
Rumah >Peranti teknologi >AI >Microsoft mencadangkan teknologi yang dipatenkan untuk meramalkan pose objek yang diartikulasikan untuk menangkap pose badan AR/VR
Microsoft mencadangkan teknologi yang dipatenkan untuk meramalkan pose objek yang diartikulasikan untuk menangkap pose badan AR/VR

- 王林ke hadapan
- 2023-09-18 19:37:01953semak imbas
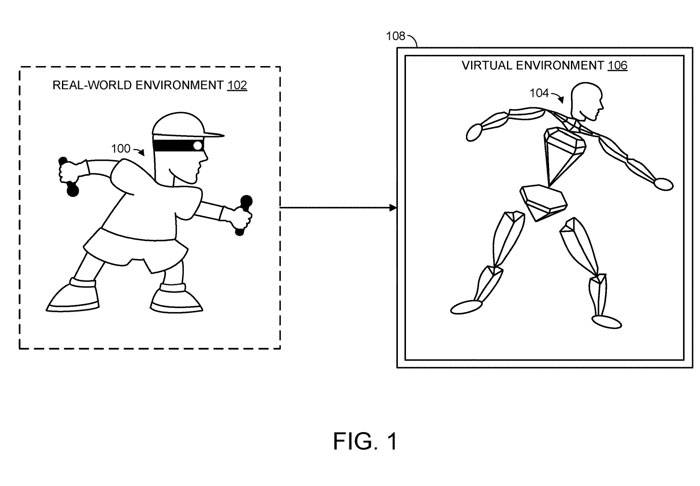
(Nweon 18 September 2023) Untuk mewakili postur dunia sebenar pengguna manusia dengan tepat, maklumat yang agak terperinci tentang kedudukan dan orientasi bahagian badan pengguna biasanya diperlukan, tetapi maklumat ini tidak selalu tersedia . Contohnya, apabila menggunakan set kepala untuk memberikan pengalaman realiti maya, sistem mungkin hanya boleh mendapatkan maklumat spatial yang berkaitan dengan kepala dan tangan pengguna. Walau bagaimanapun, dalam kebanyakan kes, ini tidak mencukupi untuk menghasilkan semula postur sebenar pengguna manusia dengan tepat
Jadi dalam aplikasi paten yang dipanggil "Ramalan pose untuk objek yang diartikulasikan", Microsoft mencadangkan teknologi untuk meramalkan pose objek yang diartikulasikan. Khususnya, model pembelajaran mesin menerima maklumat spatial n sambungan berbeza objek yang diartikulasikan, di mana n sendi adalah lebih kecil daripada semua sendi objek yang diartikulasikan.
Dalam kes pengguna manusia, sendi n mungkin termasuk sendi kepala pengguna manusia dan/atau satu atau dua sendi pergelangan tangan, yang dikaitkan dengan maklumat spatial yang memperincikan parameter kepala dan/atau tangan pengguna. 🎜🎜#
Model pembelajaran mesin telah dilatih untuk menerima maklumat spatial input untuk sambungan n+m objek yang diartikulasikan, dengan m lebih besar daripada atau sama dengan 1. Contohnya, semasa latihan awal, model pembelajaran mesin menerima data input yang sepadan dengan hampir semua sambungan objek yang diartikulasikan. Sambungan n+m mungkin termasuk setiap sambungan objek yang diartikulasikan.Dalam contoh lain, mungkin terdapat sambungan n+m di mana terdapat kurang daripada semua sambungan objek yang diartikulasikan. Semasa proses latihan, input data kepada model pembelajaran mesin mungkin disembunyikan secara beransur-ansur. Anda boleh menggantikan data input yang sepadan bagi nod tertentu dalam nod m dengan nilai yang dipratentukan, atau hanya tinggalkan
Dalam erti kata lain, model pembelajaran mesin dilatih untuk meramal dengan tepat pose objek yang diartikulasikan berdasarkan maklumat yang semakin berkurangan tentang kedudukan/orientasi pelbagai bahagian alih objek yang diartikulasikan.
Dalam erti kata lain, ciptaan boleh memberikan kelebihan teknologi yang meningkatkan interaksi manusia-komputer dengan lebih tepat menghasilkan semula gerak isyarat dunia sebenar pengguna manusia. Kelebihan teknikal ini termasuk menambah baik pengalaman realiti maya dan meningkatkan ketepatan sistem pengecaman gerak isyarat
Selain itu, teknologi yang diterangkan boleh mengurangkan penggunaan sumber pengkomputeran sambil menghasilkan semula postur sebenar pengguna manusia dengan tepat dengan mengurangkan jumlah data yang mesti dikumpul sebagai input kepada proses ramalan postur.
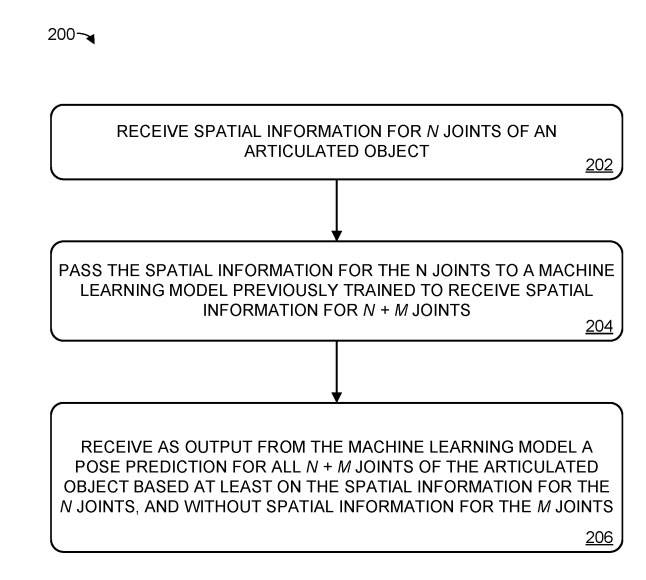
Contoh kaedah 200 menunjukkan Rajah 2 untuk meramalkan pose objek yang diartikulasikan
Sebagai contoh, sendi n mungkin termasuk sendi kepala badan manusia, dan maklumat spatial sendi kepala mungkin menerangkan parameter kepala manusia secara terperinci. Selain itu, sendi n mungkin termasuk satu atau lebih sendi pergelangan tangan badan manusia, dan maklumat spatial bagi satu atau lebih sendi pergelangan tangan mungkin menerangkan secara terperinci parameter satu atau lebih tangan badan manusia.
Maklumat spatial bagi n sendi objek yang diartikulasikan boleh diperoleh daripada output data kedudukan oleh satu atau lebih penderia. Penderia boleh disepadukan ke dalam satu atau lebih peranti yang dipegang atau dipakai oleh bahagian badan pengguna manusia yang sepadan.
Sebagai contoh, penderia mungkin termasuk satu atau lebih unit ukuran inersia yang disepadukan ke dalam peranti paparan yang dipasang di kepala dan/atau pengawal pegang tangan. Sebagai contoh lain, penderia mungkin termasuk satu atau lebih kamera.
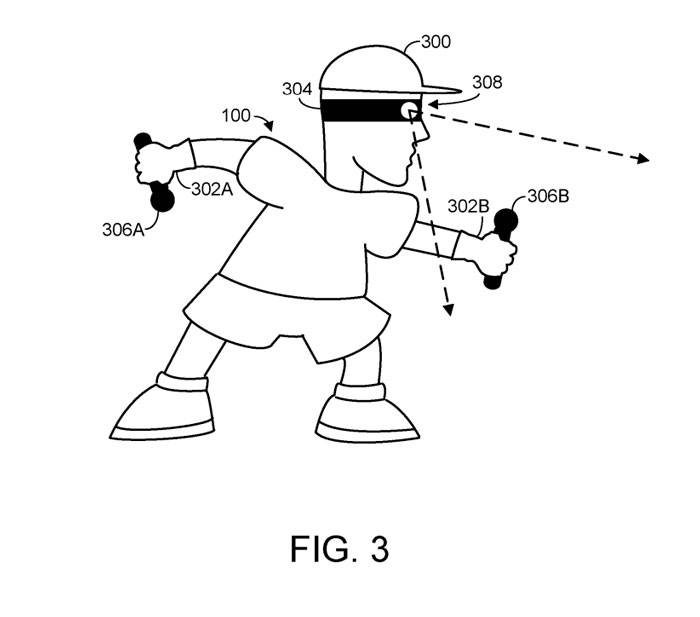
Rajah 3 secara skematik menggambarkan pelbagai jenis penderia di mana output daripada penderia mungkin termasuk atau digunakan untuk memperoleh maklumat spatial. Khususnya, pengguna manusia memakai peranti paparan yang dipasang di kepala 304 pada kepalanya 300 .
Selain itu, pengguna manusia memegang penderia kedudukan 306A dan 306B, yang mungkin dikonfigurasikan untuk mengesan dan melaporkan gerakan tangan pengguna ke paparan 304 yang dipasang di kepala dan/atau ke sistem pengkomputeran lain yang dikonfigurasikan untuk menerima maklumat spatial.
Dalam Rajah 2, kita kembali kepada situasi 204. Kami menyampaikan maklumat spatial n sendi kepada model pembelajaran mesin yang dilatih sebelum ini. Model ini menerima maklumat spatial bagi sambungan n+m sebagai input, dengan nilai m lebih besar daripada atau sama dengan 1. Dengan kata lain, berbanding model latihan sebelumnya, model pembelajaran mesin ini menerima kurang maklumat ruang bersama
Dalam 206, ramalan pose objek yang diartikulasikan diterima sebagai output daripada model pembelajaran mesin, ramalan itu berdasarkan sekurang-kurangnya maklumat spatial bagi n sendi dan tidak termasuk maklumat spatial sendi mereka. Dalam erti kata lain, walaupun maklumat spatial bagi sendi m tidak disediakan, model pembelajaran mesin boleh meramalkan postur lengkap objek sendi.
Skema 4 menunjukkan contoh model pembelajaran mesin 400 untuk menggambarkan proses ini
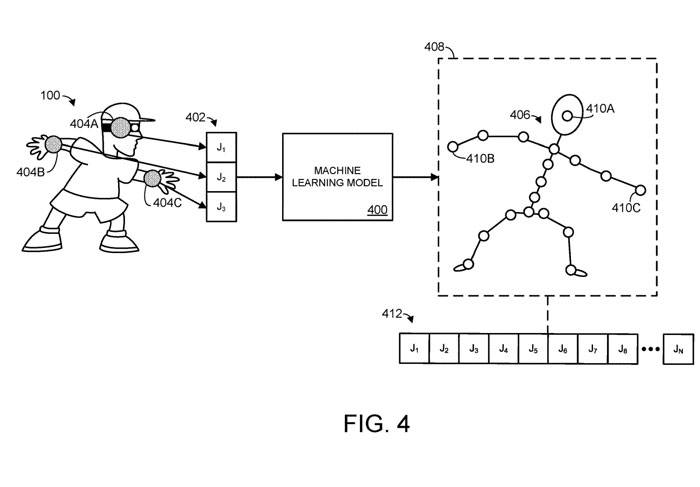
Dalam Rajah 4, model pembelajaran mesin menerima maklumat spatial 402, sepadan dengan tiga sambungan berbeza J1, J2 dan J3. Maklumat spatial untuk sendi boleh mengambil bentuk mana-mana data komputer yang sesuai yang menentukan atau boleh digunakan untuk memperoleh kedudukan dan/atau orientasi bahagian badan yang disambungkan ke sendi.
Sebagai contoh, maklumat spatial boleh secara langsung menentukan kedudukan dan orientasi bahagian badan, dan/atau maklumat spatial boleh menentukan satu atau lebih putaran sendi relatif kepada satu atau lebih paksi putaran. Dalam Rajah 4, sendi J1, J2, J3 sepadan dengan sendi kepala pengguna manusia 404A dan dua sendi pergelangan tangan 404B/404C, seperti yang ditunjukkan oleh bulatan berlorek yang ditindih pada badan pengguna.
Dalam contoh ini, sendi n termasuk tiga sendi, sepadan dengan sendi kepala dan pergelangan tangan badan manusia. Berdasarkan maklumat spatial input 402, model pembelajaran mesin mengeluarkan ramalan pose 406 objek yang diartikulasikan.
Selain itu, model pembelajaran mesin boleh mengeluarkan maklumat spatial yang diramalkan sepadan dengan sambungan yang diwakili oleh engsel maya. Pengguna manusia boleh diwakili oleh avatar dengan perkadaran kartun atau bukan manusia. Sebagai contoh, maklumat spatial yang diramalkan mungkin sepadan dengan sendi yang diwakili oleh SMPL.
Dalam erti kata lain, sendi perwakilan maya bagi perwakilan yang diartikulasikan tidak perlu mempunyai korespondensi 1:1 dengan sendi objek yang diartikulasikan. Oleh itu, output maklumat spatial yang diramalkan oleh model pembelajaran mesin mungkin untuk sambungan yang tidak sepadan secara langsung dengan sambungan n+m objek yang diartikulasikan. Sebagai contoh, perwakilan maya mungkin mempunyai kurang sendi tulang belakang daripada objek yang diartikulasikan.
Model pembelajaran mesin boleh dilatih dengan cara yang sesuai. Dalam satu penjelmaan, model pembelajaran mesin mungkin telah dilatih sebelum ini menggunakan data input latihan dengan label kebenaran tanah untuk objek yang diartikulasikan.
Dalam erti kata lain, maklumat spatial latihan bagi sendi objek yang diartikulasikan boleh diberikan kepada model pembelajaran mesin dan dilabelkan sebagai label kebenaran asas bagi pose sebenar objek yang diartikulasikan sepadan dengan maklumat spatial yang ditentukan.
Seperti yang dinyatakan di atas, model pembelajaran mesin boleh dilatih untuk menerima maklumat spatial sambungan n+m sebagai input. Ini melibatkan, dalam lelaran latihan pertama, menyediakan model pembelajaran mesin dengan data input latihan untuk semua sambungan n+m. Dalam siri lelaran latihan yang berikutnya, data input latihan bagi sendi m boleh ditutup secara beransur-ansur.
Sebagai contoh, dalam lelaran latihan kedua, sendi pertama m boleh disembunyikan, di mana maklumat spatial sendi dalam set data latihan digantikan dengan nilai pratakrif yang mewakili sendi bertopeng, atau ditinggalkan begitu sahaja.
sebagai contoh. Dalam lelaran latihan ketiga, sendi kedua m boleh ditutup, dan seterusnya, sehingga semua sendi m bertopeng, dan hanya maklumat spatial bagi n sendi diberikan kepada model pembelajaran mesin.
Proses ini digambarkan dalam Rajah 5a-5d. Khususnya, dalam Rajah 5A, model pembelajaran mesin 400 disediakan dengan set data input latihan. Dalam penjelmaan ini, data input latihan termasuk maklumat spatial yang sepadan dengan kepelbagaian postur berbeza objek yang diartikulasikan, termasuk postur pertama 502A dan postur kedua 502B.
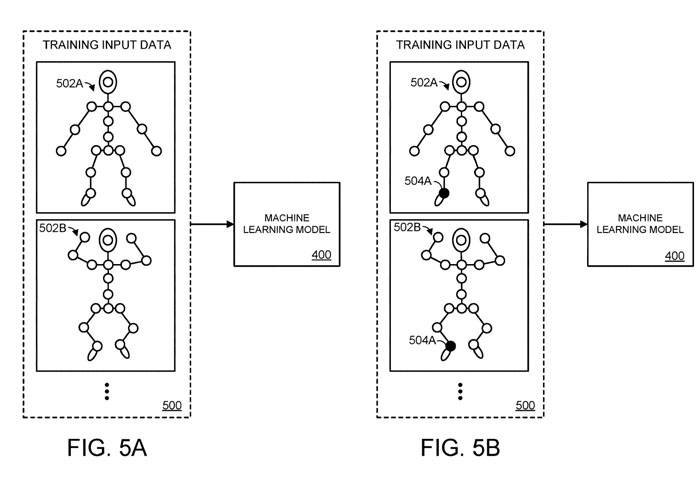
Dalam Rajah 5A, kami menyediakan maklumat spatial bagi sambungan n+m untuk objek diartikulasikan model pembelajaran mesin. Dalam perwakilan ringkas badan manusia ini, setiap bulatan yang mewakili sendi diwakili oleh corak isi putih. Walau bagaimanapun, dalam Rajah 5B kami telah melindungi 504A seperti yang ditunjukkan dengan corak isian hitam yang mewakili bulatan untuk penyambung 504A
Dalam erti kata lain, Rajah 5A mewakili lelaran awal proses latihan, di mana maklumat spatial semua sambungan n+m disediakan kepada model pembelajaran mesin. Rajah 5B menunjukkan lelaran kedua proses latihan, di mana sendi pertama 504A
antara sendi m bertopeng.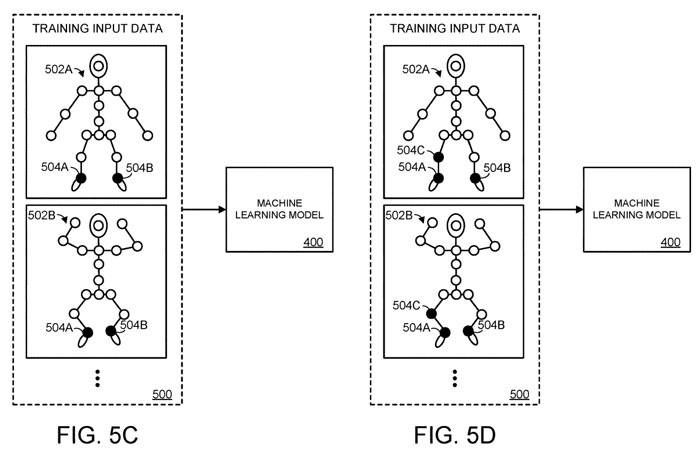
Dalam Rajah 5C, sambungan kedua 504B antara sendi m yang diwakili oleh engsel tersumbat. Begitu juga, dalam Rajah 5D, sendi ketiga di antara sendi m tersumbat. Lelaran latihan berbilang boleh diteruskan sehingga maklumat spatial setiap sendi m bertopeng, dan hanya maklumat spatial bagi n sendi diberikan kepada model pembelajaran mesin.
Dalam senario di atas, kami menerangkan situasi di mana objek yang diartikulasikan adalah seluruh tubuh badan manusia. Walau bagaimanapun, objek yang diartikulasikan juga boleh mengambil bentuk lain
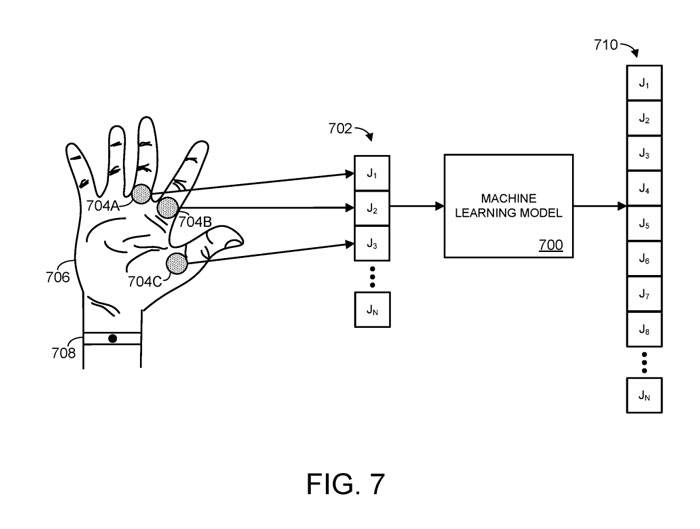
Seperti yang ditunjukkan dalam Rajah 7, objek yang diartikulasikan ialah tangan manusia, bukan seluruh tubuh manusia. Secara khusus, Rajah 7 menunjukkan contoh model pembelajaran mesin 700.
Model pembelajaran mesin 700 menerima maklumat spatial untuk sambungan J1, J2 dan J3, yang sepadan dengan tiga sambungan 704A-C objek yang diartikulasikan, dalam kes ini dalam bentuk tangan manusia 706.
Dalam kes ini, khususnya, sendi n termasuk satu atau lebih sendi jari tangan manusia. Maklumat spatial satu atau lebih sendi jari memperincikan parameter satu atau lebih jari atau segmen jari tangan manusia. Contohnya, maklumat spatial boleh menentukan kedudukan/orientasi jari tangan dan/atau putaran yang digunakan pada sendi tangan
Sebarang kaedah yang sesuai boleh digunakan untuk mengumpul maklumat ruang bersama, seperti melalui penderia kedudukan 708. Sebagai contoh, penderia kedudukan boleh mengambil bentuk kamera yang dikonfigurasikan untuk imej tangan. Sebagai contoh lain, penderia kedudukan boleh memasukkan antena frekuensi radio yang sesuai yang dikonfigurasikan untuk mendedahkan permukaan tangan kepada medan elektromagnet dan menilai kesan pergerakan dan kedekatan kulit manusia konduktif pada galangan medan elektromagnet pada antena
Mengikut maklumat spatial input 702, model pembelajaran mesin akan mengeluarkan set maklumat spatial yang diramalkan 710. Maklumat spatial 710 boleh digunakan untuk membina pose ramalan objek yang diartikulasikan. Seperti yang dinyatakan sebelum ini, maklumat spatial ini boleh mewakili kedudukan dan orientasi bahagian badan objek yang diartikulasikan
Paten berkaitan: Paten Microsoft | Ramalan pose untuk objek yang diartikulasikan
Microsoft pada asalnya menyerahkan permohonan paten yang dipanggil "Ramalan pose untuk objek yang diartikulasikan" pada Jun 2022, dan permohonan itu baru-baru ini diterbitkan oleh Pejabat Paten dan Tanda Dagangan Amerika Syarikat
Atas ialah kandungan terperinci Microsoft mencadangkan teknologi yang dipatenkan untuk meramalkan pose objek yang diartikulasikan untuk menangkap pose badan AR/VR. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Bolehkah set kepala AR/VR menjimatkan nilai pasaran Apple? Pendedahan yang paling lengkap ada di sini
- Kecerahan 4K+5000nit? AR/VR set kepala Apple Reality Pro terdedah
- Didedahkan bahawa set kepala Apple AR/VR akan tersedia dalam 6 warna dan 2 spesifikasi
- Penganalisis Morgan Stanley: Apple mempunyai 300,000-500,000 set kepala AR/VR dalam stok
- Gali ratusan paten AR/VR dan terokai semua aspek Apple XR