
Rumah >Peranti teknologi >AI >Beberapa kertas kerja telah dipilih untuk Interspeech 2023, dan Huoshan Speech menyelesaikan banyak jenis masalah praktikal dengan berkesan
Beberapa kertas kerja telah dipilih untuk Interspeech 2023, dan Huoshan Speech menyelesaikan banyak jenis masalah praktikal dengan berkesan

- 王林ke hadapan
- 2023-09-18 11:09:081077semak imbas
Baru-baru ini, beberapa kertas kerja daripada Pasukan Suara Gunung Berapi telah dipilih ke dalam Interspeech 2023, meliputi pengecaman bahasa pertuturan video pendek, timbre silang dan bahasa pertuturan gaya, dan bahasa pertuturan Terobosan inovatif dalam pelbagai arah aplikasi seperti penilaian kefasihan. Interspeech ialah salah satu persidangan teratas dalam bidang penyelidikan pertuturan yang dianjurkan oleh International Speech Communications Association ISCA Ia juga dikenali sebagai acara pemprosesan isyarat pertuturan komprehensif terbesar di dunia dan telah mendapat perhatian meluas daripada orang dalam bahasa global padang. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#interspeech2023#🎜🎜 ## 🎜🎜#event site#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 #Pembesaran Data Berasaskan Penggabungan Ujaran Rawak untuk Meningkatkan Pengecaman Pertuturan Video Pendek
Pembesaran Data Berasaskan Penggabungan Ujaran Rawak untuk Memperbaiki Pengecaman Pertuturan Video Pendek
Secara umumnya, salah satu batasan rangka kerja pengecaman pertuturan automatik (ASR) hujung ke hujung ialah jika tempoh latihan dan ayat ujian tidak sepadan, prestasinya mungkin terjejas. Dalam kertas kerja ini, pasukan Ucapan Huoshan mencadangkan kaedah peningkatan data berdasarkan penggabungan ayat rawak segera (RUC) sebagai peningkatan data bahagian hadapan untuk mengurangkan masalah latihan dan menguji ketidakpadanan panjang ayat dalam tugasan ASR video pendek. Secara khusus, pasukan mendapati bahawa pemerhatian berikut memainkan peranan utama dalam amalan inovatif: Biasanya, ayat latihan untuk ucapan spontan video pendek adalah lebih pendek daripada ayat yang ditranskripsikan manusia ( purata kira-kira 3 saat), manakala ayat ujian yang dijana daripada bahagian hadapan pengesanan aktiviti pertuturan adalah lebih lama (kira-kira 10 saat secara purata). Oleh itu, ketidakpadanan ini mungkin membawa kepada prestasi yang lemah
Pasukan Volcano Speech mengatakan bahawa untuk kerja empirikal, kami menggunakan model ASR berbilang kelas daripada 15 bahasa. Set data untuk bahasa ini berkisar antara 1,000 hingga 30,000 jam. Semasa fasa penalaan halus model, kami turut serta-merta menambah data yang telah disampel dan disambung daripada berbilang keping data. Berbanding dengan data yang tidak ditambah, kaedah ini mencapai purata pengurangan kadar ralat perkataan relatif sebanyak 5.72% merentas semua bahasa WER ayat panjang menurun dengan ketara selepas latihan RUC (biru vs. merah)Mengikut eksperimen. pemerhatian, kaedah RUC telah meningkatkan keupayaan pengecaman ayat panjang dengan ketara, manakala prestasi ayat pendek tidak menurun. Analisis lanjut mendapati kaedah penambahan data yang dicadangkan boleh mengurangkan sensitiviti model ASR kepada perubahan normalisasi panjang, yang mungkin bermakna model ASR lebih teguh dalam persekitaran yang pelbagai. Ringkasnya, walaupun kaedah peningkatan data RUC mudah dikendalikan, kesannya adalah ketara Pemarkahan kefasihan berdasarkan kaedah fonetik dan prosodi yang diselia sendiri (Pendekatan Pembelajaran Penyeliaan Sendiri Fonetik dan Prosodi untuk Pemarkahan Kefasihan Bukan Asli)
Salah satu dimensi penting untuk menilai keupayaan bahasa pelajar bahasa kedua ialah kefasihan lisan. Sebutan yang lancar terutamanya dicirikan oleh keupayaan untuk menghasilkan pertuturan dengan mudah dan normal tanpa banyak fenomena abnormal seperti jeda, teragak-agak atau pembetulan diri semasa bercakap. Kebanyakan pelajar bahasa kedua biasanya bercakap lebih perlahan dan menjeda lebih kerap daripada penutur asli. Untuk menilai kefasihan pertuturan, pasukan Volcano Speech mencadangkan kaedah pemodelan yang diselia sendiri berdasarkan pertuturan dan prosodi
Secara khususnya, dalam peringkat pra-latihan, ciri urutan input (akustik) model perlu ciri, id fonem, tempoh fonem) bertopeng, dan ciri bertopeng dihantar kepada model, dan pengekod berkaitan konteks digunakan untuk memulihkan id fonem dan maklumat tempoh fonem bahagian bertopeng berdasarkan maklumat masa , supaya model mempunyai kebolehan perwakilan Fonologi dan prosodik yang lebih berkuasa.
Penyelesaian ini menutup dan membina semula tiga ciri tempoh asal, fonem dan maklumat akustik dalam rangka kerja pemodelan jujukan, membolehkan mesin mempelajari secara automatik pertuturan dan perwakilan tempoh konteks, yang lebih baik digunakan untuk pemarkahan kelancaran.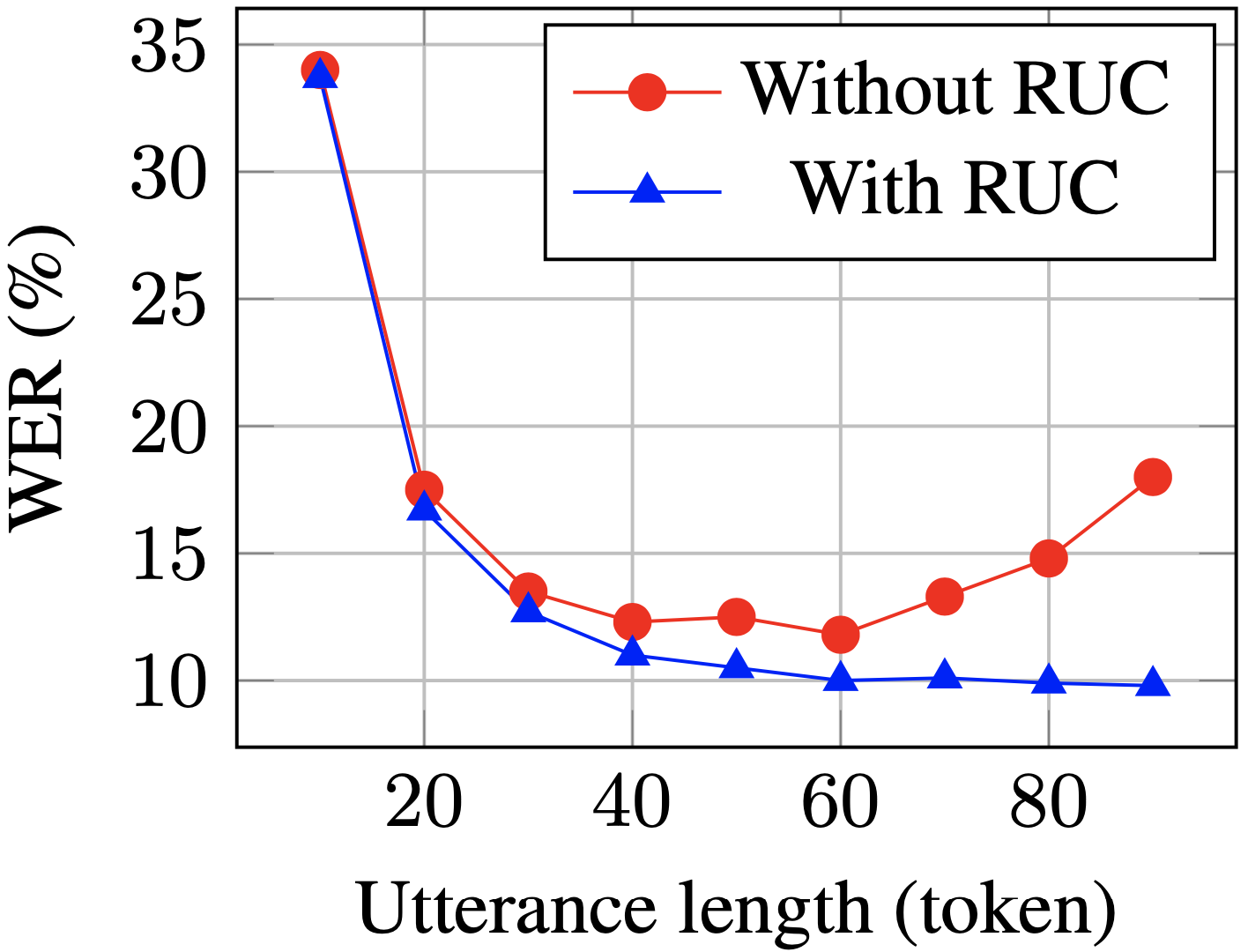
, dan korelasi antara pakar dan pakar ialah 0.831 #🎜 #Berdiri mendatar. Pada set data sumber terbuka, korelasi antara keputusan ramalan mesin dan markah pakar manusia mencapai
0.835
dan prestasi melebihi beberapa kaedah penyeliaan sendiri yang dicadangkan pada masa lalu pada tugasan ini. Dari segi senario aplikasi, kaedah ini boleh digunakan untuk senario yang memerlukan penilaian kefasihan automatik, seperti peperiksaan lisan dan pelbagai latihan lisan dalam talian.
Merungkai Sumbangan Pertuturan Bukan Asli dalam Penilaian Sebutan Automatik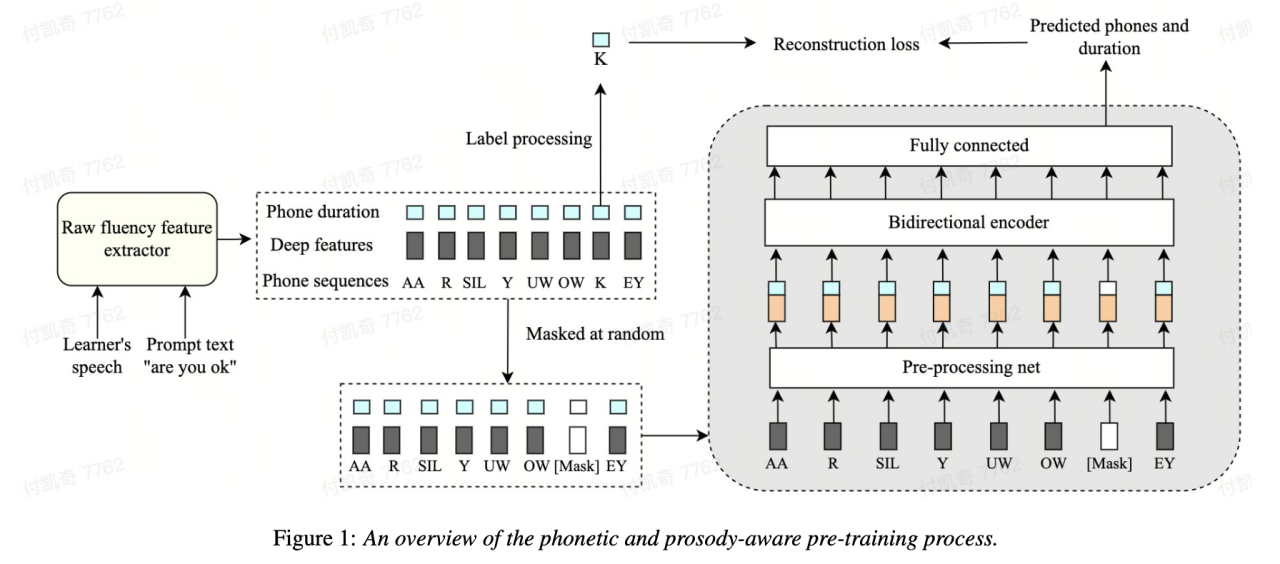
Idea asas penilaian sebutan bukan bahasa ibunda adalah untuk mengukur sisihan antara sebutan pelajar dan sebutan penutur asli Oleh itu, model akustik awal yang digunakan untuk penilaian sebutan biasanya hanya menggunakan data bahasa sasaran untuk latihan, tetapi beberapa yang terkini kajian telah mula menggunakan Data pertuturan bukan asli dimasukkan ke dalam latihan model. Terdapat perbezaan asas antara tujuan memasukkan pertuturan bukan asli ke dalam L2 ASR dan penilaian bukan asli atau pengesanan ralat sebutan: matlamat yang pertama adalah untuk menyesuaikan model kepada data bukan asli sebanyak mungkin untuk mencapai ASR yang optimum prestasi; yang kedua memerlukan mengimbangi dua perspektif Terdapat keperluan yang kelihatan bercanggah, iaitu, ketepatan pengiktirafan yang lebih tinggi bagi pertuturan bukan asli dan penilaian objektif bagi peringkat sebutan bukan asli.
Pasukan Volcano Speech bertujuan untuk mengkaji sumbangan pertuturan bukan natif dalam penilaian sebutan dari dua perspektif berbeza iaitu ketepatan penjajaran dan prestasi penilaian. Untuk tujuan ini, mereka mereka bentuk kombinasi data dan bentuk transkripsi teks yang berbeza semasa melatih model akustik, seperti yang ditunjukkan dalam rajah di atas 🎜#
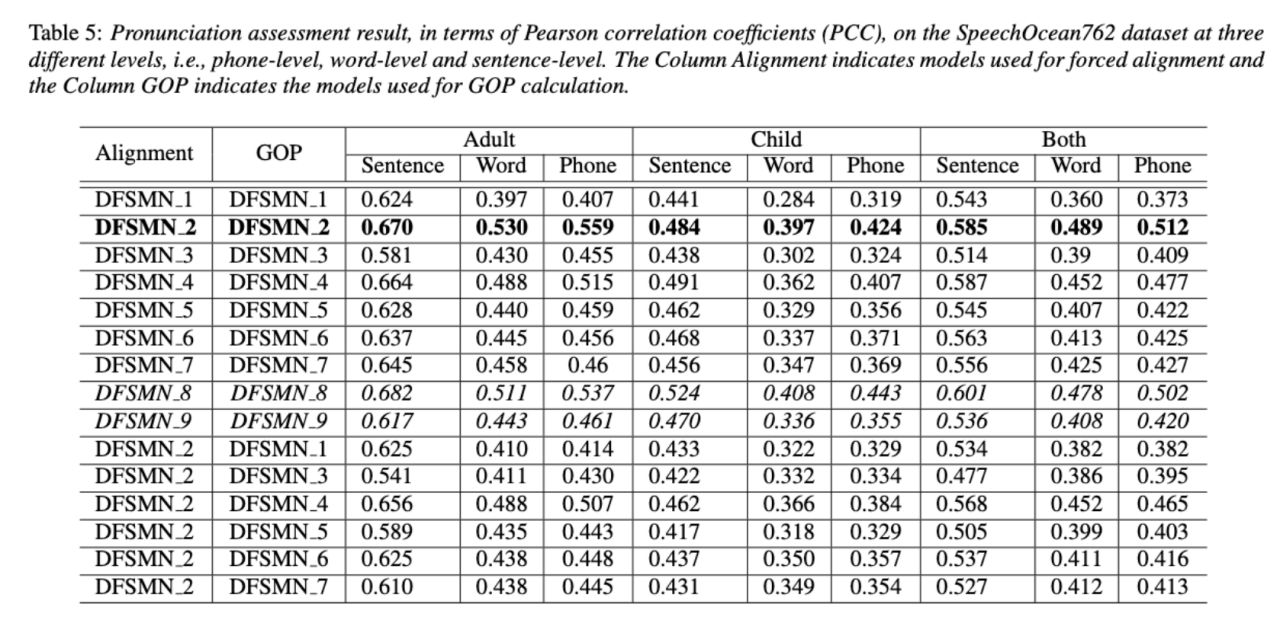
Dua jadual di atas masing-masing menunjukkan prestasi gabungan berbeza model akustik dalam ketepatan penjajaran dan penilaian . Keputusan eksperimen menunjukkan bahawa hanya menggunakan data bukan bahasa ibunda dengan urutan fonem beranotasi secara manual semasa latihan model akustik mencapai ketepatan tertinggi dalam penjajaran penilaian pertuturan dan sebutan bukan asli. Khususnya, mencampurkan separuh data bahasa ibunda dan separuh data bukan asli (urutan fonem beranotasi manusia) dalam latihan mungkin lebih teruk sedikit, tetapi setanding dengan menggunakan hanya data bukan asli dengan urutan fonem beranotasi manusia.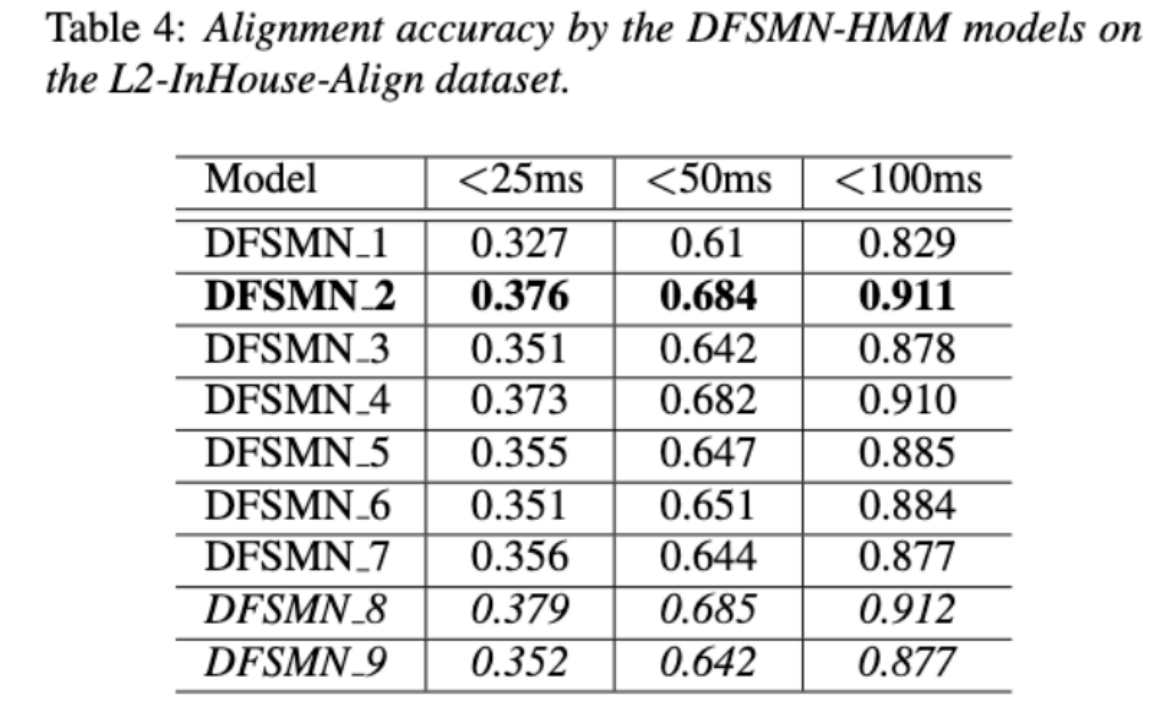 Tambahan pula, kes bercampur di atas berprestasi lebih baik apabila menilai sebutan pada data bahasa ibunda. Dengan sumber yang terhad, menambah 10 jam data bukan bahasa ibunda telah meningkatkan ketepatan penjajaran dan prestasi penilaian dengan ketara tanpa mengira jenis transkripsi teks yang digunakan berbanding latihan model akustik hanya menggunakan data bahasa ibunda. Penyelidikan ini mempunyai kepentingan panduan yang penting untuk aplikasi data dalam bidang penilaian pertuturan
Tambahan pula, kes bercampur di atas berprestasi lebih baik apabila menilai sebutan pada data bahasa ibunda. Dengan sumber yang terhad, menambah 10 jam data bukan bahasa ibunda telah meningkatkan ketepatan penjajaran dan prestasi penilaian dengan ketara tanpa mengira jenis transkripsi teks yang digunakan berbanding latihan model akustik hanya menggunakan data bahasa ibunda. Penyelidikan ini mempunyai kepentingan panduan yang penting untuk aplikasi data dalam bidang penilaian pertuturan
#🎜 🎜#  Sistem hujung ke hujung dalam bidang pengecaman pertuturan automatik (ASR) telah menunjukkan prestasi yang setanding dengan sistem hibrid. Sebagai hasil sampingan ASR, cap masa adalah penting dalam banyak aplikasi, terutamanya dalam senario seperti penjanaan sari kata dan latihan sebutan berbantukan pengiraan Kertas ini bertujuan untuk mengoptimumkan pengelas peringkat bingkai dalam sistem hujung ke hujung untuk mendapatkan cap masa. . Dalam hal ini, pasukan memperkenalkan penggunaan kehilangan CTC (pengelasan temporal penyambung) untuk melatih pengelas peringkat bingkai, dan memperkenalkan maklumat terdahulu label untuk mengurangkan fenomena lonjakan CTC Ia juga menggabungkan output penapis Mel dengan ASR pengekod sebagai ciri input.
Sistem hujung ke hujung dalam bidang pengecaman pertuturan automatik (ASR) telah menunjukkan prestasi yang setanding dengan sistem hibrid. Sebagai hasil sampingan ASR, cap masa adalah penting dalam banyak aplikasi, terutamanya dalam senario seperti penjanaan sari kata dan latihan sebutan berbantukan pengiraan Kertas ini bertujuan untuk mengoptimumkan pengelas peringkat bingkai dalam sistem hujung ke hujung untuk mendapatkan cap masa. . Dalam hal ini, pasukan memperkenalkan penggunaan kehilangan CTC (pengelasan temporal penyambung) untuk melatih pengelas peringkat bingkai, dan memperkenalkan maklumat terdahulu label untuk mengurangkan fenomena lonjakan CTC Ia juga menggabungkan output penapis Mel dengan ASR pengekod sebagai ciri input.
Dalam eksperimen dalaman Cina, kaedah ini mencapai ketepatan 95.68%/94.18% dalam cap waktu perkataan 200ms, manakala sistem hibrid tradisional hanya mencapai 93.0%/90.22%. Di samping itu, berbanding pendekatan hujung ke hujung sebelumnya, pasukan itu mencapai peningkatan prestasi mutlak sebanyak 4.80%/8.02% pada 7 bahasa dalaman. Ketepatan pemasaan perkataan juga dipertingkatkan lagi melalui pendekatan penyulingan pengetahuan bingkai demi bingkai, walaupun eksperimen ini hanya dijalankan untuk LibriSpeech.
Hasil kajian ini menunjukkan bahawa prestasi cap masa dalam sistem pengecaman pertuturan hujung-ke-hujung boleh dioptimumkan dengan berkesan dengan memperkenalkan prior label dan menggabungkan tahap ciri yang berbeza. Dalam eksperimen Cina dalaman, kaedah ini telah mencapai peningkatan yang ketara berbanding dengan sistem hibrid dan kaedah akhir-ke-hujung di samping itu, kaedah ini juga menunjukkan kelebihan yang jelas untuk pelbagai bahasa melalui penggunaan kaedah penyulingan pengetahuan, ia telah dipertingkatkan lagi; ketepatan masa. Keputusan ini bukan sahaja sangat penting untuk aplikasi seperti penjanaan sari kata dan latihan sebutan, tetapi juga menyediakan arah penerokaan yang berguna untuk pembangunan teknologi pengecaman pertuturan automatik.
Pengecaman pertuturan campuran Bahasa Cina-Bahasa Inggeris berdasarkan pembelajaran sempadan akustik khusus bahasa (Pembelajaran Sempadan Akustik Khusus Bahasa untuk Pengecaman Semula Kod Bahasa Inggeris Pertuturan Mandarin #🎜 🎜#)Kandungan yang ditulis semula: Seperti yang kita sedia maklum, matlamat utama penukaran kod (CS) adalah untuk menggalakkan komunikasi yang berkesan antara bahasa atau teknikal yang berbeza padang. CS memerlukan penggunaan dua atau lebih bahasa secara berselang-seli dalam ayat Walau bagaimanapun, penggabungan perkataan atau frasa daripada pelbagai bahasa boleh menyebabkan ralat dan kekeliruan dalam pengecaman pertuturan, yang menjadikan pengecaman pertuturan bertukar kod (CSSR) lebih Mencabar. misi
Model ASR hujung ke hujung biasa terdiri daripada pengekod, penyahkod dan mekanisme penjajaran. Kebanyakan model CSASR hujung ke hujung sedia ada hanya menumpukan pada mengoptimumkan struktur pengekod dan penyahkod, dan jarang membincangkan sama ada reka bentuk berkaitan bahasa bagi mekanisme penjajaran diperlukan. Kebanyakan karya sedia ada menggunakan campuran aksara Mandarin dan subkata Inggeris sebagai unit pemodelan untuk senario campuran Cina dan Inggeris. Aksara Mandarin biasanya mewakili suku kata tunggal dalam bahasa Mandarin dan mempunyai sempadan akustik yang jelas manakala subkata bahasa Inggeris diperoleh tanpa merujuk kepada sebarang pengetahuan akustik, jadi sempadan akustiknya mungkin kabur. Bagi mendapatkan sempadan akustik (penjajaran) yang baik antara bahasa Mandarin dan Inggeris dalam sistem CSASR, pembelajaran sempadan akustik berkaitan bahasa amat diperlukan. Oleh itu, kami menambah baik model CIF dan mencadangkan kaedah pembelajaran sempadan akustik yang dibezakan bahasa untuk tugas CSASR. Sila lihat rajah di bawah untuk butiran seni bina model
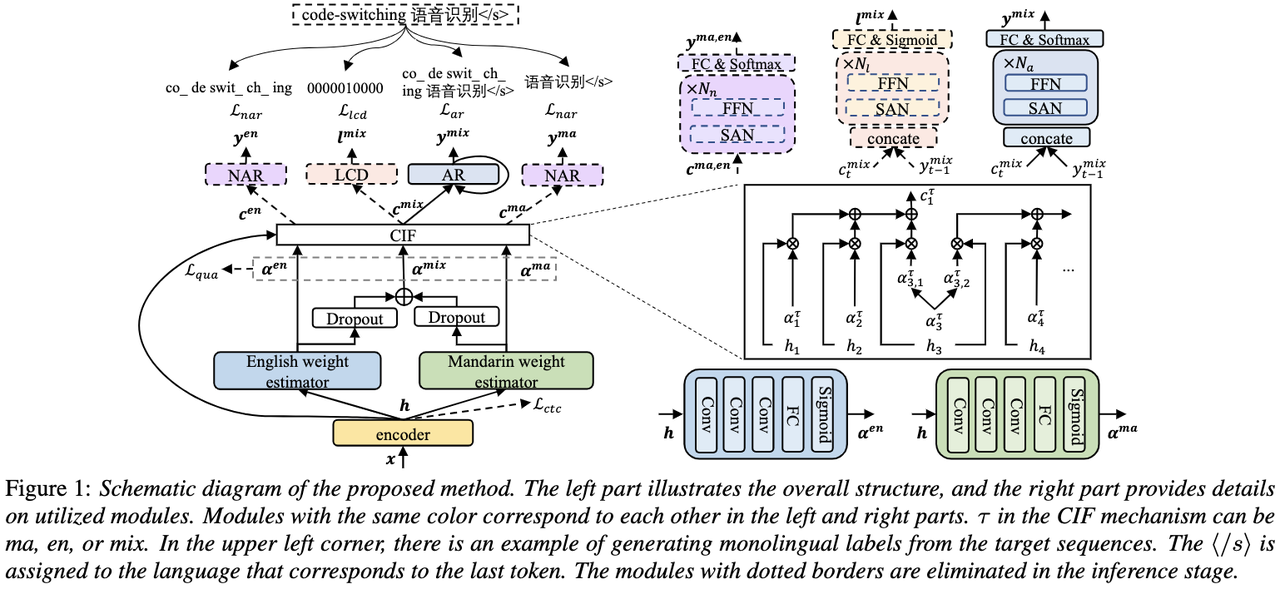
Model ini terdiri daripada enam komponen, iaitu pengekod, penganggar berat dibezakan bahasa (LSWE), modul CIF, penyahkod autoregresif (AR), Regresi bukan automatik ( penyahkod NAR) dan modul Pengesanan Perubahan Bahasa (LCD). Proses pengiraan pengekod, penyahkod autoregresif dan CIF adalah sama dengan kaedah ASR berasaskan CIF yang asal Penganggar berat khusus bahasa bertanggungjawab untuk melengkapkan pemodelan sempadan akustik bebas bahasa Penyahkod bukan autoregresif (NAR). dan Modul Pengesanan Perubahan Bahasa (LCD) direka untuk membantu latihan model dan tidak lagi dikekalkan dalam peringkat penyahkodan Keputusan eksperimen menunjukkan bahawa kaedah ini telah mencapai keputusan baharu pada dua set ujian
dan sumber terbuka Cina-Inggeris. set data bercampur SEAME Kesan SOTA masing-masing ialah 16.29% dan 22.81% MER. Untuk mengesahkan lagi kesan kaedah ini pada volum data yang lebih besar, pasukan menjalankan eksperimen pada set data dalaman selama 9,000 jam, dan akhirnya mencapai keuntungan MER relatif sebanyak 7.9%. Difahamkan bahawa kertas kerja ini juga merupakan karya pertama mengenai pembelajaran sempadan akustik untuk pembezaan bahasa dalam tugasan CSASR. 

: ASR berdasarkan perwakilan bersatu dan teks biasa Penyesuaian Domain (Penyesuaian Domain Teks sahaja menggunakan Perwakilan Teks Pertuturan Disatukan dalam Transduser) kita semua penghijrahan sentiasa Ia adalah tugas yang sangat penting dalam ASR, tetapi mendapatkan data pertuturan berpasangan dalam domain sasaran adalah sangat memakan masa dan kos Oleh itu, banyak kerja menggunakan data teks yang berkaitan dengan domain sasaran untuk meningkatkan kesan pengecaman. Antara kaedah tradisional, TTS akan meningkatkan kitaran latihan dan kos penyimpanan data berkaitan, manakala kaedah seperti ILME dan gabungan Cetek akan meningkatkan kerumitan inferens. Berdasarkan tugasan ini, pasukan memisahkan Pengekod kepada Pengekod Audio dan Pengekod Dikongsi berdasarkan RNN-T, dan memperkenalkan Pengekod Teks untuk mempelajari perwakilan yang serupa dengan isyarat pertuturan adalah melalui Pengekod Dikongsi. Kehilangan T untuk latihan dipanggil USTR (Unified Speech-Teks Representation). "Untuk bahagian Pengekod Teks, kami meneroka jenis bentuk perwakilan yang berbeza, termasuk Jujukan Aksara, Jujukan Telefon dan jujukan Sub-perkataan. Keputusan akhir menunjukkan bahawa jujukan Telefon mempunyai kesan terbaik. Bagi kaedah latihan, artikel ini meneroka kaedah berdasarkan RNN- Kaedah latihan berbilang langkah model T dan kaedah latihan Satu langkah dengan permulaan rawak sepenuhnya "
Secara khusus, pasukan menggunakan set data LibriSpeech sebagai domain Sumber dan menggunakan teks beranotasi. daripada SPGISpeech sebagai teks biasa untuk percubaan domain. Keputusan eksperimen menunjukkan bahawa kesan kaedah ini dalam bidang sasaran pada asasnya boleh sama seperti TTS kesan latihan Satu langkah adalah lebih tinggi, dan kesannya pada asasnya sama dengan Multi-step; Kaedah USTR boleh meningkatkan lagi prestasi model bahasa pemalam seperti ILME Combined, walaupun LM menggunakan korpus latihan teks yang sama. Akhirnya, pada set ujian domain sasaran, tanpa menggabungkan model bahasa luaran, kaedah ini mencapai penurunan relatif sebanyak 43.7% berbanding WER garis dasar sebanyak 23.55% -> 13.25%.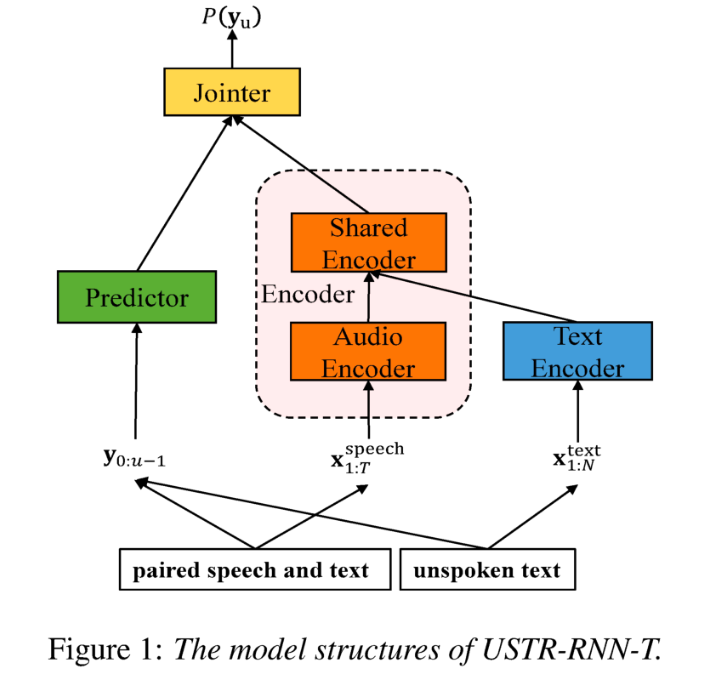
Kaedah anggaran model bahasa dalaman yang cekap berdasarkan penyulingan pengetahuan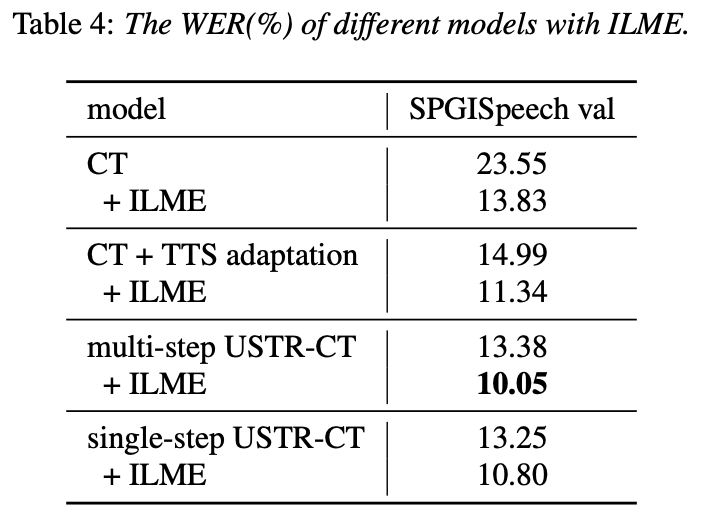
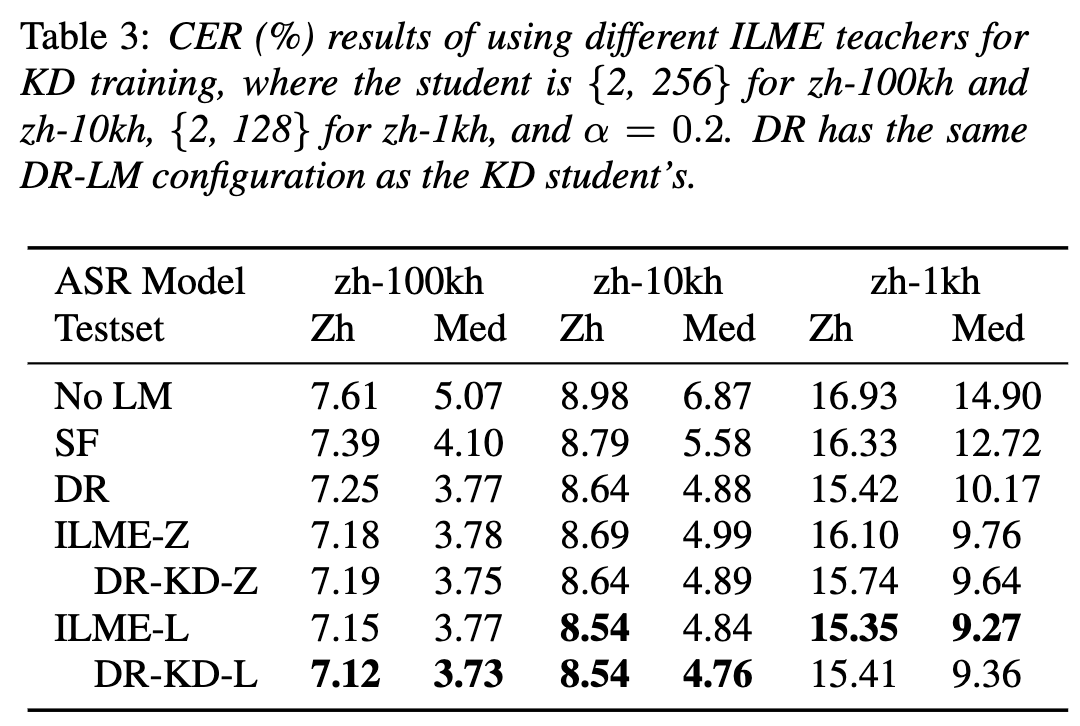
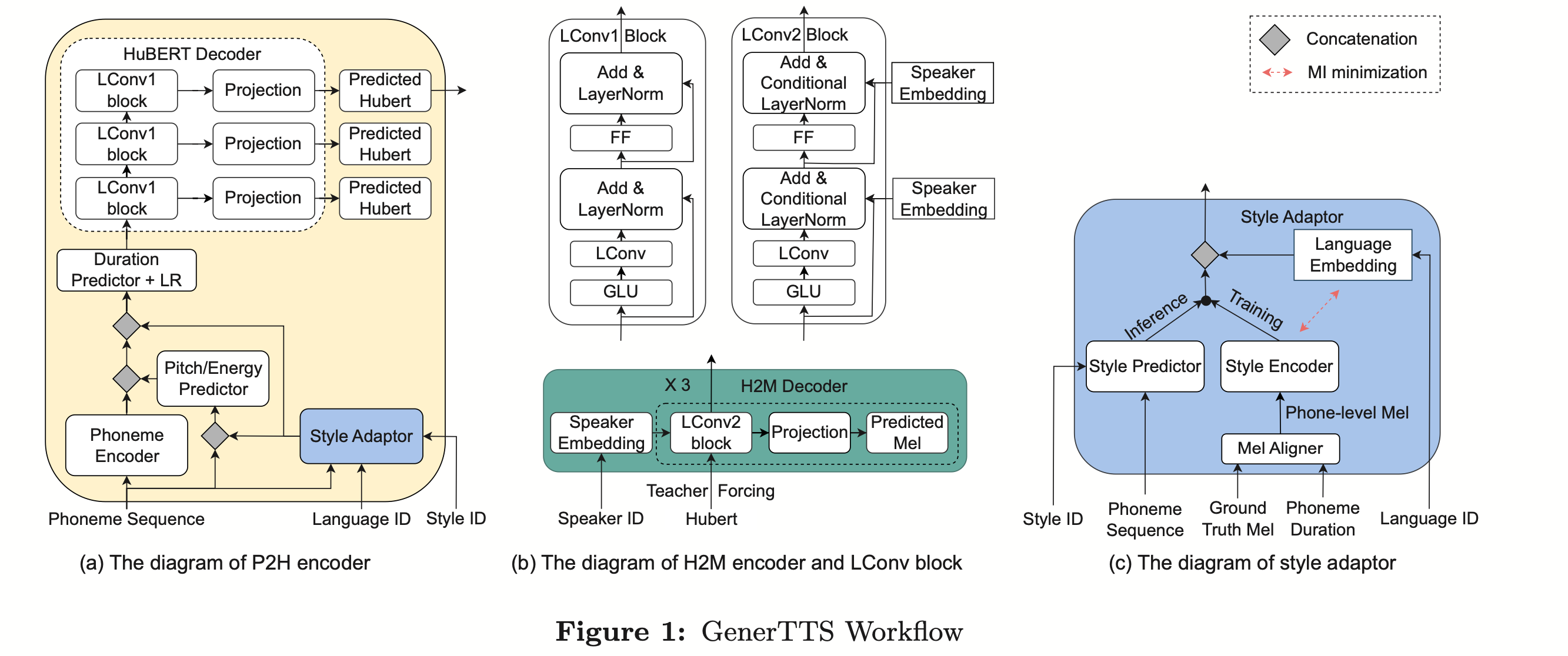
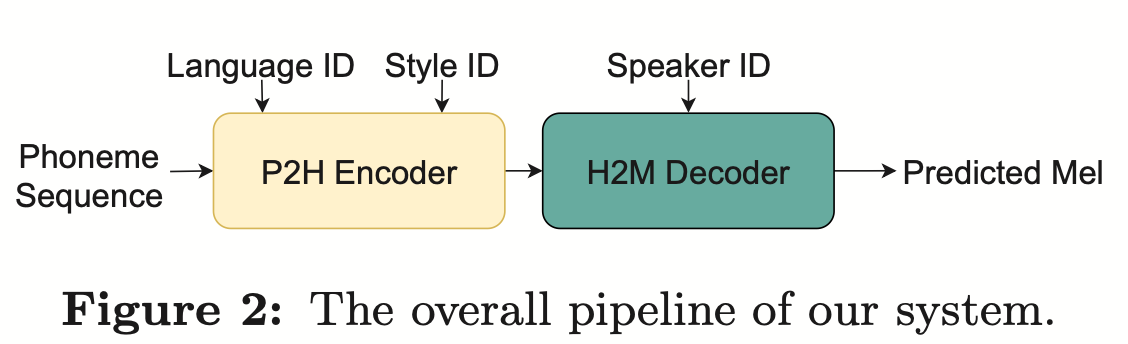
Walaupun Anggaran Model Bahasa Dalaman (ILME) telah membuktikan keberkesanannya dalam gabungan model bahasa ASR hujung ke hujung, berbanding dengan gabungan Shallow tradisional, ILME juga memperkenalkan pengiraan model bahasa dalaman, meningkatkan kos inferens. Untuk menganggar model bahasa dalaman, pengiraan hadapan tambahan diperlukan berdasarkan penyahkod ASR, atau berdasarkan kaedah Nisbah Ketumpatan, model bahasa bebas (DR-LM) dilatih menggunakan teks set latihan ASR sebagai bahasa dalaman Pengiraan model. Kaedah ILME berdasarkan penyahkod ASR biasanya boleh mencapai prestasi yang lebih baik daripada kaedah nisbah ketumpatan kerana ia secara langsung menggunakan parameter ASR untuk anggaran, tetapi jumlah pengiraannya bergantung pada jumlah parameter penyahkod ASR kelebihan kaedah nisbah ketumpatan; bahawa ia boleh dikawal oleh Saiz DR-LM membolehkan anggaran model bahasa dalaman yang cekap. Atas sebab ini, pasukan Volcano Voice mencadangkan untuk menggunakan kaedah ILME berdasarkan penyahkod ASR sebagai guru di bawah rangka kerja kaedah nisbah ketumpatan untuk menyuling dan mempelajari DR-LM, dengan itu mengurangkan dengan ketara kos pengiraan ILME sambil mengekalkan prestasi ILME. Hasil eksperimen menunjukkan kaedah ini boleh mengurangkan parameter model bahasa dalaman sebanyak 95% dan setanding prestasinya dengan kaedah ILME berdasarkan penyahkod ASR. Apabila kaedah ILME dengan prestasi yang lebih baik digunakan sebagai guru, model pelajar yang sepadan juga boleh mencapai hasil yang lebih baik. Berbanding dengan kaedah nisbah ketumpatan tradisional dengan jumlah pengiraan yang sama, kaedah ini mempunyai prestasi yang lebih baik sedikit dalam senario sumber tinggi Dalam senario migrasi merentas domain sumber rendah, keuntungan CER boleh mencapai 8%, dan ia lebih teguh kepada. fusion weights GenerTTS: Penyebutan Sebutan untuk Timbre dan Generalisasi Gaya dalam Teks-ke-Pertuturan Merentas Bahasa Timbre merentas bahasa dan gaya sintesis pertuturan yang boleh digeneralisasikan dengan rujukan sintesis pertuturan TS (TS yang boleh digeneralisasikan) atau gaya yang belum dilatih dalam bahasa sasaran. Ia menghadapi cabaran seperti kesukaran untuk memisahkan timbre dan sebutan kerana selalunya sukar untuk mendapatkan data pertuturan berbilang bahasa untuk gaya penutur tertentu dan sebutan bercampur-campur kerana gaya pertuturan mengandungi kedua-dua bahagian yang bebas bahasa dan bergantung kepada bahasa. Untuk menangani cabaran ini, pasukan Volcano Voice mencadangkan GenerTTS. Mereka dengan teliti mereka bentuk kesesakan maklumat berasaskan HuBERT untuk memisahkan hubungan antara timbre dan sebutan/gaya. Pada masa yang sama, mereka juga menghapuskan maklumat khusus bahasa dalam gaya dengan meminimumkan maklumat bersama antara gaya dan bahasa 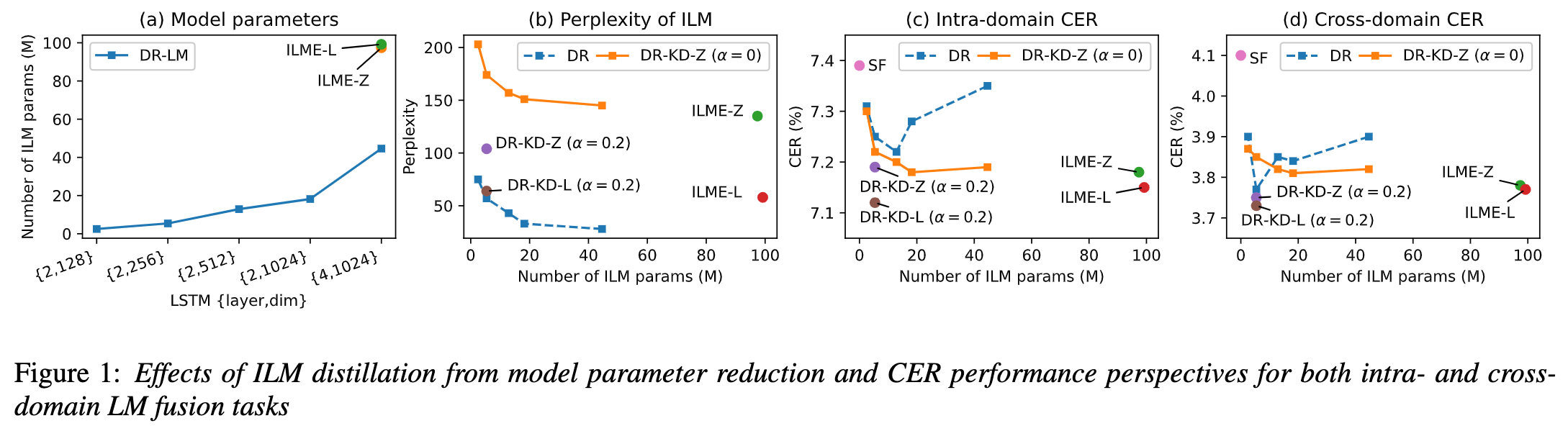
 Pasukan Volcano Voice sentiasa menyediakan keupayaan teknologi AI suara berkualiti tinggi dan penyelesaian produk suara tindanan penuh kepada barisan perniagaan dalaman ByteDance, dan menyediakan perkhidmatan luaran melalui enjin Volcano. Sejak penubuhannya pada 2017, pasukan itu telah menumpukan pada penyelidikan dan pembangunan teknologi suara pintar AI yang menerajui industri, dan sentiasa meneroka gabungan cekap AI dan senario perniagaan untuk mencapai nilai pengguna yang lebih besar.
Pasukan Volcano Voice sentiasa menyediakan keupayaan teknologi AI suara berkualiti tinggi dan penyelesaian produk suara tindanan penuh kepada barisan perniagaan dalaman ByteDance, dan menyediakan perkhidmatan luaran melalui enjin Volcano. Sejak penubuhannya pada 2017, pasukan itu telah menumpukan pada penyelidikan dan pembangunan teknologi suara pintar AI yang menerajui industri, dan sentiasa meneroka gabungan cekap AI dan senario perniagaan untuk mencapai nilai pengguna yang lebih besar.
Atas ialah kandungan terperinci Beberapa kertas kerja telah dipilih untuk Interspeech 2023, dan Huoshan Speech menyelesaikan banyak jenis masalah praktikal dengan berkesan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!