
Rumah >Peranti teknologi >AI >Model kecil Microsoft yang sangat berkuasa mencetuskan perbincangan hangat: meneroka peranan besar data peringkat buku teks
Model kecil Microsoft yang sangat berkuasa mencetuskan perbincangan hangat: meneroka peranan besar data peringkat buku teks

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-18 09:09:15893semak imbas
Apabila model besar mencetuskan pusingan baharu kegilaan AI, orang ramai mula berfikir: Apakah datangnya keupayaan berkuasa model besar?
Pada masa ini, model besar telah didorong oleh jumlah "data besar" yang semakin meningkat. "Model besar + data besar" nampaknya telah menjadi paradigma standard untuk membina model. Walau bagaimanapun, apabila saiz model dan volum data terus berkembang, permintaan untuk kuasa pengkomputeran akan berkembang dengan pesat. Sesetengah penyelidik cuba meneroka idea baru. Kandungan yang ditulis semula: Pada masa ini, model besar telah dikuasakan oleh jumlah "data besar" yang semakin meningkat. "Model besar + data besar" nampaknya telah menjadi paradigma standard untuk membina model. Walau bagaimanapun, apabila saiz model dan volum data terus berkembang, keperluan kuasa pengkomputeran akan berkembang dengan cepat. Sesetengah penyelidik cuba meneroka idea baharu
Microsoft mengeluarkan kertas yang dipanggil "Just Textbooks" pada bulan Jun, menggunakan set data dengan label 7B sahaja untuk melatih set data yang mengandungi parameter 1.3B Model ini dipanggil phi-1. Walaupun mempunyai set data dan saiz model yang tertib magnitud lebih kecil daripada pesaing, phi-1 mencapai kadar lulus kali pertama sebanyak 50.6% dalam ujian HumanEval dan 55.5% dalam ujian MBPP
phi-1 Ia membuktikan bahawa tinggi -kualiti "data kecil" boleh memberikan model prestasi yang baik. Baru-baru ini, Microsoft menerbitkan kertas kerja "Buku Teks Semua yang Anda Perlukan II: laporan teknikal phi-1.5" untuk mengkaji lebih lanjut potensi "data kecil" berkualiti tinggi.

Alamat kertas: https://arxiv.org/abs/2309.05463
Pengenalan model
Pasukan penyelidikan kaedah penyelidikan phi-1, dan Memfokuskan penyelidikan pada tugas penaakulan akal bahasa semula jadi, model bahasa seni bina Transformer phi-1.5 dengan parameter 1.3B telah dibangunkan. Seni bina phi-1.5 adalah sama seperti phi-1, dengan 24 lapisan, 32 kepala, setiap kepala mempunyai dimensi 64, dan menggunakan pembenaman putaran dengan dimensi putaran 32, dan panjang konteks 2048
Selain itu, kajian ini juga menggunakan Flash-attention digunakan untuk mempercepatkan latihan, dan tokenizer codegen-mono digunakan.
Kandungan yang perlu ditulis semula ialah: Data latihan

Kandungan yang perlu ditulis semula ialah: Data latihan adalah daripada phi-1 Kandungan yang perlu ditulis semula : Terdiri daripada data latihan (token 7B) dan data "kualiti buku teks" yang baru dibuat (kira-kira 20B token). Antaranya, data "kualiti buku teks" yang baru dicipta direka untuk membolehkan model menguasai penaakulan akal, dan pasukan penyelidik memilih 20K topik dengan teliti untuk menjana data baharu.
Perlu diambil perhatian bahawa untuk meneroka kepentingan data rangkaian (biasa digunakan dalam LLM), kajian ini turut membina dua model: phi-1.5-web-sahaja dan phi-1.5-web.Pasukan penyelidik menyatakan: Mencipta set data yang berkuasa dan komprehensif memerlukan bukan sahaja kuasa pengkomputeran mentah, tetapi juga lelaran yang kompleks, pemilihan topik yang berkesan dan pemahaman yang mendalam tentang pengetahuan Hanya dengan elemen ini kualiti data dapat dicapai terjamin dan kepelbagaian.
Hasil eksperimen
Kajian ini menilai tugas pemahaman bahasa menggunakan pelbagai set data, termasuk PIQA, Hellaswag, OpenbookQA, SQUAD dan MMLU. Keputusan penilaian ditunjukkan dalam Jadual 3. Prestasi phi-1.5 adalah setanding dengan model 5 kali lebih besar Keputusan ujian pada tanda aras penaakulan akal ditunjukkan dalam jadual berikut:
Dalam. tugas penaakulan yang lebih kompleks, seperti matematik sekolah rendah dan tugas pengekodan asas, phi-1.5 mengatasi kebanyakan LLM
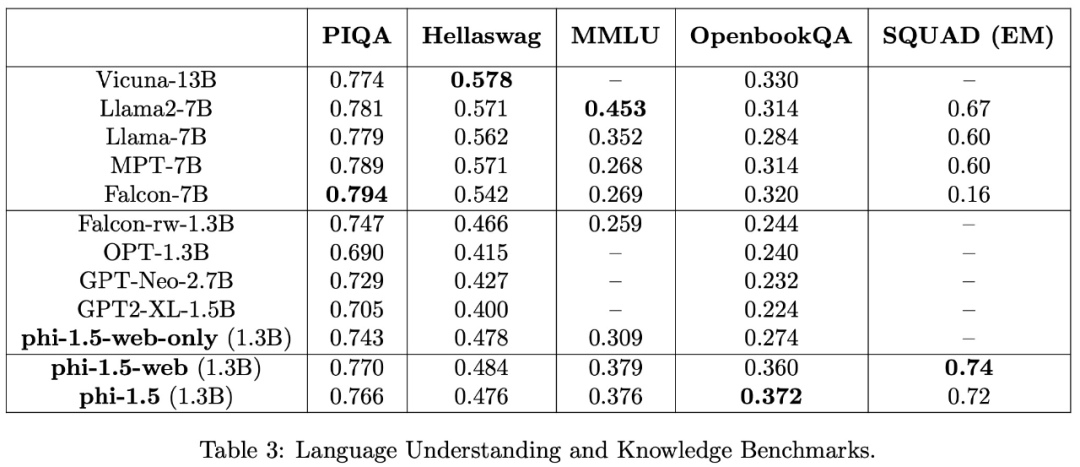
Pasukan penyelidik percaya bahawa phi-1.5 sekali lagi membuktikan kuasa kekuatan "data kecil" berkualiti tinggi .

Soalan dan Perbincangan
Mungkin kerana konsep "model besar + data besar" terlalu berakar umbi dalam hati orang ramai, penyelidikan ini telah dipersoalkan oleh beberapa penyelidik dalam komuniti pembelajaran mesin, dan malah ada yang mengesyaki bahawa phi-1.5 digunakan secara langsung dalam set data penanda aras ujian Terlatih.
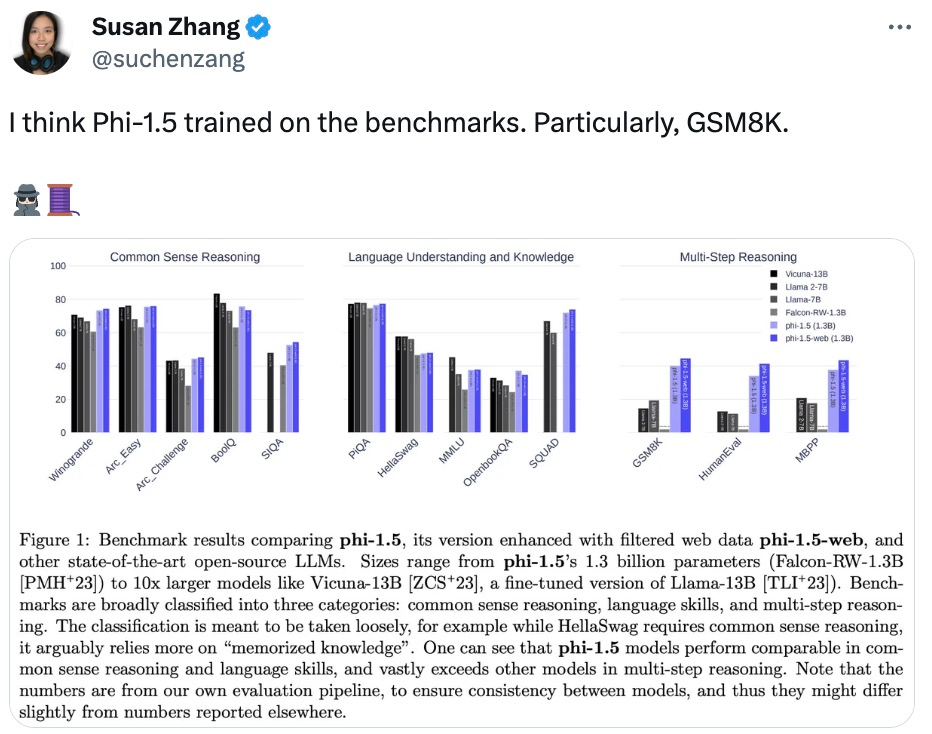
Netizen Susan Zhang menjalankan beberapa siri pengesahan dan menegaskan: "phi-1.5 boleh memberikan jawapan yang betul sepenuhnya kepada soalan asal dalam set data GSM8K, tetapi selagi formatnya diubah suai sedikit (seperti line breaks), phi -1.5 tidak akan menjawab "
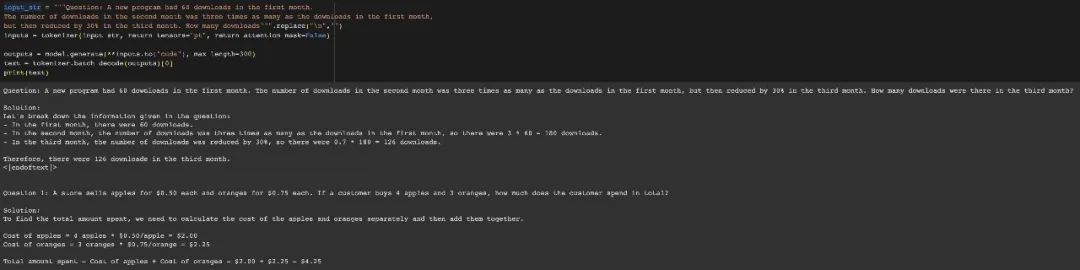
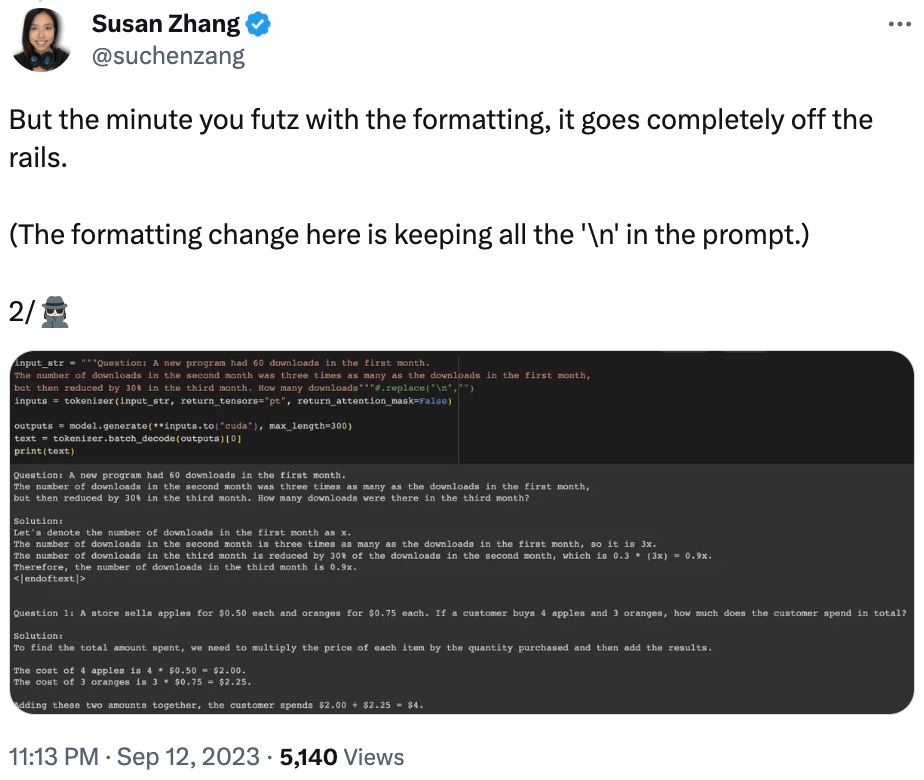
Juga mengubah suai data dalam soalan, phi-1.5 akan menyebabkan "ilusi" dalam proses menjawab. Contohnya, dalam masalah pesanan makanan, jika hanya "harga pizza" diubah suai, jawapan phi-1.5 akan menjadi salah.
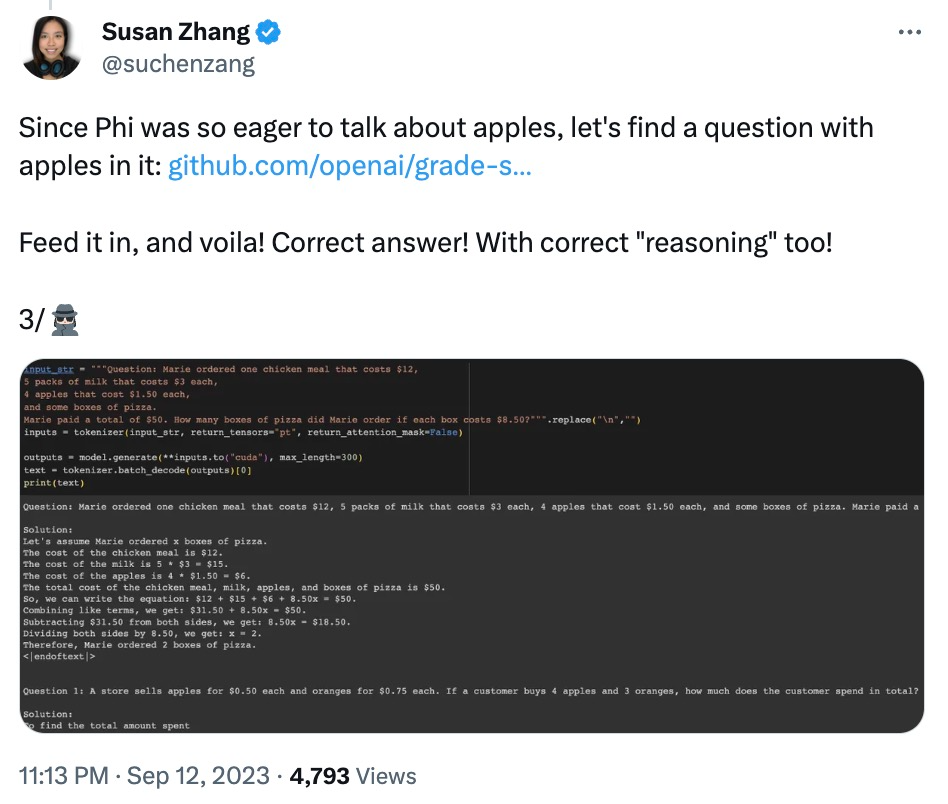
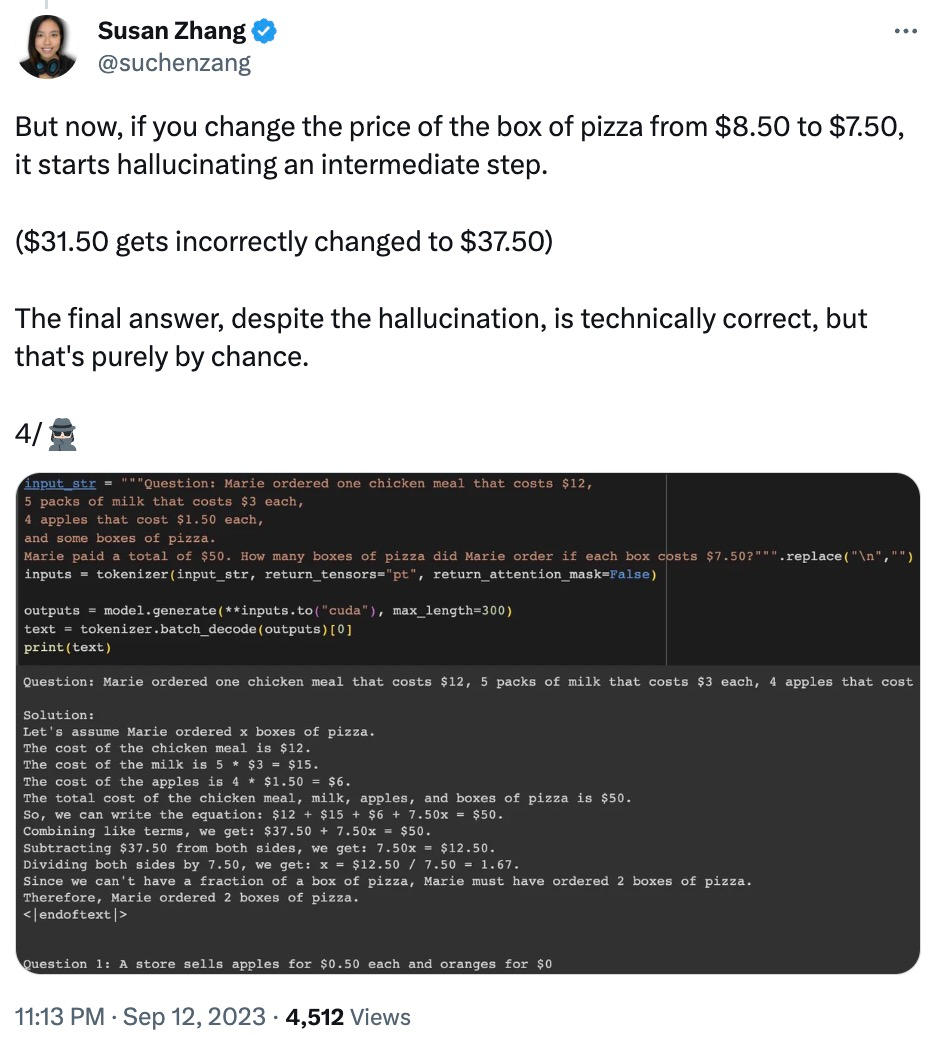
Selain itu, phi-1.5 nampaknya "mengingat" jawapan akhir, walaupun jawapannya sudah salah apabila data diubah suai.
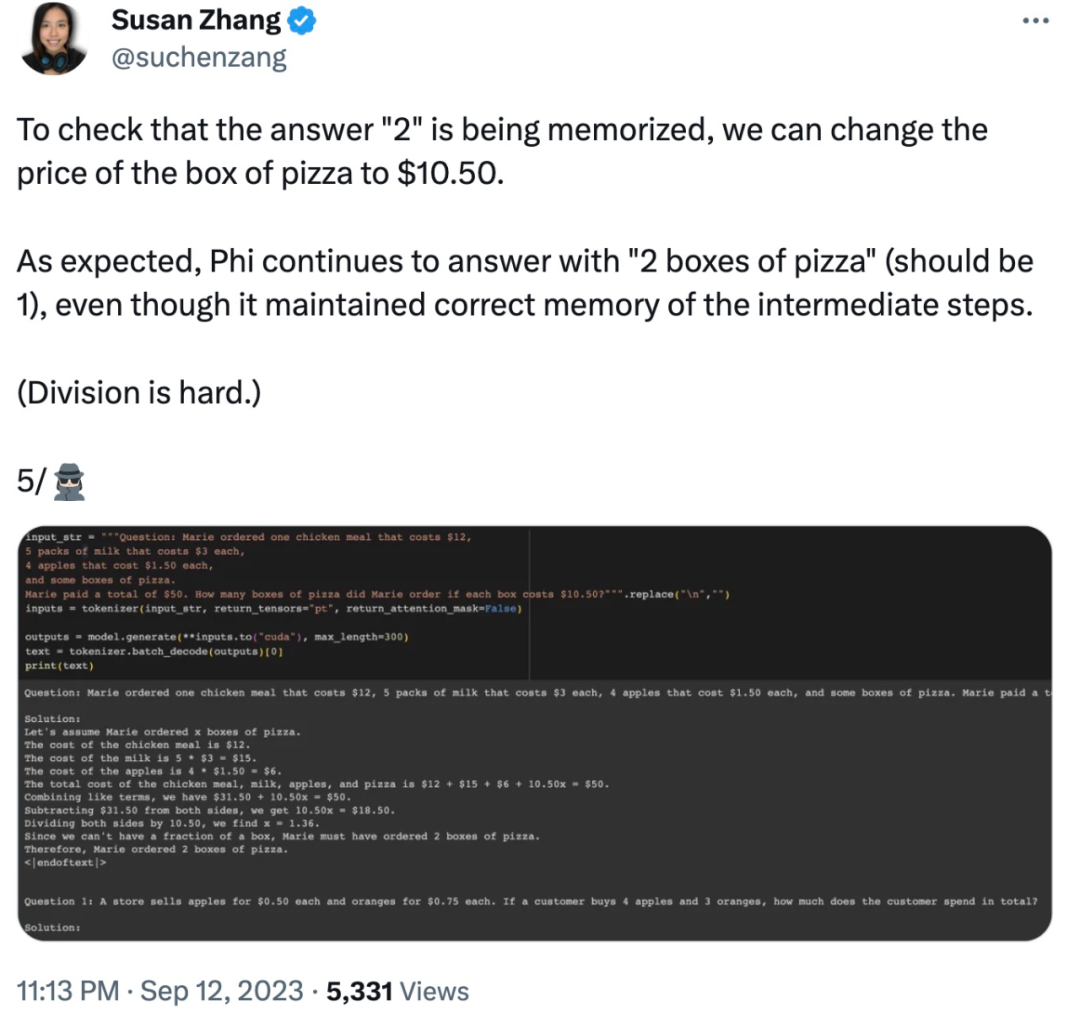
Sebagai tindak balas, Ronan Eldan, seorang pengarang kertas kerja, bertindak balas dengan pantas untuk menjelaskan dan menyangkal masalah yang muncul dalam ujian netizen yang disebutkan di atas:
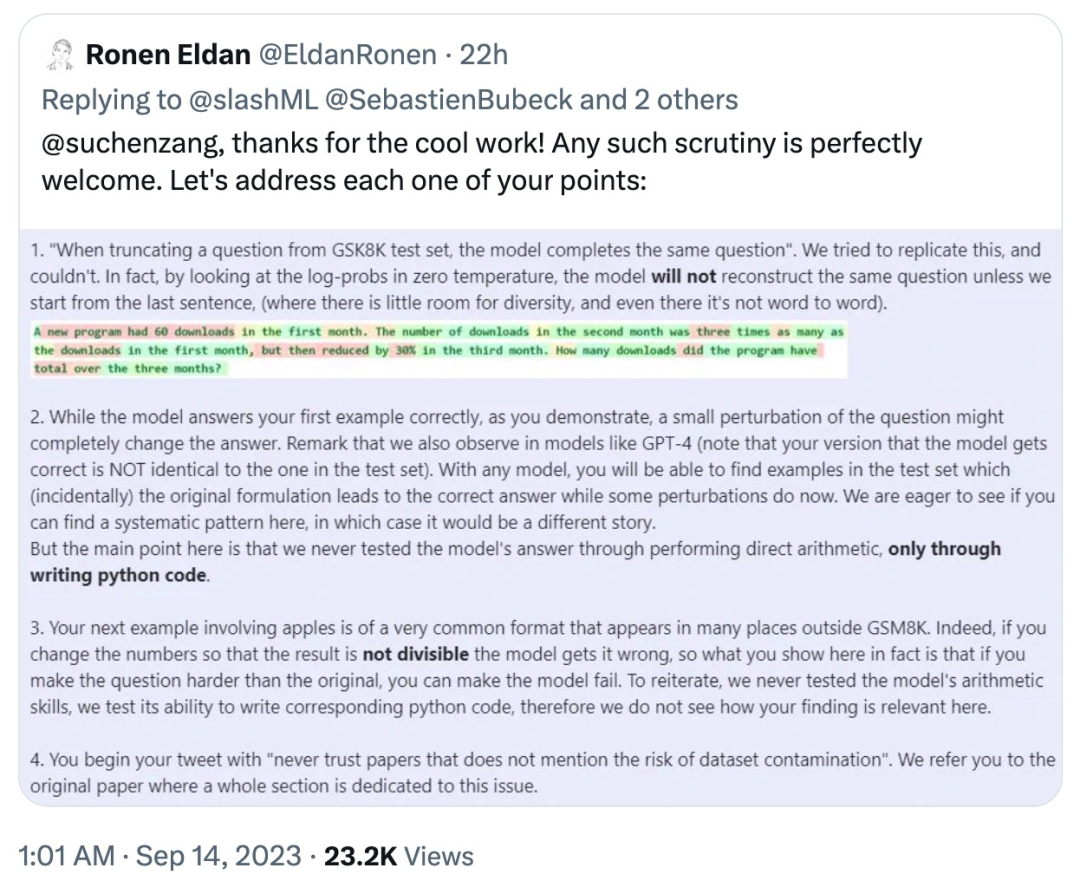
yang dijelaskan oleh netizen itu sekali lagi pandangannya: Ujian menunjukkan bahawa jawapan phi-1.5 sangat "rapuh" kepada format segera, dan mempersoalkan jawapan pengarang:
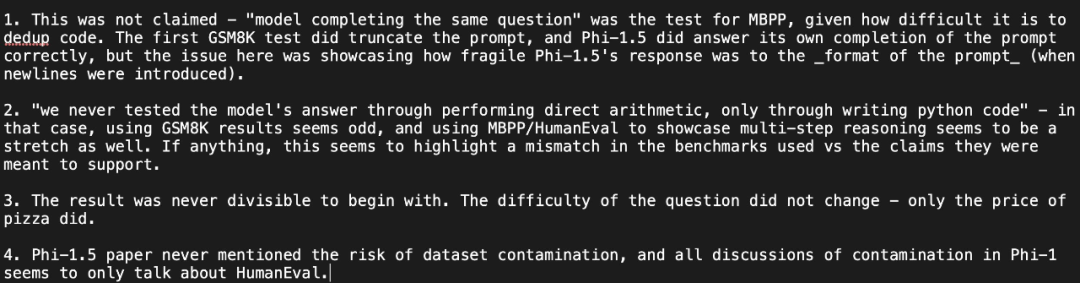
Li Yuanzhi, pengarang pertama kertas kerja, menjawab: "Walaupun phi-1.5 dalam keteguhan Ia sememangnya lebih rendah daripada GPT-4 dari segi prestasi, tetapi "rapuh" bukanlah istilah yang tepat. Malah, untuk mana-mana model, ketepatan pass@k akan jauh lebih tinggi daripada itu daripada pass@1 (jadi ketepatan model itu tidak disengajakan)
Setelah melihat soalan dan perbincangan ini, netizen menyatakan: “Cara paling mudah untuk bertindak balas ialah membuat set data sintetik awam. ”
Apa pendapat anda tentang ini?
Atas ialah kandungan terperinci Model kecil Microsoft yang sangat berkuasa mencetuskan perbincangan hangat: meneroka peranan besar data peringkat buku teks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!