
Rumah >Peranti teknologi >AI >Penaakulan H100 melonjak 8 kali ganda! NVIDIA secara rasmi mengumumkan sumber terbuka TensorRT-LLM, menyokong 10+ model
Penaakulan H100 melonjak 8 kali ganda! NVIDIA secara rasmi mengumumkan sumber terbuka TensorRT-LLM, menyokong 10+ model

- 王林ke hadapan
- 2023-09-10 16:41:011723semak imbas
"GPU miskin" akan mengucapkan selamat tinggal kepada kesusahan mereka!
Tadi, NVIDIA mengeluarkan perisian sumber terbuka yang dipanggil TensorRT-LLM, yang boleh mempercepatkan proses inferens model bahasa besar yang dijalankan pada H100# 🎜🎜 #

Jadi, berapa kali ia boleh diperbaiki?
Selepas menambah TensorRT-LLM dan siri fungsi pengoptimumannya (termasuk pemprosesan kelompok Dalam Penerbangan), jumlah pemprosesan model meningkat sebanyak 8 kali ganda.
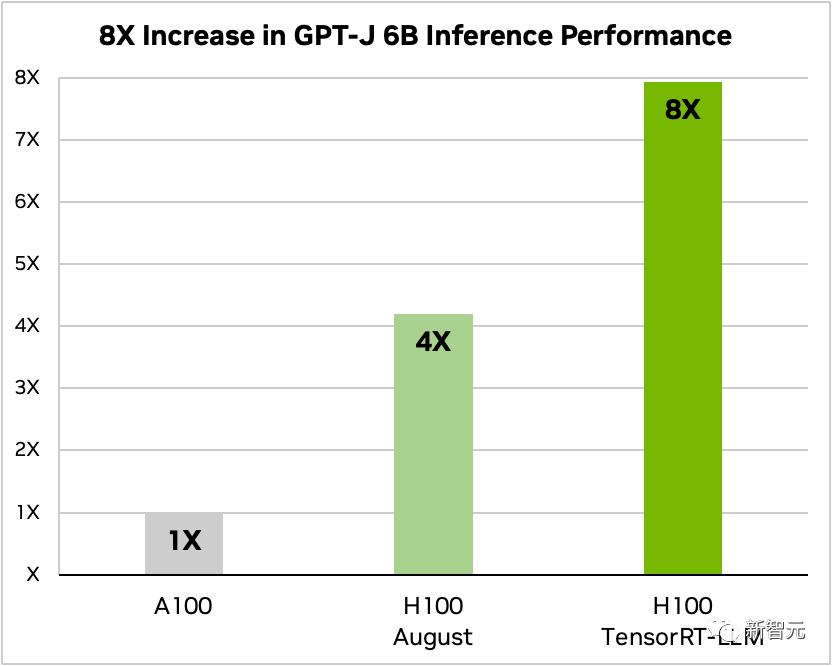
Perbandingan GPT-J-6B A100 dan H100 dengan dan tanpa TensorRT-LLM#🎜 🎜#Selain itu, mengambil Llama 2 sebagai contoh, TensorRT-LLM boleh meningkatkan prestasi inferens sebanyak 4.6 kali berbanding menggunakan A100 secara bebas
#🎜 #
Perbandingan Llama 2 70B, A100 dan H100 dengan dan tanpa TensorRT-LLM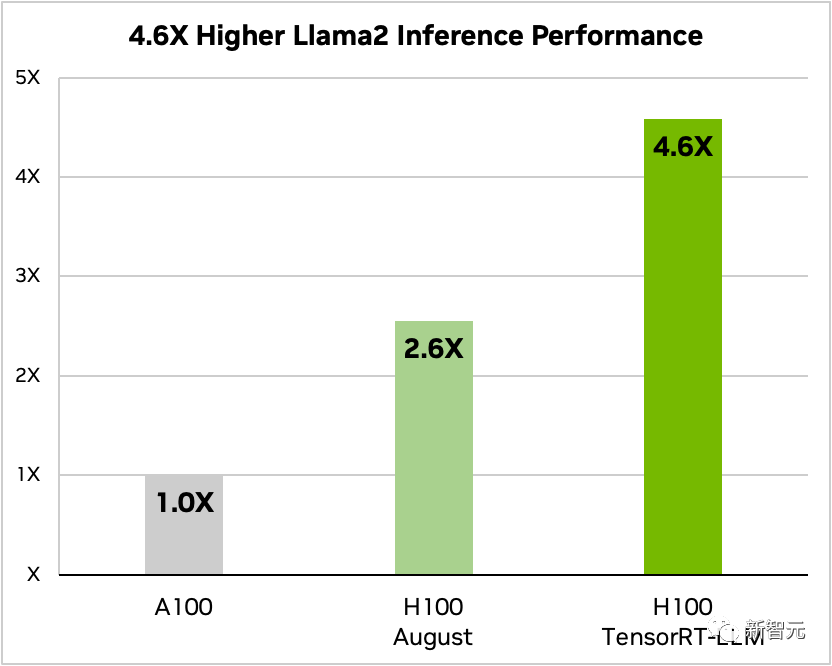
#🎜ns🎜 berkata bahawa #Netizens yang berkuasa H100, digabungkan dengan TensorRT-LLM, sudah pasti akan mengubah sepenuhnya situasi semasa inferens model bahasa besar!
TensorRT-LLM: Artifak pecutan inferens model besar
#🎜🎜🎜##🎜, disebabkan oleh besaran model Skala parameter yang besar menjadikan "pengerahan dan inferens" sukar dan mahal.
TensorRT-LLM yang dibangunkan oleh NVIDIA bertujuan untuk meningkatkan daya pengeluaran LLM dengan ketara dan mengurangkan kos melalui GPU
# 🎜🎜## 🎜 #
Secara khusus, TensorRT-LLM merangkumi penyusun pembelajaran mendalam TensorRT, kernel FasterTransformer yang dioptimumkan, pra dan pasca pemprosesan, dan komunikasi berbilang GPU/berbilang nod dalam satu Dalam keadaan terbuka mudah sumber Python API
NVIDIA telah mempertingkatkan lagi FasterTransformer untuk menjadikannya penyelesaian yang terhasil. 
Ia boleh dilihat bahawa TensorRT-LLM menyediakan antara muka pengaturcaraan aplikasi Python sumber terbuka dan modular yang mudah digunakan.
Pengekod yang tidak memerlukan pengetahuan mendalam tentang C++ atau CUDA boleh menggunakan, menjalankan dan nyahpepijat pelbagai model bahasa berskala besar dan mencapai prestasi yang cemerlang penyesuaian pantas
Menurut laporan di blog rasmi NVIDIA, TensorRT-LLM menggunakan empat kaedah untuk Meningkatkan prestasi LLM pada Nvidia GPU
Pertama sekali, TensorRT-LLM diperkenalkan untuk 10+ model besar semasa, membolehkan pembangun menjalankannya dengan segera. 
Kedua, TensorRT-LLM, sebagai perpustakaan perisian sumber terbuka, membenarkan LLM melakukan inferens pada berbilang GPU dan berbilang pelayan GPU secara serentak.
Pelayan ini disambungkan melalui sambungan NVLink dan InfiniBand NVIDIA masing-masing.
Mata ketiga ialah mengenai "pemprosesan kelompok dalam mesin", yang merupakan teknologi penjadualan serba baharu yang membolehkan tugas model berbeza masuk dan keluar secara bebas daripada yang lain. tugas GPU
Akhirnya, TensorRT-LLM dioptimumkan untuk menggunakan Enjin Transformer H100 untuk mengurangkan penggunaan memori dan kependaman semasa inferens model.
Mari kita lihat secara terperinci bagaimana TensorRT-LLM meningkatkan prestasi model
Sokongan ekologi LLM yang kaya#🎜 🎜🎜#TensorRT-LLM menyediakan sokongan yang sangat baik untuk ekosistem model sumber terbuka
Kandungan yang perlu ditulis semula ialah: dengan skala terbesar dan model Bahasa yang paling maju, seperti Llama 2-70B yang dilancarkan oleh Meta, memerlukan berbilang GPU untuk bekerjasama memberikan respons dalam masa nyata
Sebelum ini, untuk mencapai prestasi terbaik daripada inferens LLM, Pembangun mesti menulis semula model AI secara manual, memecahkannya kepada beberapa bahagian, dan kemudian menyelaraskan pelaksanaan antara GPUTensorRT-LLM menggunakan teknologi selari tensor untuk mengagihkan matriks berat kepada setiap peranti, dengan itu memudahkan proses dan membolehkan inferens cekap berskala besar Setiap model boleh dijalankan pada berbilang peranti yang disambungkan melalui NVLink Run pada berbilang GPU dan berbilang pelayan tanpa campur tangan pembangun atau perubahan model. Dengan pelancaran model dan seni bina model baharu, pembangun boleh menggunakan sumber terbuka NVIDIA AI kernel (Kernal) terkini dalam TensorRT-LLM untuk mengoptimumkan model Apa yang perlu ditulis semula Kernel adalah: Fusion termasuk pelaksanaan FlashAttention terkini, serta perhatian berbilang kepala bertopeng untuk konteks dan peringkat penjanaan pelaksanaan model GPT, dsb. Selain itu, TensorRT-LLM juga termasuk banyak model bahasa besar yang popular pada masa ini versi yang dioptimumkan, sedia untuk dijalankan. Model ini termasuk Meta Llama 2, OpenAI GPT-2 dan GPT-3, Falcon, Mosaic MPT, BLOOM dan lebih daripada sepuluh lagi. Semua model ini boleh dipanggil menggunakan TensorRT-LLM Python API yang mudah digunakan Fungsi ini boleh membantu pembangun membina model bahasa besar tersuai dengan lebih pantas dan lebih tepat untuk memenuhi keperluan berbeza pelbagai industri. Kini, model bahasa besar sangat serba boleh. Sesuatu model boleh digunakan serentak untuk berbilang tugasan yang kelihatan berbeza - daripada jawapan Soal Jawab yang mudah dalam chatbot, kepada rumusan dokumen atau penjanaan blok kod panjang, beban kerja sangat dinamik dan saiz output perlu dipenuhi Keperluan untuk tugasan susunan magnitud yang berbeza. Kepelbagaian tugas boleh menyukarkan untuk mengumpulkan permintaan dengan cekap dan melaksanakan pelaksanaan selari yang cekap, yang berpotensi menyebabkan beberapa permintaan diselesaikan lebih awal daripada yang lain. Untuk mengurus beban dinamik ini, TensorRT-LLM menyertakan teknologi penjadualan yang dioptimumkan yang dipanggil "Pengumpulan dalam penerbangan". Prinsip teras model bahasa besar ialah keseluruhan proses penjanaan teks boleh dicapai melalui berbilang lelaran model Dengan pemprosesan kelompok dalam penerbangan, masa jalan TensorRT-LLM segera dikeluarkan daripada kumpulan apabila ia selesai urutan dan bukannya menunggu keseluruhan kumpulan selesai sebelum beralih ke set permintaan seterusnya. Semasa melaksanakan permintaan baharu, permintaan lain dari kumpulan sebelumnya yang belum selesai masih diproses. Penggunaan GPU yang lebih baik melalui batching dalam mesin dan pengoptimuman peringkat kernel tambahan, menghasilkan sekurang-kurangnya dua kali ganda daya pemprosesan penanda aras permintaan dunia sebenar untuk LLM pada H100 Oleh kerana LLM mengandungi berbilion berat model dan fungsi pengaktifan, ia biasanya dilatih dan diwakili dengan nilai FP16 atau BF16, setiap satunya menduduki 16 bit memori. Walau bagaimanapun, pada masa inferens, kebanyakan model boleh diwakili dengan cekap dengan ketepatan yang lebih rendah menggunakan teknik pengkuantitian, seperti integer 8-bit atau 4-bit (INT8 atau INT4). Kuantisasi ialah proses mengurangkan berat model dan ketepatan pengaktifan tanpa mengorbankan ketepatan. Menggunakan ketepatan yang lebih rendah bermakna setiap parameter adalah lebih kecil dan model menggunakan lebih sedikit ruang dalam memori GPU.
Melalui teknologi H100 Transformer Engine, digabungkan dengan Tensor Engine H1000 GPU membolehkan pengguna menukar berat model dengan mudah kepada format FP8 baharu dan menyusun model secara automatik untuk memanfaatkan teras FP8 yang dioptimumkan. Dan proses ini tidak memerlukan sebarang pengekodan! Format data FP8 yang diperkenalkan oleh H100 membolehkan pembangun mengukur model mereka dan mengurangkan penggunaan memori secara mendadak tanpa mengurangkan ketepatan model. Berbanding dengan format data lain seperti INT8 atau INT4, pengkuantitian FP8 mengekalkan ketepatan yang lebih tinggi sambil mencapai prestasi terpantas dan paling mudah untuk dilaksanakan.
Berbanding dengan format data lain seperti INT8 atau INT4, kuantisasi FP8 mengekalkan ketepatan yang lebih tinggi sambil mencapai prestasi terpantas dan paling mudah untuk dilaksanakan Walaupun TensorRT-LLM belum Dikeluarkan secara rasmi tetapi pengguna kini boleh mengalaminya lebih awal Pautan aplikasi adalah seperti berikut: https://developer.nvidia.com/tensorrt-llm-early-access/join Nvidia juga mengatakannya akan TensorRT-LLM telah disepadukan dengan cepat ke dalam rangka kerja NVIDIA NeMo. Rangka kerja ini adalah sebahagian daripada AI Enterprise yang dilancarkan baru-baru ini oleh NVIDIA, menyediakan pelanggan perusahaan dengan platform perisian AI peringkat perusahaan yang selamat, stabil dan sangat terurus Pembangun dan penyelidik boleh rangka kerja NeMo pada NVIDIA NGC atau projek di GitHub untuk mengakses TensorRT-LLM Walau bagaimanapun, perlu diambil perhatian bahawa pengguna mesti mendaftar untuk Program Pembangun NVIDIA untuk memohon versi akses awal. Pengguna di Reddit mengadakan perbincangan hangat mengenai keluaran TensorRT-LLM Sukar untuk membayangkan sejauh mana kesannya akan dipertingkatkan selepas mengoptimumkan perkakasan khusus untuk LLM. Tetapi sesetengah netizen percaya bahawa maksud perkara ini adalah untuk membantu Lao Huang menjual lebih banyak H100. Sesetengah netizen mempunyai pendapat berbeza tentang perkara ini. Mereka percaya bahawa Tensor RT juga membantu pengguna yang menggunakan pembelajaran mendalam secara tempatan. Selagi anda mempunyai GPU RTX, anda juga mungkin mendapat manfaat daripada produk yang serupa pada masa hadapan Dari perspektif yang lebih makro, mungkin untuk LLM, akan ada satu siri langkah pengoptimuman khusus untuk tahap perkakasan, dan mungkin juga Perkakasan yang direka khusus untuk LLM telah muncul untuk meningkatkan prestasinya. Keadaan ini telah berlaku dalam banyak aplikasi popular, dan LLM tidak terkecuali
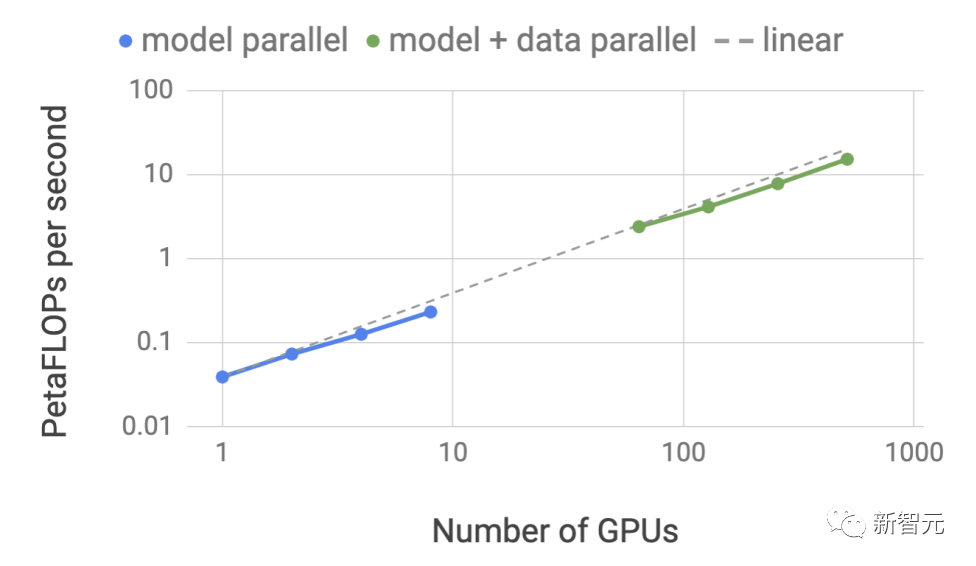
Pemprosesan kelompok dalam penerbangan

Menggunakan enjin Transformer H100 FP 8🜎🜎🜎
LLM juga menyediakan ciri yang dipanggil Enjin Transformer H100, yang boleh mengurangkan penggunaan memori dan kependaman secara berkesan semasa inferens model besar. 
Cara mendapatkan TensorRT-LLM
Perbincangan hangat di kalangan netizen


Atas ialah kandungan terperinci Penaakulan H100 melonjak 8 kali ganda! NVIDIA secara rasmi mengumumkan sumber terbuka TensorRT-LLM, menyokong 10+ model. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!