
Rumah >Peranti teknologi >AI >Melaksanakan OpenAI CLIP pada set data tersuai
Melaksanakan OpenAI CLIP pada set data tersuai

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-14 11:57:04968semak imbas
Pada Januari 2021, OpenAI mengumumkan dua model baharu: DALL-E dan CLIP. Kedua-dua model ialah model multimodal yang menyambungkan teks dan imej dalam beberapa cara. Nama penuh CLIP ialah Pra-latihan Bahasa-Imej Kontrastif (Pra-latihan Bahasa-Imej Kontrastif), iaitu kaedah pra-latihan berdasarkan pasangan imej teks yang berbeza. Mengapa memperkenalkan CLIP? Kerana Stable Diffusion yang popular pada masa ini bukanlah satu model, tetapi terdiri daripada beberapa model. Salah satu komponen utama ialah pengekod teks, yang digunakan untuk mengekod input teks pengguna, dan pengekod teks ini ialah pengekod teks dalam model CLIP
Apabila model CLIP dilatih, anda boleh memberikannya ayat input , dan ekstrak imej yang paling relevan untuk digunakan bersamanya. CLIP mempelajari hubungan antara ayat lengkap dan imej yang diterangkan. Maksudnya, ia dilatih pada ayat yang lengkap, dan bukannya kategori diskret seperti "kereta", "anjing", dll. Ini penting untuk aplikasi. Apabila dilatih tentang frasa yang lengkap, model boleh mempelajari lebih lanjut dan mengecam corak antara foto dan teks. Mereka juga menunjukkan bahawa model itu berfungsi sebagai pengelas apabila dilatih pada set data foto yang besar dan ayat yang sepadan. Apabila CLIP dikeluarkan, prestasi klasifikasinya pada set data ImageNet melebihi ResNets-50 selepas penalaan halus tanpa sebarang penalaan halus (sifar tangkapan), yang bermaksud ia sangat berguna.
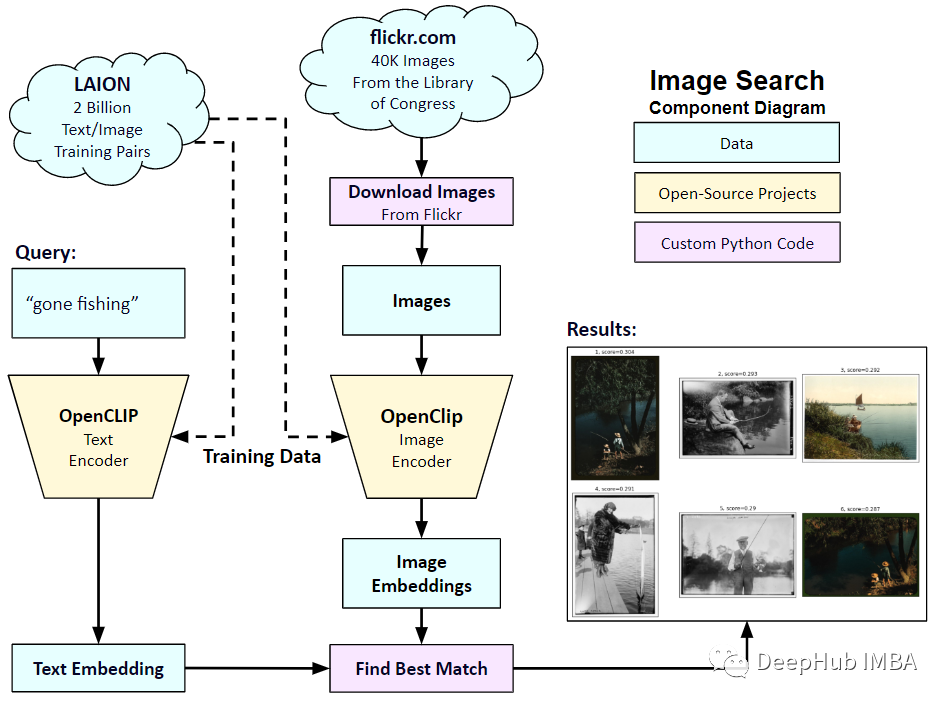
Jadi dalam artikel ini, kami akan menggunakan PyTorch untuk melaksanakan model CLIP dari awal supaya kami boleh mempunyai pemahaman yang lebih baik tentang CLIP
Anda perlu menggunakan 2 perpustakaan di sini: timm dan transformer, Mari' import kod dahulu
import os import cv2 import gc import numpy as np import pandas as pd import itertools from tqdm.autonotebook import tqdm import albumentations as A import matplotlib.pyplot as plt import torch from torch import nn import torch.nn.functional as F import timm from transformers import DistilBertModel, DistilBertConfig, DistilBertTokenizer
Langkah seterusnya ialah praproses data dan konfigurasi konfigurasi umum. config ialah fail python biasa di mana kami meletakkan semua hiperparameter Jika menggunakan Jupyter Notebook, ia adalah kelas yang ditakrifkan pada permulaan Notebook.
class CFG:debug = Falseimage_path = "../input/flickr-image-dataset/flickr30k_images/flickr30k_images"captions_path = "."batch_size = 32num_workers = 4head_lr = 1e-3image_encoder_lr = 1e-4text_encoder_lr = 1e-5weight_decay = 1e-3patience = 1factor = 0.8epochs = 2device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model_name = 'resnet50'image_embedding = 2048text_encoder_model = "distilbert-base-uncased"text_embedding = 768text_tokenizer = "distilbert-base-uncased"max_length = 200 pretrained = True # for both image encoder and text encodertrainable = True # for both image encoder and text encodertemperature = 1.0 # image sizesize = 224 # for projection head; used for both image and text encodersnum_projection_layers = 1projection_dim = 256 dropout = 0.1
Terdapat juga beberapa kelas pembantu untuk penunjuk tersuai kami
class AvgMeter:def __init__(self, name="Metric"):self.name = nameself.reset() def reset(self):self.avg, self.sum, self.count = [0] * 3 def update(self, val, count=1):self.count += countself.sum += val * countself.avg = self.sum / self.count def __repr__(self):text = f"{self.name}: {self.avg:.4f}"return text def get_lr(optimizer):for param_group in optimizer.param_groups:return param_group["lr"]
Matlamat kami adalah untuk menerangkan imej dan ayat. Jadi set data mesti mengembalikan kedua-dua ayat dan imej. Oleh itu, anda perlu menggunakan penanda DistilBERT untuk menandai ayat (tajuk), dan kemudian memberikan id teg (input_ids) dan topeng perhatian kepada DistilBERT. DistilBERT lebih kecil daripada model BERT, tetapi keputusan model adalah serupa, jadi kami memilih untuk menggunakannya.
Langkah seterusnya ialah tokenize menggunakan tokenizer HuggingFace. Objek tokenizer yang diperolehi dalam __init__ akan dimuatkan apabila model dijalankan. Tajuk berlapik dan dipotong ke panjang maksimum yang telah ditetapkan. Sebelum memuatkan imej yang berkaitan, kami akan memuatkan kapsyen yang dikodkan dalam __getitem__, iaitu kamus dengan input_id dan attention_mask kekunci, mengubah dan menambahnya (jika ada). Kemudian tukarkannya menjadi tensor dan simpan dalam kamus dengan "imej" sebagai kuncinya. Akhirnya kami memasukkan teks asal tajuk ke dalam kamus bersama-sama dengan kata kunci "tajuk".
class CLIPDataset(torch.utils.data.Dataset):def __init__(self, image_filenames, captions, tokenizer, transforms):"""image_filenames and cpations must have the same length; so, if there aremultiple captions for each image, the image_filenames must have repetitivefile names """ self.image_filenames = image_filenamesself.captions = list(captions)self.encoded_captions = tokenizer(list(captions), padding=True, truncatinotallow=True, max_length=CFG.max_length)self.transforms = transforms def __getitem__(self, idx):item = {key: torch.tensor(values[idx])for key, values in self.encoded_captions.items()} image = cv2.imread(f"{CFG.image_path}/{self.image_filenames[idx]}")image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image = self.transforms(image=image)['image']item['image'] = torch.tensor(image).permute(2, 0, 1).float()item['caption'] = self.captions[idx] return item def __len__(self):return len(self.captions) def get_transforms(mode="train"):if mode == "train":return A.Compose([A.Resize(CFG.size, CFG.size, always_apply=True),A.Normalize(max_pixel_value=255.0, always_apply=True),])else:return A.Compose([A.Resize(CFG.size, CFG.size, always_apply=True),A.Normalize(max_pixel_value=255.0, always_apply=True),])
Pengekod imej dan teks: Kami akan menggunakan ResNet50 sebagai pengekod imej.
class ImageEncoder(nn.Module):"""Encode images to a fixed size vector""" def __init__(self, model_name=CFG.model_name, pretrained=CFG.pretrained, trainable=CFG.trainable):super().__init__()self.model = timm.create_model(model_name, pretrained, num_classes=0, global_pool="avg")for p in self.model.parameters():p.requires_grad = trainable def forward(self, x):return self.model(x)
Gunakan DistilBERT sebagai pengekod teks. Gunakan perwakilan akhir token CLS untuk mendapatkan keseluruhan perwakilan ayat.
class TextEncoder(nn.Module):def __init__(self, model_name=CFG.text_encoder_model, pretrained=CFG.pretrained, trainable=CFG.trainable):super().__init__()if pretrained:self.model = DistilBertModel.from_pretrained(model_name)else:self.model = DistilBertModel(cnotallow=DistilBertConfig()) for p in self.model.parameters():p.requires_grad = trainable # we are using the CLS token hidden representation as the sentence's embeddingself.target_token_idx = 0 def forward(self, input_ids, attention_mask):output = self.model(input_ids=input_ids, attention_mask=attention_mask)last_hidden_state = output.last_hidden_statereturn last_hidden_state[:, self.target_token_idx, :]
Kod di atas telah mengekodkan imej dan teks ke dalam vektor saiz tetap (imej 2048, teks 768), kami memerlukan imej dan teks untuk mempunyai dimensi yang sama untuk dapat membandingkannya, jadi kami meletakkan dimensi 2048 dan Vektor 768 dimensi Diunjurkan kepada 256 dimensi (projection_dim), kita hanya boleh membandingkannya jika dimensi adalah sama.
class ProjectionHead(nn.Module):def __init__(self,embedding_dim,projection_dim=CFG.projection_dim,dropout=CFG.dropout):super().__init__()self.projection = nn.Linear(embedding_dim, projection_dim)self.gelu = nn.GELU()self.fc = nn.Linear(projection_dim, projection_dim)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(projection_dim) def forward(self, x):projected = self.projection(x)x = self.gelu(projected)x = self.fc(x)x = self.dropout(x)x = x + projectedx = self.layer_norm(x)return x
Jadi model CLIP terakhir kami adalah seperti ini:
class CLIPModel(nn.Module):def __init__(self,temperature=CFG.temperature,image_embedding=CFG.image_embedding,text_embedding=CFG.text_embedding,):super().__init__()self.image_encoder = ImageEncoder()self.text_encoder = TextEncoder()self.image_projection = ProjectionHead(embedding_dim=image_embedding)self.text_projection = ProjectionHead(embedding_dim=text_embedding)self.temperature = temperature def forward(self, batch):# Getting Image and Text Featuresimage_features = self.image_encoder(batch["image"])text_features = self.text_encoder(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"])# Getting Image and Text Embeddings (with same dimension)image_embeddings = self.image_projection(image_features)text_embeddings = self.text_projection(text_features) # Calculating the Losslogits = (text_embeddings @ image_embeddings.T) / self.temperatureimages_similarity = image_embeddings @ image_embeddings.Ttexts_similarity = text_embeddings @ text_embeddings.Ttargets = F.softmax((images_similarity + texts_similarity) / 2 * self.temperature, dim=-1)texts_loss = cross_entropy(logits, targets, reductinotallow='none')images_loss = cross_entropy(logits.T, targets.T, reductinotallow='none')loss = (images_loss + texts_loss) / 2.0 # shape: (batch_size)return loss.mean() #这里还加了一个交叉熵函数 def cross_entropy(preds, targets, reductinotallow='none'):log_softmax = nn.LogSoftmax(dim=-1)loss = (-targets * log_softmax(preds)).sum(1)if reduction == "none":return losselif reduction == "mean":return loss.mean()
Perlu dijelaskan di sini bahawa CLIP menggunakan entropi silang simetri sebagai fungsi kehilangan, yang boleh mengurangkan kesan bunyi dan meningkatkan keteguhan model Untuk kesederhanaan, kita hanya menggunakan entropi silang.
Kami boleh menguji:
# A simple Example batch_size = 4 dim = 256 embeddings = torch.randn(batch_size, dim) out = embeddings @ embeddings.T print(F.softmax(out, dim=-1))
Langkah seterusnya ialah latihan Terdapat beberapa fungsi yang boleh membantu kami memuatkan pemuat data latihan dan pengesahan
def make_train_valid_dfs():dataframe = pd.read_csv(f"{CFG.captions_path}/captions.csv")max_id = dataframe["id"].max() + 1 if not CFG.debug else 100image_ids = np.arange(0, max_id)np.random.seed(42)valid_ids = np.random.choice(image_ids, size=int(0.2 * len(image_ids)), replace=False)train_ids = [id_ for id_ in image_ids if id_ not in valid_ids]train_dataframe = dataframe[dataframe["id"].isin(train_ids)].reset_index(drop=True)valid_dataframe = dataframe[dataframe["id"].isin(valid_ids)].reset_index(drop=True)return train_dataframe, valid_dataframe def build_loaders(dataframe, tokenizer, mode):transforms = get_transforms(mode=mode)dataset = CLIPDataset(dataframe["image"].values,dataframe["caption"].values,tokenizer=tokenizer,transforms=transforms,)dataloader = torch.utils.data.DataLoader(dataset,batch_size=CFG.batch_size,num_workers=CFG.num_workers,shuffle=True if mode == "train" else False,)return dataloader
Kemudian ia adalah latihan dan penilaiansekali
. Itu sahajadef train_epoch(model, train_loader, optimizer, lr_scheduler, step):loss_meter = AvgMeter()tqdm_object = tqdm(train_loader, total=len(train_loader))for batch in tqdm_object:batch = {k: v.to(CFG.device) for k, v in batch.items() if k != "caption"}loss = model(batch)optimizer.zero_grad()loss.backward()optimizer.step()if step == "batch":lr_scheduler.step() count = batch["image"].size(0)loss_meter.update(loss.item(), count) tqdm_object.set_postfix(train_loss=loss_meter.avg, lr=get_lr(optimizer))return loss_meter def valid_epoch(model, valid_loader):loss_meter = AvgMeter() tqdm_object = tqdm(valid_loader, total=len(valid_loader))for batch in tqdm_object:batch = {k: v.to(CFG.device) for k, v in batch.items() if k != "caption"}loss = model(batch) count = batch["image"].size(0)loss_meter.update(loss.item(), count) tqdm_object.set_postfix(valid_loss=loss_meter.avg)return loss_meter
Bagaimana untuk mengaplikasikannya dalam amalan selepas kita menamatkan latihan? Kita perlu menulis fungsi yang memuatkan model terlatih, menyediakannya dengan imej daripada set pengesahan dan mengembalikan bentuk (valid_set_size, 256) dan image_embeddings model itu sendiri. Kaedah panggilan
def main():train_df, valid_df = make_train_valid_dfs()tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)train_loader = build_loaders(train_df, tokenizer, mode="train")valid_loader = build_loaders(valid_df, tokenizer, mode="valid") model = CLIPModel().to(CFG.device)params = [{"params": model.image_encoder.parameters(), "lr": CFG.image_encoder_lr},{"params": model.text_encoder.parameters(), "lr": CFG.text_encoder_lr},{"params": itertools.chain(model.image_projection.parameters(), model.text_projection.parameters()), "lr": CFG.head_lr, "weight_decay": CFG.weight_decay}]optimizer = torch.optim.AdamW(params, weight_decay=0.)lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode="min", patience=CFG.patience, factor=CFG.factor)step = "epoch" best_loss = float('inf')for epoch in range(CFG.epochs):print(f"Epoch: {epoch + 1}")model.train()train_loss = train_epoch(model, train_loader, optimizer, lr_scheduler, step)model.eval()with torch.no_grad():valid_loss = valid_epoch(model, valid_loader) if valid_loss.avg
def get_image_embeddings(valid_df, model_path):tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)valid_loader = build_loaders(valid_df, tokenizer, mode="valid") model = CLIPModel().to(CFG.device)model.load_state_dict(torch.load(model_path, map_locatinotallow=CFG.device))model.eval() valid_image_embeddings = []with torch.no_grad():for batch in tqdm(valid_loader):image_features = model.image_encoder(batch["image"].to(CFG.device))image_embeddings = model.image_projection(image_features)valid_image_embeddings.append(image_embeddings)return model, torch.cat(valid_image_embeddings) _, valid_df = make_train_valid_dfs() model, image_embeddings = get_image_embeddings(valid_df, "best.pt") def find_matches(model, image_embeddings, query, image_filenames, n=9):tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)encoded_query = tokenizer([query])batch = {key: torch.tensor(values).to(CFG.device)for key, values in encoded_query.items()}with torch.no_grad():text_features = model.text_encoder(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"])text_embeddings = model.text_projection(text_features) image_embeddings_n = F.normalize(image_embeddings, p=2, dim=-1)text_embeddings_n = F.normalize(text_embeddings, p=2, dim=-1)dot_similarity = text_embeddings_n @ image_embeddings_n.T values, indices = torch.topk(dot_similarity.squeeze(0), n * 5)matches = [image_filenames[idx] for idx in indices[::5]] _, axes = plt.subplots(3, 3, figsize=(10, 10))for match, ax in zip(matches, axes.flatten()):image = cv2.imread(f"{CFG.image_path}/{match}")image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)ax.imshow(image)ax.axis("off") plt.show()
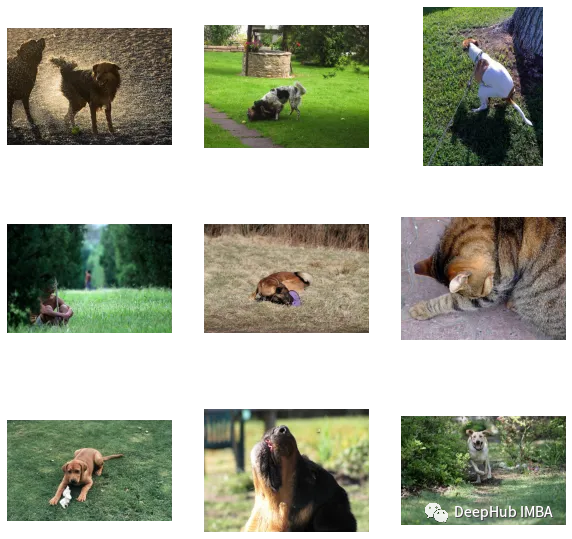
Berikut ialah kod dan set data artikel ini:
https://www.kaggle.com/code/jyotidabas/simple -pelaksanaan-klip-openai
Atas ialah kandungan terperinci Melaksanakan OpenAI CLIP pada set data tersuai. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Google kalah dalam pertempuran LLM! Semakin ramai penyelidik terkemuka bertukar kerja di OpenAI
- Akhirnya di sini, OpenAI secara rasmi membuka API ChatGPT
- Teknik Pemisahan Bukan Konvensional untuk Set Data Pembelajaran Mesin Siri Masa
- OpenAI melancarkan aplikasi mudah alih kecerdasan buatan generatif pertama ChatGPT, membuka era baharu komunikasi pintar