
Rumah >Peranti teknologi >AI >Dengarkan saya, Transformer ialah mesin vektor sokongan
Dengarkan saya, Transformer ialah mesin vektor sokongan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-17 18:09:03834semak imbas
Transformer ialah mesin vektor sokongan (SVM), satu teori baharu yang telah mencetuskan perbincangan dalam komuniti akademik.
Hujung minggu lalu, kertas kerja dari University of Pennsylvania dan University of California, Riverside cuba mengkaji prinsip struktur Transformer berdasarkan model besar, geometri yang dioptimumkan dalam lapisan perhatian dan pemisahan token input optimum daripada token tidak optimum. Kesetaraan formal diwujudkan antara masalah SVM yang terhad.
Pengarang menyatakan di hackernews bahawa teori ini menyelesaikan masalah SVM memisahkan token "baik" daripada token "buruk" dalam setiap urutan input. Sebagai pemilih token dengan prestasi cemerlang, SVM ini pada asasnya berbeza daripada SVM tradisional yang memberikan label 0-1 kepada input.
Teori ini juga menerangkan bagaimana perhatian mendorong jarang melalui softmax: token "buruk" yang jatuh di sebelah salah sempadan keputusan SVM ditindas oleh fungsi softmax, manakala token "baik" adalah token yang berakhir dengan bukan- token kebarangkalian sifar softmax. Perlu juga dinyatakan bahawa SVM ini berasal daripada sifat eksponen softmax.
Selepas kertas itu dimuat naik ke arXiv, orang ramai menyatakan pendapat mereka satu demi satu. Beberapa orang berkata: Hala tuju penyelidikan AI benar-benar berpusing, adakah ia akan kembali lagi?
Selepas melakukan bulatan penuh, mesin vektor sokongan masih tidak ketinggalan zaman.
Sejak penerbitan kertas klasik "Attention is All You Need", seni bina Transformer telah membawa kemajuan revolusioner kepada bidang pemprosesan bahasa semula jadi (NLP). Lapisan perhatian dalam Transformer menerima satu siri token input X dan menilai korelasi antara token dengan mengira 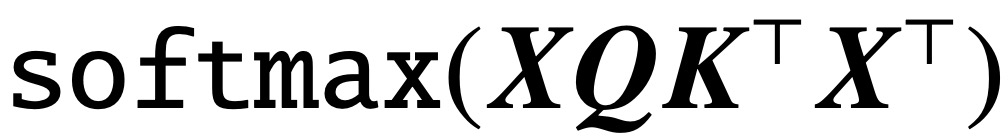 , di mana (K, Q) ialah parameter pertanyaan kunci yang boleh dilatih, akhirnya menangkap kebergantungan jauh dengan berkesan.
, di mana (K, Q) ialah parameter pertanyaan kunci yang boleh dilatih, akhirnya menangkap kebergantungan jauh dengan berkesan.
Kini, kertas baharu yang dipanggil "Transformers as Support Vector Machines" mewujudkan kesetaraan formal antara geometri pengoptimuman perhatian kendiri dan masalah SVM margin keras, menggunakan produk luar linear pasangan token Kekangan token input optimum yang berasingan daripada token yang tidak optimum.

Pautan kertas: https://arxiv.org/pdf/2308.16898.pdf
Persamaan rasmi ini berdasarkan kertas "Max-Margin Token Selection" oleh Dazanaud echanism Attention al. "Atas dasar penyelarasan Vanishing, menumpu kepada penyelesaian SVM yang meminimumkan norma nuklear bagi parameter gabungan
. Sebaliknya, parameter secara langsung melalui W meminimumkan objektif SVM norma Frobenius. Kertas kerja ini menerangkan penumpuan ini dan menekankan bahawa ia boleh berlaku ke arah optimum tempatan dan bukannya optimum global. 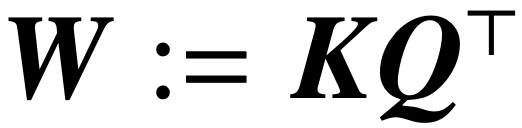 (2) Kertas kerja ini juga menunjukkan penumpuan arah tempatan/global bagi keturunan kecerunan parameterisasi W di bawah keadaan geometri yang sesuai. Yang penting, overparameterization memangkinkan penumpuan global dengan memastikan kebolehlaksanaan masalah SVM dan memastikan persekitaran pengoptimuman yang jinak tanpa titik pegun.
(2) Kertas kerja ini juga menunjukkan penumpuan arah tempatan/global bagi keturunan kecerunan parameterisasi W di bawah keadaan geometri yang sesuai. Yang penting, overparameterization memangkinkan penumpuan global dengan memastikan kebolehlaksanaan masalah SVM dan memastikan persekitaran pengoptimuman yang jinak tanpa titik pegun.
(3) Walaupun teori kajian ini digunakan terutamanya untuk kepala ramalan linear, pasukan penyelidik mencadangkan persamaan SVM yang lebih umum yang boleh meramalkan bias tersirat transformer 1 lapisan dengan kepala bukan linear/MLP.
Secara amnya, hasil kajian ini boleh digunakan untuk set data umum dan boleh dilanjutkan ke lapisan perhatian silang, dan kesahihan praktikal kesimpulan kajian telah disahkan melalui eksperimen berangka yang menyeluruh. Kajian ini mewujudkan perspektif penyelidikan baharu yang melihat pengubah berbilang lapisan sebagai hierarki SVM yang memisahkan dan memilih token terbaik.
Secara khusus, diberikan urutan input panjang T dan dimensi benam d
, kajian ini menganalisis model perhatian silang dan perhatian kendiri teras:

di mana K, Q dan V masing-masing adalah kunci, pertanyaan dan matriks nilai yang boleh dilatih, #🎜🎜 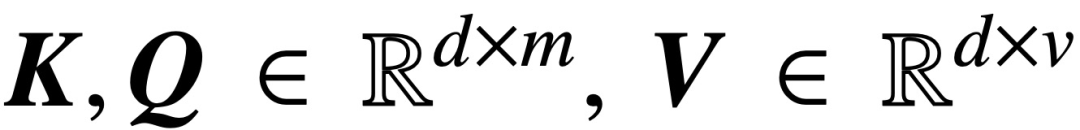 ; S (・) mewakili non-lineariti softmax, yang digunakan baris demi baris. Kajian mengandaikan bahawa token pertama Z (ditandakan dengan z) digunakan untuk ramalan. Khususnya, diberikan set data latihan
; S (・) mewakili non-lineariti softmax, yang digunakan baris demi baris. Kajian mengandaikan bahawa token pertama Z (ditandakan dengan z) digunakan untuk ramalan. Khususnya, diberikan set data latihan 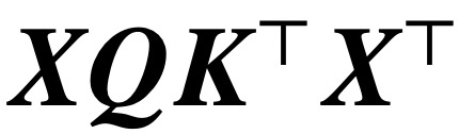 ,
, 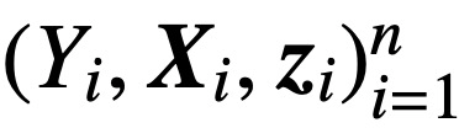 ,
, 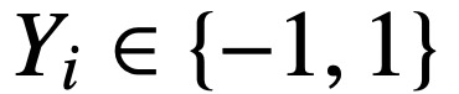 , Kaji penggunaan fungsi kehilangan berkurangan untuk pengecilan:
, Kaji penggunaan fungsi kehilangan berkurangan untuk pengecilan: 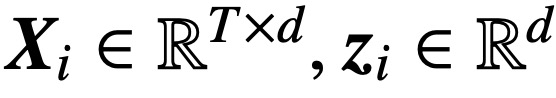
 sini , h (・): #🎜🎜
sini , h (・): #🎜🎜
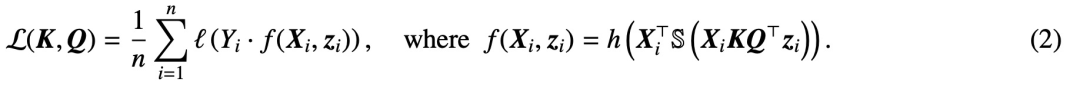
 Kertas ini distrukturkan seperti berikut: Bab 2 memperkenalkan pengetahuan awal perhatian dan pengoptimuman kendiri Bab 3 menganalisis geometri pengoptimuman perhatian kendiri dan menunjukkan perhatian parameter RP menumpu kepada penyelesaian marginal maksimum Bab 4 dan 5 masing-masing memperkenalkan analisis keturunan kecerunan global dan tempatan, menunjukkan bahawa pembolehubah pertanyaan kunci W menumpu kepada penyelesaian (Att-SVM Bab 6 menyediakan maklumat mengenai keputusan ramalan bukan linear pada kesetaraan kepala dan SVM umum Bab 7 memanjangkan teori kepada ramalan berurutan dan ramalan sebab-sebab Bab 8 membincangkan literatur yang berkaitan. Akhir sekali, Bab 9 diakhiri dengan mencadangkan soalan terbuka dan hala tuju penyelidikan masa hadapan.
Kertas ini distrukturkan seperti berikut: Bab 2 memperkenalkan pengetahuan awal perhatian dan pengoptimuman kendiri Bab 3 menganalisis geometri pengoptimuman perhatian kendiri dan menunjukkan perhatian parameter RP menumpu kepada penyelesaian marginal maksimum Bab 4 dan 5 masing-masing memperkenalkan analisis keturunan kecerunan global dan tempatan, menunjukkan bahawa pembolehubah pertanyaan kunci W menumpu kepada penyelesaian (Att-SVM Bab 6 menyediakan maklumat mengenai keputusan ramalan bukan linear pada kesetaraan kepala dan SVM umum Bab 7 memanjangkan teori kepada ramalan berurutan dan ramalan sebab-sebab Bab 8 membincangkan literatur yang berkaitan. Akhir sekali, Bab 9 diakhiri dengan mencadangkan soalan terbuka dan hala tuju penyelidikan masa hadapan.  Kandungan utama kertas tersebut adalah seperti berikut:
Kandungan utama kertas tersebut adalah seperti berikut:
#🎜🎜 bias tersirat lapisan perhatian ( Bab 2-3)
Mengoptimumkan parameter perhatian (K, Q) apabila regularization hilang akan menumpu kepada #🎜 dalam arah Maksimum penyelesaian marginal 🎜#
, sasaran norma nuklearnya ialah parameter gabungan . Dalam kes meparameterkan perhatian silang secara langsung dengan gabungan parameter W, laluan regularisasi (RP) menumpu secara berarah kepada penyelesaian (Att-SVM) yang menyasarkan norma Frobenius.
Ini ialah hasil pertama yang membezakan secara rasmi W lawan (K, Q) dinamik pengoptimuman parametrik, mendedahkan bias tertib rendah pada yang terakhir. Teori kajian ini dengan jelas menerangkan keoptimuman token yang dipilih dan secara semula jadi meluas kepada tetapan klasifikasi urutan-ke-jujukan atau kausal. 
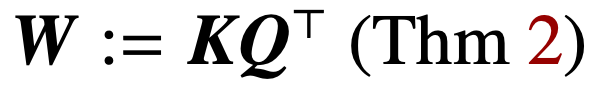 Penumpuan Turun Kecerunan (Bab 4-5) #🎜🎜🎜🎜🎜🎜🎜🎜 Dengan permulaan yang sesuai dan kepala linear h (・), lelaran turunan kecerunan (GD) gabungan pembolehubah pertanyaan kunci W menumpu ke arah kepada penyelesaian optimum tempatan (Att-SVM) (Bahagian 5). Untuk mencapai optimum tempatan, token yang dipilih mesti mempunyai skor yang lebih tinggi daripada token bersebelahan.
Penumpuan Turun Kecerunan (Bab 4-5) #🎜🎜🎜🎜🎜🎜🎜🎜 Dengan permulaan yang sesuai dan kepala linear h (・), lelaran turunan kecerunan (GD) gabungan pembolehubah pertanyaan kunci W menumpu ke arah kepada penyelesaian optimum tempatan (Att-SVM) (Bahagian 5). Untuk mencapai optimum tempatan, token yang dipilih mesti mempunyai skor yang lebih tinggi daripada token bersebelahan.
Arah optimum tempatan tidak semestinya unik dan boleh ditentukan berdasarkan ciri geometri masalah [TLZO23]. Sebagai sumbangan penting, penulis mengenal pasti keadaan geometri yang menjamin penumpuan ke arah optimum global (Bab 4). Syarat ini termasuk:
- Token terbaik mempunyai perbezaan markah yang jelas;
- Arah kecerunan awal adalah konsisten dengan token terbaik.
Selain itu, kertas kerja ini juga menunjukkan bahawa penparameteran berlebihan (iaitu, dimensi d adalah besar, dan keadaan yang sama) dengan memastikan kebolehlaksanaan (1) (Att-SVM), dan (2) jinak. landskap pengoptimuman (iaitu. Tiada titik pegun dan arah optimum tempatan palsu) untuk memangkinkan penumpuan global (lihat Bahagian 5.2).
Rajah 1 dan 2 menggambarkan ini.
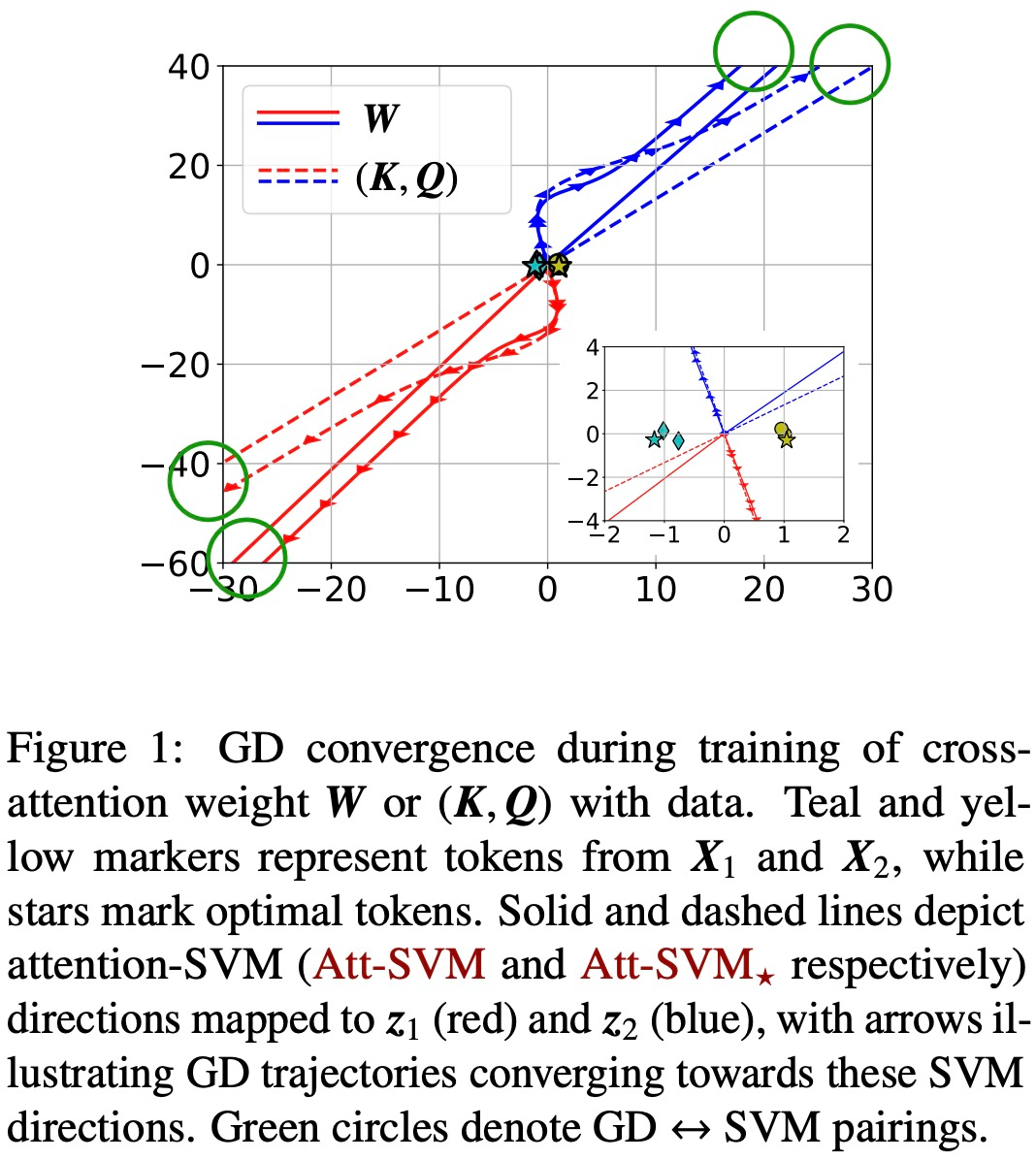
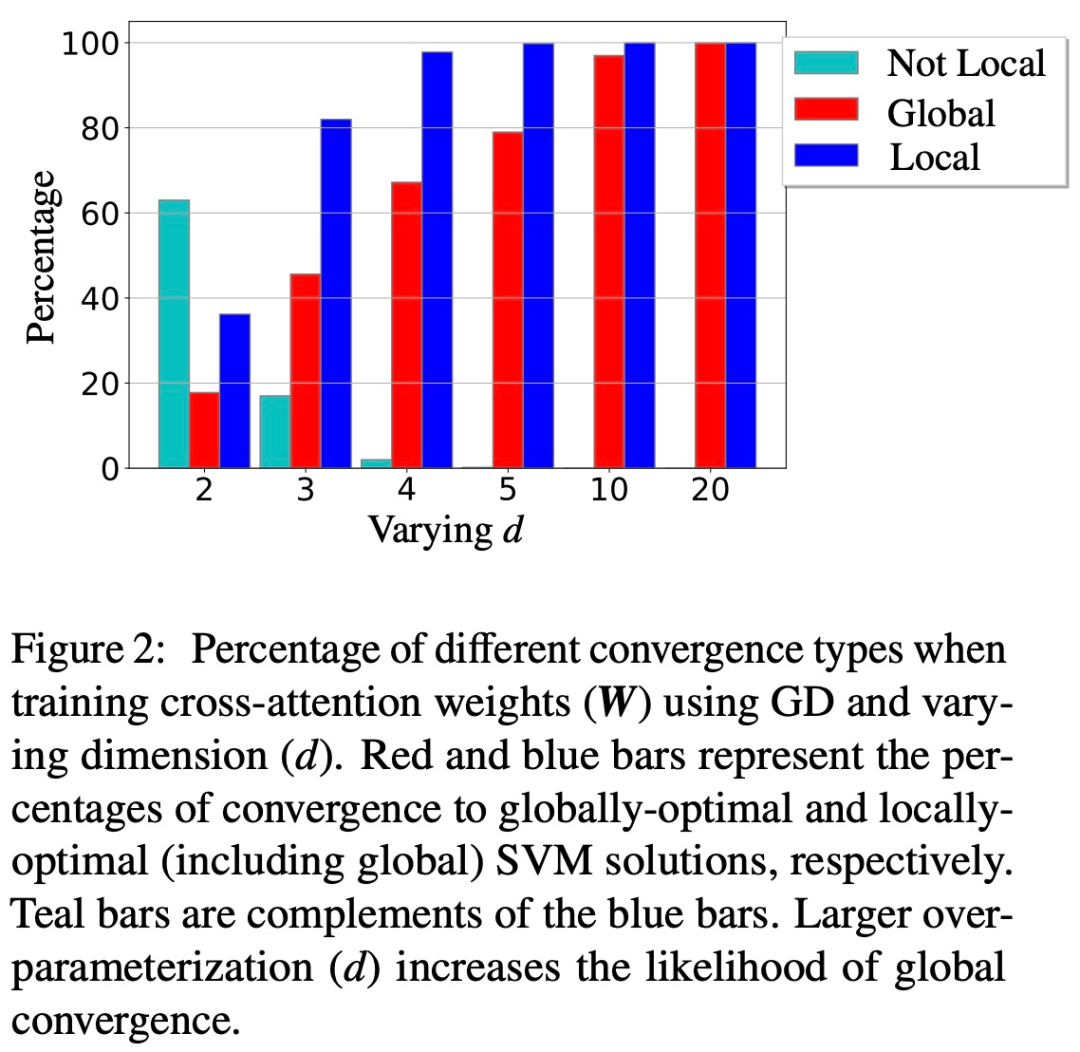
Generalisasi bersamaan SVM (Bab 6)
Lapisan Perhatian wujud apabila mengoptimumkan dengan linear H (・) Bias tanah untuk memilih satu token dari setiap urutan (aka perhatian keras). Ini ditunjukkan dalam (Att-SVM), di mana token output ialah gabungan cembung token input. Sebaliknya, pengarang menunjukkan bahawa kepala tak linear mesti terdiri daripada berbilang token, sekali gus menonjolkan kepentingannya dalam dinamik pengubah (Bahagian 6.1). Menggunakan pandangan yang diperoleh daripada teori, penulis mencadangkan pendekatan setara SVM yang lebih umum.
Terutamanya, mereka menunjukkan bahawa kaedah kami boleh meramal dengan tepat bias tersirat perhatian yang dilatih melalui keturunan kecerunan dalam kes umum yang tidak diliputi oleh teori (cth., h (・) ialah MLP). Khususnya, formula am kami memisahkan berat perhatian kepada dua bahagian: bahagian arah dikawal oleh SVM, yang memilih penanda dengan menggunakan topeng 0-1 dan bahagian terhingga, yang melaraskan Kebarangkalian softmax menentukan komposisi tepat token yang dipilih.
Ciri penting penemuan ini ialah ia digunakan pada set data sewenang-wenang (selagi SVM boleh dilaksanakan) dan boleh disahkan secara berangka. Pengarang secara meluas secara eksperimen mengesahkan kesetaraan marginal maksimum dan bias tersirat pengubah. Penulis percaya bahawa penemuan ini menyumbang kepada pemahaman transformer sebagai mekanisme pemilihan token margin maksimum hierarki dan boleh meletakkan asas untuk penyelidikan akan datang mengenai pengoptimuman dan dinamik generalisasi mereka.
Atas ialah kandungan terperinci Dengarkan saya, Transformer ialah mesin vektor sokongan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!