
Rumah >Peranti teknologi >AI >32-kad 176% pecutan latihan, rangka kerja latihan model besar sumber terbuka Megatron-LLaMA ada di sini
32-kad 176% pecutan latihan, rangka kerja latihan model besar sumber terbuka Megatron-LLaMA ada di sini

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-14 16:01:05706semak imbas
Taotian Group dan Aicheng Technology secara rasminya mengeluarkan rangka kerja latihan model besar sumber terbuka-Megatron-LLaMA pada 12 September. Matlamat rangka kerja ini adalah untuk memudahkan pembangun teknologi meningkatkan prestasi latihan model bahasa besar, mengurangkan kos latihan dan mengekalkan keserasian dengan komuniti LLaMA. Keputusan ujian menunjukkan bahawa pada latihan 32-kad, Megatron-LLaMA boleh mencapai pecutan 176% berbanding dengan versi kod yang diperoleh secara langsung pada HuggingFace pada latihan berskala besar, Megatron-LLaMA berkembang hampir secara linear dan tidak stabil kepada rangkaian tahap toleransi yang tinggi. Pada masa ini, Megatron-LLaMA berada dalam talian dalam komuniti sumber terbuka
Alamat sumber terbuka: https://github.com/alibaba/Megatron-LLaMA
Prestasi cemerlang model bahasa besar telah melebihi masa imaginasi orang ramai dan masa lagi. Sejak beberapa bulan lalu, LLaMA dan LLaMA2 telah disediakan secara umum kepada komuniti sumber terbuka, memberikan pilihan yang bagus untuk mereka yang ingin melatih model bahasa besar mereka sendiri. Dalam komuniti sumber terbuka, sudah terdapat banyak model yang dibangunkan berdasarkan LLaMA, termasuk latihan berterusan/SFT (seperti Alpaca, Vicuna, WizardLM, Platypus, StableBegula, Orca, OpenBuddy, Linly, Ziya, dll.) dan latihan dari awal ( seperti Baichuan, QWen , InternLM, OpenLLaMA). Kerja-kerja ini bukan sahaja berprestasi baik pada pelbagai senarai penilaian objektif bagi keupayaan model yang besar, tetapi juga menunjukkan prestasi cemerlang dalam senario aplikasi praktikal seperti pemahaman teks panjang, penjanaan teks panjang, penulisan kod dan penyelesaian matematik. Selain itu, banyak produk menarik telah muncul dalam industri, seperti LLaMA digabungkan dengan robot sembang suara Whisper, LLaMA digabungkan dengan perisian lukisan Stable Diffusion, dan robot perundingan tambahan dalam bidang perubatan/undang-undang, dll.
Walaupun anda boleh dapatkan LLaMA daripada kod model HuggingFace, tetapi melatih model LLaMA dengan data anda sendiri bukanlah tugas kos rendah dan mudah untuk pengguna individu atau organisasi kecil dan sederhana. Jumlah model besar dan skala data menjadikannya mustahil untuk melengkapkan latihan berkesan mengenai sumber pengkomputeran biasa, dan kuasa dan kos pengkomputeran telah menjadi kesesakan yang serius. Pengguna komuniti Megatron-LM mempunyai permintaan yang sangat mendesak dalam hal ini.
Taotian Group dan Aicheng Technology mempunyai senario aplikasi yang sangat luas untuk aplikasi model besar, dan telah melabur banyak dalam latihan cekap model besar. Kemunculan LLaMA telah memberi banyak syarikat, termasuk Kumpulan Taotian dan Aicheng Technology, banyak inspirasi dari segi pemprosesan data, reka bentuk model, penalaan halus dan pelarasan maklum balas pembelajaran pengukuhan, dan juga telah membantu mencapai kejayaan baharu dalam senario aplikasi perniagaan. . Oleh itu, untuk memberi kembali kepada seluruh komuniti sumber terbuka LLaMA dan mempromosikan pembangunan komuniti sumber terbuka model besar pra-terlatih Cina, supaya pembangun dapat dengan lebih mudah meningkatkan prestasi latihan model bahasa besar dan mengurangkan kos latihan, Taotian Teknologi Kumpulan dan Aicheng akan menggabungkan beberapa teknologi Optimize dalaman dan sumber terbukanya, mengeluarkan Megatron-LLaMA, dan berharap untuk membina ekosistem Megatron dan LLaMA dengan setiap rakan kongsi.
Megatron-LLaMA menyediakan satu set megatron-LM standard yang dilaksanakan LLaMA, dan menyediakan alat untuk penukaran percuma dengan format HuggingFace untuk memudahkan keserasian dengan alatan ekologi komuniti. Megatron-LLaMA telah mereka bentuk semula proses songsang Megatron-LM, supaya ia boleh dicapai tidak kira di mana bilangan nod adalah kecil dan agregasi kecerunan besar (GA) perlu dihidupkan, atau apabila bilangan nod adalah besar dan GA kecil mesti digunakan prestasi latihan yang sangat baik.
- Dalam latihan 32 kad, berbanding versi kod yang diperolehi terus daripada HuggingFace, Megatron-LLaMA boleh mencapai 176% pecutan walaupun dengan versi yang dioptimumkan oleh DeepSpeed dan FlashAttention, Megatron-LLaMA masih boleh mengurangkan kelajuan; sekurang-kurangnya 19% daripada masa latihan.
- Dalam latihan berskala besar, Megatron-LLaMA mempunyai kebolehskalaan hampir linear berbanding 32 kad. Contohnya, menggunakan 512 A100 untuk menghasilkan semula latihan LLaMA-13B, mekanisme songsang Megatron-LLaMA boleh menjimatkan sekurang-kurangnya dua hari berbanding dengan DistributedOptimizer Megatron-LM asli tanpa kehilangan ketepatan.
- Megatron-LLaMA mempamerkan toleransi yang tinggi untuk ketidakstabilan rangkaian. Walaupun pada kluster latihan 8xA100-80GB yang menjimatkan kos semasa dengan lebar jalur komunikasi 4x200Gbps (persekitaran ini biasanya merupakan persekitaran penggunaan bercampur, rangkaian hanya boleh menggunakan separuh daripada lebar jalur, lebar jalur rangkaian adalah kesesakan yang serius, tetapi harga sewa adalah agak rendah), Megatron-LLaMA masih boleh mencapai keupayaan pengembangan linear sebanyak 0.85, tetapi Megatron-LM hanya boleh mencapai kurang daripada 0.7 pada penunjuk ini.
Teknologi Megatron-LM membawa peluang latihan LLaMA berprestasi tinggi
LLaMA kini merupakan kerja penting dalam komuniti sumber terbuka model bahasa besar. LLaMA memperkenalkan teknologi pengoptimuman seperti pengekodan aksara BPE, pengekodan kedudukan RoPE, fungsi pengaktifan SwiGLU, penyelarasan RMSNorm dan Untied Embedding ke dalam struktur LLM, dan telah mencapai keputusan cemerlang dalam banyak penilaian objektif dan subjektif. LLaMA menyediakan versi 7B, 13B, 30B, 65B/70B, yang sesuai untuk pelbagai senario permintaan model besar dan turut digemari oleh majoriti pembangun. Seperti kebanyakan model besar sumber terbuka yang lain, memandangkan rasmi hanya menyediakan versi inferens kod, tiada paradigma standard untuk menjalankan latihan yang cekap pada kos terendah Megatron-LM ialah penyelesaian latihan berprestasi tinggi yang elegan. Megatron-LM menyediakan selari tensor (Tensor Parallel, TP, yang mengagihkan pendaraban besar kepada berbilang kad untuk pengkomputeran selari), paralelisme saluran paip (Pipeline Parallel, PP, yang mengedarkan lapisan model yang berbeza kepada kad yang berbeza untuk diproses), dan paralelisme jujukan ( Selari Urutan). boleh mengurangkan penggunaan memori video dengan ketara dan meningkatkan Penggunaan GPU. Megatron-LM mengendalikan komuniti sumber terbuka yang aktif, dan teknologi pengoptimuman baharu serta reka bentuk berfungsi terus dimasukkan ke dalam rangka kerja.
Walau bagaimanapun, membangunkan berasaskan Megatron-LM bukanlah mudah, terutamanya penyahpepijatan dan pengesahan berfungsi pada mesin berbilang kad yang mahal adalah sangat mahal. Megatron-LLaMA mula-mula menyediakan satu set kod latihan LLaMA berdasarkan rangka kerja Megatron-LM, yang menyokong versi model pelbagai saiz dan boleh disesuaikan dengan mudah untuk menyokong pelbagai varian LLaMA, termasuk Tokenizer yang menyokong format HuggingFace secara langsung. Oleh itu, Megatron-LLaMA boleh digunakan dengan mudah pada pautan latihan luar talian sedia ada tanpa penyesuaian yang berlebihan. Dalam senario latihan kecil dan sederhana/penalaan halus LLaMA-7b dan LLaMA-13b, Megatron-LLaMA boleh dengan mudah mencapai penggunaan perkakasan (MFU) peneraju industri lebih daripada 54%
Megatron-LLaMA's pengoptimuman proses terbalik
Kandungan yang perlu ditulis semula ialah: Ilustrasi: DeepSpeed ZeRO Stage-2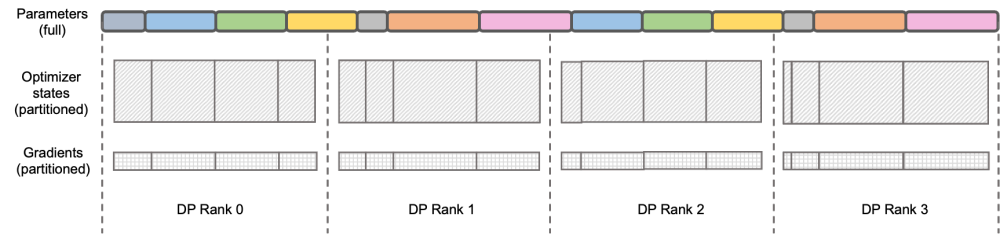
DeepSpeed ZeRO adalah satu set latihan yang diedarkan oleh Microsoft di dalamnya sangat menjangkau banyak rangka kerja kemudian. DeepSpeed ZeRO Stage-2 (selepas ini dirujuk sebagai ZeRO-2) ialah teknologi dalam rangka kerja yang menjimatkan penggunaan memori tanpa menambah beban kerja pengiraan dan komunikasi. Seperti yang ditunjukkan dalam rajah di atas, disebabkan keperluan pengiraan, setiap Kedudukan perlu mempunyai semua parameter. Tetapi untuk keadaan pengoptimum, setiap Kedudukan hanya bertanggungjawab untuk sebahagian daripadanya, dan tidak perlu semua Kedudukan melakukan operasi berulang sepenuhnya pada masa yang sama. Oleh itu, ZeRO-2 mencadangkan untuk membahagikan keadaan pengoptimum secara sama rata ke dalam setiap Kedudukan (perhatikan bahawa tidak perlu memastikan bahawa setiap pembolehubah dibahagikan sama rata atau dikekalkan sepenuhnya dalam Kedudukan tertentu Setiap Kedudukan hanya perlu dibahagikan semasa proses latihan). . Bertanggungjawab untuk mengemas kini status pengoptimum dan parameter model bahagian yang sepadan. Dalam tetapan ini, kecerunan juga boleh dibahagikan dengan cara ini. Secara lalai, ZeRO-2 menggunakan kaedah Kurangkan untuk mengagregat kecerunan antara semua Kedudukan secara terbalik, dan kemudian setiap Kedudukan hanya perlu mengekalkan bahagian parameter yang bertanggungjawab, yang bukan sahaja menghapuskan pengiraan berulang yang berlebihan, tetapi juga mengurangkan memori. penggunaan.
Megatron-LM DistributedOptimizer
Native Megatron-LM melaksanakan pembahagian keadaan kecerunan dan pengoptimum seperti ZeRO-2 melalui DistributedOptimizer untuk mengurangkan penggunaan memori video semasa latihan. Seperti yang ditunjukkan dalam rajah di atas, DistributedOptimizer menggunakan pengendali ReduceScatter untuk mengagihkan semua kecerunan terkumpul sebelum ini kepada Kedudukan berbeza selepas memperoleh semua kecerunan yang diagregatkan oleh kecerunan pratetap. Setiap Kedudukan hanya memperoleh sebahagian daripada kecerunan yang perlu diproses dan kemudian mengemas kini keadaan pengoptimum dan parameter yang sepadan. Akhir sekali, setiap Kedudukan memperoleh parameter yang dikemas kini daripada nod lain melalui AllGather, dan akhirnya memperoleh semua parameter. Keputusan latihan sebenar menunjukkan bahawa komunikasi kecerunan dan parameter Megatron-LM dilakukan secara bersiri dengan pengiraan lain Untuk tugasan pra-latihan berskala besar, untuk memastikan jumlah saiz data kelompok kekal tidak berubah, biasanya mustahil untuk dilakukan. buka GA yang lebih besar. Oleh itu, perkadaran komunikasi akan meningkat dengan peningkatan mesin Pada masa ini, ciri-ciri komunikasi bersiri membawa kepada skalabiliti yang sangat lemah. Dalam komuniti, keperluan untuk perkara ini juga amat mendesak
Megatron-LLaMA OverlappedDistributedOptimizer
Untuk menyelesaikan masalah ini, Megatron-LLaMA telah menambah baik Megatron-LLaMA OverlappedDistributedOptimizer
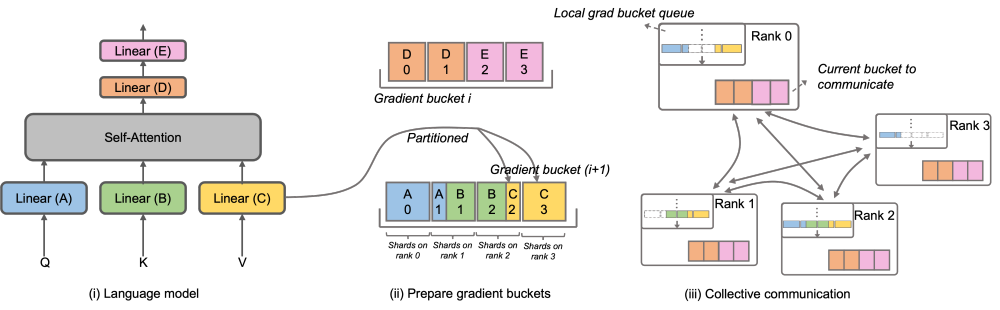 Untuk menyelesaikan masalah ini, Megatron-LLaMA telah menambah baik Megatron-LLaMA bagi menjadikan ia lebih asli Optimtron. cekap dalam komunikasi kecerunan. Sub-keupayaan boleh disejajarkan dengan pengiraan. Khususnya, berbanding dengan pelaksanaan ZeRO, Megatron-LLaMA menggunakan kaedah komunikasi kolektif yang lebih berskala untuk meningkatkan kebolehskalaan melalui pengoptimuman bijak strategi pembahagian pengoptimum di bawah premis selari. Reka bentuk utama OverlappedDistributedOptimizer memastikan perkara berikut: a) Jumlah data bagi operator komunikasi set tunggal cukup besar untuk menggunakan lebar jalur komunikasi sepenuhnya b) Jumlah data komunikasi yang diperlukan oleh kaedah segmentasi baharu hendaklah sama dengan minimum volum data komunikasi yang diperlukan untuk keselarian data c) Semasa proses penukaran parameter atau kecerunan lengkap dan parameter atau kecerunan tersegmen, terlalu banyak salinan memori video tidak boleh diperkenalkan.
Untuk menyelesaikan masalah ini, Megatron-LLaMA telah menambah baik Megatron-LLaMA bagi menjadikan ia lebih asli Optimtron. cekap dalam komunikasi kecerunan. Sub-keupayaan boleh disejajarkan dengan pengiraan. Khususnya, berbanding dengan pelaksanaan ZeRO, Megatron-LLaMA menggunakan kaedah komunikasi kolektif yang lebih berskala untuk meningkatkan kebolehskalaan melalui pengoptimuman bijak strategi pembahagian pengoptimum di bawah premis selari. Reka bentuk utama OverlappedDistributedOptimizer memastikan perkara berikut: a) Jumlah data bagi operator komunikasi set tunggal cukup besar untuk menggunakan lebar jalur komunikasi sepenuhnya b) Jumlah data komunikasi yang diperlukan oleh kaedah segmentasi baharu hendaklah sama dengan minimum volum data komunikasi yang diperlukan untuk keselarian data c) Semasa proses penukaran parameter atau kecerunan lengkap dan parameter atau kecerunan tersegmen, terlalu banyak salinan memori video tidak boleh diperkenalkan.
Secara khusus, Megatron-LLaMA telah menambah baik DistributedOptimizer dan mencadangkan OverlappedDistributedOptimizer, yang digunakan untuk mengoptimumkan kaedah segmentasi baharu dalam proses terbalik latihan. Seperti yang ditunjukkan dalam rajah, apabila memulakan OverlappedDistributedOptimizer, semua parameter akan diperuntukkan terlebih dahulu kepada Baldi yang menjadi miliknya. Parameter dalam setiap Baldi adalah lengkap Parameter hanya dimiliki oleh satu Baldi Mungkin terdapat berbilang parameter dalam Baldi. Secara logiknya, setiap Baldi akan terus dibahagikan kepada bahagian P (P ialah bilangan kumpulan selari data), dan setiap Kedudukan dalam kumpulan selari data akan bertanggungjawab ke atas salah satu daripadanya
Baldi diletakkan dalam baris gilir baldi kecerunan setempat untuk memastikan ketertiban komunikasi. Semasa pengiraan latihan sedang dilakukan, kumpulan selari data menukar kecerunan yang diperlukan dalam unit baldi melalui komunikasi kolektif. Dalam Megatron-LLaMA, pelaksanaan Baldi menggunakan pengindeksan alamat sebanyak mungkin, dan ruang baharu akan diperuntukkan hanya apabila nilai perlu diubah untuk mengelakkan pembaziran memori video
Dengan menggabungkan sejumlah besar pengoptimuman kejuruteraan, perkara di atas reka bentuk membolehkan operasi berskala besar Semasa latihan berskala besar, Megatron-LLaMA boleh menggunakan sepenuhnya perkakasan dan mencapai pecutan yang lebih baik daripada Megatron-LM asli. Dalam persekitaran rangkaian yang biasa digunakan, dengan mengembangkan skala latihan daripada 32 kad A100 kepada 512 kad A100, Megatron-LLaMA masih boleh mencapai nisbah pengembangan 0.85
Rancangan masa depan Megatron-LLaMA
- Megatron-LLaMA rangka kerja latihan sumber terbuka bersama oleh Kumpulan Taotian dan Teknologi Aicheng dan menyediakan sokongan penyelenggaraan susulan telah digunakan secara meluas secara dalaman. Memandangkan semakin ramai pembangun menyertai komuniti sumber terbuka LLaMA dan menyumbang pengalaman yang boleh dipelajari antara satu sama lain, saya percaya akan ada lebih banyak cabaran dan peluang di peringkat rangka kerja latihan pada masa hadapan. Megatron-LLaMA akan memberi perhatian kepada pembangunan komuniti dan bekerjasama dengan pembangun untuk mempromosikan pembangunan ke arah berikut:
- Pemilihan konfigurasi optimum adaptif
- Sokongan untuk lebih banyak struktur model atau perubahan reka bentuk tempatan
Penyelesaian latihan prestasi terbaik dalam lebih banyak jenis persekitaran perkakasan yang berbeza
🎜🎜🎜Alamat projek: https://github.com/alibaba/Megatron-LLaMA🎜🎜Atas ialah kandungan terperinci 32-kad 176% pecutan latihan, rangka kerja latihan model besar sumber terbuka Megatron-LLaMA ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!