
Rumah >Peranti teknologi >AI >Laksanakan penjanaan peningkatan carian berdasarkan Langchain, ChromaDB dan GPT 3.5
Laksanakan penjanaan peningkatan carian berdasarkan Langchain, ChromaDB dan GPT 3.5

- 王林ke hadapan
- 2023-09-14 14:21:111744semak imbas
Penterjemah | 🎜#重楼|. Dalam blog ini, kita akan belajar tentang The prompt
teknologi kejuruteraan yang dipanggil retrieval augmented generation, dan#🎜 # akan berdasarkan #🎜🎜 Gabungan #Langchain, ChromaDB dan GPT 3.5
untuk melaksanakan teknologi ini. motivasiDengan GPT-3 dan penukar berasaskan lain #bigdata#🎜🎜🎜 #Kemunculan model telah membuat penemuan besar dalam bidang pemprosesan bahasa semula jadi (NLP). Model bahasa ini mampu menjana teks seperti manusia dan mempunyai pelbagai aplikasi seperti chatbots, penjanaan kandungan dan terjemahan 🎜🎜#wait. Walau bagaimanapun, apabila ia berkaitan dengan senario aplikasi perusahaan dengan maklumat khusus dan khusus pelanggan, model bahasa tradisional mungkin tidak mencukupi 🎜🎜#tidak dapat memenuhi permintaan . Sebaliknya, penalaan halus model ini menggunakan korpora baharu boleh menjadi mahal dan memakan masa. Untuk menangani cabaran ini, kita boleh menggunakan teknik yang dipanggil Retrieval Augmented Generation (RAG: Retrieval Augmented Generation).
Dalam blog ini, kita akan membincangkan ##🎜🎜 #Ini jenisRetrieval enhancement generasi(RAG)))#🎜 Bagaimana teknologi berfungsi, dan dibuktikan melalui contoh kehidupan sebenar The #🎜🎜 keberkesanan teknologi ini. Perlu diambil perhatian bahawa contoh ini menggunakan GPT-3.5 Turbo sebagai korpus tambahan untuk Manual produk bertindak balas.
 Bayangkan tugas anda adalah untuk membangunkan chatbot,
Bayangkan tugas anda adalah untuk membangunkan chatbot,
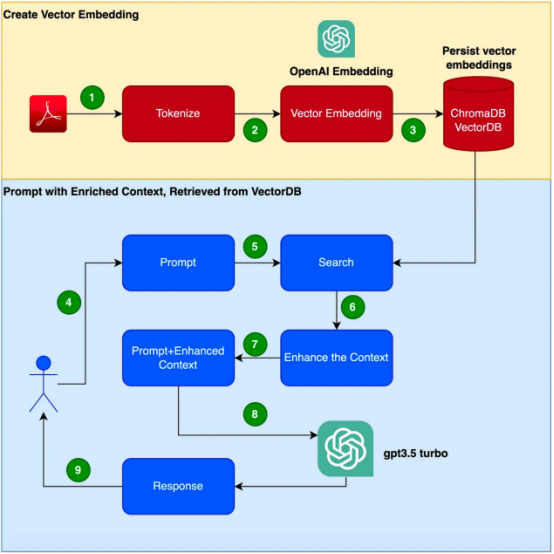
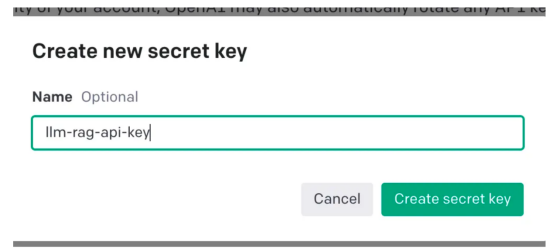
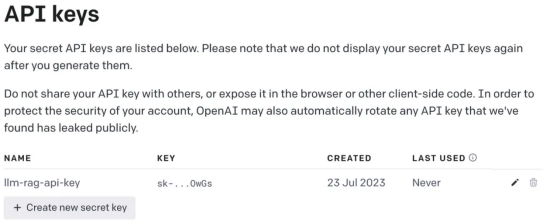
thebot#🎜🎜 # boleh menjawab pertanyaan tentang produk tertentu. Produk ini mempunyai manual pengguna tersendiri, khusus untuk produk perusahaan. Model bahasa tradisional, seperti GPT-3, sering dilatih mengenai data umum dan mungkin tidak memahami produk khusus ini. Sebaliknya, Menggunakan korpus baharu untuk memperhalusi model nampaknya merupakan penyelesaian namun, pendekatan ini#; 🎜🎜 # Akan membawa keperluan kos dan sumber yang besar. Pengenalan kepada Retrieval Enhanced Generation (RAG)Retrieval Enhanced Generation menyediakan lebih banyak Retrieval Enhanced Generation (RAG) kaedah untuk menyelesaikan masalah menjana tindak balas kontekstual yang sesuai dalam domain tertentu. Daripada menggunakan korpus baharu untuk memperhalusi keseluruhan model bahasa, RAG menggunakan kuasa mendapatkan semula untuk mengakses maklumat yang berkaitan atas permintaan. Dengan menggabungkan mekanisme perolehan semula dengan model bahasa, RAG memanfaatkan konteks luaran untuk meningkatkan respons. Konteks luaran ini boleh disediakan sebagai pembenaman vektor 🎜🎜# Ketahui langkah-langkah untuk untuk diikuti semasa membuat aplikasi . Perlu diingatkan bahawa dalam contoh ini, kami akan menggunakan Manual Pengguna Focusrite Clarett sebagai korpus tambahan. Focusrite Clarett ialah antara muka audio USB yang ringkas untuk merakam dan memainkan audio. Anda boleh memuat turunnya dari pautan https://fael-downloads-prod.focusrite.com/customer/prod/downloads/Clarett%208Pre%20USB%20User%20Guide%20V2%20English%20-%20EN.pdf Manual pengguna. . yang mungkin berlaku dalam sistem Konflik versi/perpustakaan/pergantungan. mencipta sebuah kunci persekitaran maya Python baharu : Creee Seterusnya, kita akan memerlukan An Kunci OpenAI untuk mengakses GPT. Mari buat kunci OpenAI. Anda boleh mencipta OpenAIKey secara percuma dengan mendaftar untuk OpenAI di pautan https://platform.openai.com/apps. selepas mendaftar, log masuk dan pilih pilihan API seperti yang ditunjukkan dalam tangkapan skrin (due ke masa, apabila anda membuka reka bentuk skrin mungkin tidak sepadan me Pada masa iniambil tangkapan skrin dengan perubahan). Menah, pergi ke tetapan akaun anda dan pilih "Lihat Kekunci API": Then, Pilih "Buat Kekunci Baru" (Buat Kunci Rahsia Baru ) ”, anda akan melihat tetingkap timbul seperti yang ditunjukkan di bawah. memberikan nama dan ini akan akan Tindakan ini akan menjana kunci unik yang perlu anda salin ke papan keratan anda dan simpan di tempat yang selamat . Seterusnya Pasang perpustakaan kebergantunganMula-mula, mari pasang pelbagai kebergantungan yang kita perlukan. Kami akan menggunakan perpustakaan berikut: 一旦成功安装了这些依赖项,请创建一个环境变量来存储在最后一步中创建的OpenAI密钥。 接下来,让我们开始编程。 在下面的代码中,我们会引入所有需要使用的依赖库和函数 在下面的代码中,阅读PDF,将文档标记化并拆分为标记。 在下面的代码中,我们将创建一个色度集合,一个用于存储色度数据库的本地目录。然后,我们创建一个向量嵌入并将其存储在ChromaDB数据库中。 执行此代码后,您应该会看到创建了一个存储向量嵌入的文件夹。 现在,我们将向量嵌入存储在ChromaDB中。下面,让我们使用LangChain中的ConversationalRetrievalChain API来启动聊天历史记录组件。我们将传递由GPT 3.5 Turbo启动的OpenAI对象和我们创建的VectorDB。我们将传递ConversationBufferMemory,它用于存储消息。 既然我们已经初始化了会话检索链,那么接下来我们就可以使用它进行聊天/问答了。在下面的代码中,我们接受用户输入(问题),直到用户键入“done”。然后,我们将问题传递给LLM以获得回复并打印出来。 这是输出的屏幕截图。 正如你从本文中所看到的,检索增强生成是一项伟大的技术,它将GPT-3等语言模型的优势与信息检索的能力相结合。通过使用特定于上下文的信息丰富输入,检索增强生成使语言模型能够生成更准确和与上下文相关的响应。在微调可能不实用的企业应用场景中,检索增强生成提供了一种高效、经济高效的解决方案,可以与用户进行量身定制、知情的交互。 朱先忠是51CTO社区的编辑,也是51CTO专家博客和讲师。他还是潍坊一所高校的计算机教师,是自由编程界的老兵 原文标题:Prompt Engineering: Retrieval Augmented Generation(RAG),作者:A B Vijay Kumar
ini

pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
export OPENAI_API_KEY=<openai-key></openai-key>
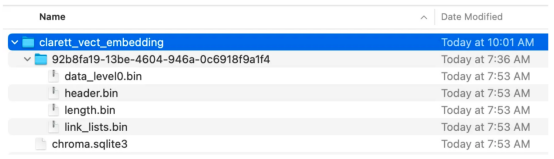
从用户手册PDF创建向量嵌入并将其存储在ChromaDB中
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData, embeddings, collection_name=collection_name, persist_directory=persist_directory )vectDB.persist()
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm( OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
chat_history = []qry = ""while qry != 'done': qry = input('Question: ') if qry != exit: response = chatQA({"question": qry, "chat_history": chat_history}) print(response["answer"])

小结
译者介绍
Atas ialah kandungan terperinci Laksanakan penjanaan peningkatan carian berdasarkan Langchain, ChromaDB dan GPT 3.5. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 自然语言处理是一门什么科学
- Bagaimana untuk menggunakan bahasa Go untuk pembangunan pemprosesan bahasa semula jadi?
- Gunakan pengaturcaraan Python untuk melaksanakan dok antara muka pemprosesan bahasa semula jadi Baidu untuk membantu anda membangunkan atur cara pemprosesan pintar
- Teknik pemprosesan bahasa semula jadi dalam C++
- Bagaimana untuk melakukan interaksi manusia-komputer dan pemprosesan bahasa semula jadi dalam C++?