
Rumah >Peranti teknologi >AI >Kejayaan baharu dalam 'generasi manusia dan adegan interaktif'! Universiti Tianda dan Universiti Tsinghua mengeluarkan Narrator: dipacu teks, boleh dikawal secara semula jadi |
Kejayaan baharu dalam 'generasi manusia dan adegan interaktif'! Universiti Tianda dan Universiti Tsinghua mengeluarkan Narrator: dipacu teks, boleh dikawal secara semula jadi |

- PHPzke hadapan
- 2023-09-11 23:13:051010semak imbas
Penjanaan Human Scene Interaction (HSI) yang semulajadi dan boleh dikawal memainkan peranan penting dalam banyak bidang seperti penciptaan kandungan realiti maya/realiti tambahan (VR/AR) dan kecerdasan buatan berpusatkan manusia.
Walau bagaimanapun, kaedah sedia ada mempunyai kebolehkawalan terhad, jenis interaksi terhad dan hasil yang tidak semulajadi, yang secara serius mengehadkan senario aplikasinya dalam realiti
Dalam penyelidikan di ICCV 2023, pasukan dari Universiti Tianjin dan Universiti Tsinghua mencadangkan penyelesaian yang dipanggil Narator untuk meneroka masalah ini. Penyelesaiannya memberi tumpuan kepada tugas mencabar untuk menjana interaksi pemandangan manusia yang realistik dan pelbagai secara semula jadi dan terkawal daripada penerangan teks
#🎜 🎜# Gambar # Pautan laman utama projek: http://cic.tju.edu.cn/faculty/likun/projects/Narator
Gambar # Pautan laman utama projek: http://cic.tju.edu.cn/faculty/likun/projects/Narator
Kandungan yang ditulis semula ialah: Pautan kod: https: //github.com/HaibiaoXuan/Narrator
Dari perspektif kognitif manusia, model generatif yang ideal seharusnya dapat menaakul dengan betul tentang hubungan spatial dan meneroka darjah kebebasan interaktif .
Oleh itu, penulis mencadangkan model generatif berdasarkan penaakulan hubungan. Model ini memodelkan perhubungan spatial dalam adegan dan penerangan melalui graf pemandangan, dan memperkenalkan mekanisme interaksi peringkat bahagian yang mewakili tindakan interaktif apabila bahagian badan atom menyatakan
#🎜 🎜#Terutamanya, pengarang mencadangkan strategi penjanaan berbilang orang yang mudah tetapi berkesan melalui penaakulan hubungan, yang merupakan penerokaan pertama generasi interaktif adegan berbilang orang yang boleh dikawal#🎜 🎜#Akhirnya, selepas banyak eksperimen dan penyelidikan pengguna, penulis membuktikan bahawa Narrator boleh menjana interaksi yang pelbagai dengan cara yang boleh dikawal, dan kesannya jauh lebih baik daripada kerja sedia ada
# 🎜🎜 #motivasi kaedah# 🎜🎜#Kaedah penjanaan interaksi adegan manusia sedia ada kebanyakannya menumpukan pada hubungan geometri fizikal interaksi, tetapi kurang kawalan semantik ke atas penjanaan dan juga terhad kepada generasi Pemain Tunggal.
Oleh itu, pengarang menumpukan pada tugas yang mencabar untuk terkawal menjana interaksi adegan manusia yang realistik dan pelbagai daripada huraian bahasa semula jadi. Penulis memerhatikan bahawa manusia lazimnya menggunakan persepsi ruang dan pengecaman tindakan untuk menerangkan secara semula jadi orang yang terlibat dalam pelbagai interaksi di lokasi yang berbeza.
Picture
Kandungan yang ditulis semula oleh Figure adalah seperti berikut: secara semula jadi Terkawal menjana interaksi adegan manusia yang konsisten secara semantik dan munasabah dari segi fizikal, sesuai untuk situasi berikut: (a) interaksi berpandukan hubungan ruang, (b) interaksi dipandu oleh pelbagai tindakan, (c) interaksi adegan berbilang orang, dan (d ) interaksi manusia-pemandangan yang menggabungkan jenis interaksi di atas perhubungan bersama. Tindakan interaktif ditentukan oleh keadaan bahagian badan atom, seperti kaki seseorang di atas tanah, bersandar pada batang tubuh, mengetuk tangan kanan, menundukkan kepala, dsb. #🎜🎜 # Sebagai titik permulaan, pengarang menggunakan graf adegan untuk mewakili perhubungan ruang dan mencadangkan mekanisme Joint Global and Local Scene Graf (JGLSG) untuk memberikan kesedaran kedudukan global untuk generasi seterusnya.
#🎜🎜 # Sebagai titik permulaan, pengarang menggunakan graf adegan untuk mewakili perhubungan ruang dan mencadangkan mekanisme Joint Global and Local Scene Graf (JGLSG) untuk memberikan kesedaran kedudukan global untuk generasi seterusnya.
#🎜🎜
Picture
Rajah 2 Gambaran keseluruhan rangka kerja narator#🎜2 Seperti yang ditunjukkan dalam Rajah ini menggunakan autoenkoder variasi bersyarat berasaskan Transformer (cVAE), yang terutamanya merangkumi bahagian berikut:
Berbanding dengan penyelidikan sedia ada, Kami mereka bentuk graf adegan global dan tempatan bersama mekanisme untuk menaakul tentang hubungan spatial yang kompleks dan mencapai kesedaran kedudukan global Pemerhatian tindakan interaktif yang dilengkapkan oleh bahagian badan, dan mekanisme tindakan peringkat komponen diperkenalkan untuk mencapai interaksi yang realistik dan pelbagai Kerugian dwipartit interaktif diperkenalkan untuk mendapatkan hasil penjanaan yang lebih baik
4) Berkembang lagi kepada penjanaan interaksi berbilang orang, dan akhirnya mempromosikan langkah pertama dalam interaksi adegan berbilang orang.
Gabungan mekanisme graf adegan global dan tempatan
Taakulan perhubungan ruang boleh memberikan model petunjuk khusus adegan, yang memainkan peranan penting dalam mencapai kebolehkawalan semula jadi interaksi adegan manusia.
Untuk mencapai matlamat ini, penulis mencadangkan mekanisme gabungan graf adegan global dan tempatan, yang dilaksanakan melalui tiga langkah berikut:
1 Penjanaan graf adegan global: diberikan adegan, gunakan pra- Yang terlatih model graf pemandangan menjana graf pemandangan global, iaitu, 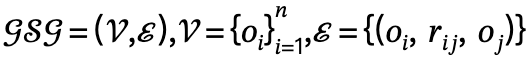 , di mana
, di mana 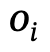 ,
, 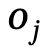 ialah objek dengan label kategori,
ialah objek dengan label kategori, 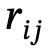 ialah hubungan antara
ialah hubungan antara 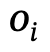 dan
dan 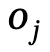 , n ialah bilangan objek, m ialah bilangan hubungan
, n ialah bilangan objek, m ialah bilangan hubungan
2. Penjanaan graf adegan tempatan: Gunakan alat penghuraian semantik untuk mengenal pasti struktur ayat yang diterangkan dan mengekstrak serta menjana adegan setempat 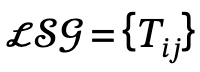 , di mana
, di mana 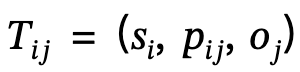 mentakrifkan triplet subjek-predikat-objek
mentakrifkan triplet subjek-predikat-objek
Pemadanan graf adegan: melalui Objek yang sama; teg semantik, model sepadan dengan nod dalam graf adegan global dan graf adegan tempatan, dan menambah nod manusia maya dengan memanjangkan perhubungan tepi untuk memberikan maklumat kedudukan
Mekanisme Tindakan Tahap Komponen (PLA)
Pengarang mencadangkan mekanisme tindakan peringkat bahagian yang terperinci yang melaluinya model dapat melihat keadaan bahagian badan yang penting dan mengabaikan bahagian yang tidak berkaitan daripada interaksi yang diberikan
Secara khusus, pengarang meneroka tindakan interaktif yang kaya dan pelbagai, dan memetakan ini tindakan yang mungkin kepada lima bahagian utama tubuh manusia: kepala, batang tubuh, lengan kiri/kanan, tangan kiri/kanan, dan bahagian bawah badan kiri/kanan.
Dalam pengekodan seterusnya, kita boleh menggunakan One-Hot untuk mewakili tindakan dan bahagian badan ini pada masa yang sama, dan menyambungkannya mengikut hubungan yang sepadan
Pengarang berada dalam generasi interaktif pelbagai tindakan An mekanisme perhatian diguna pakai untuk mengetahui status bahagian struktur badan yang berbeza
Dalam kombinasi tindakan interaktif yang diberikan, perhatian antara bahagian badan yang sepadan dengan setiap tindakan dan semua tindakan lain akan dilindungi secara automatik.
Ambil "orang mencangkung di atas tanah menggunakan kabinet" sebagai contoh Mencangkung sepadan dengan keadaan bahagian bawah badan, jadi perhatian yang ditandakan oleh bahagian lain akan disekat kepada sifar. Kandungan yang ditulis semula: Ambil "seorang mencangkung di atas tanah menggunakan kabinet" sebagai contoh Mencangkung sepadan dengan keadaan bahagian bawah badan, jadi perhatian bahagian badan yang lain akan disekat sepenuhnya
Pengoptimuman persepsi pemandangan
Pengarang memanfaatkan kekangan geometri dan fizikal untuk pengoptimuman yang menyedari pemandangan untuk meningkatkan hasil penjanaan. Sepanjang proses pengoptimuman, kaedah ini memastikan pose yang dihasilkan tidak menyimpang, sambil menggalakkan sentuhan dengan adegan dan mengekang badan untuk mengelakkan interpenetrasi dengan adegan
Memandangkan adegan tiga dimensi S dan parameter SMPL-X yang dihasilkan , kerugian pengoptimuman ialah:
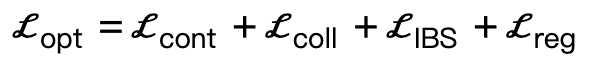
Antaranya, 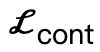 menggalakkan bucu badan untuk menghubungi tempat kejadian;
menggalakkan bucu badan untuk menghubungi tempat kejadian; 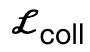 ialah istilah perlanggaran berdasarkan jarak yang ditandatangani; kerja. Ia adalah koleksi titik sama jarak yang dijadikan sampel antara tempat kejadian dan badan manusia;
ialah istilah perlanggaran berdasarkan jarak yang ditandatangani; kerja. Ia adalah koleksi titik sama jarak yang dijadikan sampel antara tempat kejadian dan badan manusia; 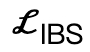
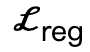 Multiple Scene Interaction (MHSI)
Multiple Scene Interaction (MHSI)
Dalam adegan dunia sebenar, dalam banyak kes bukan hanya seorang yang berinteraksi dengan adegan itu, tetapi Ia adalah interaksi berbilang orang secara bebas atau bersekutu.
Walau bagaimanapun, disebabkan kekurangan set data MHSI, kaedah sedia ada biasanya memerlukan usaha manual tambahan dan tidak dapat mengendalikan tugas ini dengan cara yang boleh dikawal dan automatik.
Untuk tujuan ini, penulis hanya menggunakan set data individu tunggal sedia ada dan mencadangkan strategi yang mudah dan berkesan untuk hala tuju generasi berbilang orang.
Selepas diberi penerangan teks berkaitan berbilang orang, pengarang mula-mula menghuraikannya ke dalam berbilang graf adegan tempatan
dan tindakan interaktif, dan Tentukan calon ditetapkan sebagai 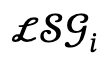 , dengan l ialah bilangan orang.
, dengan l ialah bilangan orang. 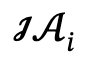
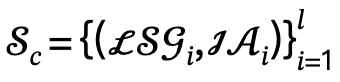
Untuk setiap item dalam set calon, ia adalah input pertama ke dalam Narator bersama-sama dengan adegan
dan graf adegan global yang sepadan, dan maka proses pengoptimuman dilakukan . 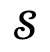
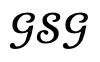
Untuk menangani perlanggaran antara orang, kerugian tambahan
diperkenalkan semasa proses pengoptimuman, di mana ialah jarak yang ditandatangani antara orang. 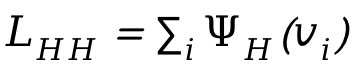
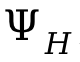 Kemudian, apabila kehilangan pengoptimuman adalah lebih rendah daripada ambang yang ditentukan berdasarkan pengalaman percubaan, hasil yang dijana ini diterima dan dikemas kini
Kemudian, apabila kehilangan pengoptimuman adalah lebih rendah daripada ambang yang ditentukan berdasarkan pengalaman percubaan, hasil yang dijana ini diterima dan dikemas kini
. 
Perlu diperhatikan bahawa kaedah kemas kini ini mewujudkan hubungan antara hasil setiap generasi dan hasil generasi sebelumnya, mengelakkan tahap kesesakan tertentu, dan selaras dengan mudah Generasi berbilang adalah lebih munasabah dan interaktif daripada taburan spatial.
Proses di atas boleh dinyatakan sebagai:
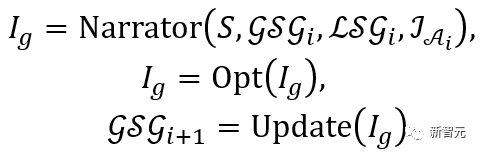
 Gambar
Gambar
Rajah 3 Keputusan perbandingan kualitatif kaedah berbeza
Rajah 3 menunjukkan hasil perbandingan kualitatif Narator dan tiga garis dasar. Disebabkan oleh batasan perwakilan PiGraph-Text, ia mempunyai masalah penembusan yang lebih serius
POSA-Teks sering jatuh ke dalam minima tempatan semasa proses pengoptimuman, mengakibatkan hubungan interaktif yang buruk. COINS-Teks mengikat tindakan pada objek tertentu, kurang kesedaran global tentang pemandangan, membawa kepada penembusan dengan objek yang tidak ditentukan, dan sukar untuk mengendalikan hubungan ruang yang kompleks.
Sebaliknya, Narator boleh menaakul dengan betul tentang hubungan ruang berdasarkan tahap huraian teks yang berbeza dan menganalisis keadaan badan di bawah pelbagai tindakan, dengan itu mencapai hasil penjanaan yang lebih baik.
Dari segi perbandingan kuantitatif, seperti yang ditunjukkan dalam Jadual 1, Narator mengatasi kaedah lain dalam lima penunjuk, menunjukkan bahawa keputusan yang dihasilkan oleh kaedah ini mempunyai ketekalan teks yang lebih tepat dan kebolehpercayaan fizikal yang lebih baik.
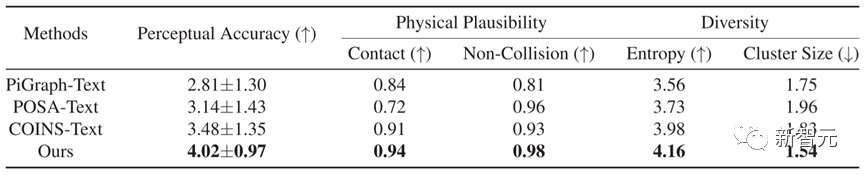 Jadual 1 Hasil perbandingan kuantitatif kaedah berbeza
Jadual 1 Hasil perbandingan kuantitatif kaedah berbeza
Selain itu, penulis juga menyediakan perbandingan dan analisis terperinci untuk lebih memahami keberkesanan strategi MHSI yang dicadangkan.
Memandangkan pada masa ini tiada kerja pada MHSI, mereka memilih pendekatan yang mudah sebagai garis dasar, iaitu penjanaan berjujukan dan pengoptimuman dengan COINS.
Untuk membuat perbandingan yang adil, kehilangan perlanggaran buatan juga diperkenalkan. Rajah 4 dan Jadual 2 masing-masing menunjukkan keputusan kualitatif dan kuantitatif, yang mana kedua-duanya sangat membuktikan bahawa strategi yang dicadangkan oleh penulis adalah konsisten secara semantik dan munasabah dari segi fizikal pada MHSI.
 Rajah 4 Perbandingan kualitatif dengan MHSI menggunakan kaedah penjanaan dan pengoptimuman COINS
Rajah 4 Perbandingan kualitatif dengan MHSI menggunakan kaedah penjanaan dan pengoptimuman COINS

Mengenai pengarang



utama
 penglihatan, penglihatan komputer dan penjanaan imej
penglihatan, penglihatan komputer dan penjanaan imej
 Arah penyelidikan tertumpu terutamanya pada penglihatan dan grafik komputer yang berpusatkan manusia
Arah penyelidikan tertumpu terutamanya pada penglihatan dan grafik komputer yang berpusatkan manusia
komputer dalam
fotografi pengiraan
🎜🎜 🎜Pautan halaman utama peribadi: https://liuyebin.com/🎜🎜🎜
Arah utama penyelidikan: penglihatan 3D, pembinaan semula dan penjanaan pintar
#🎜##🎜##🎜##🎜##🎜 🎜 🎜#Laman utama peribadi: http://cic.tju.edu.cn/faculty/likun Rujukan:#🎜]🎜#[1]🎜# Savva M, Chang A [2] Hassan M, Ghosh P, Tesch J, et al Mempopulasikan adegan 3D dengan mempelajari interaksi adegan manusia[C]. -14718. #🎜 🎜#
[3] Zhao K, Wang S, Zhang Y, et al Sintesis interaksi adegan manusia dengan kawalan semantik[C]. , 2022: 311- 327.Atas ialah kandungan terperinci Kejayaan baharu dalam 'generasi manusia dan adegan interaktif'! Universiti Tianda dan Universiti Tsinghua mengeluarkan Narrator: dipacu teks, boleh dikawal secara semula jadi |. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- ps照片更换场景怎么换
- 单例模式的适用场景包括哪些
- 根据应用场景的不同,机器人可以分为哪几种类型
- Pasukan Zhu Jun memperoleh sumber terbuka model penyebaran pelbagai mod berskala besar pertama berdasarkan Transformer di Universiti Tsinghua, dan ia telah siap sepenuhnya selepas penulisan semula teks dan imej.
- Siri buku teks AI yang disyorkan yang menyepadukan industri dan pendidikan ‖ Baidu bergabung tenaga dengan Tsinghua Publishing House untuk membantu memupuk bakat AI