkinan outlier dalam data. Outlier ialah titik yang berbeza dengan ketara daripada aliran keseluruhan data dan boleh memberi kesan ketara pada model yang dipasang. Dengan mengenal pasti dan menganalisis outlier, anda boleh memahami dengan lebih baik corak asas dalam data anda dan meningkatkan ketepatan model anda. Dalam artikel ini, kita akan melihat dengan lebih dekat sisa pelajar dan cara melaksanakannya dalam python.
Apakah sisa pelajar?
Istilah "sisa terpelajar" merujuk kepada kelas sisa tertentu yang sisihan piawainya dibahagikan dengan anggaran. Sisa analisis regresi menerangkan perbezaan antara nilai yang diperhatikan bagi pembolehubah bergerak balas dan nilai jangkaannya yang dijana oleh model. Untuk mencari penyimpangan dalam data yang mungkin mempengaruhi model dipasang dengan ketara, sisa pelajar telah digunakan.
Formula berikut biasanya digunakan untuk mengira sisa pelajar -
studentized residual = residual / (standard deviation of residuals * (1 - hii)^(1/2))
Di mana "sisa" merujuk kepada perbezaan antara nilai tindak balas yang diperhatikan dan nilai tindak balas yang dijangka, "sisa sisihan piawai" merujuk kepada anggaran sisa sisihan piawai dan "hii" merujuk kepada setiap titik data faktor leverage .
Gunakan Python untuk mengira sisa pelajar
Pakejstatsmodels boleh digunakan untuk mengira sisa pelajar dalam Python. Sebagai ilustrasi, pertimbangkan perkara berikut -
tatabahasa
OLSResults.outlier_test()
Di mana OLSResults merujuk kepada model linear yang dipasang menggunakan kaedah ols() model statistik.
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83],
'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
model = ols('rating ~ points', data=df).fit()
stud_res = model.outlier_test()
Di mana "penilaian" dan "skor" merujuk kepada regresi linear mudah.
Algoritma
Import numpy, panda, Statsmodel api.
Buat set data.
Lakukan model regresi linear ringkas pada set data.
Kira sisa pelajar.
Cetak sisa pelajar.
Contoh
Berikut ialah demonstrasi menggunakan perpustakaan scikit-posthocs untuk menjalankan ujian Dunn -
#import necessary packages and functions
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
#create dataset
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83], 'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
Seterusnya gunakan kelas statsmodels OLS untuk mencipta model regresi linear -
#fit simple linear regression model
model = ols('rating ~ points', data=df).fit()
Menggunakan kaedah outlier test(), baki pelajar bagi setiap pemerhatian dalam set data boleh dijana dalam DataFrame -
#calculate studentized residuals stud_res = model.outlier_test() #display studentized residuals print(stud_res)
Output
student_resid unadj_p bonf(p) 0 1.048218 0.329376 1.000000 1 -1.018535 0.342328 1.000000 2 0.994962 0.352896 1.000000 3 0.548454 0.600426 1.000000 4 1.125756 0.297380 1.000000 5 -0.465472 0.655728 1.000000 6 -0.029670 0.977158 1.000000 7 -2.940743 0.021690 0.216903 8 0.100759 0.922567 1.000000 9 -0.134123 0.897080 1.000000
Kami juga boleh memplot nilai peramal dengan cepat berdasarkan sisa pelajar -
tatabahasa
x = df['points']
y = stud_res['student_resid']
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
Di sini kita akan menggunakan perpustakaan matpotlib untuk melukis carta dengan warna = 'hitam' dan gaya hidup = '--'
Algoritma
Import perpustakaan pyplot matplotlib
Tentukan nilai peramal
Definisi sisa pelajar
Cipta serakan peramal berbanding sisa pelajar
Contoh
import matplotlib.pyplot as plt
#define predictor variable values and studentized residuals
x = df['points']
y = stud_res['student_resid']
#create scatterplot of predictor variable vs. studentized residuals
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
Output
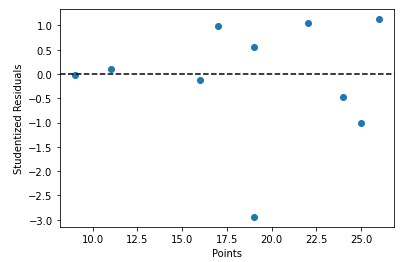
KESIMPULAN
Kenal pasti dan nilaikan kemungkinan outlier data. Memeriksa sisa pelajar membolehkan anda mencari mata yang menyimpang dengan ketara daripada aliran keseluruhan data dan meneroka sebab ia mempengaruhi model yang dipasang. Mengenal pasti pemerhatian penting Sisa pelajar boleh digunakan untuk menemui dan menilai data berpengaruh yang mempunyai kesan ketara ke atas model yang dipasang. Cari tempat leverage tinggi. Sisa pelajar boleh digunakan untuk mengenal pasti titik leverage yang tinggi. Leveraj ialah ukuran berapa banyak pengaruh titik pada model yang dipasang. Secara keseluruhan, menggunakan sisa pelajar membantu menganalisis dan meningkatkan prestasi model regresi.
Atas ialah kandungan terperinci Bagaimana untuk mengira sisa pelajar dalam Python?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!