
Rumah >Peranti teknologi >AI >Ceramah teknikal lima minit yang mendalam tentang model generatif GET3D
Ceramah teknikal lima minit yang mendalam tentang model generatif GET3D

- 王林ke hadapan
- 2023-09-01 19:01:061422semak imbas
Bahagian 01●
Kata Pengantar
Dalam beberapa tahun kebelakangan ini, dengan peningkatan alat penjanaan imej kecerdasan buatan yang diwakili oleh Midjourney dan Stable Diffusion, teknologi penjanaan imej kecerdasan buatan 2D telah menjadi alat bantu yang digunakan oleh ramai pereka dalam projek sebenar digunakan dalam pelbagai senario perniagaan dan mencipta lebih banyak nilai praktikal. Pada masa yang sama, dengan kebangkitan Metaverse, banyak industri bergerak ke arah mewujudkan dunia maya 3D berskala besar, dan kandungan 3D yang pelbagai dan berkualiti tinggi menjadi semakin penting untuk industri seperti permainan, robotik, seni bina, dan platform sosial. Walau bagaimanapun, mencipta aset 3D secara manual memakan masa dan memerlukan kemahiran artistik dan pemodelan tertentu. Salah satu cabaran utama ialah isu skala - walaupun terdapat banyak model 3D yang boleh ditemui di pasaran 3D, mengisi sekumpulan watak atau bangunan yang semuanya kelihatan berbeza dalam permainan atau filem masih memerlukan pelaburan artis yang besar masa. Akibatnya, keperluan untuk alat penciptaan kandungan yang boleh berskala dari segi kuantiti, kualiti dan kepelbagaian kandungan 3D telah menjadi semakin jelas
 Gambar
Gambar
Sila lihat Rajah 1, ini adalah foto ruang metaverse ( Sumber: filem "Wreck-It Ralph 2")
Terima kasih kepada fakta bahawa model generatif 2D telah mencapai kualiti realistik dalam sintesis imej resolusi tinggi, kemajuan ini juga telah memberi inspirasi kepada penyelidikan tentang penjanaan kandungan 3D. Kaedah awal bertujuan untuk memanjangkan penjana CNN 2D terus ke grid voxel 3D, tetapi jejak memori yang tinggi dan kerumitan pengiraan lilitan 3D menghalang proses penjanaan pada resolusi tinggi. Sebagai alternatif, penyelidikan lain telah meneroka awan titik, perwakilan tersirat atau oktre. Walau bagaimanapun, kerja-kerja ini tertumpu terutamanya pada penjanaan geometri dan mengabaikan penampilan. Perwakilan keluaran mereka juga perlu diproses pasca untuk menjadikannya serasi dengan enjin grafik standard
Untuk menjadi praktikal untuk pengeluaran kandungan, model generatif 3D yang ideal harus memenuhi keperluan berikut:
Mempunyai keupayaan untuk menjana grafik 3D dengan geometri perincian dan topologi sewenang-wenangnya Keupayaan bentuk
Tulis semula kandungan: (b) Output hendaklah berupa jejaring bertekstur, yang merupakan ungkapan biasa yang digunakan oleh perisian grafik standard seperti Blender dan Maya
Boleh diselia menggunakan imej 2D, kerana ia lebih baik daripada bentuk 3D eksplisit Secara umumnya
Bahagian 02
Pengenalan kepada model generatif 3D
Untuk memudahkan proses penciptaan kandungan dan membolehkan aplikasi praktikal, rangkaian 3D generatif telah menjadi kawasan penyelidikan aktif yang mampu menghasilkan aset 3D yang berkualiti tinggi dan pelbagai . Banyak model generatif 3D diterbitkan setiap tahun di persidangan seperti ICCV, NeurlPS dan ICML, termasuk model termaju berikut
Textured3DGAN ialah model generatif yang merupakan lanjutan daripada kaedah konvolusi menghasilkan jejaring 3D bertekstur. Ia dapat belajar menjana jaringan tekstur daripada imej fizikal menggunakan GAN di bawah pengawasan 2D. Berbanding dengan kaedah sebelumnya, Textured3DGAN melonggarkan keperluan untuk titik utama dalam langkah anggaran pose dan generalisasi kaedah kepada koleksi imej tidak berlabel dan kategori/set data baharu, seperti ImageNet
DIB-R: ialah pemapar Boleh Dibezakan berdasarkan interpolasi, menggunakan PyTorch rangka kerja pembelajaran mesin di bahagian bawah. Penyampai ini telah ditambahkan pada repositori 3D Deep Learning PyTorch GitHub (Kaolin). Kaedah ini membolehkan pengiraan analitik kecerunan untuk semua piksel dalam imej. Idea teras adalah untuk menganggap rasterisasi latar depan sebagai interpolasi wajaran atribut tempatan dan rasterisasi latar belakang sebagai pengagregatan berasaskan jarak bagi geometri global. Dengan cara ini, ia boleh meramalkan maklumat seperti bentuk, tekstur dan cahaya daripada satu imej
PolyGen: PolyGen ialah model generatif autoregresif berdasarkan seni bina Transformer untuk mesh model secara langsung. Model meramalkan bucu dan muka jejaring secara bergilir-gilir. Kami melatih model menggunakan set data ShapeNet Core V2, dan hasilnya sudah sangat hampir dengan model mesh yang dibina manusia
SurfGen: Sintesis bentuk 3D Adversarial dengan diskriminator permukaan yang jelas. Model terlatih hujung ke hujung mampu menghasilkan bentuk 3D kesetiaan tinggi dengan topologi yang berbeza.
GET3D ialah model generatif yang boleh menjana bentuk bertekstur 3D berkualiti tinggi dengan mempelajari imej. Terasnya ialah pemodelan permukaan boleh dibezakan, pemaparan boleh dibezakan dan rangkaian lawan generatif 2D. Dengan melatih koleksi imej 2D, GET3D boleh terus menjana jejaring 3D bertekstur eksplisit dengan topologi kompleks, butiran geometri yang kaya dan tekstur ketelitian tinggi
 imej
imej
Apa yang perlu ditulis semula ialah: Model penjanaan GET3D Rajah 2 (Sumber: laman web rasmi kertas GET3D https://nv-tlabs.github.io/GET3D/)
GET3D ialah model generatif 3D yang dicadangkan baru-baru ini yang menggunakan berbilang model dengan geometri kompleks seperti ShapeNet, Turbosquid dan Renderpeople seperti kerusi, motosikal, kereta, orang ramai dan bangunan, menunjukkan prestasi terkini dalam penjanaan bentuk 3D tanpa had
Bahagian 03
Seni bina dan ciri-ciri GET3D
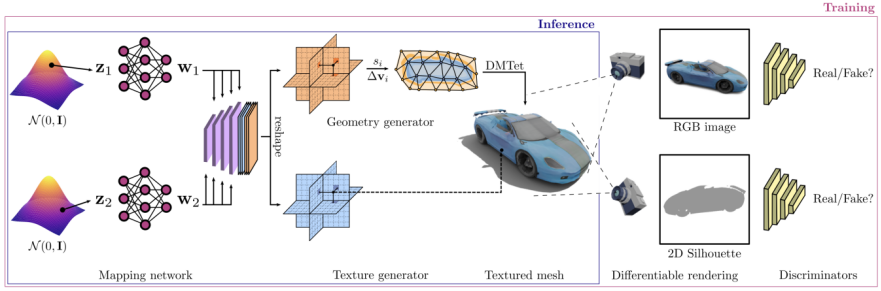 Pictures
Pictures
Seni bina GET3D berasal dari laman web rasmi kertas GET3D Rajah 3 menunjukkan seni bina
adalah potensi pengekodan dua medan 3D melalui SDF. dan medan tekstur, kemudian gunakan DMTet (Deep Marching Tetrahedra) untuk mengekstrak jaringan permukaan 3D daripada SDF, dan tanya medan tekstur dalam awan titik permukaan untuk mendapatkan warna. Keseluruhan proses dilatih menggunakan kehilangan musuh yang ditakrifkan pada imej 2D. Khususnya, imej dan kontur RGB diperoleh menggunakan pemapar boleh dibezakan berasaskan rasterisasi. Akhir sekali, dua diskriminator 2D digunakan, setiap satu untuk imej dan kontur RGB, untuk membezakan sama ada input adalah sebenar atau palsu. Keseluruhan model boleh dilatih hujung-ke-hujung
GET3D juga sangat fleksibel dalam aspek lain dan boleh disesuaikan dengan mudah kepada tugas lain selain menyatakan jejaring eksplisit sebagai output, termasuk:
Pelaksanaan geometri dan tekstur berasingan: Penyahgandingan yang baik antara geometri dan tekstur dicapai, membolehkan interpolasi bermakna kod terpendam geometri dan kod terpendam tekstur
Dengan melakukan berjalan rawak dalam ruang terpendam, apabila menjana peralihan lancar antara kelas bentuk yang berbeza, Dan menjana bentuk 3D yang sepadan untuk mencapai
Hasilkan bentuk baharu: Ini boleh diganggu dengan menambahkan sedikit bunyi kecil pada kod pendam setempat, dengan itu menghasilkan bentuk yang kelihatan serupa tetapi sedikit berbeza secara tempatan
Penjanaan bahan tanpa pengawasan: melalui Gabungan dengan DIBR++, jana bahan dengan cara yang tidak diselia sepenuhnya dan hasilkan kesan pencahayaan bergantung pada pandangan yang bermakna
Penjanaan bentuk berpandukan teks: dengan menggabungkan StyleGAN NADA, memanfaatkan imej 2D yang dihasilkan secara pengiraan dan teks yang disediakan pengguna Menggunakan kehilangan CLIP arah untuk memperhalusi penjana 3D, pengguna boleh menjana sejumlah besar yang bermakna bentuk melalui gesaan teks
 Gambar
Gambar
Sila rujuk Rajah 4, yang menunjukkan proses menghasilkan bentuk berdasarkan teks. Sumber angka ini ialah laman web rasmi kertas GET3D, URLnya ialah https://nv-tlabs.github.io/GET3D/
Bahagian 04
Ringkasan
Walaupun GET3D telah mengambil langkah ke arah 3D praktikal model penjanaan bentuk tekstur Satu langkah penting, tetapi ia masih mempunyai beberapa batasan. Khususnya, proses latihan masih bergantung pada pengetahuan siluet 2D dan pengedaran kamera. Oleh itu, pada masa ini GET3D hanya boleh dinilai berdasarkan data sintetik. Sambungan yang menjanjikan adalah untuk memanfaatkan kemajuan dalam pembahagian contoh dan anggaran pose kamera untuk mengurangkan masalah ini dan melanjutkan GET3D kepada data dunia sebenar. GET3D pada masa ini hanya dilatih mengikut kategori, dan akan dikembangkan kepada berbilang kategori pada masa hadapan untuk mewakili kepelbagaian antara kategori dengan lebih baik. Semoga penyelidikan ini akan membawa orang ramai selangkah lebih dekat untuk menggunakan kecerdasan buatan untuk penciptaan kandungan 3D secara percuma
Atas ialah kandungan terperinci Ceramah teknikal lima minit yang mendalam tentang model generatif GET3D. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!