
Rumah >Peranti teknologi >AI >Memenuhi keperluan pengkomputeran kompleks era AI Kajian semula Adam Server G952N6
Memenuhi keperluan pengkomputeran kompleks era AI Kajian semula Adam Server G952N6

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-22 23:37:011045semak imbas
Pembangunan AI generatif dan LLM yang pesat telah mempromosikan aplikasi teknologi pintar yang mendalam dalam beribu-ribu industri Pengkomputeran dipercepatkan telah menjadi pemacu pertumbuhan infrastruktur IT, terutamanya lelaran berterusan pelayan AI, CXL, HBM dan produk atau produk lain. Prestasi cemerlang membolehkan orang ramai melihat peluang pasarannya yang lebih luas. Kandungan yang perlu ditulis semula ialah: Pelayan EVOC Adam G952N6 ialah pelayan pengkomputeran heterogen dua saluran kad GPU 4U10 yang direka oleh Ewanke yang dilengkapi dengan pemproses siri berskala Xeon generasi ketiga Intel Ia sesuai untuk Internet dan IDC (Pusat Data Internet ) ) Perniagaan seperti pengkomputeran awan, data besar, universiti, kecerdasan buatan dan pengkomputeran berprestasi tinggi boleh memenuhi keperluan senario seperti skala data besar, kuasa pengkomputeran aplikasi yang tinggi dan fleksibiliti.
Daripada penampilan, Pelayan Adam G952N6 menggunakan gaya reka bentuk yang ringkas dan elegan, yang mudah dipasang, dibuka dan diselenggara Ini adalah pelayan yang dipasang di rak 4U dengan berat bersih 60.35KG dan saiz 840mm. (panjang) *460mm (lebar) *175mm (tinggi), logo yang boleh dikenali pada panel hadapan dan garisan oren menyerlahkan perangai pengeluar besar.

Kandungan yang perlu ditulis semula ialah: EVOC Adam server G952N6
Sudut kanan atas panel hadapan menyediakan 2 antara muka USB 3.2 dan 1 VGA, sudut kiri atas ialah 1 butang/penunjuk UID, 1 butang RST, 1 butang suis/penunjuk kuasa, dan 1 lampu status kesihatan, 1 penunjuk cakera keras cahaya dan 2 lampu penunjuk LAN, membolehkan pengguna melihatnya dengan jelas sekali imbas.
Pada masa yang sama, G952N6 mempunyai 12 ruang cakera keras boleh tukar panas 3.5 inci dan boleh menyokong 4 cakera keras U.2 NVMe, yang boleh memenuhi sepenuhnya keperluan penyimpanan data aplikasi seperti AI generatif, HPC dan analisis data besar .

Kandungan yang perlu ditulis semula ialah: EVOC Adam server G952N6
Papan induk G952N6 dilengkapi dengan 2 antara muka M.2 untuk cakera sistem dan menyediakan sehingga 13 slot pengembangan PCIe untuk memenuhi pelbagai keperluan pengembangan pelanggan Ia menyokong sehingga 10 pemecut GPU 300W tinggi penuh, panjang penuh, dua lebar. kad, dan sesuai untuk Untuk aplikasi seperti pembelajaran mendalam dan analisis data besar. Papan ini menyediakan GbE khusus IPMI dan antara muka OCP 3.0 untuk pemilihan yang fleksibel.
Dalam operasi dan penyelenggaraan, anda boleh menyemak status pengendalian peralatan melalui antara muka pengurusan Web BMC, LED diagnosis kerosakan, dsb., tandai mesin yang rosak melalui lampu penunjuk UID pada telinga pelekap, cari peralatan yang rosak dengan cepat, selesaikan masalah dalam masa, memudahkan kerja penyelenggaraan dan meningkatkan ketersediaan Sistem. Di samping itu, pelayan G952N6 juga menyepadukan sistem pengurusan pelesapan haba pintar, yang boleh melaraskan mod pelesapan haba secara bijak mengikut status operasi keseluruhan mesin, meningkatkan nisbah kecekapan tenaga peralatan, dan menjimatkan kos elektrik untuk pelanggan
Konfigurasi parameter khusus pelayan G952N6 adalah seperti berikut: - Pemproses: Pemproses Intel Xeon lapan teras 2.5GHz - Memori: 32GB DDR4 RAM -Storan: 1TB SSD - Rangkaian: Antara muka Gigabit Ethernet - Sistem pengendalian: Windows Server 2019 - Slot pengembangan: 4 slot PCIe x16 - Bekalan kuasa: Bekalan kuasa boleh tukar panas dua lewah - Saiz: Reka bentuk dipasang di rak 2U Di atas ialah konfigurasi parameter khusus pelayan Yiwanke G952N6
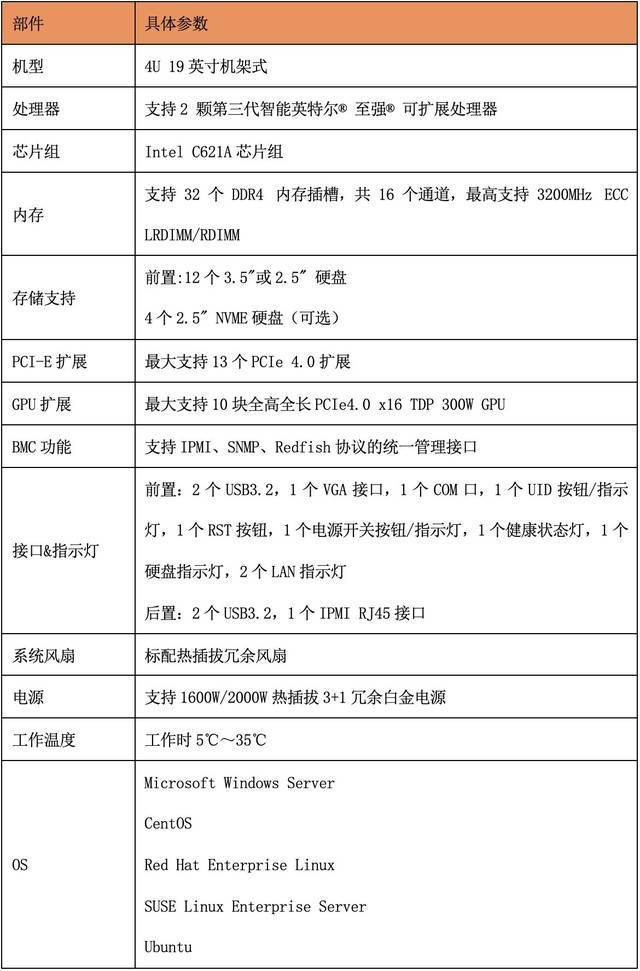
Billion G952N6 konfigurasi parameter pelayan
Mengikut konfigurasi berkaitan di atas, satu CPU pelayan ini mempunyai sehingga 40 teras dan 80 utas, TDP maksimum 270W, frekuensi utama maksimum 3.6GHz dan 3 set pautan sambung sambungan UPI 11.2 GT/s, yang boleh digunakan dengan cipset pelayan Intel C621A dan memori 32 DDR4 3200 MTS. Pada masa yang sama, ia juga menyokong 16 memori jenis BPA PMEM, meningkatkan kapasiti memori dengan berkesan
Dalam sesi ujian, kami menjalankan pemeriksaan awal struktur penampilan pelayan G952N6, dan memeriksa butiran secara berasingan seperti skrin sutera on-board, skrin skrin slot OCP, skrin skrin port bersiri, skrin skrin cahaya cakera keras, slot PCIE , skrin skrin lampu/suis kuasa, dan mutu kerja skrin sutera yang jelas, sesuai dengan kualiti pengeluar utama.
Kemudian kami menganalisis panel pelayan, pemasangan OS, fungsi CPU, fungsi memori, cakera PCH SATA, cakera SATA/SAS/NVME kad RAID/HBA, cakera PCIE U.2 NVMe atau cakera M.2 NVMe onboard, fungsi GPU, Slot PCIE, port rangkaian onboard, antara muka VGA, port bersiri, antara muka USB, antara muka kuasa, antara muka kipas, slot OCP dan banyak lagi ujian fungsi asas telah dijalankan, dan semua item ujian telah diluluskan dengan prestasi cemerlang.
Sebagai contoh, semasa menguji slot PCIE, jalankan ujian tekanan kad PCIE selama 10 minit Tiada mesej ralat dalam dmesg dan bmc sel, dan tiada keabnormalan dalam kad PCIE 15 kali, kad PCIE boleh dikenali secara normal, dan prestasinya sangat baik.
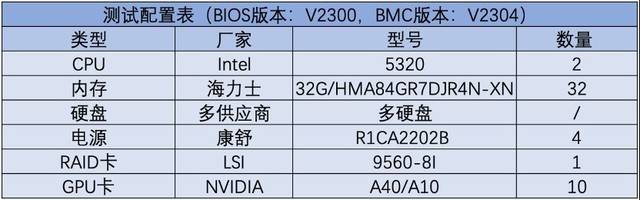
Uji jadual konfigurasi
Memasuki ujian prestasi, kami menjalankan ujian komprehensif tentang prestasi CPU, prestasi memori, prestasi cakera keras dan prestasi kad grafik.
Mula-mula kami melakukan ujian prestasi pada CPU Dengan bantuan program ujian Linpack, kami menguji kuasa pengkomputeran CPU dengan mengira penyelesaian kepada sistem persamaan linear berketepatan dua. Keputusan ujian menunjukkan bahawa nilai yang diukur adalah lebih baik daripada nilai teori Prestasi pengkomputeran titik terapung yang lebih baik membolehkan pelayan mempunyai prestasi yang sangat baik dalam aplikasi kejuruteraan atau persekitaran pengaturcaraan, seperti simulasi eksperimen fizik atau pengiraan berangka dalam pengaturcaraan komputer. .
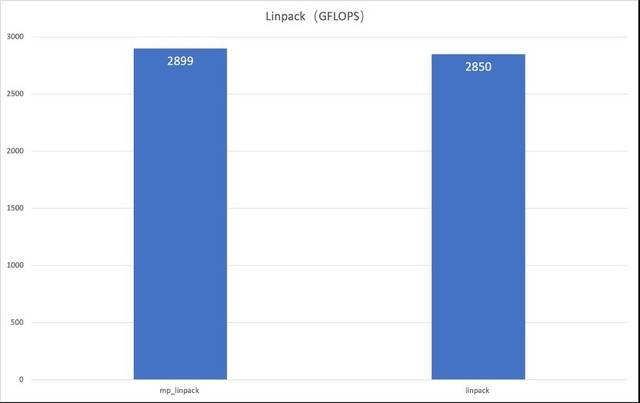
Kandungan yang perlu ditulis semula ialah: Ujian prestasi Unit Pemprosesan Pusat (CPU)
Dalam ujian memori pelayan G952N6, kami memilih dua alatan, STREAM (versi v5.10) dan MLC (versi v3.9), untuk ujian. Antaranya, STREAM ialah program ujian jalur lebar memori arus perdana yang mempunyai keperluan rendah pada kuasa pengkomputeran CPU, tetapi memberikan tekanan yang lebih besar pada jalur lebar memori CPU. Melalui ujian, kita boleh mendapatkan nilai maksimum operasi mampan lebar jalur memori, bukan nilai teori. Program ini terutamanya menggunakan empat operasi tatasusunan, termasuk salinan tatasusunan (Salin), transformasi skala tatasusunan (Skala), jumlah vektor tatasusunan (Tambah), dan jumlah vektor komposit tatasusunan (Triad). Nilai tatasusunan yang digunakan dalam ujian adalah dalam ketepatan dua kali ganda
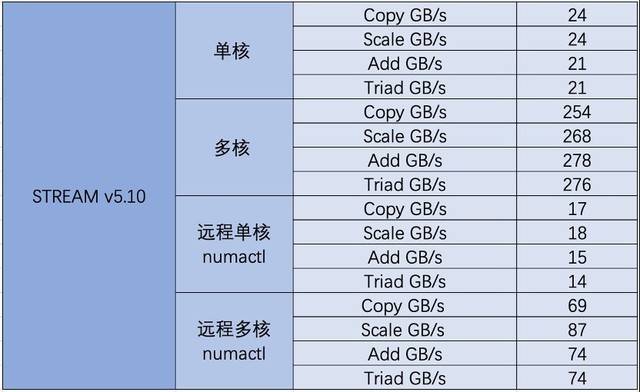
Untuk menguji prestasi ingatan
Secara umumnya, apabila aplikasi mendapat data daripada cache pemproses atau subsistem memori, mereka menghadapi pelbagai masalah kependaman. Ditambah dengan had lebar jalur memori, kelewatan ini boleh memberi kesan kepada prestasi aplikasi. MLC boleh digunakan untuk menguji kelewatan ini. Sebagai contoh, hasil arahan kependaman capaian memori boleh disoal untuk mewakili matriks kependaman akses memori percuma antara atau dalam nod dalam ns
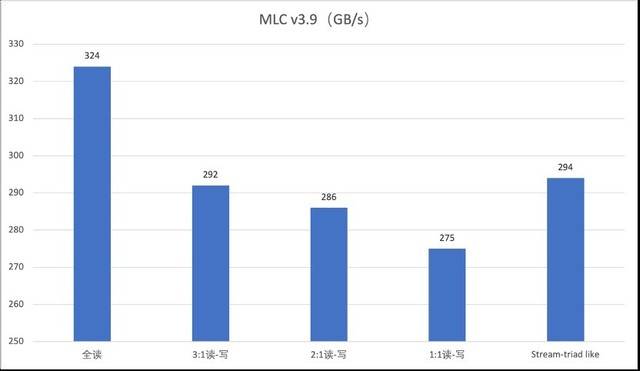
Untuk menguji prestasi ingatan
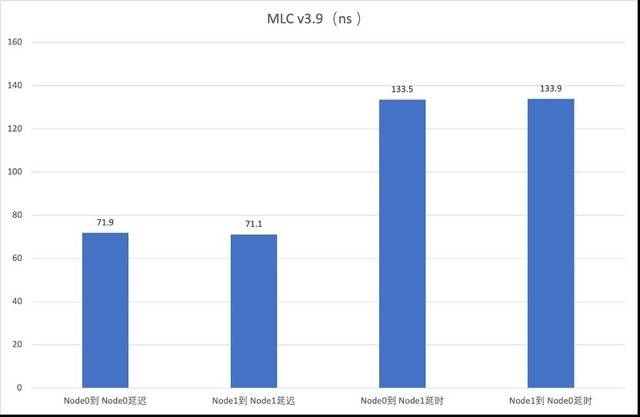
Untuk menguji prestasi ingatan
Berdasarkan keputusan ujian memori, prestasi secara amnya lebih tinggi daripada nilai teori tapak web rasmi Ia bukan sahaja boleh mengendalikan tugas biasa seperti pertanyaan data, aplikasi dan panggilan, tetapi juga memainkan peranan yang lebih besar dalam prestasi tinggi yang popular. pengkomputeran dan aplikasi lain. Seperti yang dapat dilihat dalam konfigurasi model, memori ECC boleh melaksanakan pemeriksaan dan pembetulan ralat, yang sebahagian besarnya memastikan keselamatan dan kestabilan keseluruhan sistem dan boleh meminimumkan kadar kecacatan, manakala memori RDIMM boleh mengurangkan kependaman , sesuai untuk besar -berkapasiti, berkelajuan tinggi, senario aplikasi masa nyata Di samping itu, dengan bantuan LRDIMM, penggunaan penimbal pada bas data boleh mengurangkan beban elektrik pengawal memori sistem, membolehkan bas memori pelayan mencapai lebih tinggi. kekerapan operasi sangat meningkatkan kapasiti yang disokong oleh memori.
Dalam ujian prestasi cakera keras, kami menguji cakera SAS, cakera NVMe dan cakera SATA, menggunakan perisian FIO (versi v3.15) ialah perisian profesional untuk menguji cakera, Alat untuk sistem fail. prestasi peranti blok dan peranti rangkaian boleh mensimulasikan pelbagai jenis beban I/O, termasuk baca dan tulis secara rawak atau berurutan, baca dan tulis bercampur, akses rawak atau berjujukan, dsb., dan ujian boleh disesuaikan dan dikonfigurasikan dengan sangat baik, menjadikan Keseluruhannya sokongan mesin untuk prestasi cakera keras ditunjukkan sepenuhnya.
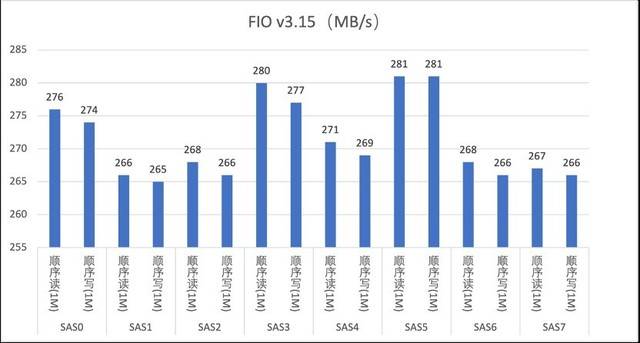
Ujian baca dan tulis jujukan cakera SAS
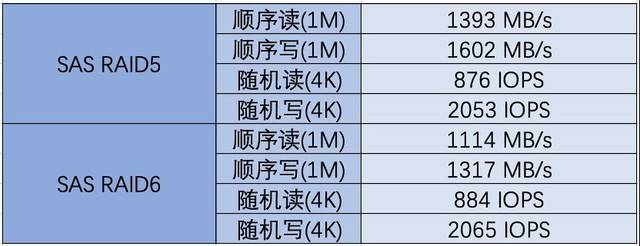
Kandungan ujian RAID cakera SAS perlu ditulis semula
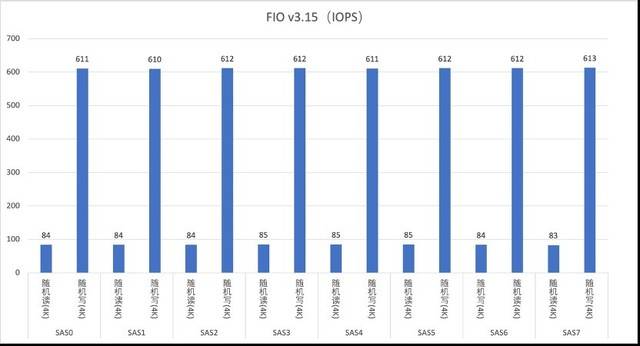
Ujian baca dan tulis secara rawak cakera SAS
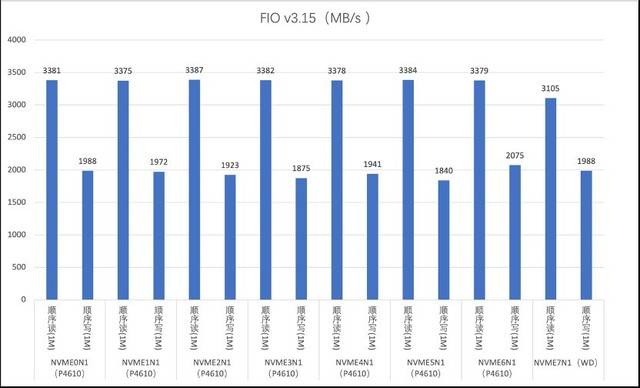
Kandungan yang perlu ditulis semula ialah: Ujian baca dan tulis berurutan cakera NVMe
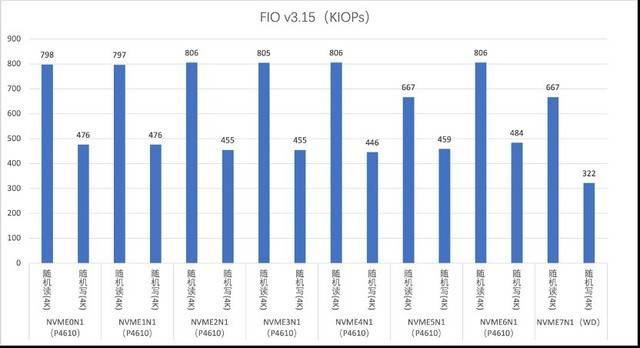
Menjalankan ujian baca dan tulis secara rawak pada cakera NVMe
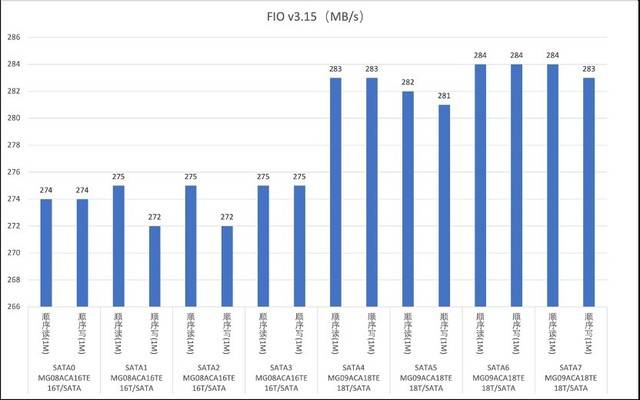
Ujian baca dan tulis berurutan cakera SATA
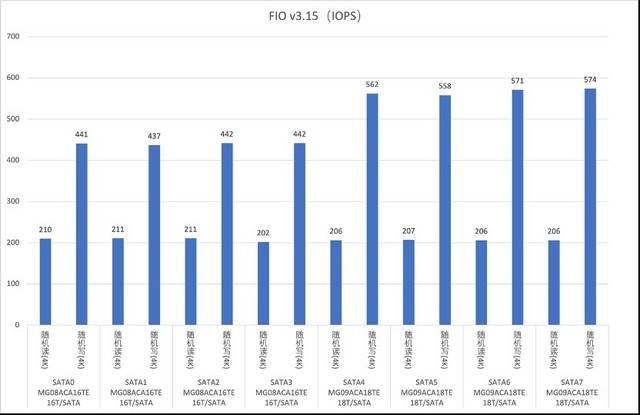
Ujian baca dan tulis secara rawak cakera SATA
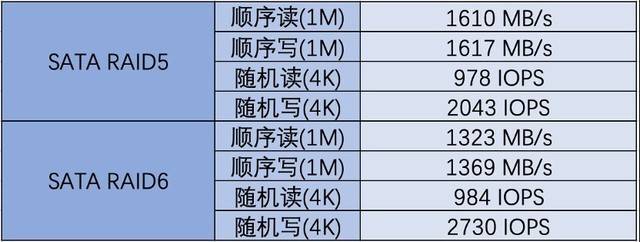
Ujian RAID cakera SATA
Pelayan G952N6 menyediakan tiga pilihan pemacu keras: SAS, SATA dan NVMe untuk memenuhi pelbagai keperluan storan dan sandaran data yang kompleks. Selepas ujian, kami mendapati bahawa prestasi sebenar cakera keras adalah lebih baik daripada nilai teori di laman web rasmi. Sebagai contoh, cakera NVMe mempunyai ciri prestasi tinggi dan kependaman rendah Ia boleh menggunakan sepenuhnya keupayaan lebar jalur tinggi PCIe untuk menyediakan kadar pemindahan data dan IOPS yang lebih tinggi, dan sesuai untuk senario seperti pemprosesan data besar dan berprestasi tinggi. pengkomputeran. Pemacu keras SAS berfungsi dengan baik dalam RAID, memberikan perlindungan data yang lebih tinggi dan keupayaan tindak balas kesalahan
Kami menggunakan alatan CUDA untuk menguji GPU CUDA ialah platform pengkomputeran selari berprestasi tinggi yang membolehkan pembangun menggunakan C/C++, Fortran dan bahasa pengaturcaraan lainuntuk melaksanakan pengkomputeran selari pada GPU NVIDIA, menyediakan keupayaan pengkomputeran yang berkuasa dan cekap. penghantaran data Kaedah ini telah menjadikan GPU digunakan secara meluas dalam pengkomputeran saintifik, pembelajaran mesin, pembelajaran mendalam dan bidang lain. CUDA-Z ialah alat yang digunakan untuk menanyakan maklumat kad grafik dan menguji prestasi kad grafik. Ia boleh menjalankan ujian profesional GPU NVIDIA Ia juga merupakan perisian ujian yang kami pilih kali ini (CUDA-Z 10.251).
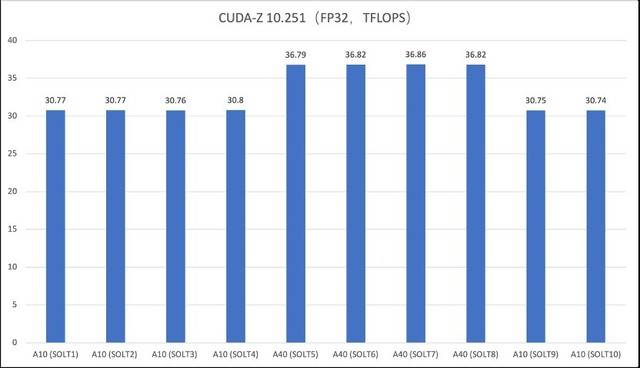
Kandungan ujian CUDA-Z FP32 perlu ditulis semula
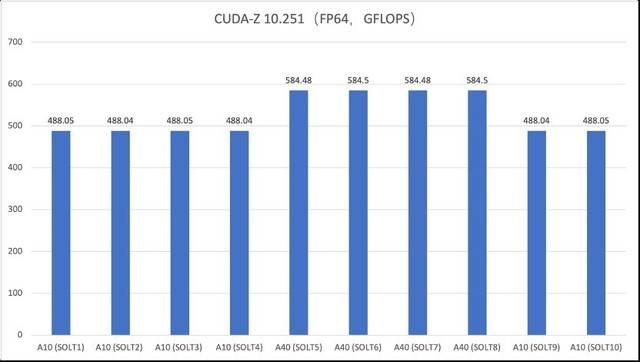
Ujian CUDA-Z FP64 ialah alat untuk menguji prestasi titik terapung berketepatan ganda GPU. Ia membantu pengguna menilai sejauh mana kad grafik mereka mengendalikan operasi titik terapung berketepatan dua kali. Dengan menjalankan ujian CUDA-Z FP64, pengguna boleh memahami prestasi kad grafik mereka semasa mengendalikan tugas pengkomputeran ketepatan tinggi. Ini penting untuk aplikasi yang memerlukan pengkomputeran saintifik, analisis data dan aplikasi lain yang memerlukan pengiraan ketepatan tinggi. Dengan menggunakan ujian CUDA-Z FP64, pengguna boleh memilih kad grafik yang betul untuk memenuhi keperluan khusus mereka dan mengoptimumkan tugas pengkomputeran mereka
Mengikut data ujian, nilai ujian sebenar prestasi kad grafik adalah lebih baik daripada nilai teori rasmi. Ambil FP32 dan FP64 sebagai contoh yang pertama ialah ketepatan lalai yang diterima pakai oleh kebanyakan rangka kerja pembelajaran mendalam Ia boleh memberikan kelajuan pengiraan yang lebih pantas sambil memastikan ketepatan pengiraan tertentu. Prestasi titik terapung ketepatan tunggal adalah tinggi dan boleh memenuhi keperluan pemprosesan grafik 3D dengan lebih baik, seperti pemodelan kejuruteraan dan tugas reka bentuk. Nilai tinggi nombor titik terapung berketepatan dua FP64 boleh memenuhi keperluan pengiraan saintifik yang tepat, seperti pemodelan molekul, dinamik bendalir dan senario lain
Selain itu, kami juga menguji penggunaan kuasa mesin Hasilnya menunjukkan bahawa penggunaan kuasa maksimum pelayan G952N6 ialah 3224 W apabila dihidupkan, penggunaan kuasa tanpa beban di bawah sistem ialah 823 W, dan penggunaan kuasa. di bawah 50% beban sistem (di bawah sistem Jalankan PTU+FIO+gpu_burn untuk membiarkan CPU, memori dan cakera NVMe/cakera keras mencapai 50%, 10 minit) ialah 3365 W. Penggunaan kuasa maksimum di bawah sistem (jalankan YES+DD di bawah sistem untuk membolehkan CPU, memori, dan cakera NVMe/cakera keras mencapai 100%, 10 minit) ialah 3652 W. Pelayan ini mempunyai prestasi yang baik dan kawalan penggunaan kuasa dan prestasi penjimatan tenaga juga. sangat terpuji.
Ringkasan:
Melalui ujian di atas, pelayan Adam Server G952N6 menunjukkan prestasi yang sangat baik dari segi prestasi pemproses dan memori, keupayaan berbilang teras dan berbilang benang boleh mengendalikan puncak perniagaan dengan mudah apabila memproses data serentak tinggi dan berskala besar. Keupayaan pengembangan PCIe boleh memenuhi keperluan AI panas semasa dalam mana-mana senario, dan boleh mengeluarkan sepenuhnya potensi GPU untuk membawa prestasi besar kepada aplikasi seperti pembelajaran mendalam dan analisis data besar Dengan sokongan pelbagai bentuk cakera keras seperti NVMe, Ia boleh memenuhi pelbagai keperluan kompleks dengan lebih baik dalam senario perniagaan seperti Internet, AI dan pengkomputeran awan, seperti penyimpanan data kompleks berskala besar, pengembangan sumber anjal, pengkomputeran berprestasi tinggi, dll. Daripada prestasi keseluruhan, Adam Pelayan G952N6 Ia adalah produk yang sangat kompetitif untuk era awan dan AI.
Atas ialah kandungan terperinci Memenuhi keperluan pengkomputeran kompleks era AI Kajian semula Adam Server G952N6. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI