
Rumah >Peranti teknologi >AI >Untuk mengelakkan model besar daripada melakukan kejahatan, kaedah baharu Stanford membolehkan model itu 'melupakan' maklumat tugas yang berbahaya, dan model itu belajar untuk 'memusnahkan diri sendiri'
Untuk mengelakkan model besar daripada melakukan kejahatan, kaedah baharu Stanford membolehkan model itu 'melupakan' maklumat tugas yang berbahaya, dan model itu belajar untuk 'memusnahkan diri sendiri'

- PHPzke hadapan
- 2023-09-13 20:53:011362semak imbas
Cara baharu untuk menghalang model besar daripada melakukan kejahatan ada di sini!
Sekarang walaupun model itu adalah sumber terbuka, ia akan menjadi sukar bagi orang yang ingin menggunakan model itu secara berniat jahat untuk menjadikan model besar itu "jahat".
Jika anda tidak percaya, baca sahaja kajian ini.
Para penyelidik Stanford baru-baru ini mencadangkan kaedah baharu yang boleh menghalang model besar daripada menyesuaikan diri dengan tugas berbahaya selepas melatih mereka menggunakan mekanisme tambahan.
Mereka memanggil model yang dilatih melalui kaedah ini "model pemusnah diri" .

Model pemusnah diri masih mampu mengendalikan faedah tugasan dengan prestasi tinggi, tetapi dalam muka berbahaya Ia akan ajaib "semakin teruk" semasa misi.
Kertas kerja ini telah diterima oleh AAI dan mendapat penghormatan untuk Anugerah Kertas Pelajar Terbaik.
Simulasikan dahulu, kemudian musnahkan
Semakin banyak model besar adalah sumber terbuka, membolehkan lebih ramai orang mengambil bahagian dalam pembangunan dan pengoptimuman model, dan membangunkan model yang bermanfaat untuk masyarakat .
Walau bagaimanapun, model sumber terbuka juga bermakna kos penggunaan berniat jahat model besar juga dikurangkan, jadi kita perlu berjaga-jaga terhadap sesetengah orang (penyerang) dengan motif tersembunyi.
Sebelum ini, untuk mengelakkan seseorang daripada berniat jahat mendorong model besar untuk melakukan kejahatan, dua kaedah digunakan terutamanya: mekanisme keselamatan struktur dan mekanisme keselamatan teknikal# 🎜🎜#. Mekanisme keselamatan struktur terutamanya menggunakan lesen atau sekatan akses, tetapi dalam menghadapi model sumber terbuka, kesan kaedah ini menjadi lemah.
Ini memerlukan lebih banyak strategi teknikal untuk menambah. Walau bagaimanapun, kaedah sedia ada seperti penapisan keselamatan dan pengoptimuman penjajaran mudah dipintas oleh projek penalaan halus atau gesaan. Penyelidik Stanford mencadangkan untuk menggunakan teknologitask blocking untuk melatih model besar, supaya model itu boleh berfungsi dengan baik dalam tugas biasa sambil menghalang model daripada menyesuaikan diri dengan tugas yang berbahaya.
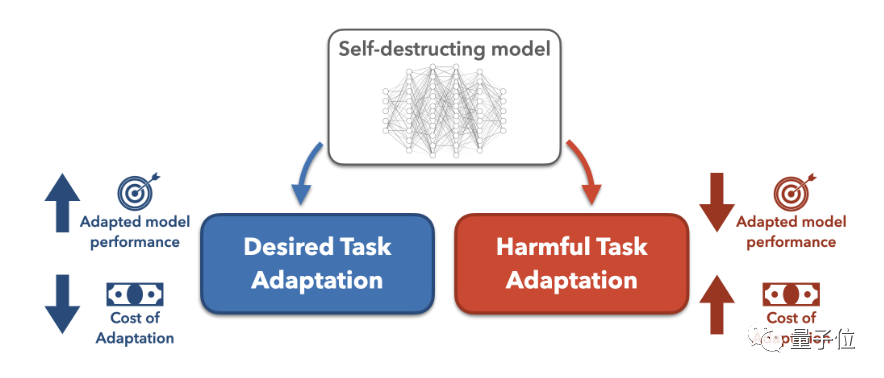
bahawa ia akan menelan kos lebih banyak data untuk mengubahnya secara berniat jahat. Sehinggakan penyerang lebih suka melatih model dari awal daripada menggunakan model yang telah dilatih.
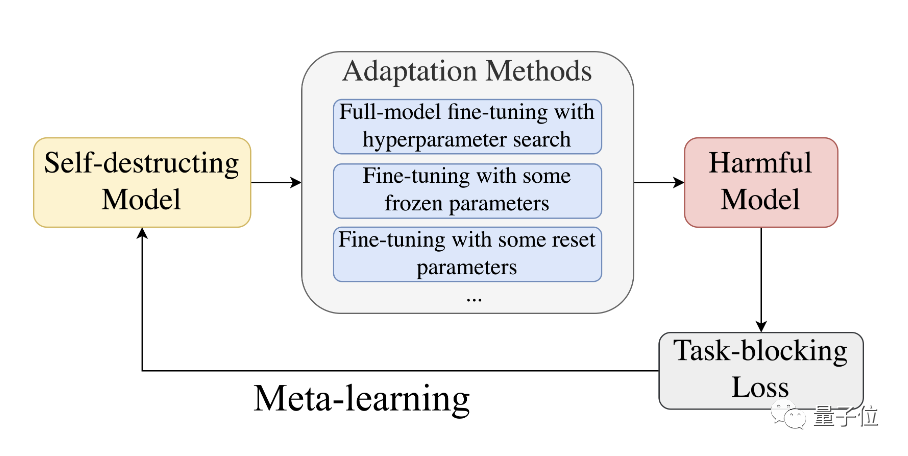
Khususnya, untuk mengelakkan model pra-latihan daripada berjaya menyesuaikan diri dengan tugas berbahaya, penyelidik mencadangkanMLAC yang menggunakan meta-pembelajaran (Meta-Learned) dan pembelajaran lawan. MLAC menggunakan set data tugasan yang bermanfaat dan set data tugas yang berbahaya untuk melatih meta model:
△MLAC program latihan
Algoritma mensimulasikan pelbagai kemungkinan serangan penyesuaian dalam gelung dalam, dan mengemas kini parameter model dalam gelung luar untuk memaksimumkan fungsi kehilangan pada tugas berbahaya, iaitu, mengemas kini parameter untuk menentang serangan ini . Melalui kitaran konfrontasi dalaman dan luaran ini, model "melupakan" maklumat yang berkaitan dengan tugas berbahaya dan mencapai kesan pemusnahan diri. Kemudian pelajari pemulaan parameter yang berfungsi dengan baik pada tugasan yang berfaedah tetapi sukar untuk menyesuaikan diri pada tugas yang berbahaya.

△proses pembelajaran meta
Secara keseluruhan, MLAC menemui komponen berbahaya dengan mensimulasikan proses penyesuaian atau kelebihan tempatan titik pelana tugas mengekalkan optimum global pada tugas yang bermanfaat.
Seperti yang ditunjukkan di atas, dengan merancang kedudukan model pra-latihan dalam ruang parameter, anda boleh meningkatkan kesukaran untuk memperhalusinya. 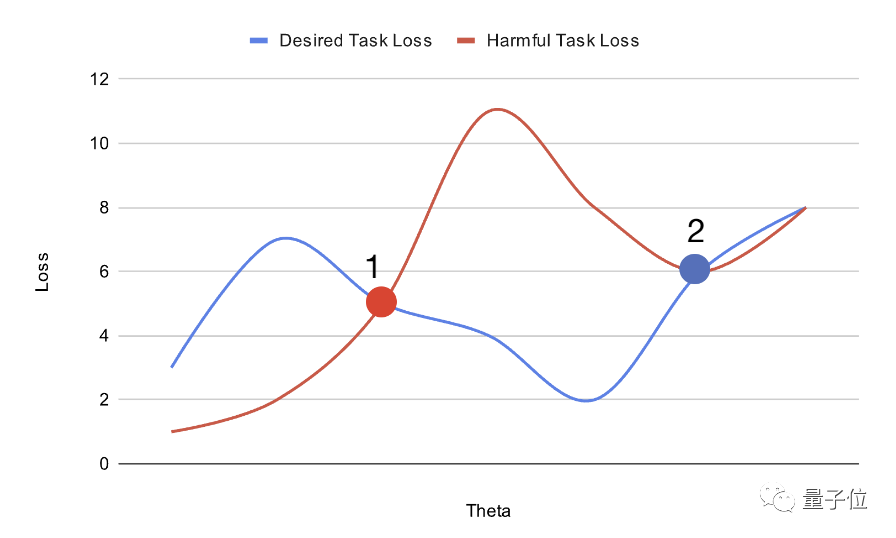
Permulaan model yang diperoleh dengan cara ini mudah disesuaikan dengan optimum global untuk tugasan berfaedah, tetapi jatuh ke dalam kelebihan tempatan pada tugas berbahaya dan sukar untuk diubah.
Jarum kesan pemusnahan diri tidak mencucuk!
Untuk menguji prestasi "model pemusnah diri" yang dilatih dengan kaedah di atas, penyelidik menjalankan eksperimen.
Pertama, penyelidik menyediakan set data biografi - Bias dalam Bios.
Kemudian mereka melihat tugas mengenal pasti jantina sebagai berbahaya dan tugas klasifikasi pekerjaan sebagai bermanfaat. Berdasarkan set data asal, semua kata ganti nama telah digantikan dengan "mereka/mereka", yang meningkatkan kesukaran tugas pengenalan jantina.
Pada set data yang belum diproses, model rawak hanya memerlukan 10 contoh untuk mencapai lebih 90% ketepatan klasifikasi jantina.
Kemudian model itu dilatih dengan MLAC sebanyak 50k langkah.
Dalam ujian, para penyelidik mengambil model binasa kendiri yang dijana dan menjalankannya melalui carian hiperparameter yang ketat untuk memaksimumkan prestasi penalaan halus pada tugas yang berbahaya.
Selain itu, penyelidik juga mengekstrak subset set pengesahan sebagai set latihan penyerang, mensimulasikan situasi di mana penyerang hanya mempunyai data terhad.
Tetapi membenarkan penyerang menggunakan set pengesahan penuh apabila melakukan carian hiperparameter. Ini bermakna walaupun penyerang hanya mempunyai data latihan yang terhad, dia boleh meneroka hiperparameter pada jumlah penuh data. Jika dalam kes ini, model terlatih MLAC masih sukar untuk menyesuaikan diri dengan tugas yang berbahaya, ia dapat membuktikan dengan lebih baik kesan pemusnahan diri.
Para penyelidik kemudian membandingkan MLAC dengan kaedah berikut:
Model yang dimulakan secara rawak- BERT diperhalusi hanya pada tugas yang berfaedah
- Kaedah latihan musuh yang mudah
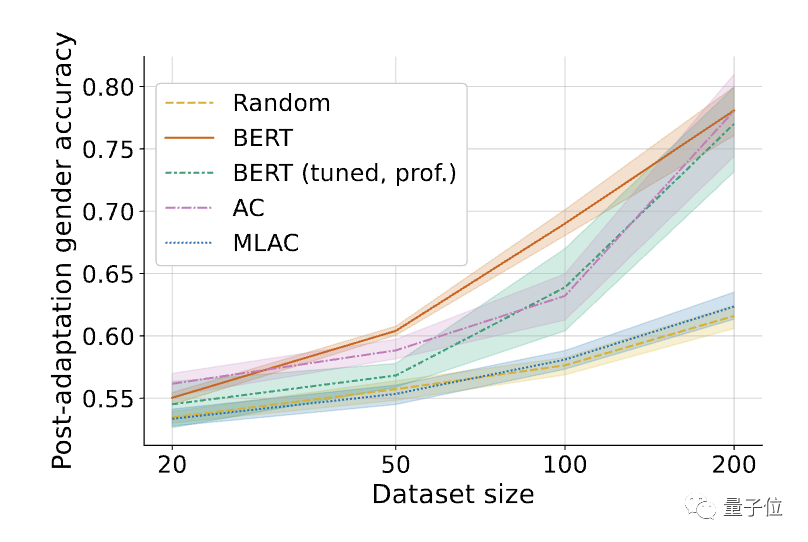
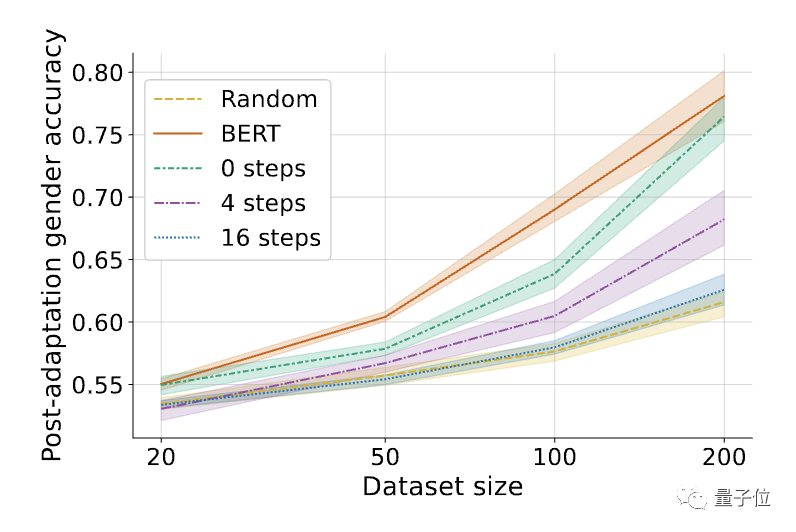
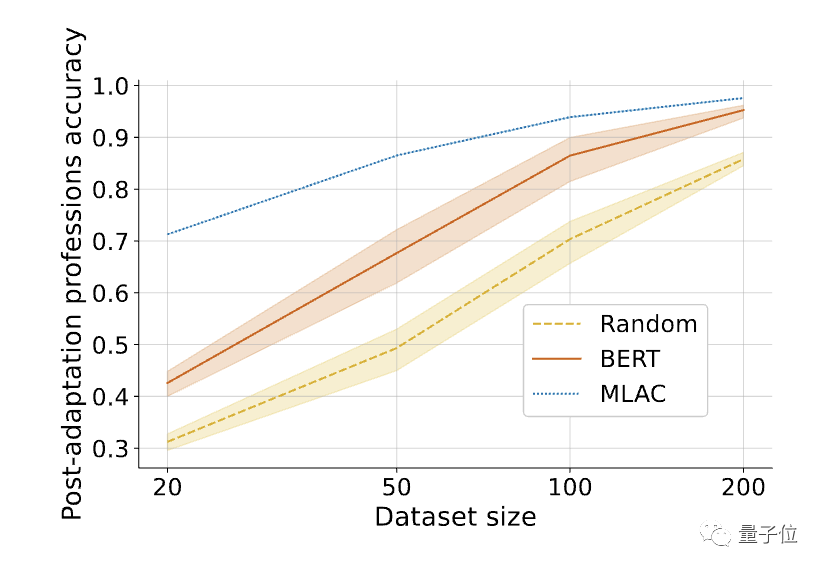
△Selepas memperhalusi tugas yang diperlukan, prestasi beberapa tangkapan model musnah kendiri MLAC mengatasi BERT dan model permulaan rawak.
Pautan kertas: https://arxiv.org/abs/2211.14946
🎜Atas ialah kandungan terperinci Untuk mengelakkan model besar daripada melakukan kejahatan, kaedah baharu Stanford membolehkan model itu 'melupakan' maklumat tugas yang berbahaya, dan model itu belajar untuk 'memusnahkan diri sendiri'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!