


Sembilan kaedah analisis kepentingan ciri Python yang biasa digunakan

Analisis kepentingan ciri digunakan untuk memahami kegunaan atau nilai setiap ciri (pembolehubah atau input) dalam membuat ramalan. Matlamatnya adalah untuk mengenal pasti ciri paling penting yang mempunyai kesan terbesar pada output model, dan ia merupakan kaedah yang sering digunakan dalam pembelajaran mesin.
Mengapa analisis kepentingan ciri penting
Jika anda mempunyai set data dengan berdozen atau bahkan ratusan ciri, setiap ciri mungkin mempunyai sumbangan kepada prestasi model pembelajaran mesin anda. Tetapi tidak semua ciri dicipta sama. Sesetengahnya mungkin berlebihan atau tidak relevan, yang meningkatkan kerumitan pemodelan dan boleh menyebabkan pemasangan berlebihan.
Analisis kepentingan ciri boleh mengenal pasti dan menumpukan pada ciri yang paling bermaklumat, menghasilkan kelebihan berikut: 1. Berikan cerapan: Dengan menganalisis kepentingan ciri, kami boleh mendapatkan cerapan tentang ciri dalam data yang mempunyai kesan paling besar pada hasil, sekali gus membantu kami memahami sifat data dengan lebih baik. 2. Optimumkan model: Dengan mengenal pasti ciri utama, kami boleh mengoptimumkan prestasi model, mengurangkan overhed pengkomputeran dan storan yang tidak diperlukan, dan meningkatkan kecekapan latihan dan ramalan model. 3. Pemilihan ciri: Analisis kepentingan ciri boleh membantu kami memilih ciri dengan kuasa ramalan yang paling tinggi, dengan itu meningkatkan ketepatan dan keupayaan generalisasi model. 4. Terangkan model: Analisis kepentingan ciri juga boleh membantu kami menerangkan hasil ramalan model, mendedahkan corak dan hubungan sebab di sebalik model dan meningkatkan kebolehtafsiran model Bersama
- Latihan dan inferens yang lebih pantas .
- Kebolehtafsiran yang dipertingkatkan
- Mari kita lihat dengan lebih mendalam beberapa kaedah analisis kepentingan ciri dalam Python.
- Kaedah Analisis Kepentingan Ciri
1. Pilih Pilih Kepentingan Kepentingan
Kaedah ini menyusun nilai setiap ciri secara rawak, dan kemudian memantau tahap kemerosotan prestasi model. Jika penurunan lebih besar, ini bermakna ciri itu lebih pentingfrom sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier from sklearn.inspection import permutation_importance from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=1) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) baseline = rf.score(X_test, y_test) result = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=1, scoring='accuracy') importances = result.importances_mean # Visualize permutation importances plt.bar(range(len(importances)), importances) plt.xlabel('Feature Index') plt.ylabel('Permutation Importance') plt.show()
2. Kepentingan ciri terbina dalam (coef_ atau feature_importances_)
Sesetengah model, seperti regresi linear dan hutan rawak secara langsung Output markah kepentingan ciri. Ini menunjukkan sumbangan setiap ciri kepada ramalan akhir. 
from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier X, y = load_breast_cancer(return_X_y=True) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X, y) importances = rf.feature_importances_ # Plot importances plt.bar(range(X.shape[1]), importances) plt.xlabel('Feature Index') plt.ylabel('Feature Importance') plt.show()
3, Tinggalkan satu keluar
Alih keluar satu ciri pada satu masa dan nilai ketepatannya. 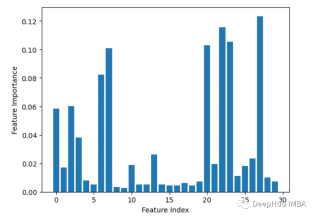
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt import numpy as np # Load sample data X, y = load_breast_cancer(return_X_y=True) # Split data into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # Train a random forest model rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) # Get baseline accuracy on test data base_acc = accuracy_score(y_test, rf.predict(X_test)) # Initialize empty list to store importances importances = [] # Iterate over all columns and remove one at a time for i in range(X_train.shape[1]):X_temp = np.delete(X_train, i, axis=1)rf.fit(X_temp, y_train)acc = accuracy_score(y_test, rf.predict(np.delete(X_test, i, axis=1)))importances.append(base_acc - acc) # Plot importance scores plt.bar(range(len(importances)), importances) plt.show()
4. Analisis korelasi
Kandungan yang perlu ditulis semula ialah: Kira korelasi antara ciri dan pembolehubah sasaran, semakin penting ciri tersebut 
Alih keluar ciri secara rekursif dan lihat cara ia mempengaruhi prestasi model. Ciri yang mengakibatkan penurunan yang lebih besar apabila dialih keluar adalah lebih penting.
import pandas as pd from sklearn.datasets import load_breast_cancer X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y correlations = df.corrwith(df.y).abs() correlations.sort_values(ascending=False, inplace=True) correlations.plot.bar()
Kepentingan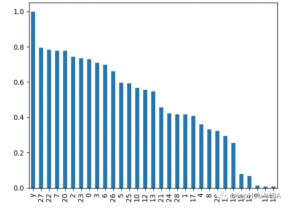
Kira satu Bilangan kali ciri digunakan dalam membelah data Ciri ini digunakan dalam semua pokok. Lebih banyak pemisahan bermakna lebih penting
from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import RFE import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y rf = RandomForestClassifier() rfe = RFE(rf, n_features_to_select=10) rfe.fit(X, y) print(rfe.ranking_)
7. Analisis komponen utama PCA
Lakukan analisis komponen utama pada ciri dan lihat nisbah varians yang dijelaskan bagi setiap komponen utama. Ciri dengan beban yang lebih tinggi pada beberapa komponen pertama adalah lebih penting.
import xgboost as xgb import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y model = xgb.XGBClassifier() model.fit(X, y) importances = model.feature_importances_ importances = pd.Series(importances, index=range(X.shape[1])) importances.plot.bar()
 8. Analisis varians ANOVA
8. Analisis varians ANOVA
Gunakan f_classif() untuk mendapatkan analisis nilai varians bagi setiap ciri. Semakin tinggi nilai f, semakin kuat korelasi antara ciri dan sasaran.
from sklearn.decomposition import PCA import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y pca = PCA() pca.fit(X) plt.bar(range(pca.n_components_), pca.explained_variance_ratio_) plt.xlabel('PCA components') plt.ylabel('Explained Variance')
 9. Ujian khi kuasa dua
9. Ujian khi kuasa dua
Gunakan fungsi chi2() untuk mendapatkan statistik khi kuasa dua bagi setiap ciri. Ciri dengan markah yang lebih tinggi lebih berkemungkinan bebas daripada pembolehubah sasaran
from sklearn.feature_selection import chi2 import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y chi_scores = chi2(X, y) chi_scores = pd.Series(chi_scores[0], index=range(X.shape[1])) chi_scores.plot.bar()
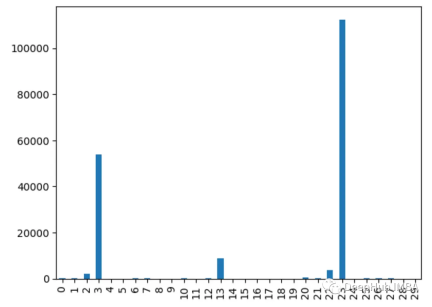
为什么不同的方法会检测到不同的特征?
由于不同的特征重要性方法,有时可以确定哪些特征是最重要的
1、他们用不同的方式衡量重要性:
有的使用不同特特征进行预测,监控精度下降
像XGBOOST或者回归模型使用内置重要性来进行特征的重要性排序
而PCA着眼于方差解释
2、不同模型有不同模型的方法:
线性模型偏向于处理线性关系,而树模型则更倾向于捕捉接近根节点的特征
3、交互作用:
有些方法可以获取特征之间的相互关系,而有些方法则不行,这会导致结果的不同
3、不稳定:
使用不同的数据子集,重要性值可能在同一方法的不同运行中有所不同,这是因为数据差异决定的
4、Hyperparameters:
通过调整超参数,例如主成分分析(PCA)组件或决策树的深度,也会对结果产生影响
所以不同的假设、偏差、数据处理和方法的可变性意味着它们并不总是在最重要的特征上保持一致。
选择特征重要性分析方法的一些最佳实践
- 尝试多种方法以获得更健壮的视图
- 聚合结果的集成方法
- 更多地关注相对顺序,而不是绝对值
- 差异并不一定意味着有问题,检查差异的原因会对数据和模型有更深入的了解
Atas ialah kandungan terperinci Sembilan kaedah analisis kepentingan ciri Python yang biasa digunakan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Elakkan 5 kesilapan biasa ini di AI yang setiap orang baru membuatApr 18, 2025 am 11:25 AM
Elakkan 5 kesilapan biasa ini di AI yang setiap orang baru membuatApr 18, 2025 am 11:25 AMMemulakan perjalanan AI anda? Elakkan perangkap biasa ini! Panduan ini menyoroti lima pemula kesilapan yang kerap membuat dan menawarkan penyelesaian untuk pengalaman pembelajaran yang lebih lancar dan lebih berjaya. Takeaways Kunci: Menguasai fundamental AI sebelum mengatasi masalah
 Tech dengan hormat: AI dan Kuasa Komuniti Orang AsliApr 18, 2025 am 11:21 AM
Tech dengan hormat: AI dan Kuasa Komuniti Orang AsliApr 18, 2025 am 11:21 AMJawapannya kompleks. AI membawa potensi besar untuk menyokong penentuan nasib sendiri, pemeliharaan bahasa, dan pengawasan iklim. Tetapi ia juga risiko memperdalam corak pemadaman, eksploitasi, dan pengecualian yang lama-kecuali jika ia berlaku
 Kesan ejen AI maya mengenai pengalaman produk digitalApr 18, 2025 am 11:13 AM
Kesan ejen AI maya mengenai pengalaman produk digitalApr 18, 2025 am 11:13 AMRevolusi Perkhidmatan Pelanggan: Kebangkitan Ejen AI Maya dalam Sistem Maklumat Bersepadu Dalam landskap digital yang pesat berkembang, perniagaan sentiasa mencari cara inovatif untuk meningkatkan komunikasi pelanggan. Integrasi
 Google bersalah sekali lagi, Meta di Percubaan, Openai Social, IR Rolls Up Touchcast AIApr 18, 2025 am 11:10 AM
Google bersalah sekali lagi, Meta di Percubaan, Openai Social, IR Rolls Up Touchcast AIApr 18, 2025 am 11:10 AMPada 17 April 2025, Hakim Daerah A.S. Leonie Brinkema memutuskan bahawa Google telah memonopoli segmen utama pasaran pengiklanan digital secara haram. Mahkamah memutuskan bahawa Google menyalahgunakan dominasinya dengan mengikat pelayan iklan penerbit dan pertukaran iklannya,
 AV Bytes: Inovasi AI Mingguan yang menampilkan SearchGPT, Llama 3.1 dan banyak lagiApr 18, 2025 am 11:06 AM
AV Bytes: Inovasi AI Mingguan yang menampilkan SearchGPT, Llama 3.1 dan banyak lagiApr 18, 2025 am 11:06 AMSatu kejayaan besar dalam bidang AI minggu ini! Av Bytes membawa anda kemajuan terkini dalam bidang AI, dan kegembiraan tidak boleh dilepaskan! Masa depan enjin carian? Openai's SearchGPT, Meta's Llama 3.1, dan Model 2 besar Mistral AI semua menolak AI ke ketinggian baru. Di samping itu, AI memenangi pingat dalam Olimpik Matematik dan menunjukkan potensi melampaui doktor manusia dalam bidang diagnosis perubatan. Semua ini menunjukkan bahawa fiksyen sains secara beransur -ansur menjadi realiti! Sorotan minggu ini: Openai's SearchGPT: Prototaip enjin carian baru yang menggunakan teknologi pemprosesan bahasa semulajadi maju untuk meningkatkan kecekapan pengambilan maklumat. Meta's Llama 3.1: Merangkul
 Apakah rantaian ketumpatan dalam kejuruteraan segera? - Analytics VidhyaApr 18, 2025 am 11:04 AM
Apakah rantaian ketumpatan dalam kejuruteraan segera? - Analytics VidhyaApr 18, 2025 am 11:04 AMMenguasai rantaian ketumpatan dalam kejuruteraan segera: Buat arahan ringkas dan berkesan Dalam pemprosesan bahasa semulajadi (NLP) dan kecerdasan buatan, menguasai kejuruteraan segera menjadi penting. Kemahiran ini menggabungkan sains dan seni, dan ia melibatkan dengan teliti merancang arahan yang tepat untuk membimbing model AI untuk menghasilkan hasil yang diinginkan. Di antara banyak teknologi, rantai ketumpatan menonjol sebagai cara yang kuat untuk mewujudkan tip ringkas dan berkesan. Artikel ini secara mendalam meneroka konsep, penerapan rantai ketumpatan dalam kejuruteraan tip dan kepentingan mereka dalam penciptaan kandungan yang didorong oleh AI. Gambaran Keseluruhan Petua mengenai kaedah rantaian ketumpatan dalam kejuruteraan adalah penting dalam NLP dan AI. Secara beransur -ansur meningkatkan pelbagai ringkasan dengan memampatkan dan menambah maklumat yang relevan.
 Elevenlabs API: Panduan untuk Sintesis Suara, Pengklonan, dan banyak lagiApr 18, 2025 am 10:59 AM
Elevenlabs API: Panduan untuk Sintesis Suara, Pengklonan, dan banyak lagiApr 18, 2025 am 10:59 AMElevenlabs: merevolusikan sintesis suara dengan AI Mengubah teks menjadi suara yang menawan dengan mudah dengan sintesis suara dan penyelesaian audio AI ElevenLabs. Panduan ini meneroka ciri utama ElevenLabs, menyediakan demo API praktikal
 Membangun Carian Persamaan Imej yang cekap dengan VGG16 dan FAIApr 18, 2025 am 10:56 AM
Membangun Carian Persamaan Imej yang cekap dengan VGG16 dan FAIApr 18, 2025 am 10:56 AMPengambilan Imej Rapid: Membina Sistem Carian Kesamaan Berkelajuan Tinggi dengan VGG16 dan Faiss Bayangkan kekecewaan mencari secara manual melalui foto -foto yang tidak terhingga untuk mencari imej tertentu. Artikel ini menerangkan penyelesaian: membina kilat cepat


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Dreamweaver Mac版
Alat pembangunan web visual

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

