
Rumah >Peranti teknologi >AI >Apakah sumber keupayaan pembelajaran kontekstual Transformer?
Apakah sumber keupayaan pembelajaran kontekstual Transformer?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-18 08:01:141404semak imbas
Mengapa transformer berprestasi baik? Dari manakah datangnya keupayaan Pembelajaran Dalam Konteks yang dibawanya kepada banyak model bahasa besar? Dalam bidang kecerdasan buatan, transformer telah menjadi model dominan dalam pembelajaran mendalam, tetapi asas teori untuk prestasi cemerlangnya tidak dikaji dengan secukupnya.
Baru-baru ini, penyelidik dari Google AI, ETH Zurich dan Google DeepMind menjalankan kajian baharu untuk cuba membongkar rahsia beberapa algoritma pengoptimuman dalam Google AI. Dalam kajian ini, mereka merekayasa balik pengubah dan menemui beberapa kaedah pengoptimuman. Makalah ini dipanggil "Mendedahkan Algoritma Pengoptimuman Mesa dalam Transformer"
Pautan kertas: https://arxiv.org/abs/2309.05858
Pengarang yang meminimumkan kerugian akan menghasilkan autogresif yang universal. algoritma pengoptimuman berasaskan kecerunan tambahan yang berjalan dalam hantaran hadapan Transformer. Fenomena ini baru-baru ini dipanggil "pengoptimuman mesa." Tambahan pula, penyelidik mendapati bahawa algoritma pengoptimuman mesa yang terhasil mempamerkan keupayaan pembelajaran pukulan kecil kontekstual, bebas daripada saiz model. Oleh itu, keputusan baharu melengkapkan prinsip pembelajaran pukulan kecil yang telah muncul sebelum ini dalam model bahasa besar.
Para penyelidik percaya bahawa kejayaan Transformers adalah berdasarkan bias seni bina algoritma pengoptimuman Mesa yang dilaksanakannya dalam pas ke hadapan: (i) mentakrifkan matlamat pembelajaran dalaman, dan (ii) mengoptimumkannya
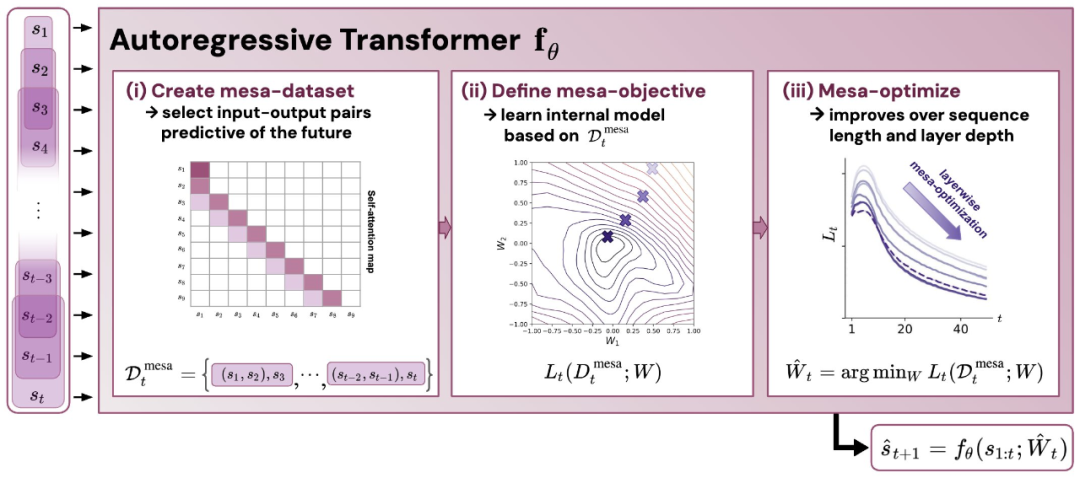
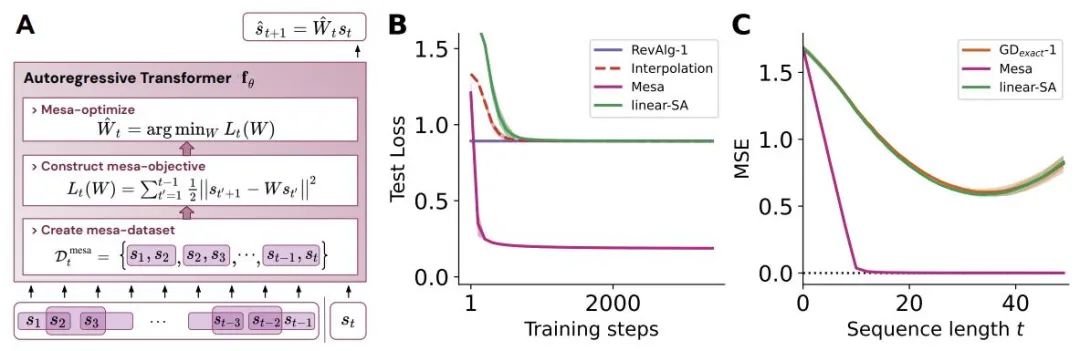
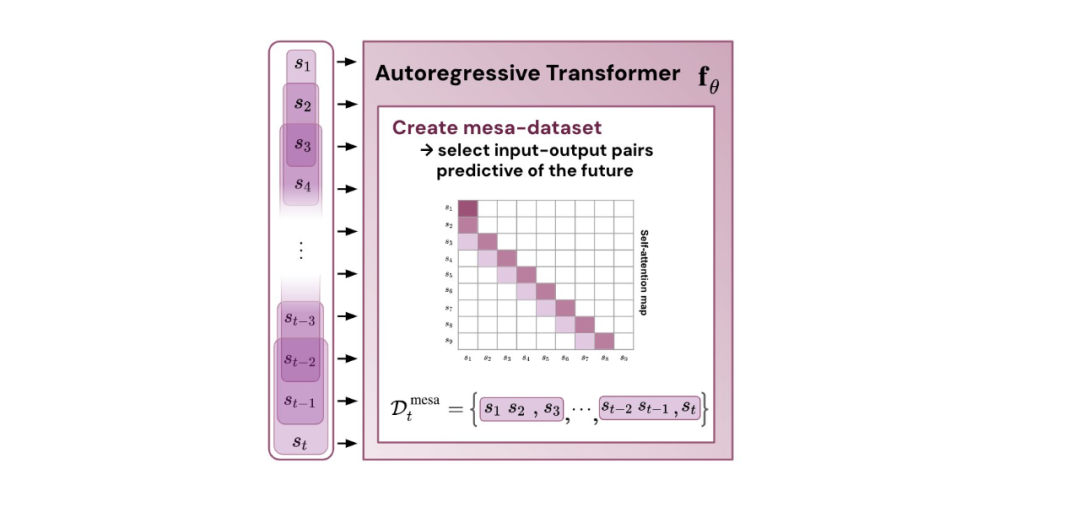
Rajah 1: Ilustrasi hipotesis baharu: mengoptimumkan pemberat θ bagi Transformer autoregresif fθ menghasilkan algoritma pengoptimuman mesa yang dilaksanakan dalam perambatan hadapan model. Sebagai urutan input s_1, . . , s_t diproses ke langkah masa t, Transformer (i) mencipta set latihan dalaman yang terdiri daripada pasangan persatuan sasaran input, (ii) mentakrifkan fungsi objektif dalaman melalui set data hasil, yang digunakan untuk mengukur prestasi model dalaman menggunakan pemberat W, (iii) Optimumkan objektif ini dan gunakan model yang dipelajari untuk menjana ramalan masa hadapan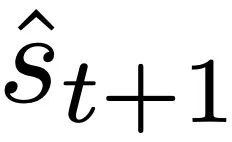 .
.
Sumbangan kajian ini termasuk yang berikut:
- Mengumumkan teori von Oswald et al dan menunjukkan bagaimana Transformers secara teori boleh mengoptimumkan objektif yang dibina secara dalaman daripada regresi menggunakan kaedah berasaskan kecerunan seterusnya. urutan.
- Transformer kejuruteraan terbalik secara eksperimen dilatih pada tugas pemodelan jujukan mudah dan menemui bukti kukuh bahawa hantaran hadapan mereka melaksanakan algoritma dua langkah: (i) lapisan perhatian kendiri awal melalui penanda pengumpulan dan salinan membina set data latihan dalaman, jadi set data latihan dalaman dibina secara tersirat. Tentukan fungsi objektif dalaman dan (ii) optimumkan objektif ini pada tahap yang lebih mendalam untuk menjana ramalan.
- Sama seperti LLM, eksperimen menunjukkan bahawa model latihan autoregresif mudah juga boleh menjadi pelajar konteks, dan pelarasan segera adalah penting untuk meningkatkan pembelajaran konteks LLM dan juga boleh meningkatkan prestasi dalam persekitaran tertentu.
- Diinspirasikan oleh penemuan bahawa lapisan perhatian cuba mengoptimumkan fungsi objektif dalaman secara tersirat, pengarang memperkenalkan lapisan mesa, jenis lapisan perhatian baharu yang boleh menyelesaikan masalah pengoptimuman kuasa dua terkecil dan bukannya hanya mengambil satu langkah kecerunan. untuk mencapai optimum. Percubaan menunjukkan bahawa satu lapisan mesa mengatasi Transformer perhatian kendiri linear dalam dan softmax pada tugas berjujukan mudah sambil memberikan lebih kebolehtafsiran.

- Selepas eksperimen pemodelan bahasa awal, didapati bahawa menggantikan lapisan perhatian kendiri standard dengan lapisan mesa mencapai hasil yang menjanjikan, membuktikan bahawa lapisan ini mempunyai keupayaan kontekstual yang kukuh.
Berdasarkan kerja baru-baru ini yang menunjukkan bahawa transformer yang dilatih secara eksplisit untuk menyelesaikan tugasan kecil dalam konteks boleh melaksanakan algoritma keturunan kecerunan (GD). Di sini, pengarang menunjukkan bahawa keputusan ini digeneralisasikan kepada pemodelan jujukan autoregresif-pendekatan tipikal untuk melatih LLM.
Pertama, analisa Transformer yang dilatih pada dinamik linear mudah. Dalam kes ini, setiap jujukan dijana oleh W* yang berbeza untuk mengelakkan hafalan jujukan silang. Dalam persediaan mudah ini, penyelidik menunjukkan cara Transformer mencipta set data mesa dan menggunakan GD praproses untuk mengoptimumkan objektif mesa
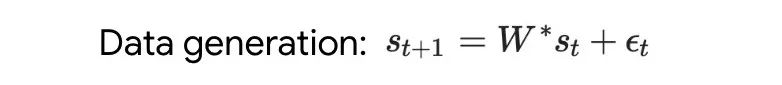
Kandungan yang ditulis semula ialah: kita boleh mengagregatkan struktur token unsur jujukan bersebelahan dengan melatih pengubah dalam. Menariknya, kaedah prapemprosesan mudah ini menghasilkan matriks berat yang sangat jarang (kurang daripada 1% berat adalah bukan sifar), menghasilkan algoritma kejuruteraan terbalik
Untuk perhatian kendiri linear satu lapisan, pemberat Sepadan dengan langkah penurunan kecerunan. Untuk Transformer mendalam, kebolehtafsiran menjadi sukar. Kajian ini bergantung pada probing linear dan meneliti sama ada pengaktifan tersembunyi dapat meramalkan sasaran autoregresif atau input praproses
Menariknya, kebolehramalan kedua-dua kaedah probing secara beransur-ansur bertambah baik dengan peningkatan kedalaman rangkaian. Dapatan ini menunjukkan bahawa GD praproses tersembunyi dalam model.
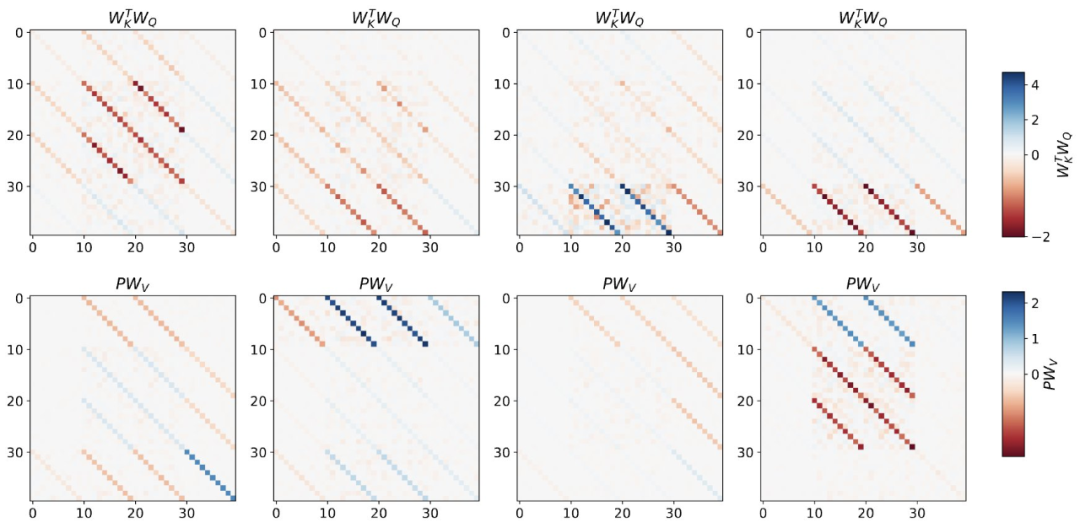
Rajah 2: Kejuruteraan songsang lapisan perhatian kendiri linear terlatih.
Kajian mendapati bahawa lapisan latihan boleh dipasang dengan sempurna apabila menggunakan semua darjah kebebasan dalam pembinaan, termasuk bukan sahaja kadar pembelajaran yang dipelajari η, tetapi juga satu set pemberat awal yang dipelajari W_0. Yang penting, seperti yang ditunjukkan dalam Rajah 2, algoritma satu langkah yang dipelajari masih berprestasi jauh lebih baik daripada satu lapisan mesa.
Dengan tetapan berat yang mudah, kita dapat melihat bahawa adalah mudah untuk mencari melalui pengoptimuman asas bahawa lapisan ini boleh menyelesaikan tugas penyelidikan ini secara optimum. Keputusan ini membuktikan bahawa bias induktif pengekodan keras bermanfaat untuk pengoptimuman mesa
Dengan cerapan teori ke dalam kes berbilang lapisan, mula-mula analisa linear dalam dan softmax dan beri perhatian hanya kepada Transformer. Pengarang memformat input mengikut struktur 4 saluran, 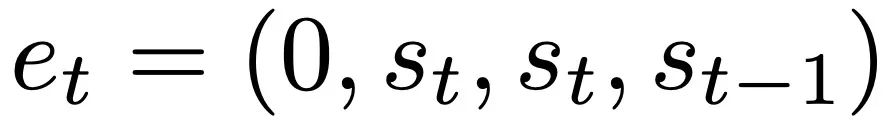 , yang sepadan dengan pilihan W_0 = 0.
, yang sepadan dengan pilihan W_0 = 0.
Seperti model satu lapisan, penulis melihat struktur yang jelas dalam berat model terlatih. Sebagai analisis kejuruteraan terbalik yang pertama, kajian ini mengeksploitasi struktur ini dan membina algoritma (RevAlg-d, dengan d mewakili bilangan lapisan) yang mengandungi 16 parameter setiap pengepala lapisan (bukannya 3200). Penulis mendapati bahawa ungkapan termampat tetapi kompleks ini boleh menggambarkan model terlatih. Khususnya, ia membenarkan interpolasi antara Transformer sebenar dan pemberat RevAlg-d dalam cara yang hampir tanpa kerugian
Walaupun ungkapan RevAlg-d menerangkan Transformer berbilang lapisan terlatih dengan sebilangan kecil parameter bebas, ia adalah sukar untuk menukar Ia dijelaskan sebagai algoritma pengoptimuman mesa. Oleh itu, penulis menggunakan analisis probing regresi linear (Alain & Bengio, 2017; Akyürek et al., 2023) untuk mencari ciri-ciri algoritma pengoptimuman mesa yang dihipotesiskan.
Pada Transformer perhatian kendiri linear dalam yang ditunjukkan dalam Rajah 3, kita dapat memerhatikan bahawa kedua-dua probe mampu untuk penyahkodan linear, dan apabila panjang jujukan dan kedalaman rangkaian meningkat, prestasi penyahkodan juga meningkat. Oleh itu, kami menemui algoritma pengoptimuman asas yang menurun lapisan demi lapisan berdasarkan objektif mesa asal Lt (W) sambil menambah baik nombor keadaan masalah pengoptimuman mesa. Ini mengakibatkan penurunan pesat dalam objektif mesa Lt (W). Tambahan pula, kita juga dapat melihat bahawa prestasi meningkat dengan ketara apabila kedalaman meningkat
Dengan prapemprosesan data yang lebih baik, fungsi objektif autoregresif Lt (W) boleh dioptimumkan secara berperingkat (merentasi lapisan), jadi penurunan pantas boleh dipertimbangkan Ia dicapai melalui pengoptimuman ini
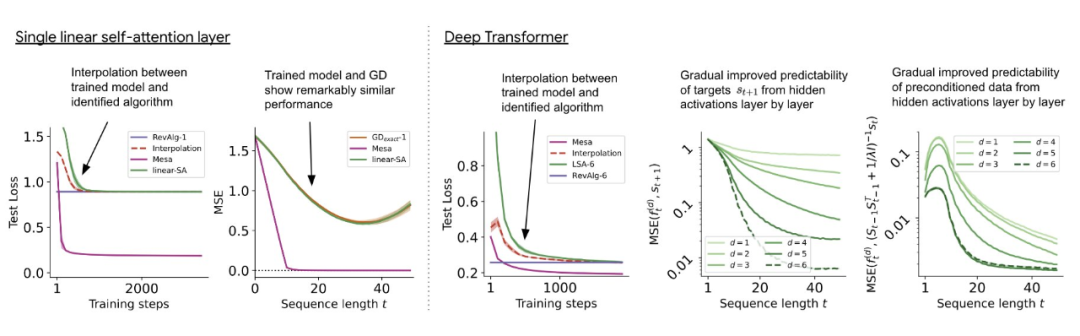
Rajah 3: Latihan Transformer berbilang lapisan untuk kejuruteraan terbalik input token yang dibina.
Ini menunjukkan bahawa jika transformer dilatih pada token yang dibina, ia akan meramalkan dengan pengoptimuman mesa. Menariknya, apabila elemen jujukan diberikan secara langsung, pengubah akan membina token dengan sendirinya dengan mengumpulkan elemen, yang dipanggil oleh pasukan penyelidik sebagai "mencipta dataset mesa".
Kesimpulan
Dapatan kajian ini ialah apabila model Transformer digunakan untuk latihan mengenai tugas ramalan jujukan di bawah objektif autoregresif standard, Algoritma inferens berasaskan kecerunan boleh dibangunkan. Oleh itu, keputusan multi-tugas dan meta-pembelajaran terkini juga boleh digunakan untuk tetapan latihan LLM penyeliaan kendiri tradisional
Selain itu, kajian juga mendapati bahawa mereka yang belajar inferens autoregresif Algoritma boleh digunakan semula untuk menyelesaikan tugas pembelajaran kontekstual yang diselia tanpa perlu latihan semula, dengan itu mentafsir keputusan dalam rangka kerja yang bersatu 🎜#
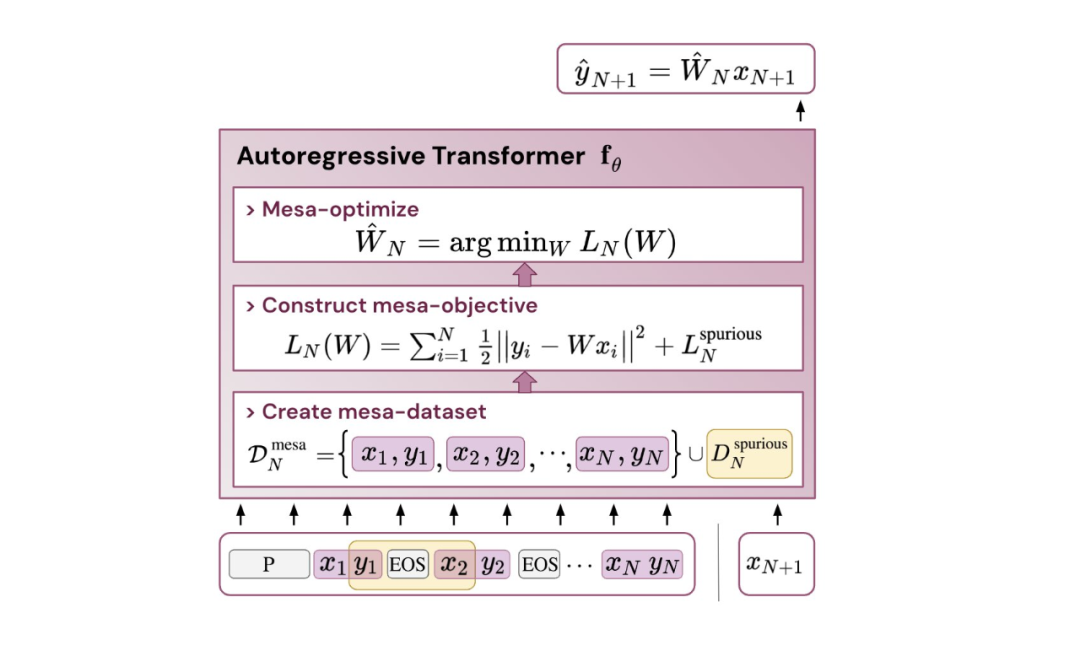
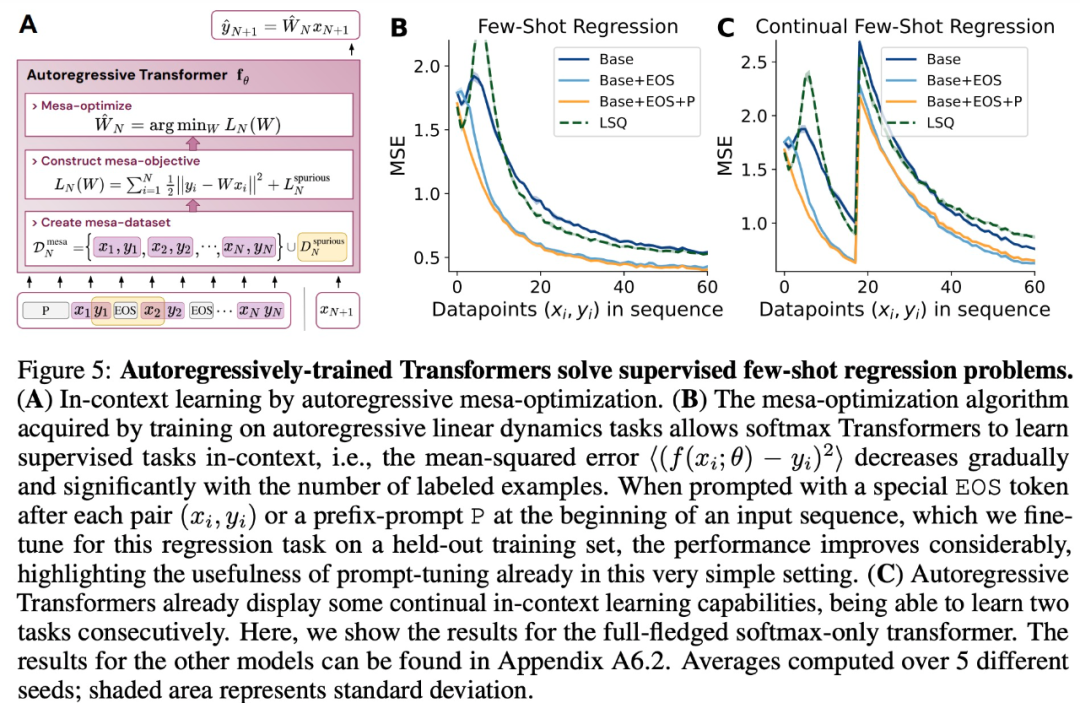
Jadi, apakah kaitannya dengan pembelajaran kontekstual? Menurut kajian itu, selepas melatih model pengubah, pada tugas jujukan autoregresif, ia mencapai pengoptimuman mesa yang sesuai dan oleh itu boleh melakukan pembelajaran konteks beberapa pukulan tanpa sebarang penalaan halus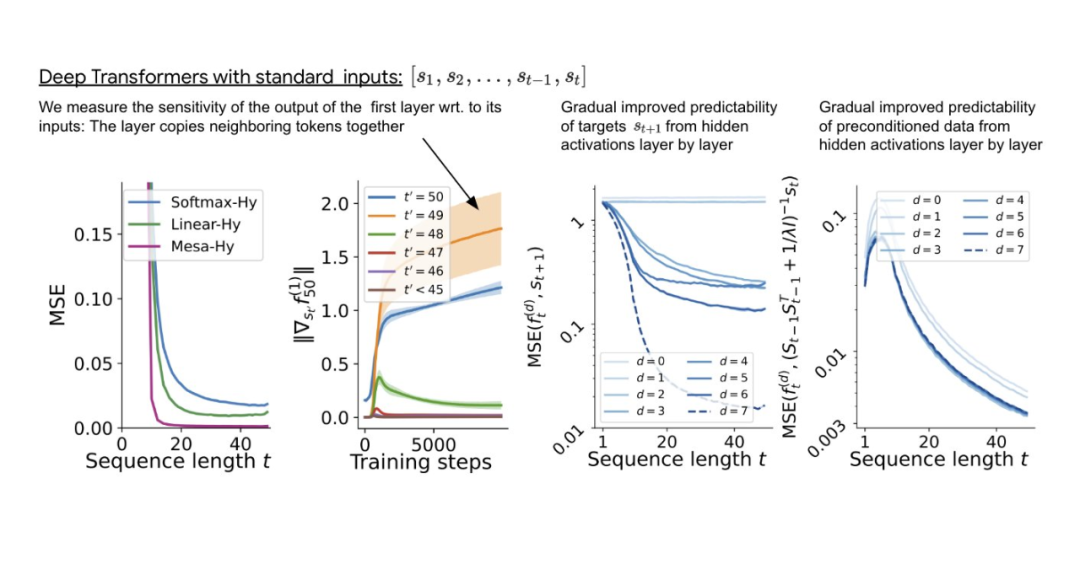
Kajian ini mengandaikan bahawa pengoptimuman mesa juga wujud dalam LLM, dengan itu meningkatkan keupayaan pembelajaran konteksnya. Menariknya, kajian itu juga mendapati bahawa menyesuaikan gesaan secara berkesan untuk LLM juga boleh membawa kepada peningkatan yang ketara dalam keupayaan pembelajaran kontekstual.
 #🎜🎜🎜##🎜🎜🎜##🎜🎜🎜 🎜#Pembaca yang berminat boleh membaca teks asal kertas untuk mengetahui lebih lanjut tentang kandungan penyelidikan.
#🎜🎜🎜##🎜🎜🎜##🎜🎜🎜 🎜#Pembaca yang berminat boleh membaca teks asal kertas untuk mengetahui lebih lanjut tentang kandungan penyelidikan.
Atas ialah kandungan terperinci Apakah sumber keupayaan pembelajaran kontekstual Transformer?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!