
Rumah >Peranti teknologi >AI >Tidak perlu 4 H100s! 34 bilion parameter Code Llama boleh dijalankan pada Mac, 20 token sesaat, terbaik pada penjanaan kod
Tidak perlu 4 H100s! 34 bilion parameter Code Llama boleh dijalankan pada Mac, 20 token sesaat, terbaik pada penjanaan kod

- PHPzke hadapan
- 2023-09-19 13:05:011022semak imbas
Seorang pembangun dalam komuniti sumber terbuka, Georgi Gerganov, mendapati bahawa dia boleh menjalankan model 34B Code Llama dengan ketepatan F16 penuh pada M2 Ultra, dan kelajuan inferens melebihi 20 token/s. .
 Penemuan George segera mencetuskan perbincangan di kalangan orang besar dalam industri kecerdasan buatan
Penemuan George segera mencetuskan perbincangan di kalangan orang besar dalam industri kecerdasan buatan
Karpathy tweet semula dan mengulas, "Pelaksanaan spekulatif LLM ialah pengoptimuman masa inferens yang sangat baik."
"Pensampelan Spekulatif" mempercepatkan inferens
Dalam contoh ini, Georgi menggunakan model draf kuantum Q4 7B (iaitu, Kod Llama 7B) untuk melaksanakan penyahkodan Kod Llama 7B, Ultra44B dan kemudiannya. menjana.
 Secara ringkasnya, gunakan "model kecil" untuk membuat draf, dan kemudian gunakan "model besar" untuk menyemak dan membuat pembetulan untuk mempercepatkan keseluruhan proses.
Secara ringkasnya, gunakan "model kecil" untuk membuat draf, dan kemudian gunakan "model besar" untuk menyemak dan membuat pembetulan untuk mempercepatkan keseluruhan proses.
Alamat GitHub: https://twitter.com/ggerganov/status/1697262700165013689
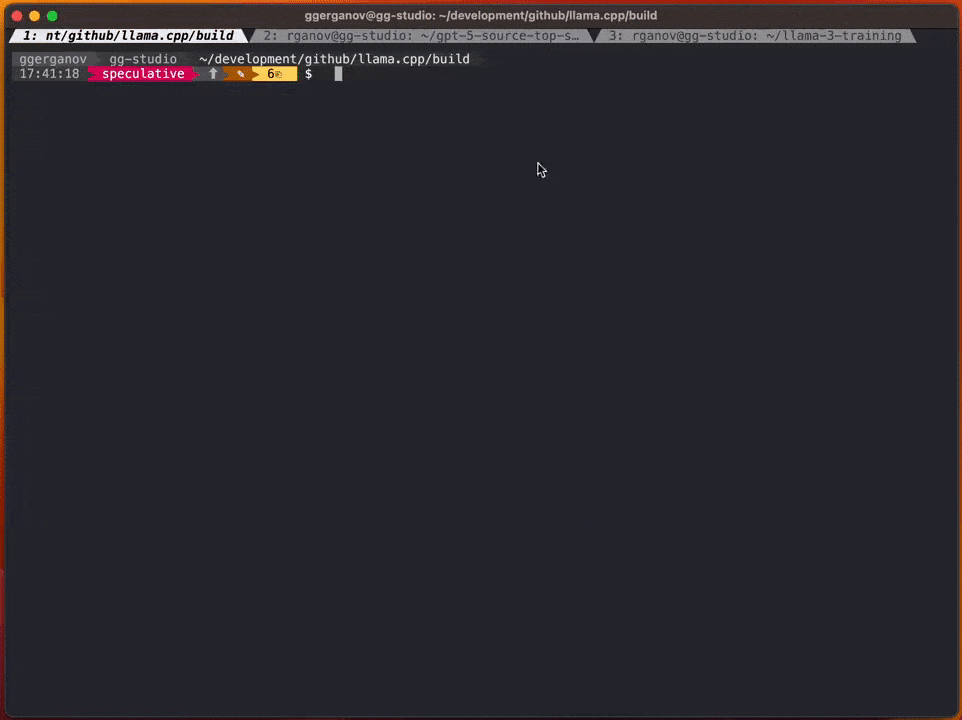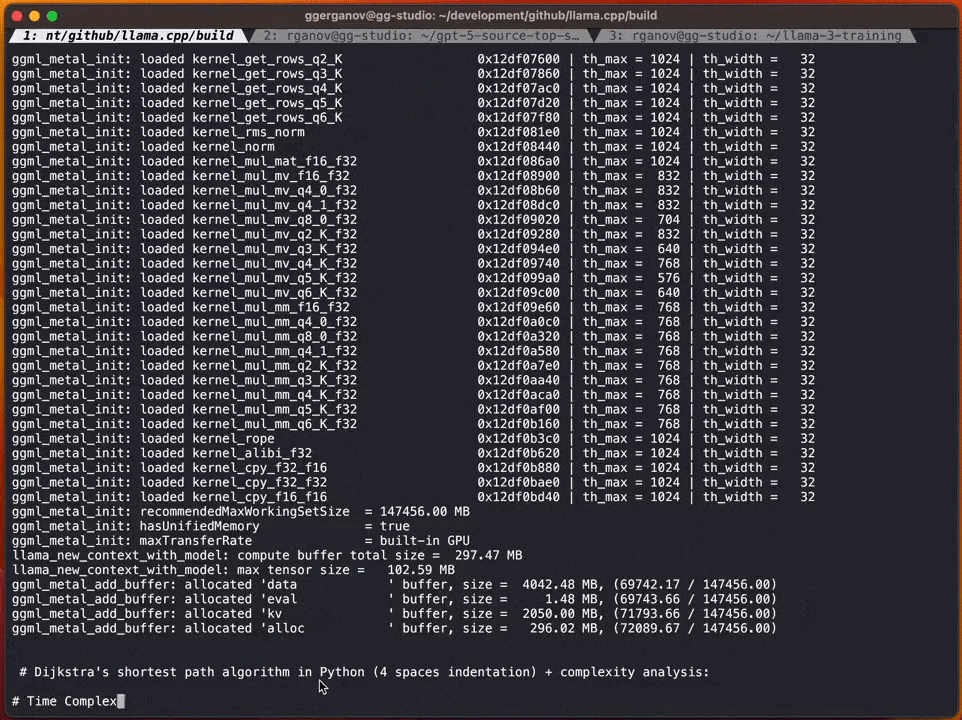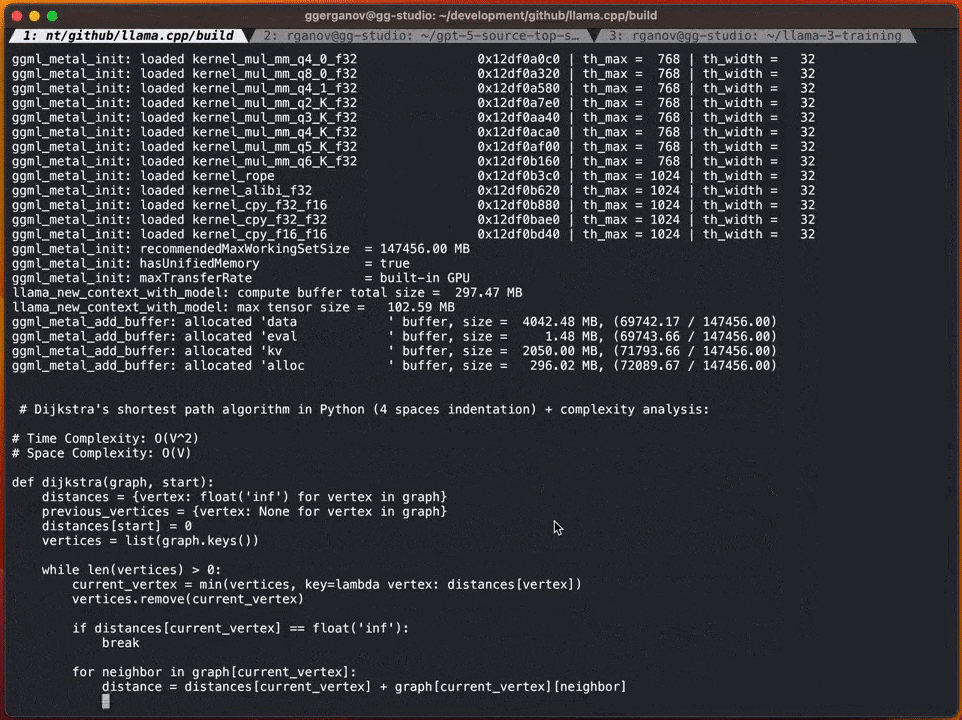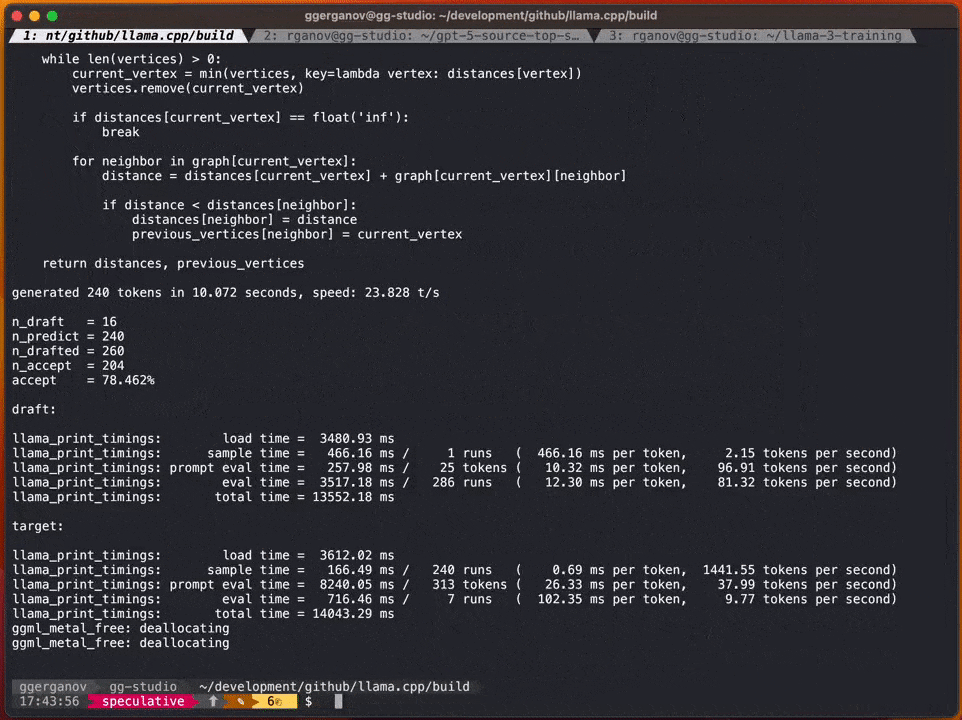
Menurut Georgi, kepantasannya adalah
:F16 34B: Lebih kurang. sesaat 10 token 
Apa yang perlu ditulis semula ialah: S4 7B: ~80 token sesaat
contoh sampling standard tanpa menggunakan sampel F16
Selepas menambah strategi pensampelan spekulatif, kelajuan boleh mencapai kira-kira 20 markah sesaatMenurut Georgi, kelajuan menjana kandungan mungkin berbeza-beza. Walau bagaimanapun, pendekatan ini nampaknya sangat berkesan dari segi penjanaan kod, kerana kebanyakan kosa kata boleh diteka dengan betul oleh model draf
Kes penggunaan menggunakan "persampelan tatabahasa" juga berkemungkinan besar mendapat manfaat daripadanya
Spekulasi Bagaimanakah pensampelan membolehkan inferens pantas?
Karpathy membuat penjelasan berdasarkan tiga kajian terdahulu oleh Google Brain, UC Berkeley dan DeepMind.

Sila klik pautan berikut untuk melihat kertas: https://arxiv.org/pdf/2211.17192.pdf
Alamat kertas: https://arxiv.org/pdf 1811.03115.pdf satu input token Masa adalah sama dengan masa yang diperlukan untuk membatch ke hadapan LLM pada token input K (K lebih besar daripada yang anda fikirkan).

Fakta yang tidak intuitif ini adalah kerana pensampelan sangat terhad oleh ingatan, dan kebanyakan "kerja" tidak dikira, tetapi pemberat Transformer dibaca daripada VRAM ke dalam cache pada cip untuk diproses.

Untuk menyelesaikan tugas membaca semua pemberat, lebih baik menerapkannya pada vektor input keseluruhan kelompok Sebab mengapa kita tidak boleh mengeksploitasi fakta ini secara naif dan sampel token K sekaligus adalah kerana setiap token N Semuanya bergantung pada token yang kami sampel pada langkah N-1. Ini adalah pergantungan bersiri, jadi pelaksanaan garis dasar hanya diteruskan satu demi satu dari kiri ke kanan. Kini, idea bijak ialah menggunakan model draf yang kecil dan murah untuk mula-mula menjana urutan calon yang terdiri daripada penanda K - "draf". Kami kemudian menyuapkan semua maklumat ini bersama-sama ke dalam model besar Mengikut kaedah di atas, ini hampir sepantas memasukkan hanya satu token. Kemudian, kami memeriksa model dari kiri ke kanan, dan logit yang diramalkan oleh token sampel. Mana-mana sampel yang sepadan dengan draf membolehkan kami segera melompat ke token seterusnya. Sekiranya terdapat perselisihan faham, kami meninggalkan model draf dan menanggung kos untuk melakukan kerja sekali sahaja (mengambil sampel draf model dan melakukan hantaran hadapan pada token seterusnya) Ini berfungsi dalam amalan Sebabnya ialah token draf akan diterima dalam kebanyakan kes, dan kerana ia adalah token mudah, model draf yang lebih kecil pun boleh menerimanya. Apabila token mudah ini diterima, kami akan melangkau bahagian ini. Token kesukaran yang model besar tidak bersetuju akan "kembali" kepada kelajuan asal, tetapi sebenarnya akan menjadi lebih perlahan kerana kerja tambahan. Jadi, secara ringkasnya: helah aneh ini berfungsi kerana LLM dikekang ingatan semasa membuat inferens. Dalam kes "saiz kelompok 1", satu jujukan minat diambil sampel, yang merupakan kes bagi kebanyakan kes penggunaan "LLM tempatan". Selain itu, kebanyakan token adalah "mudah". Pengasas bersama HuggingFace berkata model parameter 34 bilion itu kelihatan sangat besar dan tidak terurus di luar pusat data setahun setengah yang lalu. Kini ia boleh dikendalikan dengan mudah hanya dengan komputer riba LLM hari ini bukan satu titik kejayaan, tetapi sistem yang memerlukan berbilang komponen penting untuk berfungsi bersama dengan berkesan. Penyahkodan Spekulatif ialah contoh hebat yang membantu kita berfikir dari perspektif sistem. 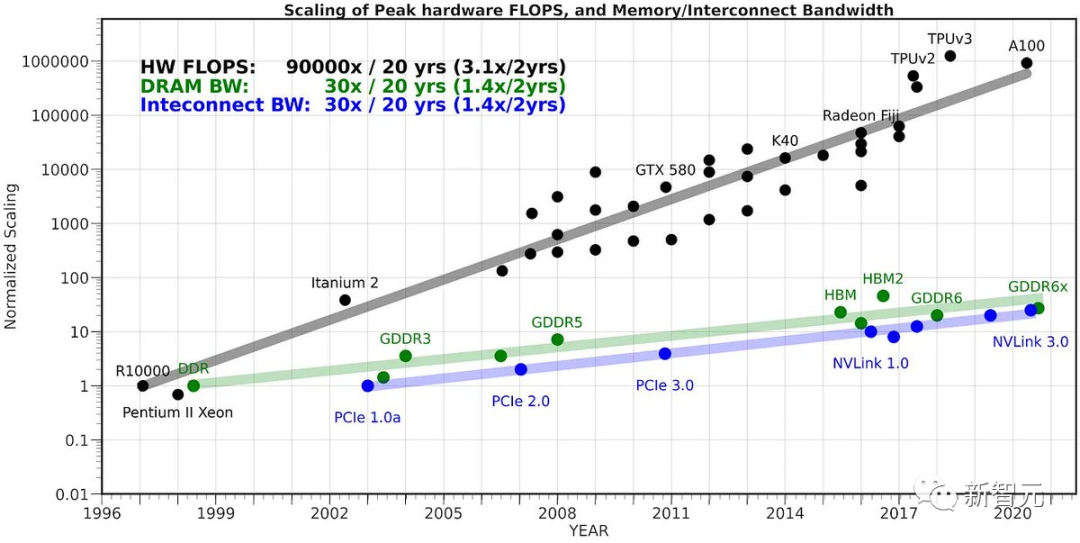

Atas ialah kandungan terperinci Tidak perlu 4 H100s! 34 bilion parameter Code Llama boleh dijalankan pada Mac, 20 token sesaat, terbaik pada penjanaan kod. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!