
Rumah >Peranti teknologi >AI >Andrew Ng sukakannya! Sarjana Harvard dan MIT menggunakan catur untuk membuktikan bahawa model bahasa besar memang 'memahami' dunia
Andrew Ng sukakannya! Sarjana Harvard dan MIT menggunakan catur untuk membuktikan bahawa model bahasa besar memang 'memahami' dunia

- 王林ke hadapan
- 2023-09-15 11:29:011591semak imbas
Pada tahun 2021, ahli bahasa Universiti Washington, Emily M. Bender menerbitkan kertas kerja dengan alasan bahawa model bahasa besar tidak lebih daripada "burung kakak tua stokastik". secara rawak menjana perkataan yang kelihatan munasabah seperti burung kakak tua.
Disebabkan rangkaian saraf yang tidak dapat ditafsirkan, komuniti akademik tidak pasti sama ada model bahasa itu burung nuri rawak, dan pendapat pelbagai pihak sangat berbeza.
Disebabkan kekurangan ujian yang diiktiraf secara meluas, sama ada model boleh "memahami dunia" telah menjadi persoalan falsafah dan bukannya persoalan saintifik.
Baru-baru ini, penyelidik dari Universiti Harvard dan MIT bersama-sama menerbitkan kajian baharu Othello-GPT, yang mengesahkan keberkesanan perwakilan dalaman dalam permainan papan mudah Mereka percaya bahawa perwakilan dalaman model bahasa sememangnya telah dicipta model dunia, bukan sekadar ingatan atau statistik mudah, tetapi sumber keupayaannya masih tidak jelas.

Pautan kertas: https://arxiv.org/pdf/2210.13382.pdf
Tanpa pengetahuan awal tentang peraturan Othello, penyelidik boleh Predict bahawa model itu langkah undang-undang dan menangkap keadaan lembaga dengan ketepatan yang sangat tinggi.
Andrew Ng menyatakan pengiktirafan tinggi untuk penyelidikan ini dalam lajur "Surat" Beliau percaya bahawa berdasarkan penyelidikan ini, terdapat sebab untuk mempercayai bahawa model bahasa berskala besar telah membina model dunia yang cukup kompleks, dan sedikit sebanyak. , memahami dunia.
Pautan blog: https://www.deeplearning.ai/the-batch/does-ai-understand-the-world/
Namun, Andrew Ng juga berkata walaupun falsafah itu penting, ini Perdebatan mungkin akan berterusan selama-lamanya, jadi mari kita ke pengaturcaraan!
Model Dunia Papan Catur
Jika anda membayangkan papan catur sebagai "dunia" yang mudah dan memerlukan model membuat keputusan berterusan semasa permainan, anda boleh menguji pada mulanya sama ada model jujukan boleh mempelajari perwakilan dunia.

Para penyelidik memilih permainan Othello yang mudah, Othello, sebagai platform percubaan bergilir-gilir untuk membuat gerakan Dalam arah lurus atau pepenjuru, semua kepingan musuh (tidak termasuk ruang) di antara dua bahagian sebelah sendiri semuanya akan menjadi kepingan seseorang (dipanggil potongan tangkapan pada akhirnya). , lembaga akan diduduki sepenuhnya, yang mempunyai lebih ramai anak lelaki menang.
Berbanding dengan catur, peraturan Othello jauh lebih mudah pada masa yang sama, ruang carian permainan catur cukup besar sehingga model tidak dapat melengkapkan penjanaan urutan melalui ingatan, jadi ia sangat sesuai untuk menguji perwakilan dunia; keupayaan pembelajaran model.
Model Bahasa Othello
Para penyelidik mula-mula melatih versi varian GPT bagi model bahasa (Othello-GPT), memasukkan skrip permainan (satu siri operasi pergerakan catur yang dibuat oleh pemain) ke dalam model, tetapi model tidak mempunyai maklumat tentang Pengetahuan terdahulu tentang permainan dan peraturan yang berkaitan.
Model ini tidak dilatih secara eksplisit untuk meneruskan peningkatan strategi, memenangi permainan, dsb., tetapi mempunyai ketepatan yang agak tinggi apabila menjana operasi pergerakan Othello yang sah.
Dataset
Para penyelidik menggunakan dua set data latihan:
Kejuaraan (Kejuaraan) lebih menumpukan pada kualiti data, terutamanya yang diterima pakai daripada kejohanan strategik manusia yang profesional langkah, tetapi masing-masing hanya 7605 dan 132921 sampel permainan Selepas dua set data digabungkan, mereka dibahagikan secara rawak kepada set latihan (20 juta sampel) dan set pengesahan (3.796 juta sampel) pada nisbah 8:2. ).
Sintetik memberi lebih perhatian kepada skala data dan terdiri daripada operasi pergerakan rawak dan undang-undang Pengedaran data berbeza daripada set data kejuaraan, tetapi diambil secara sama rata daripada pokok permainan Othello, dengan 20 juta sampel digunakan latihan dan 3.796 juta sampel untuk pengesahan.
Penerangan setiap permainan terdiri daripada rentetan token, dan saiz perbendaharaan kata ialah 60 (8*8-4)
Model dan latihan
Seni bina model ialah 8 lapisan Model GPT dengan 8 kepala , dimensi tersembunyi ialah 512
Berat model dimulakan sepenuhnya secara rawak, termasuk lapisan pembenaman perkataan Walaupun terdapat hubungan geometri dalam senarai perkataan yang mewakili kedudukan papan catur (seperti C4 lebih rendah daripada B4), bias induktif ini tidak dinyatakan dengan jelas, tetapi diserahkan kepada model untuk belajar.
Ramalkan langkah undang-undang
Penunjuk penilaian utama model ialah sama ada operasi pergerakan yang diramalkan oleh model mematuhi peraturan Othello.
Othello-GPT yang dilatih pada set data sintetik mempunyai kadar ralat 0.01% dan pada set data kejuaraan kadar ralat 5.17%, berbanding dengan kadar ralat 93.29% untuk Othello-GPT yang tidak terlatih, iaitu , kedua-dua set data ini membolehkan model mempelajari peraturan permainan pada tahap tertentu.
Satu penjelasan yang mungkin ialah model itu mengingati semua operasi pergerakan permainan Othello.
Untuk menguji tekaan ini, para penyelidik mensintesis set data baharu: pada permulaan setiap permainan, Othello mempunyai empat kemungkinan kedudukan pembukaan (C5, D6, E3 dan F4), dan semua bukaan C5 Selepas mengalih keluar pergerakan, ia digunakan sebagai set latihan, dan kemudian data pembukaan C5 digunakan sebagai ujian, iaitu hampir 1/4 pokok permainan telah dialih keluar Didapati kadar ralat model masih 0.02% sahaja
. Jadi Othello-GPT Prestasi tinggi bukan disebabkan oleh ingatan, kerana data ujian benar-benar tidak kelihatan semasa proses latihan Jadi apa sebenarnya yang membuatkan model itu berjaya meramalkan?
Teroka perwakilan dalaman
Alat yang biasa digunakan untuk mengesan perwakilan dalaman rangkaian saraf ialah probe Setiap probe ialah pengelas atau regressor yang inputnya terdiri daripada pengaktifan dalaman rangkaian dan dilatih untuk Meramalkan ciri yang diminati.
Dalam tugasan ini, untuk mengesan sama ada pengaktifan dalaman Othello-GPT mengandungi perwakilan keadaan papan catur semasa, selepas memasukkan urutan pergerakan, vektor pengaktifan dalaman digunakan untuk meramalkan langkah pergerakan seterusnya.
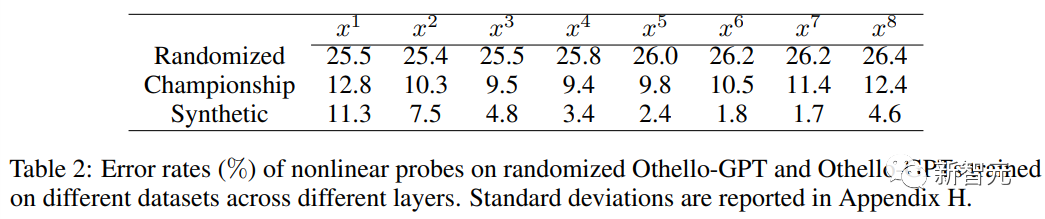
Apabila menggunakan probe linear, perwakilan dalaman Othello-GPT terlatih hanya lebih tepat sedikit daripada tekaan rawak.

Apabila menggunakan probe tak linear (MLP dua lapisan), kadar ralat menurun dengan ketara, membuktikan bahawa keadaan papan tidak disimpan dalam pengaktifan rangkaian dengan cara yang mudah.
Eksperimen Intervensi
Untuk menentukan hubungan sebab akibat antara ramalan model dan perwakilan dunia yang muncul, iaitu, sama ada keadaan lembaga memang mempengaruhi keputusan ramalan rangkaian, penyelidik menjalankan satu set eksperimen intervensi dan Mengukur hasil kesan.
Memandangkan satu set pengaktifan daripada Othello-GPT, gunakan probe untuk meramalkan keadaan papan, merekodkan ramalan pergerakan yang berkaitan, dan kemudian mengubah suai pengaktifan untuk membenarkan kuar meramalkan keadaan papan yang dikemas kini.
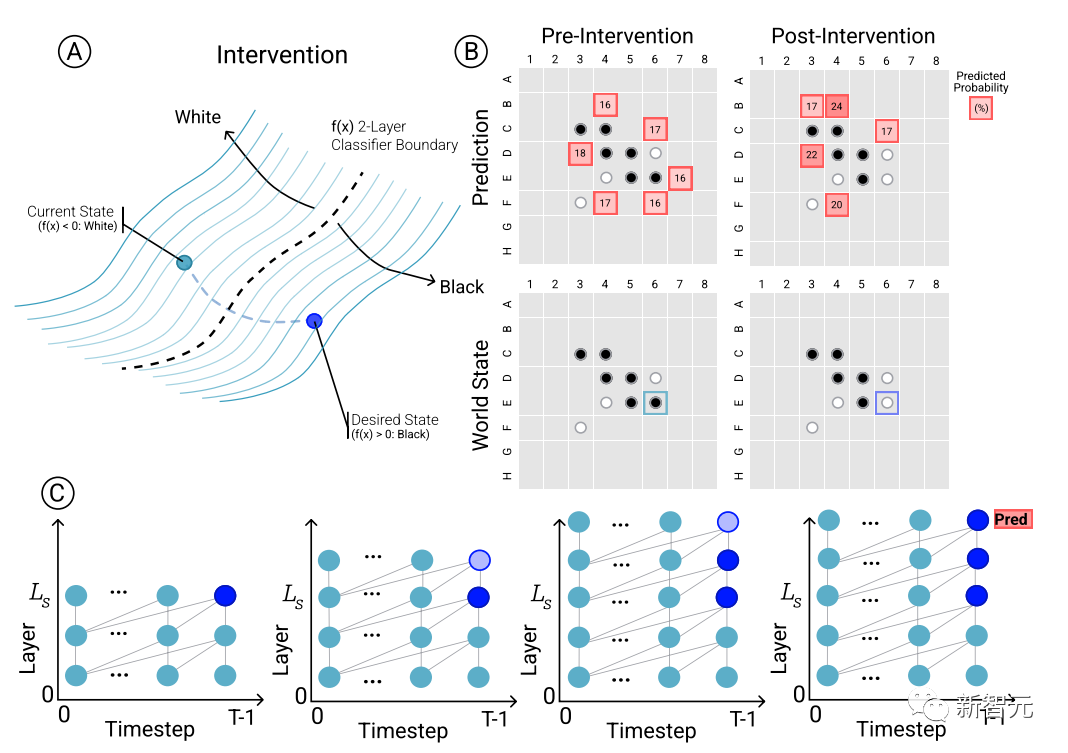
Operasi intervensi termasuk menukar buah catur dalam kedudukan tertentu daripada putih kepada hitam, dsb. Pengubahsuaian kecil akan menyebabkan keputusan model mendapati bahawa perwakilan dalaman boleh melengkapkan ramalan dengan pasti, iaitu, terdapat jurang antara perwakilan dalaman dan ramalan model.
Visualisasi
Selain eksperimen intervensi untuk mengesahkan keberkesanan perwakilan dalaman, penyelidik juga memvisualisasikan hasil ramalan Sebagai contoh, untuk setiap buah catur pada papan catur, model boleh ditanya sama ada teknologi intervensi digunakan untuk menukar buah catur Bagaimana keputusan yang diramalkan akan berubah sepadan dengan kepentingan keputusan yang diramalkan.
Kemudian kad diwarnakan dan divisualisasikan berdasarkan ketonjolan yang diramalkan oleh top1 keadaan papan catur semasa Oleh kerana peta yang dilukis adalah input berdasarkan ruang terpendam rangkaian, ia juga boleh dipanggil peta ketonjolan terpendam.

Adalah dapat dilihat bahawa corak yang jelas dipamerkan dalam peta kepentingan terpendam bagi ramalan 1 teratas Othello-GPT yang dilatih pada set data sintetik dan kejuaraan.
Versi sintetik Othello-GPT menunjukkan nilai kepentingan yang lebih tinggi dalam kedudukan operasi yang sah, manakala nilai kepentingan operasi haram adalah jauh lebih rendah Malah pemain catur yang mempunyai sedikit pengalaman dapat melihat niat model tersebut
Peta saliency versi kejohanan adalah lebih kompleks Walaupun nilai saliency bagi kedudukan operasi undang-undang adalah agak tinggi, kedudukan lain juga menunjukkan saliency yang lebih tinggi.
Atas ialah kandungan terperinci Andrew Ng sukakannya! Sarjana Harvard dan MIT menggunakan catur untuk membuktikan bahawa model bahasa besar memang 'memahami' dunia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!