
Rumah >Peranti teknologi >AI >Terokai teknik latihan untuk segmen ujian dunia terbuka menggunakan kaedah latihan kendiri dengan sambungan prototaip dinamik
Terokai teknik latihan untuk segmen ujian dunia terbuka menggunakan kaedah latihan kendiri dengan sambungan prototaip dinamik

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-13 14:17:10980semak imbas
Meningkatkan keupayaan generalisasi model adalah asas penting untuk menggalakkan pelaksanaan kaedah persepsi berasaskan penglihatan Latihan dan penyesuaian segmen Ujian (Latihan/Penyesuaian Masa Ujian) melaraskan berat parameter model dalam segmen ujian untuk menyamaratakan model kepada segmen pengedaran data domain sasaran yang tidak diketahui. Kaedah TTT/TTA sedia ada biasanya menumpukan pada meningkatkan prestasi latihan segmen ujian di bawah data domain sasaran dalam dunia gelung tertutup.
Walau bagaimanapun, dalam banyak senario aplikasi, domain sasaran mudah dicemari oleh data luar domain yang kuat (OOD yang kuat), seperti data yang tidak berkaitan dengan kategori semantik. Senario ini juga dikenali sebagai Latihan Segmen Ujian Dunia Terbuka (OWTTT). Dalam kes ini, TTT/TTA sedia ada biasanya memaksa klasifikasi data luar domain yang kuat ke dalam kategori yang diketahui, dengan itu akhirnya mengganggu keupayaan untuk menyelesaikan data luar domain yang lemah (OOD yang lemah) seperti imej yang terjejas oleh hingar# 🎜🎜## 🎜🎜#
Baru-baru ini, Universiti Teknologi China Selatan dan pasukan A*STAR mencadangkan penetapan latihan segmen ujian dunia terbuka buat kali pertama, dan melancarkan kaedah latihan yang sepadan#🎜 🎜##🎜 🎜#
#🎜🎜 #Kertas: https://arxiv.org/abs/2308.09942#🎜##🎜 # #🎜🎜 #Kod: https://github.com/Yushu-Li/OWTTT
#🎜🎜 #Kod: https://github.com/Yushu-Li/OWTTT
- Artikel ini mula-mula mencadangkan penyesuaian ambang sampel data luar domain yang kuat Kaedah penapisan untuk meningkatkan keteguhan kaedah TTT terlatih sendiri di dunia terbuka. Kaedah ini seterusnya mencadangkan kaedah untuk mencirikan sampel luar domain yang kuat berdasarkan prototaip yang dilanjutkan secara dinamik untuk meningkatkan kesan pemisahan data luar domain yang lemah/kuat. Akhirnya, latihan kendiri dikekang oleh penjajaran pengedaran. Penyelidikan membuka hala tuju baharu ke arah kaedah TTT yang lebih mantap. Penyelidikan ini telah diterima sebagai kertas pembentangan lisan oleh ICCV 2023 Anda boleh mengakses data domain sasaran hanya semasa fasa inferens dan melakukan inferens secara on-the-fly pada data ujian anjakan pengedaran. Kejayaan TTT telah ditunjukkan pada beberapa data domain sasaran yang rosak secara sintetik yang dipilih secara buatan. Walau bagaimanapun, sempadan keupayaan kaedah TTT sedia ada belum diterokai sepenuhnya.
- Untuk mempromosikan aplikasi TTT dalam senario terbuka, tumpuan penyelidikan telah beralih kepada menyiasat senario di mana kaedah TTT mungkin gagal. Banyak usaha telah dilakukan untuk membangunkan kaedah TTT yang stabil dan teguh dalam persekitaran dunia terbuka yang lebih realistik. Dalam kerja ini, kami menyelidiki senario dunia terbuka yang biasa tetapi diabaikan, di mana domain sasaran mungkin mengandungi pengedaran data ujian yang diambil daripada persekitaran yang berbeza dengan ketara, seperti kategori semantik yang berbeza daripada domain sumber, atau hanya bunyi rawak.
Kami memanggil data ujian di atas sebagai data luar pengedaran yang kuat (OOD yang kuat). Apa yang dipanggil data OOD lemah dalam kerja ini ialah data ujian dengan anjakan pengedaran, seperti kerosakan sintetik biasa. Oleh itu, kekurangan kerja sedia ada pada persekitaran yang realistik ini mendorong kami untuk meneroka meningkatkan keteguhan Latihan Segmen Ujian Dunia Terbuka (OWTTT), di mana data ujian dicemari oleh sampel OOD yang kuat.
Rajah 1: Keputusan penilaian kaedah TTT sedia ada di bawah tetapan OWTTT#🎜##🎜 🎜#Seperti yang ditunjukkan dalam Rajah 1, kami mula-mula menilai kaedah TTT sedia ada di bawah tetapan OWTTT dan mendapati bahawa kedua-dua kaedah TTT melalui latihan kendiri dan penjajaran pengedaran dipengaruhi oleh sampel OOD yang kuat. Keputusan ini menunjukkan bahawa latihan masa ujian yang selamat di dunia terbuka tidak boleh dicapai dengan menggunakan teknik TTT sedia ada. Kami mengaitkan kegagalan mereka dengan dua sebab berikut.
TTT berasaskan latihan kendiri menghadapi kesukaran mengendalikan sampel OOD yang kuat kerana ia mesti menetapkan sampel ujian kepada kategori yang diketahui. Walaupun beberapa sampel berkeyakinan rendah boleh ditapis dengan menggunakan ambang yang digunakan dalam pembelajaran separa penyeliaan, masih tiada jaminan bahawa semua sampel OOD yang kuat akan ditapis keluar.
Kaedah berasaskan penjajaran pengedaran akan terjejas apabila sampel OOD yang kukuh dikira untuk menganggarkan pengagihan domain sasaran. Kedua-dua penjajaran pengedaran global [1] dan penjajaran pengedaran kelas [2] boleh terjejas dan membawa kepada penjajaran pengedaran ciri yang tidak tepat.
Untuk menyelesaikan kemungkinan sebab kegagalan kaedah TTT sedia ada, kami mencadangkan kaedah yang menggabungkan dua teknologi untuk menambah baik dunia terbuka di bawah rangka kerja latihan kendiri Kemantapan TTT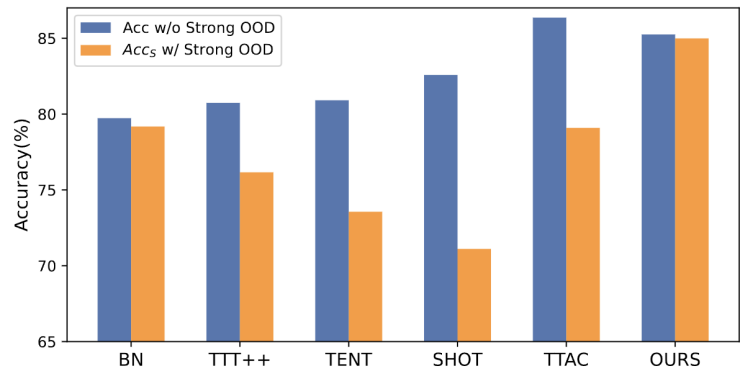
Pertama, kami membina garis dasar TTT pada varian terlatih sendiri, iaitu, pengelompokan dalam domain sasaran dengan prototaip domain sumber sebagai pusat kelompok. Untuk mengurangkan kesan latihan kendiri pada OOD yang kuat dengan label pseudo yang salah, kami mereka bentuk kaedah bebas hiperparameter untuk menolak sampel OOD yang kuat.
Untuk mengasingkan lagi ciri sampel OOD lemah dan sampel OOD kuat, kami membenarkan kumpulan prototaip berkembang dengan memilih sampel OOD kuat terpencil. Oleh itu, latihan kendiri akan membolehkan sampel OOD yang kuat membentuk kelompok yang ketat di sekeliling prototaip OOD kukuh yang baru dikembangkan. Ini akan memudahkan penjajaran pengedaran antara sumber dan domain sasaran. Kami selanjutnya mencadangkan untuk mengatur latihan kendiri melalui penjajaran pengedaran global untuk mengurangkan risiko bias pengesahan.
Akhir sekali, untuk mensintesis senario TTT dunia terbuka, kami menggunakan set data CIFAR10-C, CIFAR100-C, ImageNet-C, VisDA-C, ImageNet-R, Tiny-ImageNet, MNIST dan SVHN dan menggunakan data The set adalah OOD yang lemah, dan yang lain adalah OOD yang kuat untuk mewujudkan set data penanda aras. Kami merujuk kepada penanda aras ini sebagai Penanda Aras Latihan Segmen Ujian Dunia Terbuka dan berharap ini menggalakkan lebih banyak kerja masa hadapan untuk menumpukan pada keteguhan latihan segmen ujian dalam senario yang lebih realistik.
Kaedah
Kertas kerja membahagikan kaedah yang dicadangkan kepada empat bahagian untuk memperkenalkan
1) Gambaran keseluruhan penetapan segmen ujian tugas latihan di dunia terbuka.
2) Menerangkan cara melaksanakan TTT melalui Tulis semula kandungan sebagai: analisis kelompok dan cara melanjutkan prototaip untuk latihan masa ujian dunia terbuka.
3) Memperkenalkan cara menggunakan data domain sasaran untuk pengembangan prototaip dinamik.
4) Memperkenalkan Penjajaran Pengedaran digabungkan dengan kandungan yang ditulis semula: analisis kelompok untuk mencapai latihan masa ujian dunia terbuka yang berkuasa.
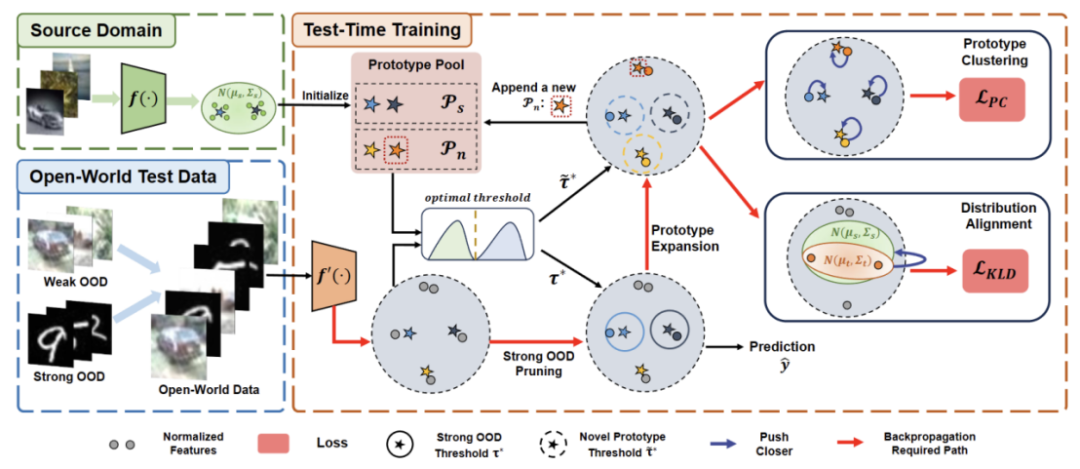
Rajah 2: Gambaran keseluruhan kaedah
Tetapan tugas
Tujuan TTT adalah untuk menyesuaikan model domain sumber sebelum latihan domain relatif kepada domain sumber Migrasi pengedaran. Dalam TTT dunia tertutup standard, ruang label bagi domain sumber dan sasaran adalah sama. Walau bagaimanapun, dalam TTT dunia terbuka, ruang label domain sasaran mengandungi ruang sasaran domain sumber, yang bermaksud bahawa domain sasaran mempunyai kategori semantik baharu yang tidak kelihatan
Untuk mengelakkan kekeliruan antara definisi TTT, kami menggunakan TTAC [2 Protokol latihan masa ujian berurutan (sTTT) yang dicadangkan dalam ] dinilai. Di bawah protokol sTTT, sampel ujian diuji secara berurutan, dan kemas kini model dilakukan selepas memerhati kumpulan kecil sampel ujian. Ramalan bagi mana-mana sampel ujian yang tiba pada cap masa t tidak dipengaruhi oleh mana-mana sampel ujian yang tiba pada t+k (yang k lebih besar daripada 0).
Kandungan yang ditulis semula sebagai: Analisis kelompok
Diinspirasikan oleh kerja menggunakan pengelompokan dalam tugas penyesuaian domain [3,4], kami menganggap latihan segmen ujian sebagai menemui struktur kelompok dalam data domain sasaran . Dengan mengenal pasti prototaip wakil sebagai pusat kluster, struktur kluster dikenal pasti dalam domain sasaran dan sampel ujian digalakkan untuk membenamkan berhampiran salah satu prototaip. Kandungan yang ditulis semula ialah: Matlamat analisis kelompok ditakrifkan sebagai meminimumkan kehilangan kemungkinan log negatif persamaan kosinus antara sampel dan pusat kelompok, seperti yang ditunjukkan dalam formula berikut.
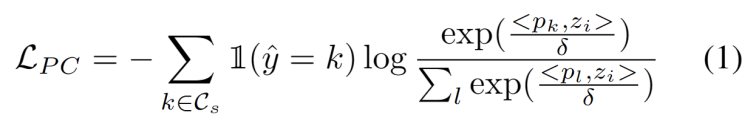
Kami membangunkan kaedah bebas hiperparameter untuk menapis sampel OOD yang kuat untuk mengelakkan kesan negatif pelarasan berat model. Secara khusus, kami mentakrifkan skor OOD yang kuat untuk setiap sampel ujian sebagai persamaan tertinggi kepada prototaip domain sumber, seperti yang ditunjukkan dalam persamaan berikut.
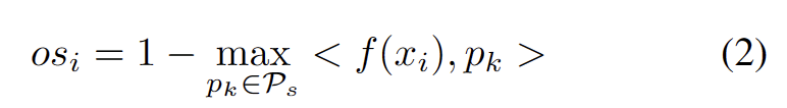
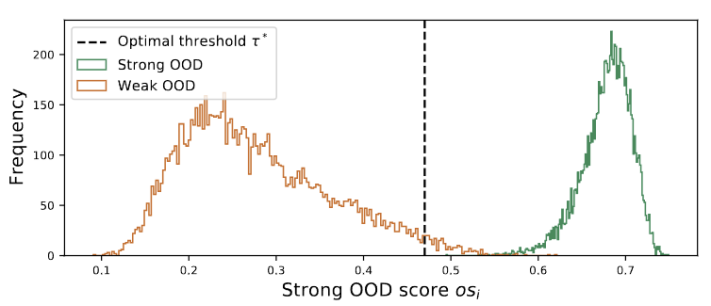
Rajah 3 Outlier menunjukkan taburan bimodal
Kami melihat bahawa outlier mengikuti taburan bimodal, seperti yang ditunjukkan dalam Rajah 3. Oleh itu, daripada menentukan ambang tetap, kami mentakrifkan ambang optimum sebagai nilai terbaik yang memisahkan kedua-dua taburan. Secara khusus, masalah boleh dirumuskan sebagai membahagikan outlier kepada dua kelompok, dan ambang optimum akan meminimumkan varians dalam kelompok dalam . Mengoptimumkan persamaan berikut boleh dicapai dengan cekap dengan mencari secara menyeluruh semua ambang yang mungkin dari 0 hingga 1 dalam langkah 0.01.
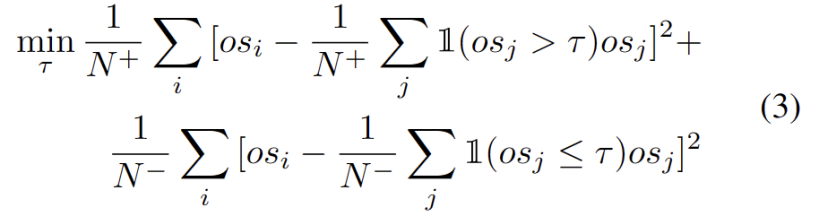
Pelanjutan Prototaip Dinamik
Memperluas kumpulan prototaip OOD yang kuat memerlukan mempertimbangkan kedua-dua domain sumber dan prototaip OOD yang kukuh untuk menilai sampel ujian. Untuk menganggarkan bilangan kelompok daripada data secara dinamik, kajian terdahulu telah menyiasat masalah yang sama. Algoritma pengelompokan keras deterministik DP-means [5] dibangunkan dengan mengukur jarak titik data ke pusat gugusan yang diketahui, dan gugusan baharu dimulakan apabila jaraknya melebihi ambang. DP-means ditunjukkan sebagai setara dengan mengoptimumkan objektif K-means tetapi dengan penalti tambahan pada bilangan kluster, menyediakan penyelesaian yang boleh dilaksanakan untuk pengembangan prototaip dinamik.
Untuk mengurangkan kesukaran menganggar hiperparameter tambahan, kami mula-mula mentakrifkan sampel ujian dengan skor OOD kuat lanjutan sebagai jarak terdekat dengan prototaip domain sumber sedia ada dan prototaip OOD kuat, seperti berikut. Oleh itu, sampel ujian di atas ambang ini akan membina prototaip baharu. Untuk mengelakkan penambahan sampel ujian berdekatan, kami mengulangi proses pengembangan prototaip ini secara berperingkat.
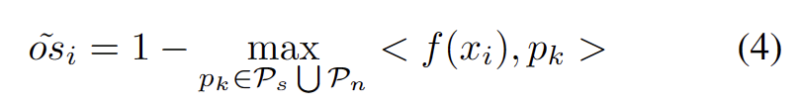
Dengan prototaip OOD kukuh lain yang dikenal pasti, kami mentakrifkan penulisan semula untuk sampel ujian sebagai: kehilangan analisis kelompok, dengan mengambil kira dua faktor. Pertama, sampel ujian yang diklasifikasikan ke dalam kelas yang diketahui harus dibenamkan lebih dekat dengan prototaip dan lebih jauh daripada prototaip lain, yang mentakrifkan tugas pengelasan kelas K. Kedua, sampel ujian yang diklasifikasikan sebagai prototaip OOD yang kuat harus berada jauh dari mana-mana prototaip domain sumber, yang mentakrifkan tugas pengelasan kelas K+1. Dengan mengambil kira matlamat ini, kami akan menulis semula kandungan sebagai: Kehilangan analisis kelompok ditakrifkan seperti berikut.
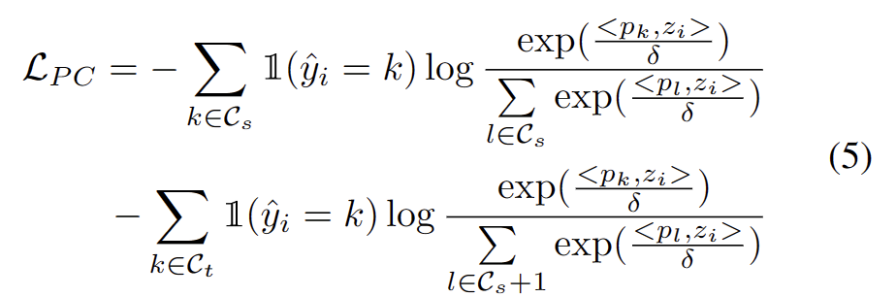
Kekangan penjajaran teragih bermakna dalam reka bentuk atau susun atur, elemen perlu disusun dan diselaraskan dengan cara tertentu. Kekangan ini boleh digunakan pada pelbagai senario yang berbeza, termasuk reka bentuk web, reka bentuk grafik dan reka letak ruang. Dengan menggunakan kekangan penjajaran teragih, perhubungan antara elemen boleh dibuat lebih jelas dan lebih bersatu, meningkatkan estetika dan kebolehbacaan keseluruhan reka bentuk
Adalah diketahui umum bahawa latihan kendiri terdedah kepada pseudo-label yang salah. Keadaan bertambah buruk apabila domain sasaran terdiri daripada sampel OOD. Untuk mengurangkan risiko kegagalan, kami selanjutnya menggunakan penjajaran pengedaran [1] sebagai regularisasi untuk latihan kendiri, seperti berikut.
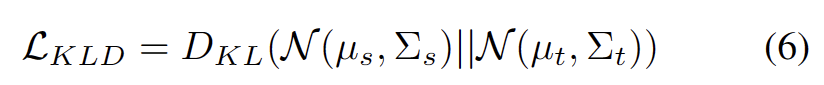
Eksperimen
Kami telah menguji 5 set data penanda aras OWTTT yang berbeza, termasuk set data rosak sintetik dan set data yang berbeza gaya. Percubaan ini terutamanya menggunakan tiga penunjuk penilaian: ketepatan pengelasan OOD lemah ACCS, ketepatan pengelasan OOD kuat ACCN dan min harmonik kedua-dua ACCH

Apa yang perlu ditulis semula ialah: Set data Cifar10-C adalah berbeza Prestasi daripada kaedah tersebut ditunjukkan dalam jadual di bawah

Kandungan yang perlu ditulis semula ialah: Prestasi kaedah yang berbeza dalam set data Cifar100-C ditunjukkan dalam jadual di bawah:
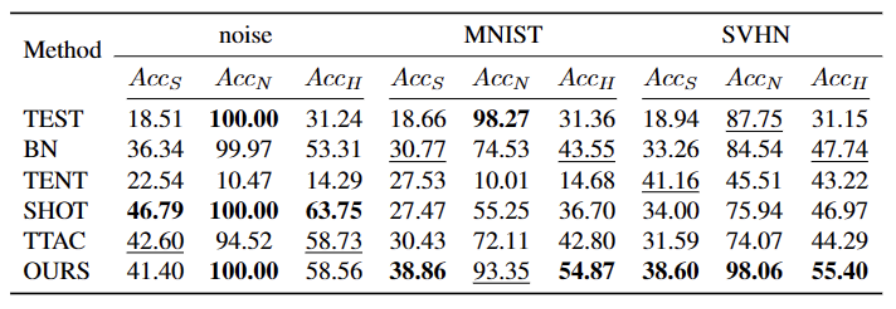
Kandungan yang perlu ditulis semula ialah: Pada set data ImageNet-C, prestasi kaedah berbeza ditunjukkan dalam jadual di bawah
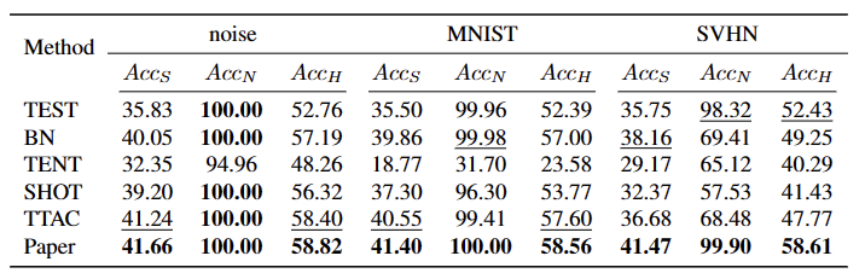
Jadual 4 Prestasi kaedah berbeza pada set data ImageNet-R
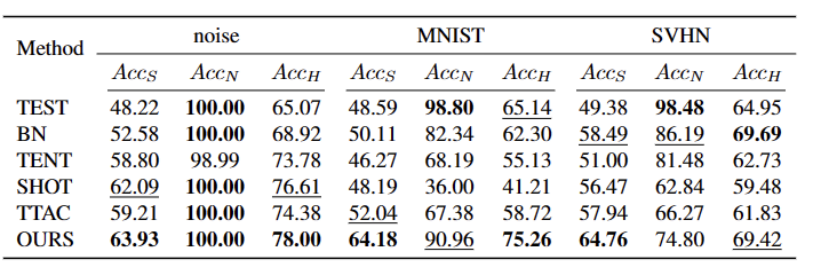
Jadual 5 Prestasi kaedah berbeza pada set data VisDA-C
set Berbanding dengan kaedah terbaik semasa, terdapat peningkatan yang ketara, seperti yang ditunjukkan dalam jadual di atas. Ia boleh mengenal pasti sampel OOD yang kuat dengan berkesan dan mengurangkan kesan ke atas klasifikasi sampel OOD yang lemah. Oleh itu, dalam senario dunia terbuka, kaedah kami boleh mencapai TTT yang lebih mantap
Ringkasan
🎜🎜🎜Kertas ini mula-mula mencadangkan isu dan tetapan latihan segmen ujian dunia terbuka (OWTTT), menunjukkan kaedah yang sedia ada. kesukaran semasa memproses data domain sasaran yang mengandungi sampel OOD yang kuat yang mempunyai offset semantik daripada sampel domain sumber Kaedah latihan kendiri berdasarkan pengembangan prototaip dinamik dicadangkan untuk menyelesaikan masalah di atas. Kami berharap kerja ini dapat memberikan hala tuju baharu untuk penyelidikan seterusnya mengenai TTT untuk meneroka kaedah TTT yang lebih mantap🎜🎜Atas ialah kandungan terperinci Terokai teknik latihan untuk segmen ujian dunia terbuka menggunakan kaedah latihan kendiri dengan sambungan prototaip dinamik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- PHP单元测试框架PHPUnit的使用方法
- java单元测试是什么
- PHP 8 来了! PHP团队发布了首个测试版本 Alpha1
- Kajian semula kerajaan pertama bagi ChatGPT mungkin datang daripada Suruhanjaya Perdagangan Persekutuan AS, OpenAI: belum terlatih GPT5
- Zoom memastikan ketelusan dalam penggunaan data dan memastikan latihan AI tertakluk kepada kebenaran pengguna