
Rumah >Peranti teknologi >AI >Universiti Jiao Tong Shanghai mengeluarkan CodeApex, penanda aras penilaian pengaturcaraan dwibahasa model besar Adakah mesin benar-benar mula mencabar manusia dalam menulis kod?
Universiti Jiao Tong Shanghai mengeluarkan CodeApex, penanda aras penilaian pengaturcaraan dwibahasa model besar Adakah mesin benar-benar mula mencabar manusia dalam menulis kod?

- 王林ke hadapan
- 2023-09-05 23:29:111472semak imbas
Membina mesin yang boleh menulis kod mereka sendiri ialah matlamat yang telah diusahakan oleh perintis dalam sains komputer dan kecerdasan buatan. Dengan perkembangan pesat model besar jenis GPT, matlamat sedemikian menjadi lebih dekat berbanding sebelum ini.
Kemunculan Model Bahasa Besar telah menarik lebih banyak perhatian daripada penyelidik kepada keupayaan pengaturcaraan model. Di bawah keadaan ini, Makmal APEX Universiti Jiao Tong Shanghai melancarkan CodeApex - set data penanda aras dwibahasa yang memberi tumpuan kepada menilai pemahaman pengaturcaraan dan keupayaan penjanaan kod LLM.
Untuk menilai keupayaan pemahaman pengaturcaraan model bahasa besar, CodeApex telah mereka tiga jenis soalan aneka pilihan: pemahaman konsep, penaakulan akal dan penaakulan multi-hop. Selain itu, CodeApex juga menggunakan soalan algoritma dan kes ujian yang sepadan untuk menilai keupayaan penjanaan kod LLM. CodeApex menilai sejumlah 14 model bahasa besar pada tugas pengekodan. Antaranya, GPT3.5-turbo menunjukkan keupayaan pengaturcaraan terbaik, masing-masing mencapai kira-kira 50% dan 56% ketepatan pada kedua-dua tugas ini. Ia boleh dilihat bahawa model bahasa yang besar masih mempunyai banyak ruang untuk penambahbaikan dalam tugas pengaturcaraan Membina mesin yang boleh menulis kodnya sendiri adalah masa depan yang sangat menjanjikan. .
Kertas: https://apex.sjtu.edu.cn/codeapex/paper/
- Pengenalan
- pengaturcaraan adalah tugas utama dalam kejuruteraan dan penjanaan kod Memainkan peranan penting dalam produktiviti pembangun, meningkatkan kualiti kod dan mengautomasikan proses pembangunan perisian. Walau bagaimanapun, tugasan ini masih mencabar untuk model besar disebabkan oleh kerumitan dan kepelbagaian semantik kod. Berbanding dengan pemprosesan bahasa semula jadi biasa, menggunakan LLM untuk menjana kod memerlukan lebih penekanan pada tatabahasa, struktur, pemprosesan terperinci dan pemahaman konteks, dan mempunyai keperluan yang sangat tinggi untuk ketepatan kandungan yang dijana. Pendekatan tradisional termasuk model berasaskan peraturan tatabahasa, model berasaskan templat dan model berasaskan peraturan, yang selalunya bergantung pada peraturan yang direka secara manual dan algoritma heuristik yang terhad dalam liputan dan ketepatan. Dalam beberapa tahun kebelakangan ini, dengan kemunculan model pra-latihan berskala besar seperti CodeBERT dan GPT3.5, penyelidik telah mula meneroka aplikasi model ini dalam pemahaman pengaturcaraan dan tugas penjanaan kod. Model ini menyepadukan tugas penjanaan kod semasa latihan, membolehkan mereka memahami dan menjana kod. Walau bagaimanapun, penilaian yang saksama terhadap kemajuan LLM dalam pemahaman dan penjanaan kod adalah sukar kerana kekurangan set data penanda aras standard, tersedia secara umum, berkualiti tinggi dan pelbagai. Oleh itu, mewujudkan set data penanda aras yang meliputi semantik dan struktur kod secara meluas adalah penting untuk menggalakkan penyelidikan dalam pemahaman pengaturcaraan dan penjanaan kod.
- Set data penanda aras kod sedia ada mempunyai masalah kebolehgunaan dan kepelbagaian apabila digunakan pada LLM. Contohnya, beberapa set data lebih sesuai untuk menilai LLM pemodelan bahasa dwiarah jenis Bert. Walau bagaimanapun, set data penanda aras kod berbilang bahasa sedia ada (seperti Human-Eval) mengandungi masalah yang agak mudah, kekurangan kepelbagaian dan hanya boleh melaksanakan beberapa kod fungsi asas. Untuk mengisi jurang di atas, Makmal Pengurusan Data dan Pengetahuan APEX Universiti Jiao Tong Shanghai membina penanda aras penilaian baharu untuk pemahaman kod model besar dan penjanaan-CodeApex. Sebagai set data penanda aras dwibahasa (Bahasa Inggeris, Cina), CodeApex menumpukan pada menilai pemahaman pengaturcaraan dan keupayaan penjanaan kod LLM.
Adegan percubaan keseluruhan CodeApex ditunjukkan dalam gambar di atas.
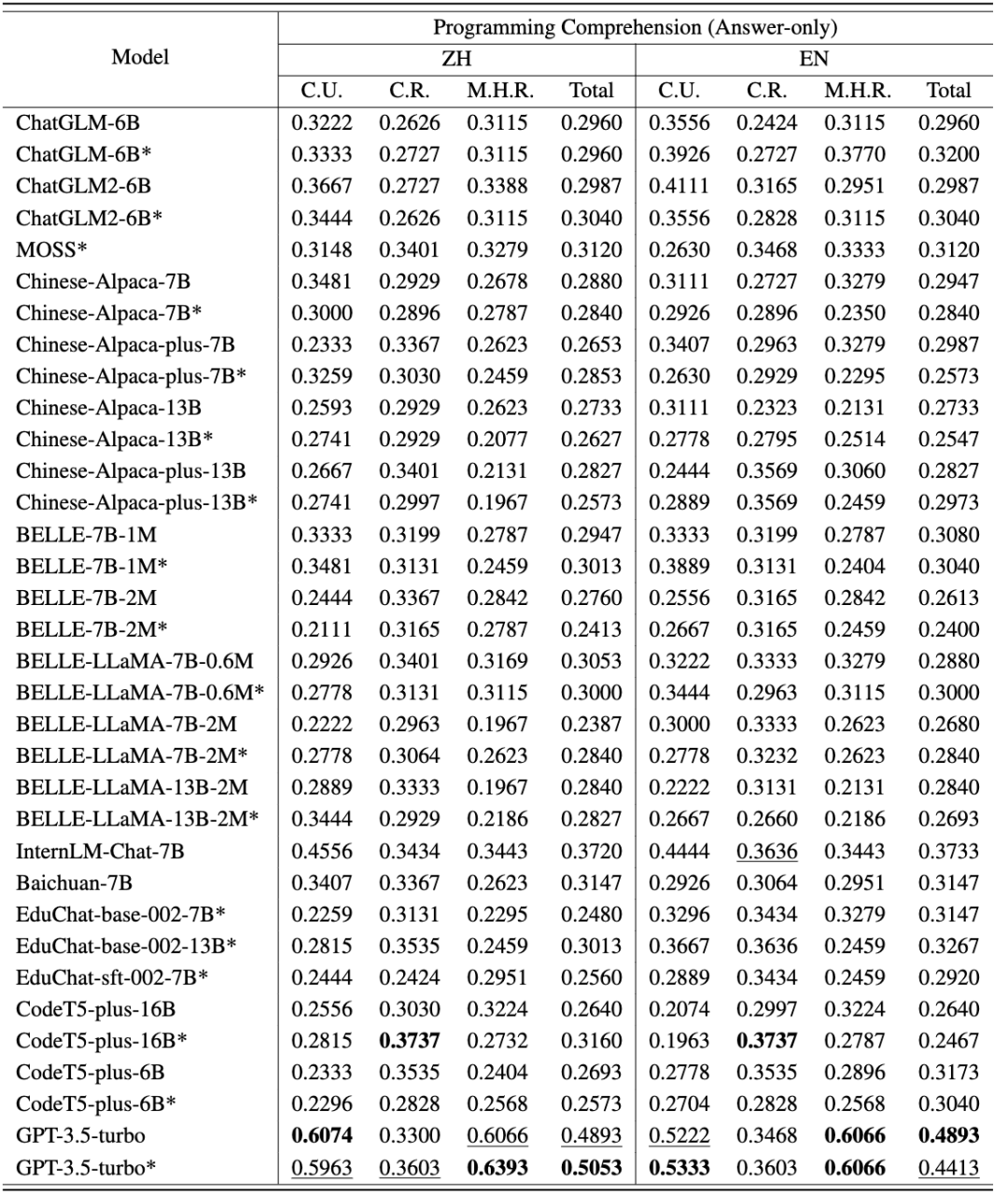
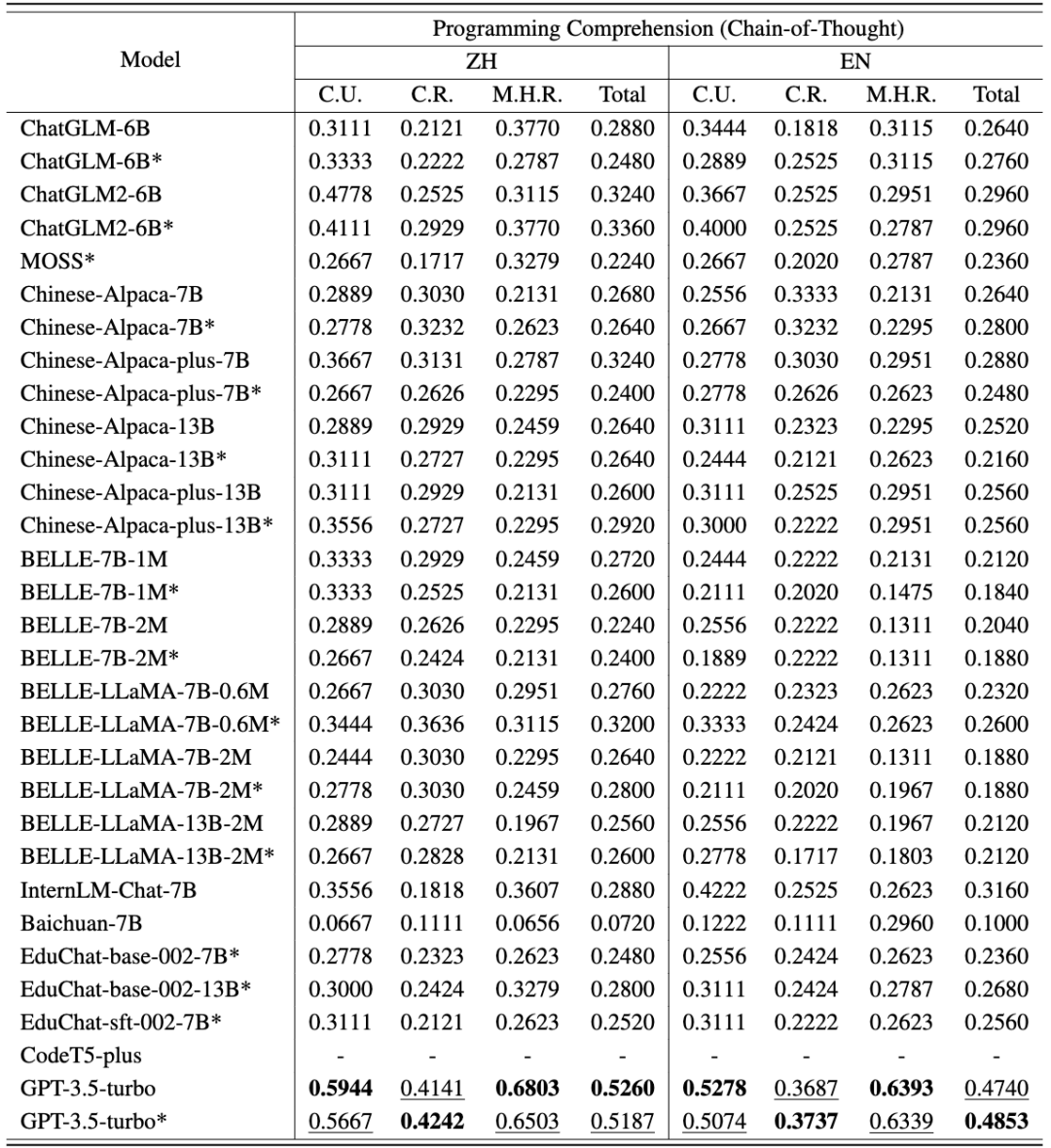
Tugas pertama pemahaman pengaturcaraan termasuk 250 soalan aneka pilihan, yang dibahagikan kepada pemahaman konsep, penaakulan akal dan penaakulan multi-hop. Soalan yang digunakan untuk ujian dipilih daripada soalan peperiksaan akhir kursus yang berbeza (pengaturcaraan, struktur data, algoritma) di kolej dan universiti, yang mengurangkan risiko bahawa data sudah ada dalam korpus latihan LLM. CodeApex menguji keupayaan pemahaman kod LLM dalam tiga senario: 0-shot, 2-shot, dan 5-shot, dan juga menguji kesan mod Jawapan Sahaja dan Rantaian-Pemikiran terhadap keupayaan LLM.
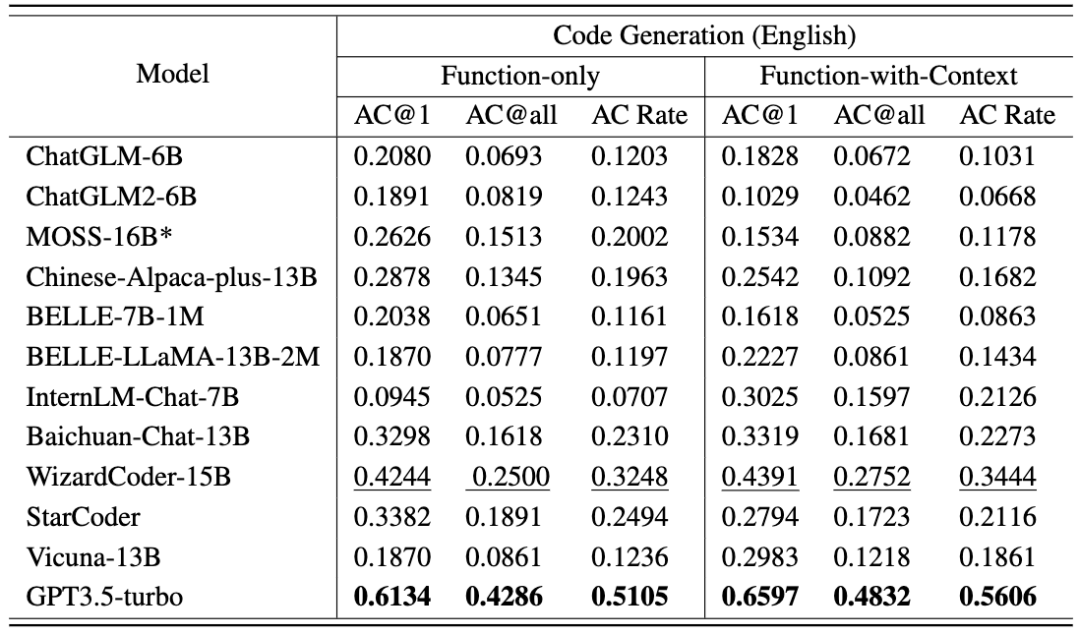
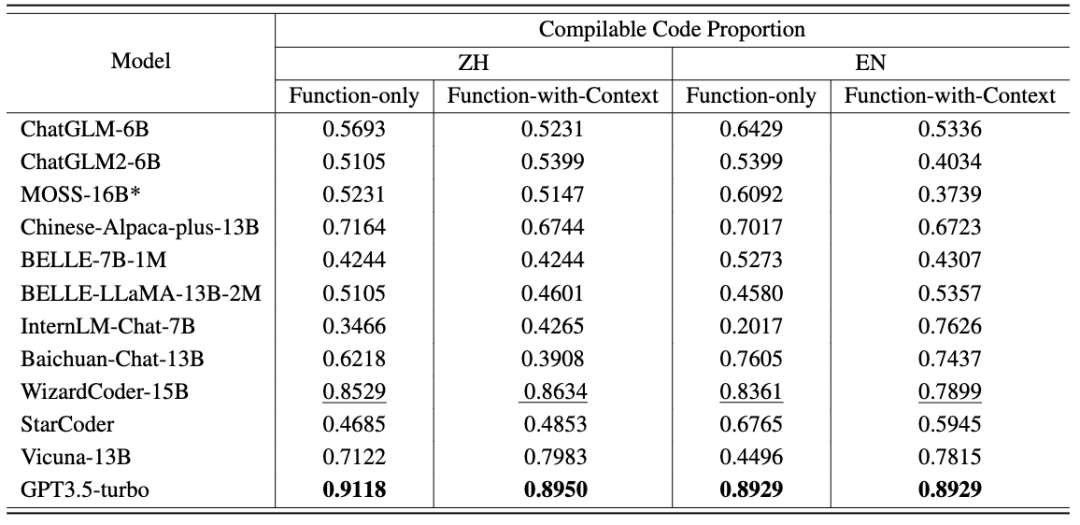
Penjanaan kod tugas kedua termasuk 476 masalah algoritma berasaskan C++, meliputi mata pengetahuan algoritma biasa, seperti carian binari, carian mendalam-pertama, dsb. CodeApex memberikan penerangan tentang masalah dan prototaip fungsi yang melaksanakan masalah, dan memerlukan LLM untuk melengkapkan bahagian utama fungsi. CodeApex juga menyediakan dua senario: fungsi-sahaja dan fungsi-dengan-konteks Perbezaan di antara mereka ialah yang pertama hanya mempunyai perihalan fungsi sasaran, manakala yang kedua, sebagai tambahan kepada perihalan fungsi sasaran, juga disediakan. dengan kod panggilan dan masa fungsi sasaran, kekangan ruang, penerangan input dan output. Hasil eksperimen menunjukkan bahawa model yang berbeza menunjukkan prestasi yang berbeza dalam tugas berkaitan kod, dan GPT3.5-turbo menunjukkan daya saing yang sangat baik dan kelebihan yang jelas. Tambahan pula, CodeApex membandingkan prestasi LLM dalam senario dwibahasa, mendedahkan hasil yang berbeza. Secara keseluruhannya, masih terdapat banyak ruang untuk penambahbaikan dalam ketepatan LLM dalam penarafan CodeApex, yang menunjukkan bahawa potensi LLM dalam tugas berkaitan kod masih belum dieksploitasi sepenuhnya. Untuk menyepadukan sepenuhnya model bahasa besar ke dalam senario pengeluaran kod sebenar, pemahaman pengaturcaraan adalah penting. Pemahaman pengaturcaraan memerlukan keupayaan untuk memahami kod dari semua aspek, seperti menguasai sintaks, memahami aliran pelaksanaan kod, dan memahami algoritma pelaksanaan. CodeApex mengekstrak 250 soalan aneka pilihan daripada soalan peperiksaan akhir kolej sebagai data ujian ini dibahagikan kepada tiga kategori: pemahaman konsep, penaakulan akal dan penaakulan multi-hop. Mod ujian merangkumi dua kategori: Jawab-Sahaja dan Rantaian-Pemikiran. Hasil penilaian Bahasa Cina dan Inggeris CodeApex mengenai tugas pemahaman kod ditunjukkan dalam dua jadual berikut. (Model berprestasi terbaik ditunjukkan dalam huruf tebal; model berprestasi terbaik seterusnya digariskan.) Kesimpulan berikut boleh dibuat daripada ini: Melatih model bahasa yang besar untuk menjana kod yang tepat dan boleh laku adalah Tugas yang mencabar. CodeApex menilai terutamanya keupayaan LLM untuk menjana algoritma berdasarkan penerangan yang diberikan dan secara automatik menilai ketepatan kod yang dijana melalui ujian unit. Tugas penjanaan kod CodeApex termasuk 476 masalah algoritma berasaskan C++, meliputi mata pengetahuan algoritma biasa, seperti carian binari dan algoritma graf. CodeApex memberikan penerangan tentang masalah dan prototaip fungsi yang melaksanakan masalah, dan memerlukan LLM untuk melengkapkan bahagian utama fungsi. CodeApex menyediakan dua senario: Fungsi-sahaja dan Fungsi-dengan-konteks. Senario Fungsi sahaja hanya menyediakan penerangan tentang fungsi sasaran, manakala senario Fungsi dengan konteks bukan sahaja menyediakan penerangan tentang fungsi sasaran, tetapi juga menyediakan kod panggilan, kekangan masa dan ruang serta penerangan input dan output bagi fungsi sasaran. Setiap versi bahasa menggunakan dua strategi Prompt (Fungsi-Sahaja dan Fungsi-dengan-Konteks). Untuk menyelaraskan dengan senario ujian kod manusia, metrik penilaian termasuk AC@1, AC@all dan kadar AC. Keputusan tugas penjanaan kod untuk setiap model ditunjukkan dalam dua jadual berikut. (Prestasi terbaik: tebal; prestasi kedua terbaik: garis bawah.) Kesimpulan berikut boleh dibuat: Selain itu, CodeApex menyediakan perkadaran kod yang boleh dikompilasi dalam setiap senario. Selepas menyambungkan fungsi yang dijana kepada fungsi utama, kod yang disusun disemak melalui kes ujian. Anda boleh lihat: CodeApex, sebagai penanda aras dwibahasa yang memfokuskan pada keupayaan pengaturcaraan LLM, menilai pemahaman pengaturcaraan dan keupayaan penjanaan kod model bahasa besar. Dari segi pemahaman pengaturcaraan, CodeApex menilai kebolehan model yang berbeza dalam tiga kategori soalan aneka pilihan. Dari segi penjanaan kod, CodeApex menggunakan kadar lulus kes kod ujian untuk menilai keupayaan model. Untuk kedua-dua tugas ini, CodeApex mereka bentuk strategi Prompt dengan teliti dan membandingkannya dalam senario yang berbeza. CodeApex dinilai secara eksperimen pada 14 LLM, termasuk LLM umum dan model LLM khusus berdasarkan penalaan halus kod. Pada masa ini, GPT3.5 telah mencapai tahap yang agak baik dari segi keupayaan pengaturcaraan, masing-masing mencapai ketepatan kira-kira 50% dan 56% dalam pemahaman pengaturcaraan dan penjanaan kod. CodeApex menunjukkan bahawa potensi model bahasa yang besar untuk tugas pengaturcaraan masih belum dieksploitasi sepenuhnya. Kami menjangkakan bahawa memanfaatkan model bahasa yang besar untuk menjana kod akan merevolusikan bidang pembangunan perisian dalam masa terdekat. Apabila pemprosesan bahasa semula jadi dan pembelajaran mesin semakin maju, model ini akan menjadi lebih berkuasa dan mahir dalam memahami dan menjana coretan kod. Pembangun akan mendapati mereka mempunyai sekutu yang tidak pernah berlaku sebelum ini dalam usaha pengekodan mereka, kerana mereka boleh bergantung pada model ini untuk mengautomasikan tugas yang membosankan, meningkatkan produktiviti mereka dan meningkatkan kualiti perisian. Pada masa hadapan, CodeApex akan mengeluarkan lebih banyak ujian (seperti pembetulan kod) untuk menguji keupayaan kod model bahasa besar juga akan terus dikemas kini untuk menambah masalah kod yang lebih pelbagai. Pada masa yang sama, eksperimen manusia juga akan ditambahkan pada senarai CodeApex untuk membandingkan keupayaan pengekodan model bahasa besar dengan tahap manusia. CodeApex menyediakan penanda aras dan rujukan untuk penyelidikan tentang keupayaan pengaturcaraan model bahasa yang besar, dan akan menggalakkan pembangunan dan kemakmuran model bahasa besar dalam bidang kod. Makmal Pengurusan Data dan Pengetahuan APEX Universiti Jiao Tong Shanghai telah ditubuhkan pada tahun 1996. Pengasasnya ialah Profesor Yu Yong, ketua guru kelas ACM. Makmal ini komited untuk meneroka teknologi kecerdasan buatan yang secara berkesan melombong dan mengurus data dan meringkaskan pengetahuan Ia telah menerbitkan lebih daripada 500 kertas akademik antarabangsa dan meneruskan aplikasi praktikal dalam senario sebenar. Sepanjang 27 tahun yang lalu, APEX Laboratory telah menjadi perintis global dalam banyak gelombang teknologi dunia Makmal ini mula mengkaji teknologi teras Web Semantik (kini dikenali sebagai Graf Pengetahuan) pada tahun 2000, dan mula mengkaji enjin carian yang diperibadikan dan. cadangan pada tahun 2003. Teknologi sistem, mula mempelajari teori dan algoritma pembelajaran pemindahan pada tahun 2006, mula meneroka teknologi pembelajaran mendalam pada tahun 2009 dan membangunkan perpustakaan latihan rangkaian saraf berdasarkan GPU. Semasa menghasilkan hasil penyelidikan dan pelaksanaan saintifik yang bermanfaat, APEX Lab juga telah membangunkan pasukan penyelidikan sains data dan pembelajaran mesin yang kukuh, termasuk Xue Guirong, Zhang Lei, Lin Chenxi, Liu Guangcan, Wang Haofen, Li Lei, Dai Wenyuan, Li Zhenhui, Chen Tianqi, Zhang Weinan, Yang Diyi dan alumni cemerlang lain dalam bidang kecerdasan buatan. Pemahaman Kod


Hasil eksperimen dan kesimpulan
Penjanaan Kod


Hasil eksperimen dan kesimpulan
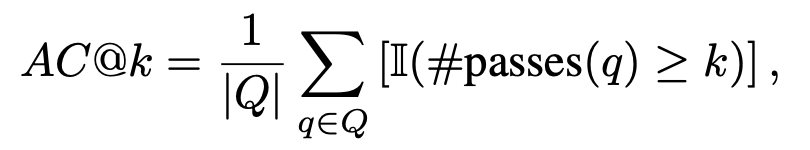
Kesimpulan
Pengenalan kepada APEX Laboratory
Atas ialah kandungan terperinci Universiti Jiao Tong Shanghai mengeluarkan CodeApex, penanda aras penilaian pengaturcaraan dwibahasa model besar Adakah mesin benar-benar mula mencabar manusia dalam menulis kod?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!