
Rumah >Peranti teknologi >AI >Salesforce bekerjasama dengan penyelidik MIT untuk membuka tutorial semakan GPT-4 sumber terbuka untuk menyampaikan lebih banyak maklumat dengan lebih sedikit perkataan
Salesforce bekerjasama dengan penyelidik MIT untuk membuka tutorial semakan GPT-4 sumber terbuka untuk menyampaikan lebih banyak maklumat dengan lebih sedikit perkataan

- 王林ke hadapan
- 2023-09-19 20:33:13929semak imbas
Teknologi ringkasan automatik telah mencapai kemajuan yang ketara dalam beberapa tahun kebelakangan ini, terutamanya disebabkan oleh anjakan paradigma. Pada masa lalu, teknologi ini bergantung terutamanya pada penalaan halus diselia pada set data beranotasi, tetapi kini menggunakan model bahasa besar (LLM) untuk gesaan sifar tangkapan, seperti GPT-4. Melalui tetapan segera yang teliti, tanpa latihan tambahan, anda boleh mencapai kawalan yang baik ke atas panjang ringkasan, tema, gaya dan ciri lain
Tetapi satu aspek sering diabaikan: ketumpatan maklumat ringkasan. Secara teorinya, sebagai pemampatan teks lain, ringkasan harus lebih padat, iaitu, mengandungi lebih banyak maklumat, daripada fail sumber. Memandangkan kependaman tinggi penyahkodan LLM, adalah penting untuk merangkumi lebih banyak maklumat dengan lebih sedikit perkataan, terutamanya untuk aplikasi masa nyata.
Walau bagaimanapun, ketumpatan maklumat adalah soalan terbuka: jika abstrak mengandungi butiran yang tidak mencukupi, ia bersamaan dengan tiada maklumat jika ia mengandungi terlalu banyak maklumat tanpa menambah jumlah panjang, ia akan menjadi Tidak Dapat Difahami. Untuk menyampaikan lebih banyak maklumat dalam belanjawan token tetap, adalah perlu untuk menggabungkan pengabstrakan, pemampatan dan gabungan.
Dalam penyelidikan baru-baru ini, penyelidik dari Salesforce, MIT, dan lain-lain cuba menentukan had peningkatan kepadatan dengan meminta keutamaan manusia untuk satu set ringkasan yang dijana oleh GPT-4. Kaedah ini memberikan banyak inspirasi untuk meningkatkan "keupayaan ekspresi" model bahasa besar seperti GPT-4

Pautan kertas: https://arxiv. org/pdf/2309.04269.pdf
Alamat set data: https://huggingface.co/datasets/griffin/chain_of_density
Secara khusus, penyelidik menggunakan setiap Purata bilangan entiti setiap token digunakan sebagai proksi untuk ketumpatan, menghasilkan ringkasan awal, jarang entiti. Kemudian, mereka secara berulang mengenal pasti dan menggabungkan 1-3 entiti yang hilang daripada ringkasan sebelumnya tanpa meningkatkan jumlah panjang (5 kali jumlah panjang). Setiap ringkasan mempunyai nisbah entiti kepada token yang lebih tinggi daripada ringkasan sebelumnya. Berdasarkan data keutamaan manusia, penulis akhirnya menentukan bahawa manusia lebih suka ringkasan yang hampir padat seperti ringkasan tulisan manusia, dan lebih padat daripada ringkasan yang dihasilkan oleh gesaan GPT-4 biasa
Sumbangan keseluruhan kajian boleh Diringkaskan dalam perkara berikut:
-
Kita perlu membangunkan kaedah iteratif berasaskan segera (CoD) untuk meningkatkan ketumpatan entiti ringkasan
#🎜 🎜# - Penilaian ketumpatan ringkasan secara manual dan automatik dalam artikel CNN/Daily Mail untuk lebih memahami kemakluman (memihak kepada lebih banyak entiti) dan kejelasan (memihak kepada lebih banyak entiti) # 🎜🎜# Abstrak GPT-4 sumber terbuka, anotasi dan satu set 5000 abstrak CoD tanpa nota untuk penilaian atau penghalusan.
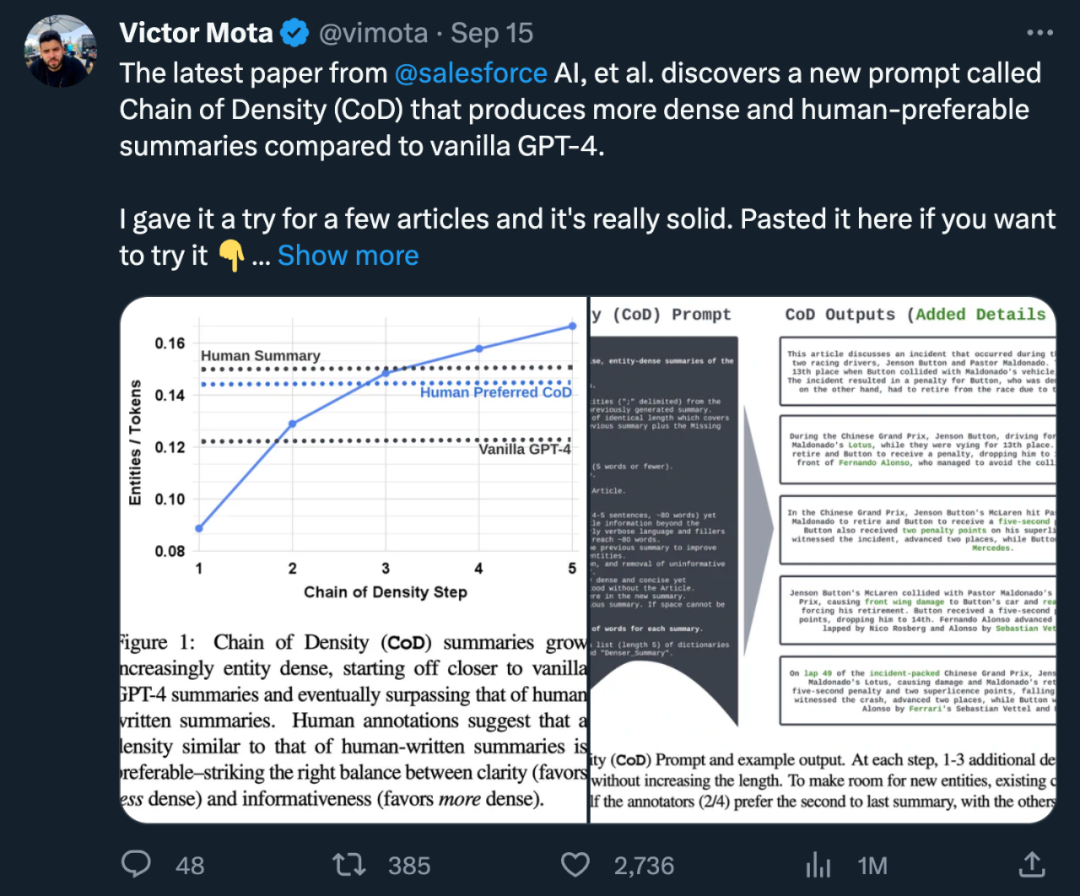
Pengarang merumuskan satu rantaian ketumpatan (CoD) Prompt, yang menjana ringkasan awal dan menjadikan ketumpatan entitinya terus meningkat. Khususnya, dalam bilangan interaksi yang tetap, set unik entiti penting dalam teks sumber dikenal pasti dan digabungkan ke dalam ringkasan sebelumnya tanpa menambah panjang.
Sampel gesaan dan output ditunjukkan dalam Rajah 2. Pengarang tidak menyatakan secara eksplisit jenis entiti, sebaliknya mentakrifkan entiti yang hilang sebagai:
- Berkaitan dengan cerita utama:
-
# 🎜🎜 #
Spesifik: ringkas dan tepat (5 perkataan atau kurang); #Setia: hadir dalam artikel; Pengarang memilih 100 artikel secara rawak daripada set ujian ringkasan CNN/DailyMail untuk menjana ringkasan CoD. Untuk memudahkan rujukan, mereka membandingkan statistik ringkasan CoD dengan ringkasan rujukan titik tumpu khas dan ringkasan yang dijana oleh GPT-4 di bawah gesaan biasa: "Tulis ringkasan artikel yang sangat pendek. Tidak lebih daripada 70 patah perkataan." 🎜# - Statistik situasi Dalam kajian, penulis merumuskan daripada dua aspek: data statistik langsung dan data statistik tidak langsung. Statistik langsung (token, entiti, ketumpatan entiti) dikawal secara langsung oleh CoD, manakala statistik tidak langsung ialah hasil sampingan yang dijangkakan daripada ketumpatan.
-
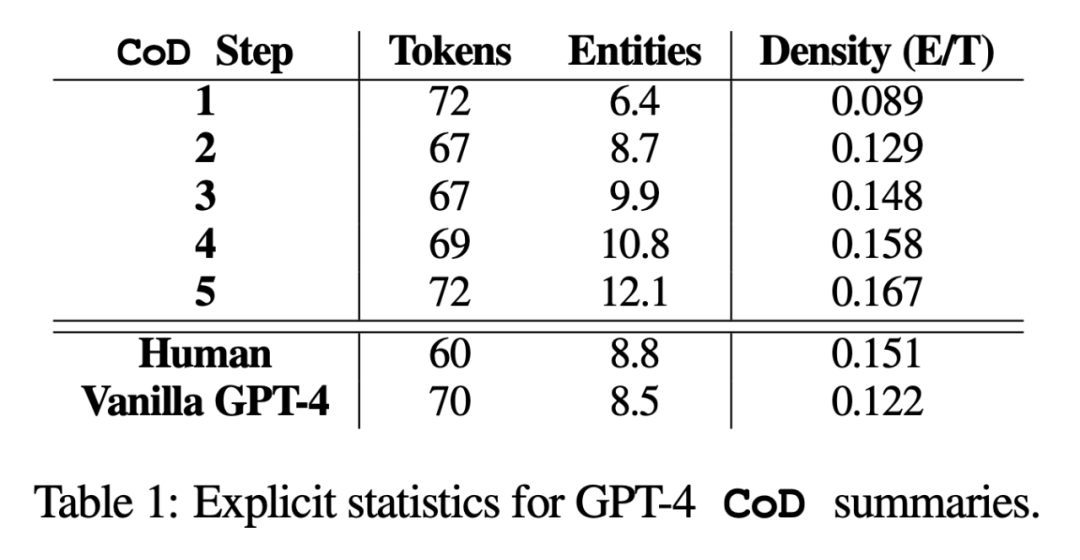
Statistik langsung. Seperti yang ditunjukkan dalam Jadual 1, langkah kedua mengurangkan panjang dengan purata 5 token (daripada 72 kepada 67) disebabkan oleh penyingkiran perkataan yang tidak perlu daripada ringkasan yang panjang lebar. Ketumpatan entiti bermula pada 0.089, pada mulanya lebih rendah daripada manusia dan Vanila GPT-4 (0.151 dan 0.122), dan akhirnya meningkat kepada 0.167 selepas 5 langkah ketumpatan.
 Statistik tidak langsung. Tahap abstraksi harus meningkat dengan setiap langkah CoD, kerana abstrak berulang kali ditulis semula untuk memberi ruang kepada setiap entiti tambahan. Penulis mengukur abstraksi menggunakan ketumpatan pengekstrakan: panjang persegi purata serpihan yang diekstrak (Grusky et al., 2018). Begitu juga, gabungan konsep harus meningkat secara monoton apabila entiti ditambahkan pada ringkasan panjang tetap. Penulis menyatakan tahap integrasi dengan purata bilangan ayat sumber yang sejajar dengan setiap ayat ringkasan. Untuk penjajaran, penulis menggunakan kaedah keuntungan relatif ROUGE (Zhou et al., 2018), yang menjajarkan ayat sumber dengan ayat sasaran sehingga keuntungan ROUGE relatif ayat tambahan tidak lagi positif. Mereka juga menjangkakan pengedaran kandungan, atau kedudukan dalam artikel dari mana kandungan ringkasan datang, akan berubah.
Statistik tidak langsung. Tahap abstraksi harus meningkat dengan setiap langkah CoD, kerana abstrak berulang kali ditulis semula untuk memberi ruang kepada setiap entiti tambahan. Penulis mengukur abstraksi menggunakan ketumpatan pengekstrakan: panjang persegi purata serpihan yang diekstrak (Grusky et al., 2018). Begitu juga, gabungan konsep harus meningkat secara monoton apabila entiti ditambahkan pada ringkasan panjang tetap. Penulis menyatakan tahap integrasi dengan purata bilangan ayat sumber yang sejajar dengan setiap ayat ringkasan. Untuk penjajaran, penulis menggunakan kaedah keuntungan relatif ROUGE (Zhou et al., 2018), yang menjajarkan ayat sumber dengan ayat sasaran sehingga keuntungan ROUGE relatif ayat tambahan tidak lagi positif. Mereka juga menjangkakan pengedaran kandungan, atau kedudukan dalam artikel dari mana kandungan ringkasan datang, akan berubah. Secara khusus, penulis menjangkakan bahawa abstrak CoD pada mulanya akan menunjukkan "lead bias" (Lead Bias) yang kuat, tetapi kemudian secara beransur-ansur mula memperkenalkan entiti dari tengah dan akhir artikel. Untuk mengukur ini, mereka menggunakan penjajaran dalam gabungan untuk menulis semula kandungan dalam bahasa Cina, tanpa ayat asal muncul dan mengukur purata kedudukan ayat merentas semua ayat sumber yang dijajarkan.
Rajah 3 mengesahkan hipotesis ini: apabila langkah menulis semula meningkat, abstraksi meningkat (imej kiri menunjukkan ketumpatan pengekstrakan yang lebih rendah), kadar gabungan juga meningkat (imej tengah menunjukkan), dan abstrak mula memasukkan kandungan dari tengah dan akhir artikel (ditunjukkan di sebelah kanan). Menariknya, semua ringkasan CoD adalah lebih abstrak berbanding dengan ringkasan tulisan manusia dan ringkasan asas
Apabila menulis semula kandungan, ia perlu ditulis semula dalam bahasa Cina, ayat asal tidak perlu muncul
Untuk lebih baik Untuk memahami pertukaran ringkasan CoD, penulis menjalankan kajian manusia berasaskan keutamaan dan melakukan penilaian berasaskan penarafan menggunakan GPT-4.
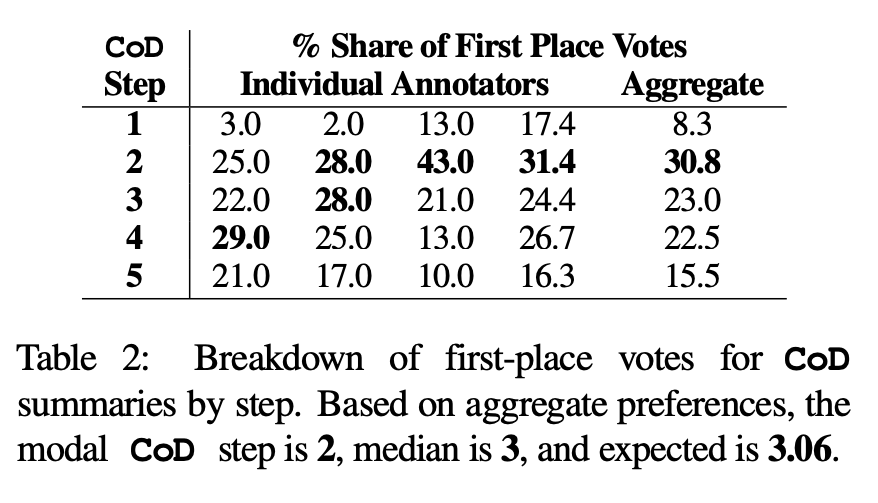
Keutamaan manusia. Khususnya, untuk 100 artikel yang sama (5 langkah *100 = 500 abstrak kesemuanya), pengarang secara rawak menunjukkan abstrak dan artikel CoD "yang dibuat semula" kepada empat pengarang pertama kertas kerja. Setiap annotator memberikan ringkasan kegemaran mereka berdasarkan definisi Stiennon et al. (2020) tentang "ringkasan yang baik." Jadual 2 melaporkan undian tempat pertama setiap annotator dalam peringkat CoD, serta ringkasan setiap annotator. Secara keseluruhannya, 61% daripada abstrak tempat pertama (23.0+22.5+15.5) melibatkan ≥3 langkah pemekatan. Nombor median langkah CoD pilihan adalah di tengah (3), dengan jangkaan nombor langkah 3.06.
Berdasarkan kepadatan purata dalam langkah ketiga, kepadatan entiti pilihan semua calon CoD adalah lebih kurang 0.15. Seperti yang dapat dilihat daripada Jadual 1, ketumpatan ini konsisten dengan ringkasan yang ditulis oleh manusia (0.151), tetapi jauh lebih tinggi daripada ringkasan yang ditulis dengan GPT-4 Prompt biasa (0.122)
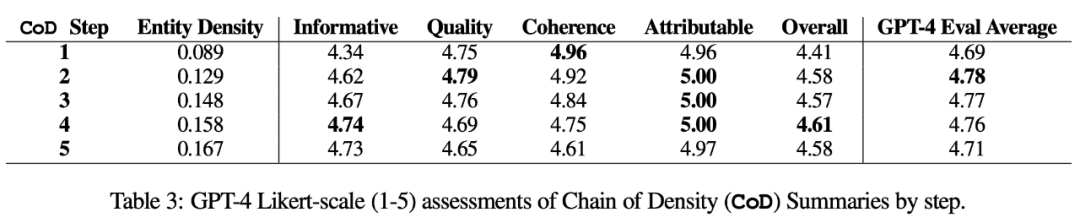
metrik automatik. Sebagai tambahan kepada penilaian manusia (di bawah), pengarang menggunakan GPT-4 untuk menjaringkan ringkasan CoD (1-5 mata) sepanjang 5 dimensi: kemakluman, kualiti, koheren, kebolehatributan dan keseluruhan. Seperti yang ditunjukkan dalam Jadual 3, ketumpatan berkorelasi dengan kemakluman, tetapi sehingga had, dengan skor memuncak pada langkah 4 (4.74).
Daripada purata skor setiap dimensi, langkah pertama dan terakhir CoD mempunyai skor terendah, manakala tiga langkah tengah mempunyai skor hampir (masing-masing 4.78, 4.77 dan 4.76).
Analisis kualitatif. Terdapat pertukaran yang jelas antara koheren/kebolehbacaan abstrak dan kemakluman. Dua langkah CoD ditunjukkan dalam Rajah 4: ringkasan satu langkah dipertingkatkan dengan lebih terperinci, dan ringkasan langkah yang satu lagi terjejas. Secara purata, ringkasan CoD perantaraan paling baik mencapai keseimbangan ini, tetapi pertukaran ini masih perlu ditakrifkan dan dikira dengan tepat dalam kerja masa hadapan.
Untuk butiran lanjut kertas, sila rujuk kertas asal.
 Statistik tidak langsung. Tahap abstraksi harus meningkat dengan setiap langkah CoD, kerana abstrak berulang kali ditulis semula untuk memberi ruang kepada setiap entiti tambahan. Penulis mengukur abstraksi menggunakan ketumpatan pengekstrakan: panjang persegi purata serpihan yang diekstrak (Grusky et al., 2018). Begitu juga, gabungan konsep harus meningkat secara monoton apabila entiti ditambahkan pada ringkasan panjang tetap. Penulis menyatakan tahap integrasi dengan purata bilangan ayat sumber yang sejajar dengan setiap ayat ringkasan. Untuk penjajaran, penulis menggunakan kaedah keuntungan relatif ROUGE (Zhou et al., 2018), yang menjajarkan ayat sumber dengan ayat sasaran sehingga keuntungan ROUGE relatif ayat tambahan tidak lagi positif. Mereka juga menjangkakan pengedaran kandungan, atau kedudukan dalam artikel dari mana kandungan ringkasan datang, akan berubah.
Statistik tidak langsung. Tahap abstraksi harus meningkat dengan setiap langkah CoD, kerana abstrak berulang kali ditulis semula untuk memberi ruang kepada setiap entiti tambahan. Penulis mengukur abstraksi menggunakan ketumpatan pengekstrakan: panjang persegi purata serpihan yang diekstrak (Grusky et al., 2018). Begitu juga, gabungan konsep harus meningkat secara monoton apabila entiti ditambahkan pada ringkasan panjang tetap. Penulis menyatakan tahap integrasi dengan purata bilangan ayat sumber yang sejajar dengan setiap ayat ringkasan. Untuk penjajaran, penulis menggunakan kaedah keuntungan relatif ROUGE (Zhou et al., 2018), yang menjajarkan ayat sumber dengan ayat sasaran sehingga keuntungan ROUGE relatif ayat tambahan tidak lagi positif. Mereka juga menjangkakan pengedaran kandungan, atau kedudukan dalam artikel dari mana kandungan ringkasan datang, akan berubah. 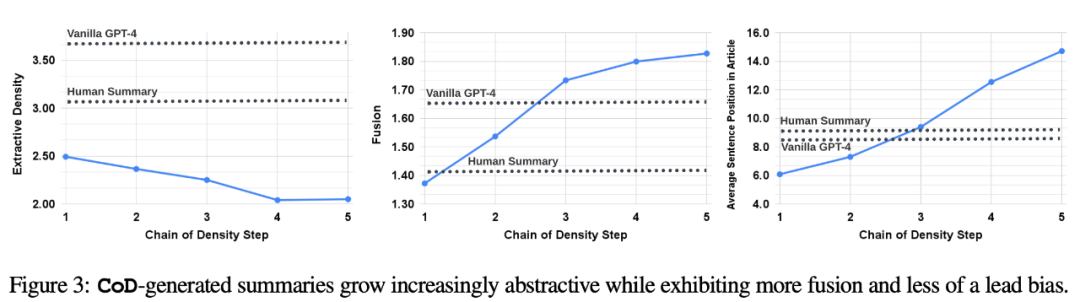
 Untuk butiran lanjut kertas, sila rujuk kertas asal.
Untuk butiran lanjut kertas, sila rujuk kertas asal. Atas ialah kandungan terperinci Salesforce bekerjasama dengan penyelidik MIT untuk membuka tutorial semakan GPT-4 sumber terbuka untuk menyampaikan lebih banyak maklumat dengan lebih sedikit perkataan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!