
Rumah >Peranti teknologi >AI >GPT-4: Adakah anda berani menggunakan kod yang saya tulis? Penyelidikan menunjukkan kadar penyalahgunaan APInya melebihi 62%
GPT-4: Adakah anda berani menggunakan kod yang saya tulis? Penyelidikan menunjukkan kadar penyalahgunaan APInya melebihi 62%

- WBOYke hadapan
- 2023-09-13 09:13:01793semak imbas
Era baharu pemodelan bahasa telah tiba.
Oleh itu, semakin ramai jurutera perisian memilih untuk menanyakan model bahasa yang besar untuk menjawab soalan pengaturcaraan, seperti menggunakan API untuk menjana coretan kod atau mengesan pepijat dalam kod. Model bahasa yang besar boleh mendapatkan jawapan yang disesuaikan dengan lebih sesuai untuk soalan pengaturcaraan daripada mencari forum pengaturcaraan dalam talian seperti Stack Overflow.
LLM adalah pantas, tetapi ini juga menutupi potensi risiko dalam penjanaan kodnya. Dari perspektif kejuruteraan perisian, keteguhan dan kebolehpercayaan keupayaan LLM untuk menjana kod belum dikaji secara menyeluruh, walaupun banyak hasil penyelidikan telah diterbitkan (dari segi mengelakkan ralat sintaksis dan meningkatkan pemahaman semantik kod yang dijana).
Tidak seperti situasi dalam forum pengaturcaraan dalam talian, kod yang dijana oleh LLM tidak disemak oleh rakan sebaya komuniti, jadi isu penyalahgunaan API mungkin berlaku, seperti semakan sempadan yang hilang dalam pembacaan fail dan pengindeksan berubah, penutupan I/O fail hilang , penyelesaian transaksi gagal, dsb. Walaupun sampel kod yang dijana boleh melaksanakan atau melaksanakan fungsi dengan betul, penyalahgunaan boleh membawa kepada potensi risiko yang serius dalam produk, seperti kebocoran memori, ranap program, kegagalan pengumpulan sampah, dsb.
Apa yang lebih teruk ialah pengaturcara yang bertanya soalan ini adalah yang paling terdedah kerana mereka lebih berkemungkinan baharu kepada API dan tidak dapat membezakan kemungkinan masalah dalam coretan kod yang dijana.
Rajah di bawah menunjukkan contoh jurutera perisian yang bertanya kepada LLM untuk soalan pengaturcaraan. Dapat dilihat bahawa Llama-2 boleh memberikan coretan kod dengan sintaks yang betul, fungsi yang betul dan penjajaran sintaks, tetapi terdapat masalah bahawa ia. tidak cukup teguh dan boleh dipercayai, kerana Ia tidak mengambil kira fakta bahawa fail sudah wujud atau folder tidak wujud.

Oleh itu, apabila menilai keupayaan penjanaan kod model bahasa besar, kebolehpercayaan kod mesti dipertimbangkan.
Dari segi menilai keupayaan penjanaan kod model bahasa yang besar, kebanyakan penanda aras sedia ada memfokuskan pada ketepatan fungsi hasil pelaksanaan kod yang dijana, yang bermaksud selagi kod yang dihasilkan dapat memenuhi keperluan fungsi pengguna, pengguna Terima sahaja.
Tetapi dalam bidang pembangunan perisian, ia tidak mencukupi untuk kod dilaksanakan dengan betul. Apa yang diperlukan oleh jurutera perisian ialah kod yang boleh menggunakan API baharu dengan betul dan boleh dipercayai tanpa potensi risiko dalam jangka masa panjang.
Selain itu, skop masalah pengaturcaraan terkini adalah jauh dari kejuruteraan perisian. Kebanyakan sumber datanya ialah rangkaian cabaran pengaturcaraan dalam talian, seperti Codeforces, Kattis, Leetcode, dsb. Walaupun pencapaian itu luar biasa, ia tidak mencukupi untuk membantu pembangunan perisian berfungsi dalam senario aplikasi praktikal.
Untuk tujuan ini, Li Zhong dan Zilong Wang dari University of California, San Diego mencadangkan RobustAPI, rangka kerja yang boleh menilai kebolehpercayaan dan keteguhan kod yang dihasilkan oleh model bahasa yang besar, yang mengandungi set data masalah pengaturcaraan dan Penilai tatabahasa abstrak untuk pokok (AST).

Alamat kertas: https://arxiv.org/pdf/2308.10335.pdf
Matlamat set data adalah untuk mencipta tetapan penilaian yang hampir dengan pembangunan perisian sebenar. Untuk tujuan ini, penyelidik mengumpul soalan perwakilan tentang Java daripada Stack Overflow. Java adalah salah satu bahasa pengaturcaraan yang paling popular dan digunakan secara meluas untuk pembangunan perisian berkat ciri write once run anywhere (WORA).
Untuk setiap soalan, penyelidik memberikan penerangan terperinci dan API Java yang berkaitan. Mereka juga mereka bentuk satu set templat untuk memanggil model bahasa yang besar untuk menjana coretan kod dan penjelasan yang sepadan.
Para penyelidik juga menyediakan penilai yang menggunakan pepohon sintaks abstrak (AST) untuk menganalisis coretan kod yang dijana dan membandingkannya dengan corak penggunaan API yang dijangkakan.
Para penyelidik juga memformalkan corak penggunaan AI ke dalam urutan panggilan berstruktur mengikut kaedah Zhang et al (2018). Urutan panggilan berstruktur ini boleh menunjukkan cara API ini boleh digunakan dengan betul untuk menghapuskan potensi risiko sistem. Dari perspektif kejuruteraan perisian, sebarang pelanggaran jujukan panggilan berstruktur ini dianggap sebagai kegagalan.
Penyelidik mengumpul 1208 soalan sebenar daripada Stack Overflow, yang melibatkan 24 API Java yang mewakili. Para penyelidik juga menjalankan penilaian eksperimen, termasuk bukan sahaja model bahasa sumber tertutup (GPT-3.5 dan GPT-4), tetapi juga model bahasa sumber terbuka (Llama-2 dan Vicuna-1.5). Untuk tetapan hiperparameter model, mereka menggunakan tetapan lalai dan tidak melakukan pelarasan hiperparameter selanjutnya. Mereka juga mereka bentuk dua bentuk percubaan: pukulan sifar dan satu pukulan, yang masing-masing memberikan sifar atau satu sampel tunjuk cara dalam gesaan.
Para penyelidik menganalisis secara menyeluruh kod yang dijana oleh LLM dan mengkaji penyalahgunaan API biasa. Mereka berharap ini akan memberi penerangan tentang isu penting penyalahgunaan API apabila menjana kod dalam LLM, dan penyelidikan ini juga boleh memberikan dimensi baharu kepada penilaian LLM melebihi ketepatan fungsi yang biasa digunakan. Selain itu, set data dan penganggar akan menjadi sumber terbuka.
Sumbangan kertas kerja ini diringkaskan seperti berikut:
- Penanda aras baharu untuk menilai kebolehpercayaan dan keteguhan penjanaan kod LLM dicadangkan: RobustAPI.
- menyediakan rangka kerja penilaian komprehensif yang merangkumi set data soalan Stack Overflow dan penyemak penggunaan API menggunakan AST. Berdasarkan rangka kerja ini, penyelidik menganalisis prestasi LLM yang biasa digunakan, termasuk GPT-3.5, GPT-4, Llama-2 dan Vicuna-1.5.
- Analisis komprehensif prestasi kod yang dijana LLM. Mereka meringkaskan penyalahgunaan API biasa untuk setiap model dan menunjukkan arah untuk penambahbaikan untuk penyelidikan masa depan.
Gambaran Keseluruhan Kaedah
RobustAPI ialah rangka kerja untuk menilai secara menyeluruh kebolehpercayaan dan keteguhan kod yang dijana LLM.
Proses pengumpulan data dan proses penjanaan segera semasa membina set data ini akan diterangkan di bawah Kemudian pola penyalahgunaan API yang dinilai dalam RobustAPI akan diberikan dan kemungkinan akibat penyalahgunaan akan dibincangkan diberikan analisis statik kes penyalahgunaan menggunakan pokok sintaks abstrak.
Didapati bahawa berbanding kaedah berasaskan peraturan seperti padanan kata kunci, kaedah baharu boleh menilai penyalahgunaan API kod yang dijana LLM dengan ketepatan yang lebih tinggi.
Pengumpulan data
Untuk memanfaatkan hasil penyelidikan sedia ada dalam bidang kejuruteraan perisian, titik permulaan apabila penyelidik membina RobustAPI ialah set data daripada ExampleCheck (Zhang et al. 2018). ExampleCheck ialah rangka kerja untuk mengkaji penyalahgunaan API Java biasa dalam forum Soal Jawab web.
Penyelidik memilih 23 API Java biasa daripada set data ini, seperti ditunjukkan dalam Jadual 1 di bawah. 23 API ini meliputi 5 bidang, termasuk pemprosesan rentetan, struktur data, pembangunan mudah alih, penyulitan dan operasi pangkalan data.

penjanaan segera
RobustAPI juga mengandungi templat segera yang boleh diisi menggunakan sampel daripada set data. Para penyelidik kemudian mengumpul respons LLM terhadap gesaan dan menggunakan penyemak API untuk menilai kebolehpercayaan kod mereka.

Dalam gesaan ini, pengenalan tugasan dan format respons yang diperlukan akan diberikan terlebih dahulu. Kemudian, jika eksperimen yang dilakukan adalah eksperimen beberapa sampel, demonstrasi beberapa sampel juga akan diberikan. Berikut ialah contoh:
Sampel demo
Sampel demo telah terbukti membantu LLM memahami bahasa semula jadi. Untuk menganalisis dengan teliti keupayaan penjanaan kod LLM, penyelidik mereka bentuk dua tetapan beberapa pukulan: demonstrasi tidak relevan sampel tunggal dan demonstrasi bergantung sampel tunggal.
Dalam tetapan demo agnostik sampel tunggal, contoh demo yang disediakan untuk LLM menggunakan API yang agnostik. Para penyelidik membuat hipotesis bahawa contoh demonstrasi sedemikian akan menghapuskan ralat sintaksis dalam kod yang dihasilkan. Contoh tidak berkaitan yang digunakan dalam RobustAPI adalah seperti berikut:

Dalam tetapan demo korelasi sampel tunggal, contoh demo yang disediakan untuk LLM menggunakan API yang sama seperti yang digunakan untuk masalah yang diberikan. Contoh ini mengandungi pasangan soalan dan jawapan. Soalan dalam tunjuk cara ini tidak disertakan dalam set data ujian, dan jawapan telah diperbetulkan secara manual untuk memastikan tiada penyalahgunaan API dan semantik jawapan dan soalan diselaraskan dengan baik.
Penyalahgunaan Java API
Para penyelidik merumuskan 40 peraturan API untuk 23 API dalam RobustAPI, yang telah disahkan dalam dokumentasi API ini. Peraturan ini termasuk:
(1) Syarat pengawal untuk API, yang harus diperiksa sebelum panggilan API. Sebagai contoh, hasil File.exists () hendaklah disemak sebelum File.createNewFile ().
(2) Urutan panggilan API yang diperlukan, iaitu, API harus dipanggil dalam susunan tertentu. Contohnya, tutup () hendaklah dipanggil selepas File.write ().
(3) struktur kawalan API. Contohnya, SimpleDateFormat.parse () harus disertakan dalam struktur cuba-tangkap.
Contoh diberikan di bawah:

Mengesan penyalahgunaan API
Untuk menilai ketepatan penggunaan API dalam kod, API boleh dikesan. Kaedahnya adalah untuk mengekstrak hasil panggilan dan struktur kawalan daripada segmen kod, seperti yang ditunjukkan dalam Rajah 2 di bawah.

Pemeriksa kod mula-mula menyemak coretan kod yang dijana untuk melihat sama ada ia adalah sekeping kod dalam kaedah atau kaedah daripada kelas supaya ia boleh merangkum coretan dan menggunakannya Membina pokok sintaks abstrak ( AST).
Pemeriksa kemudian berjalan melalui AST dan merekodkan semua panggilan kaedah dan struktur kawalan mengikut tertib, yang menjana urutan panggilan.
Seterusnya, penyemak membandingkan jujukan panggilan ini dengan peraturan penggunaan API. Ia menyimpulkan jenis contoh untuk setiap panggilan kaedah dan menggunakan jenis dan kaedah itu sebagai kunci untuk mendapatkan semula peraturan penggunaan API yang sepadan.
Akhir sekali, penyemak mengira jujukan biasa terpanjang antara jujukan panggilan ini dan peraturan penggunaan API.
Jika jujukan panggilan tidak sepadan dengan peraturan penggunaan API yang dijangkakan, penyemak melaporkan penyalahgunaan API.
Hasil eksperimen
Para penyelidik menilai RobustAPI pada 4 LLM: GPT-3.5, GPT-4, Llama-2 dan Vicuna-1.5.
Penunjuk penilaian yang digunakan dalam eksperimen termasuk: Kadar penyalahgunaan API, peratusan sampel boleh laku dan peratusan penyalahgunaan API keseluruhan.
Tujuan eksperimen adalah untuk cuba menjawab soalan berikut:
- Soalan 1: Apakah kadar penyalahgunaan API LLM ini dalam menyelesaikan masalah pengaturcaraan dunia sebenar?
- Soalan 2: Apakah kesan sampel demo yang tidak relevan terhadap keputusan?
- Soalan 3: Bolehkah contoh penggunaan API yang betul mengurangkan kadar penyalahgunaan API?
- Soalan 4: Mengapa kod yang dijana oleh LLM gagal melepasi semakan penggunaan API? . -masalah pengaturcaraan dunia.
Pencarian 2: Daripada semua jawapan LLM yang mengandungi kod boleh laku, 57-70% daripada coretan kod mempunyai isu penyalahgunaan API, yang boleh membawa kesan serius dalam pengeluaran.

Penemuan 4: Sesetengah LLM boleh mempelajari contoh penggunaan yang betul, yang boleh mengurangkan kadar penyalahgunaan API. Penemuan 5: GPT-4 mempunyai bilangan jawapan terbesar yang mengandungi kod boleh laku. Untuk API penanda aras, LLM yang berbeza juga mempunyai aliran yang berbeza dalam kadar penyalahgunaan. Selain itu, penyelidik juga menunjukkan kes tipikal berdasarkan GPT-3.5 dalam kertas: model mempunyai respons berbeza di bawah tetapan percubaan yang berbeza. Tugasnya ialah meminta model membantu menulis rentetan pada fail menggunakan API PrintWriter.write. Dalam tetapan demo yang tidak berkaitan sampel sifar dan sampel tunggal, jawapannya berbeza sedikit, tetapi ralat API berlaku dalam kedua-dua kes Masalah dengan penggunaan - Tiada pengecualian dipertimbangkan. Selepas model diberikan contoh penggunaan API yang betul, model belajar cara menggunakan API dan menghasilkan kod yang boleh dipercayai. Sila rujuk kertas asal untuk butiran lanjut. 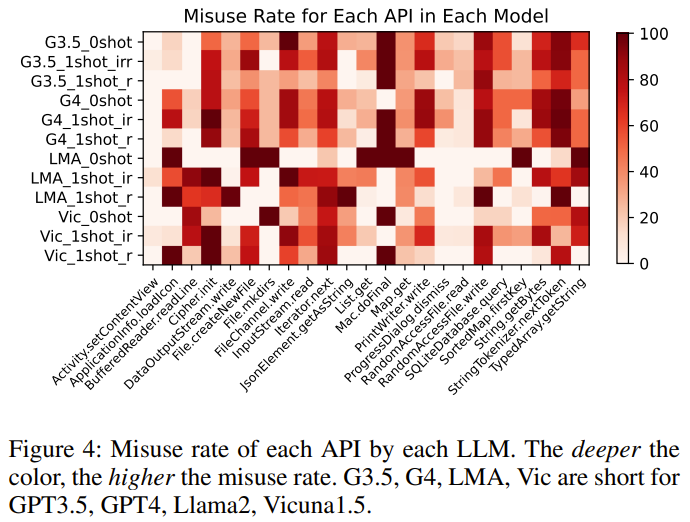

Atas ialah kandungan terperinci GPT-4: Adakah anda berani menggunakan kod yang saya tulis? Penyelidikan menunjukkan kadar penyalahgunaan APInya melebihi 62%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- zbrush怎么删除多余的模型
- 介绍GIT 代码分支管理模型之一
- 使用树形结构的数据模型是什么
- Peperiksaan Masuk Kolej Inggeris tahun ini, CMU menggunakan pra-latihan pembinaan semula untuk mencapai skor tinggi 134, dengan ketara mengatasi GPT3
- Media AS: Musk dan yang lain berhak meminta penggantungan latihan AI dan perlu memperlahankan untuk keselamatan