Model bahasa berskala besar (LLM) termasuk struktur penyahkod sahaja (seperti model keluarga GPT dan LLAMA), struktur pengekod sahaja (seperti BERT) dan struktur penyahkod pengekod (seperti T5) dan model variannya mempunyai telah Ia telah mencapai kejayaan yang luar biasa dan telah digunakan secara meluas dalam pelbagai pemprosesan bahasa dan tugas berbilang modal. Walaupun kejayaan ini, kos latihan LLM masih tinggi sehinggakan hanya segelintir syarikat yang mampu membayar kos latihannya. Di samping itu, trend semasa menunjukkan bahawa data latihan berskala besar akan digunakan pada masa hadapan, yang akan meningkatkan lagi kos pembangunan model besar. Sebagai contoh, latihan LLAMA-1 menggunakan token 1-1.4 TB, manakala Llama 2 mencapai 2 TB. Satu lagi cabaran utama dalam membangunkan LLM ialah penilaian. Kaedah penilaian arus perdana dibahagikan kepada dua kategori: penilaian pengetahuan (MMLU dan C-Eval) dan penilaian tugas NLP. Kaedah penilaian ini mungkin tidak benar-benar menggambarkan keupayaan model kerana mungkin terdapat isu kebocoran data, iaitu beberapa bahagian set data penilaian mungkin telah digunakan semasa proses latihan model. Tambahan pula, kaedah penilaian berorientasikan pengetahuan mungkin tidak mencukupi untuk menilai tahap kecerdasan. Kaedah penilaian yang lebih adil dan objektif adalah untuk mengukur kecerdasan kecerdasan (IQ) LLM, iaitu menyamaratakan LLM kepada keadaan dan konteks yang tidak dilihat dalam data latihan. Strategi Pertumbuhan. Untuk menyelesaikan masalah kos latihan, banyak institusi seperti Institut Penyelidikan Kecerdasan Buatan Zhiyuan Beijing dan Institut Teknologi Pengkomputeran Akademi Sains China baru-baru ini telah membuat beberapa percubaan - melatih LLM tahap parameter 100 bilion melalui strategi pertumbuhan untuk kali pertama. Pertumbuhan bermakna bilangan parameter semasa latihan tidak tetap, tetapi berkembang daripada model yang lebih kecil kepada model yang lebih besar. 
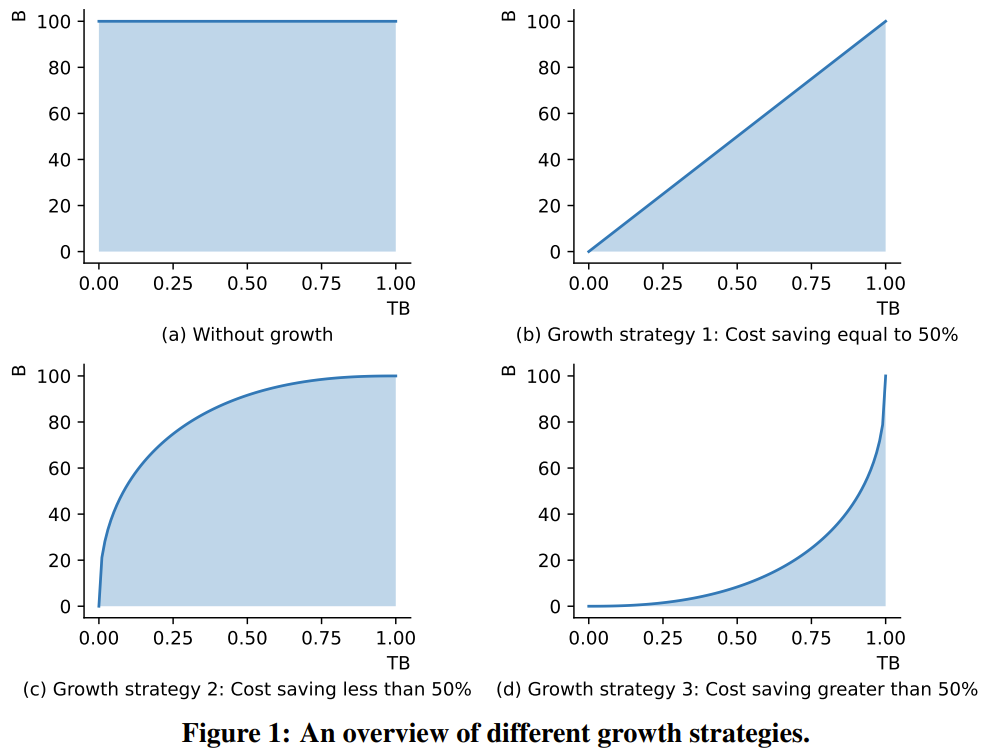
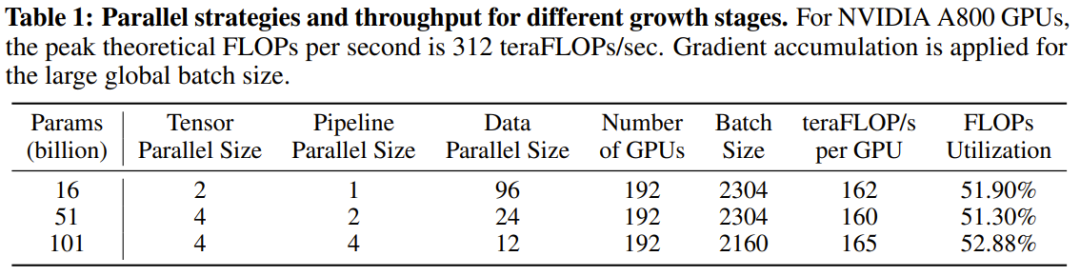
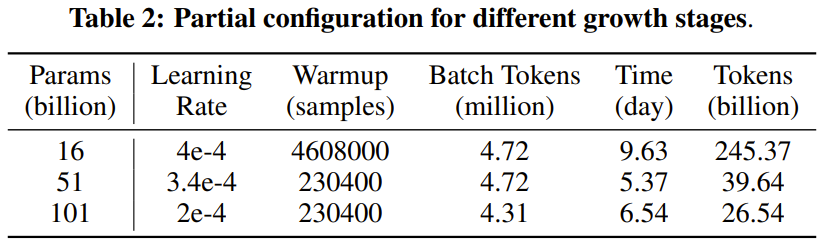
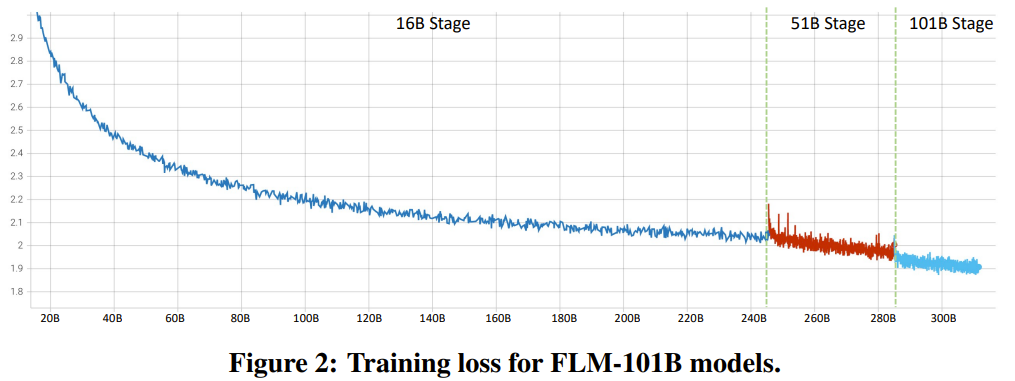
Rajah 1 menunjukkan tiga senario tipikal strategi pertumbuhan. Oleh kerana FLOP LLM adalah berkadar secara kasar dengan bilangan parameternya, kawasan antara lengkung perubahan parameter model dan paksi X boleh mewakili kos pengiraan latihan.
Rajah 1 (a) menunjukkan strategi latihan standard tanpa pertumbuhan model 1 (b) ialah strategi pertumbuhan linear, yang boleh menjimatkan 50% daripada kos 1 (c) ialah strategi pertumbuhan sederhana , yang menjimatkan kurang daripada 50% daripada kos 1 (d) ialah strategi pertumbuhan radikal yang boleh menjimatkan lebih daripada 50% kos. Analisis ini menggambarkan bahawa untuk menjimatkan kos pengkomputeran sebanyak mungkin, strategi pertumbuhan yang agresif harus diguna pakai. Reka bentuk pengendali pertumbuhan kajian baharu ini diilhamkan oleh MSG dalam kertas kerja "pra-latihan model bahasa 2x lebih pantas melalui pertumbuhan struktur bertopeng", yang merupakan satu set lengkap operasi yang meliputi keempat-empat Transformer dimensi pertumbuhan struktur. Lebih penting lagi, MSG boleh berkembang sambil mengekalkan fungsinya dengan ketat. Oleh itu, walaupun model kecil boleh belajar dengan cepat dengan ruang carian parameter yang lebih kecil, pengetahuannya boleh diwarisi oleh model yang lebih besar berikutnya. Ini membolehkan strategi pertumbuhan mencapai prestasi yang lebih baik menggunakan kos pengiraan yang sama atau kurang. Model FLM-101B sumber terbuka. Penyelidik di Institut Penyelidikan Zhiyuan melatih model LLM dengan 101 bilion parameter melalui pertumbuhan beransur-ansur, dan mereka juga menyatakan bahawa mereka akan mengeluarkan model itu sebagai sumber terbuka. Seni bina model ini adalah evolusi FreeLM. Oleh itu, para penyelidik menamakannya FLM-101B, di mana F bermaksud Percuma. Rangka kerja FreeLM mempunyai dua objektif pra-latihan, yang masing-masing dipandu oleh isyarat bahasa dan isyarat guru. Dalam penyelidikan baharu ini, kedua-dua matlamat ini disatukan ke dalam paradigma pemodelan bahasa yang sama. Tanda Aras Penilaian IQ. Sebagai tambahan kepada paradigma latihan kos rendah, pasukan itu juga membuat satu lagi sumbangan dengan mencadangkan satu set penanda aras yang sistematik untuk penilaian kecerdasan kecerdasan (IQ) LLM. Penyelidikan terdahulu telah menunjukkan bahawa walaupun penunjuk tahap kebingungan (PPL) boleh mencerminkan kualiti teks yang dijana pada tahap tertentu, ia tidak boleh dipercayai. Sebaliknya, skala data latihan LLM adalah sangat besar sehingga sukar untuk kita membezakan sama ada model itu hanya memetik data pengetahuan, atau sama ada ia benar-benar mencapai keupayaan penaakulan, analisis dan generalisasi seperti manusia, yang apa kajian ini mentakrifkan asas IQ. Beberapa metrik penilaian yang biasa digunakan (MMLU untuk Bahasa Inggeris dan C-Eval untuk Bahasa Cina) jelas berorientasikan pengetahuan dan tidak dapat mencerminkan sepenuhnya tahap kecerdasan model. Untuk pemeriksaan kewarasan, pasukan menjalankan ujian: lima penyelidik sains komputer dari universiti terkenal dunia mengambil peperiksaan menggunakan soalan ujian kimia C-Eval. Ternyata ketepatan mereka hampir sama seperti meneka secara rawak kerana kebanyakan sukarelawan telah melupakan apa yang mereka pelajari tentang kimia. Oleh itu, penanda aras penilaian yang menekankan pengetahuan tentang kepakaran tidak mencukupi untuk mengukur IQ model. Untuk mengukur IQ LLM secara menyeluruh, pasukan membangunkan penanda aras penilaian IQ yang mengambil kira empat aspek utama IQ: pemetaan simbol, pemahaman peraturan, perlombongan corak dan penentangan terhadap gangguan.
Bahasa bersifat simbolik. Terdapat beberapa kajian menggunakan simbol dan bukannya label kategori untuk menilai tahap kecerdasan LLM. Begitu juga, pasukan itu menggunakan pendekatan pemetaan simbolik untuk menguji keupayaan LLM untuk membuat generalisasi kepada konteks yang tidak kelihatan.
Keupayaan penting kecerdasan manusia ialah memahami peraturan yang diberikan dan mengambil tindakan yang sepadan. Kaedah ujian ini telah digunakan secara meluas dalam pelbagai peringkat ujian. Oleh itu, pemahaman peraturan menjadi ujian kedua di sini.
Kandungan yang ditulis semula: Perlombongan corak ialah bahagian penting kecerdasan, yang melibatkan aruhan dan deduksi. Dalam sejarah perkembangan sains, kaedah ini memainkan peranan yang penting. Selain itu, soalan ujian dalam pelbagai pertandingan selalunya memerlukan kebolehan menjawab ini. Atas sebab ini, kami memilih perlombongan corak sebagai penunjuk penilaian ketiga
Penunjuk terakhir dan sangat penting ialah keupayaan anti-gangguan, yang juga merupakan salah satu keupayaan teras kecerdasan. Kajian telah menunjukkan bahawa kedua-dua bahasa dan imej mudah terganggu oleh bunyi bising. Dengan mengambil kira perkara ini, pasukan menggunakan imuniti gangguan sebagai metrik penilaian akhir.
Sudah tentu, empat penunjuk ini bukanlah kata akhir dalam penilaian IQ LLM, tetapi ia boleh menjadi titik permulaan untuk merangsang pembangunan penyelidikan seterusnya, dan dijangka akhirnya membawa kepada rangka kerja penilaian IQ LLM yang komprehensif. Sumbangan utama kajian ini termasuk:
Pengkaji menyatakan bahawa ini adalah percubaan penyelidikan LLM untuk melatih lebih daripada 100 bilion parameter dari awal menggunakan strategi pertumbuhan. Pada masa yang sama, ini juga merupakan model parameter 100 bilion kos terendah pada masa ini, hanya berharga 100,000 dolar AS
Dengan menambah baik objektif latihan FreeLM, kaedah carian hiperparameter yang berpotensi dan pertumbuhan memelihara fungsi, penyelidikan ini menyelesaikan masalah ketidakstabilan . Para penyelidik percaya kaedah ini juga boleh membantu komuniti penyelidikan saintifik yang lebih luas.
Para penyelidik juga menjalankan perbandingan percubaan model baharu dengan model yang berkuasa sebelum ini, termasuk menggunakan penanda aras berorientasikan pengetahuan dan penanda aras penilaian IQ sistematik yang baru dicadangkan. Keputusan eksperimen menunjukkan bahawa model FLM-101B adalah kompetitif dan teguh
Pasukan akan mengeluarkan pusat pemeriksaan model, kod, alatan berkaitan, dll. untuk mempromosikan penyelidikan dan pembangunan LLM dwibahasa dalam bahasa Cina dan Inggeris dengan skala 100 bilion parameter.
FLM-101B gambaran keseluruhan reka bentukSecara seni bina, FLM-101B menggunakan FreeLM sebagai rangkaian tulang belakang dan menyepadukan xPos. Dari segi saiz model, terima kasih kepada strategi pertumbuhan baharu, penyelidik boleh mendapatkan model tiga saiz: 16B, 51B dan 101B dalam satu latihan. Bagi tetapan pra-latihan, FLM-101B mewarisi strategi latihan FreeLM. Dari segi strategi pertumbuhan, tidak seperti amalan biasa model latihan saiz berbeza secara bebas, pasukan boleh melatih tiga model secara berurutan dengan parameter 16B, 51B dan 101B, di mana setiap model mewarisi saiz yang lebih besar daripada sebelumnya. satu. Pengetahuan tentang model kecil. Bagi perkakasan latihan, sekumpulan 24 pelayan DGX-A800 GPU (8×80G) digunakan; masa latihan FLM-101B adalah kurang daripada 26 hari untuk lebih banyak strategi selari dan konfigurasi model rujuk jadual di bawah 1 dan 2.
Kestabilan latihan FLM-101B Untuk menyelesaikan masalah yang tidak stabil seperti percanggahan kerugian dan letupan kecerunan yang diterangkan secara ringkas, seperti yang diterangkan secara ringkas oleh penyelidik. Ramalan kerugian. Kaedah yang baru dicadangkan untuk mencapai kestabilan latihan adalah seperti berikut: Pertama, tentukan pengagihan data sebelum memulakan latihan FLM-16B. Seterusnya, lakukan carian grid pada tiga hiperparameter, termasuk kadar pembelajaran, sisihan piawai permulaan dan suhu softmax lapisan output. Carian grid dilakukan dengan menjalankan model pengganti dengan dimensi keadaan tersembunyi (iaitu, lebar model) 256, kiraan kepala 2 dan kiraan parameter 40 juta. Semua hiperparameter struktur lain dan data latihan model pengganti ini adalah sama seperti FLM-16B. Menggunakan keselarian data pada 6 nod, carian grid mengambil masa 24.6 jam, yang secara kasarnya diterjemahkan kepada 6 jam menggunakan konfigurasi 24-nod. Melalui carian grid ini, penyelidik menemui hiperparameter optimum: kadar pembelajaran = 4e-4, sisihan piawai = 1.6e-2, suhu softmax = 2.0. Kemudian mereka memindahkan hiperparameter ini melalui µP untuk mencapai pengalaman latihan yang lancar yang mengelakkan masalah ketidakstabilan. Apabila MSG digunakan dalam kombinasi, LM-51B dan FLM-101B tidak mempunyai masalah perbezaan pertumbuhan berikutnya. Rajah 2 menunjukkan keluk kehilangan latihan yang lengkap.
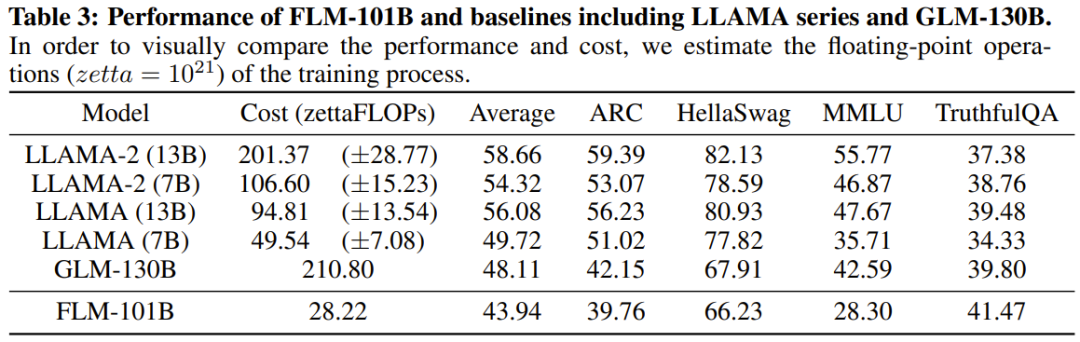
Ketepatan campuran melalui Bfloat16. Tujuan menggunakan ketepatan campuran adalah untuk menjimatkan kos memori dan masa semasa runtime Di sini mereka memilih Bfloat16. Jadual 3 membandingkan prestasi FLM-101B dengan model penanda aras berkuasa lain (model siri LLAMA dan GLM-130B).
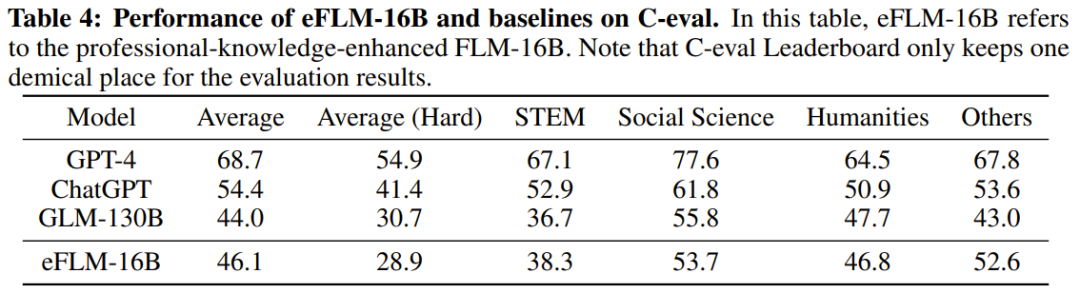
Para penyelidik berkata bahawa keputusan ini menunjukkan bahawa FLM-101B tidak mempunyai sebarang kelebihan dalam pengetahuan fakta, dan jika lebih banyak data latihan boleh digunakan, prestasinya akan terus bertambah baik. Jadual 4 menunjukkan keputusan eFLM-16B berbanding model garis dasar dari segi penilaian kepakaran.
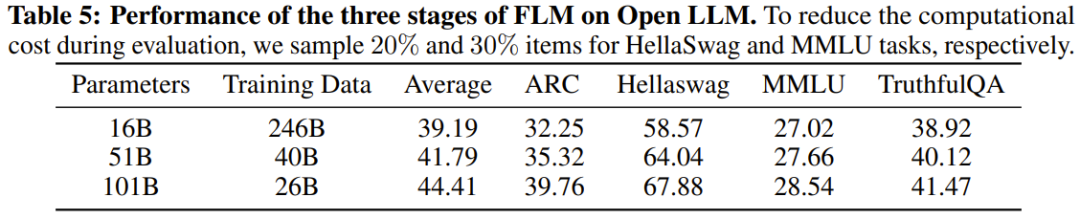
Ternyata markah pada set data yang menekankan kepakaran tidak menggambarkan tahap kecerdasan LLM, kerana sesetengah data latihan tertentu mungkin mempunyai sumbangan yang amat menggalakkan. Jadual 5 menunjukkan prestasi setiap peringkat model FLM.
Seperti yang dijangkakan, prestasi FLM akan bertambah baik apabila model meningkat. FLM-101B menunjukkan prestasi terbaik pada hampir setiap misi. Ini bermakna setiap kali model berkembang, ia mewarisi pengetahuan dari peringkat sebelumnya. Dalam percubaan, untuk menjalankan penilaian yang lebih sistematik terhadap IQ LLM, pasukan dari Institut Penyelidikan Harta Intelek menggunakan beberapa set data yang berkaitan dengan IQ yang diperlukan. pengubahsuaian, mereka juga menjana beberapa data sintetik baharu. Secara khusus, penilaian IQ yang mereka cadangkan terutamanya mempertimbangkan empat aspek: pemetaan simbol, pemahaman peraturan, perlombongan corak dan anti-gangguan. Tugasan ini mempunyai satu persamaan utama: semuanya bergantung pada penaakulan dan generalisasi dalam konteks baharu. . yang setanding dengan GPT-3 dan lebih baik daripada GLM-130B. Selain pengaruh data latihan, penyelidik membuat spekulasi bahawa kelebihan ini mungkin disebabkan oleh model kecil pada peringkat awal memperhalusi ruang carian yang lebih kecil Apabila model menjadi lebih besar dan lebih luas, dan keupayaan generalisasi adalah dipertingkatkan, Kelebihan ini terus dimainkan. Atas ialah kandungan terperinci Dengan AS$100,000 + 26 hari, LLM kos rendah dengan 100 bilion parameter telah dilahirkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!