
Rumah >Java >JavaSoalan temu bual >Penemubual: Bagaimana untuk menyelesaikan data Redis condong, titik panas dan isu lain
Penemubual: Bagaimana untuk menyelesaikan data Redis condong, titik panas dan isu lain
- Java后端技术全栈ke hadapan
- 2023-08-15 16:43:081728semak imbas
Redis sebagai teknologi arus perdana mempunyai banyak senario aplikasi Banyak temu bual dengan kilang besar, sederhana dan kecil telah menyenaraikannya sebagai kandungan pemeriksaan utama
Beberapa hari lalu, ketika seorang rakan Planet sedang belajar, dia menemui perkara berikut. pertanyaan dan datang untuk berunding dengan Tom. mempunyai beberapa soalan semasa menyemak redis , sila lihat:
Jika kluster redis mempunyai data condong dan pengagihan data tidak sekata, bagaimana cara menyelesaikannya?Apabila memproses hotKey, cipta beberapa salinan kunci, seperti k-1, k-2..., Bagaimana untuk membuat salinan ini menulis sama rata? Bagaimana untuk mengakses secara merata?
redis menggunakan slot cincang untuk mengekalkan kluster. Sama seperti pencincangan yang konsisten, penghijrahan penuh boleh dielakkan. Mengapa tidak hanya menggunakan pencincangan yang konsisten?
Balas:Dalam bidang cache yang diedarkan, Redis kini digunakan secara meluas Rangka kerja ini ialah storan memori tulen, pelaksanaan perintah berbenang tunggal, struktur data asas yang kaya dan sokongan untuk penyimpanan dan carian data dalam pelbagai dimensi.Sebagai pemecut prestasi, cache teragih memainkan peranan yang sangat penting dalam pengoptimuman sistem. Berbanding dengan cache tempatan, walaupun ia menambah penghantaran rangkaian dan mengambil masa kurang daripada 1 milisaat, ia mempunyai kelebihan pengurusan berpusat dan menyokong kapasiti storan yang sangat besar.
Sudah tentu dengan jumlah data yang banyak, pelbagai masalah timbul seperti: data skew, data hotspot dan lain-lain
Apa itu data skew? . Pelanggan memajukan permintaan baca dan tulis kepada kejadian tertentu melalui strategi penghalaan tertentu.
Disebabkan kekhususan data perniagaan, mengikut peraturan sharding yang ditentukan, data pada kejadian yang berbeza mungkin diedarkan secara tidak sekata Sebilangan besar data tertumpu pada satu atau beberapa nod mesin untuk pengiraan, mengakibatkan jumlah beban nod ini mempunyai Walaupun nod lain melahu dan menunggu, mengakibatkan kecekapan keseluruhan yang rendah.
Apakah sebab data condong?
1. Terdapat kunci besar
Sebagai contoh, menyimpan satu atau lebih data BigKey jenis String mengambil banyak memori.
Abang Tom telah menyiasat masalah ini sebelum ini Untuk menyelamatkan masalah semasa pembangunan, seorang rakan sekerja menggunakan format JSON untuk menggabungkan berbilang data perniagaan menjadi satu nilai dan hanya mengaitkan satu kunci ini pasangan mencapai ratusan M.
Kerap membaca dan menulis kekunci besar menggunakan sumber memori yang berat dan memberi tekanan hebat pada penghantaran rangkaian, yang seterusnya menyebabkan tindak balas permintaan menjadi perlahan, mencetuskan kesan runtuhan salji, dan akhirnya menyebabkan pelbagai penggera tamat masa sistem. . - warna: rgba(0, 0, 0, 0.06);lebar sempadan: 1px;gaya sempadan: pepejal;warna sempadan: rgba(0, 0, 0, 0.08);jejari sempadan: 2px;padding-kanan : 2px;padding-left: 2px;">pecahkannya kepada bahagian
Strateginya adalah untuk membahagikan bigKey kepada berbilang kunci kecil dan mengekalkannya secara bebas, yang akan mengurangkan kos dengan banyak. Sudah tentu, pembongkaran ini juga memberi perhatian kepada beberapa prinsip Ia adalah perlu untuk mempertimbangkan kedua-dua senario perniagaan dan senario akses, dan meletakkannya secara rapat.
Contohnya: terdapat antara muka RPC yang mempunyai pergantungan dalaman pada Redis Sebelum ini, semua data boleh diperolehi dengan mengaksesnya sekali sahaja , peningkatan dalam bilangan panggilan akan menyebabkan masalah masa tindak balas antara muka keseluruhan yang besar.
Agensi kerajaan di Zhejiang menyokong pengoptimuman proses tersebut, dan menjalankannya paling banyak sekali adalah sebab yang sama. 
<span style="font-size: 16px;">化整为零</span>的策略,将一个bigKey拆分为多个小key,独立维护,成本会降低很多。当然这个拆也讲究些原则,既要考虑业务场景也要考虑访问场景,将关联紧密的放到一起。
比如:有个RPC接口内部对 Redis 有依赖,之前访问一次就可以拿到全部数据,拆分将要控制单值的大小,也要控制访问的次数,毕竟调用次数增多了,会拉大整体的接口响应时间。
浙江的政府机构都在提倡优化流程,最多跑一次,都是一个道理。
2、HashTag 使用不当
Redis 采用单线程执行命令,从而保证了原子性。当采用集群部署后,为了解决mset、lua 脚本等对多key 批量操作,为了保证不同的 key 能路由到同一个 Redis 实例上,引入了 HashTag 机制。
用法也很简单,使用<span style="font-size: 16px;">{}</span>
;margin-bottom: 5px;line-height: 3em;">2. Penggunaan HashTag yang tidak betul
Redis menggunakan satu utas untuk melaksanakan arahan, dengan itu memastikan atomicity . Apabila penggunaan kluster diguna pakai, untuk menyelesaikan operasi kelompok berbilang kunci seperti skrip mset dan lua, dan untuk memastikan bahawa kunci yang berbeza boleh dihalakan ke contoh Redis yang sama, HashTag .
Penggunaan juga sangat mudah, gunakan
{}🎜🎜Pendakap, nyatakan kunci untuk mengira hanya cincang rentetan dalam pendakap, dengan itu memasukkan pasangan nilai kunci kunci yang berbeza ke dalam slot cincang yang sama. 🎜🎜🎜🎜🎜Contohnya: 🎜🎜🎜🎜192.168.0.1:6380> CLUSTER KEYSLOT testtag
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT {testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey1{testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey2{testtag}
(integer) 764🎜🎜🎜Semak kod perniagaan untuk melihat sama ada HashTag diperkenalkan dan terlalu banyak kunci dihalakan ke satu tika. Pertimbangkan cara membahagikan berdasarkan senario tertentu. 🎜🎜🎜🎜Sama seperti RocketMQ, dalam banyak kes keperluan perniagaan kita boleh dipenuhi selagi partition disimpan teratur. Dalam amalan sebenar, kita perlu mencari titik keseimbangan ini, bukannya menyelesaikan masalah demi menyelesaikannya. 🎜🎜. , setiap nod dalam kelompok boleh mengendalikan 0 atau maksimum 16384 slot. Anda boleh memindahkan slot yang agak besar secara manual ke mesin terbiar sedikit untuk memastikan keseragaman storan dan akses.
Apakah tempat liputan cache?
Cache hotspot bermakna kebanyakan atau bahkan semua permintaan perniagaan mencecah data cache yang sama, yang memberi tekanan besar pada pelayan cache dan malah melebihi had beban satu mesin, menyebabkan pelayan turun.
Penyelesaian:
1. Buat beberapa salinan
Penyelesaian:
1. Buat berbilang salinan
nombor kunci di sebalik kekunci #0, nombor sebegitu, #0, nombor nombor di sebalik kekunci #1, #0, nombor sekuensial. . . Berbilang salinan kunci#10, kunci yang diproses ini terletak pada berbilang nod cache.
Setiap kali pelanggan mengakses, ia hanya perlu menyambung nombor rawak dengan had atas bilangan serpihan berdasarkan kekunci asal, dan menghalakan permintaan ke nod contoh yang tidak boleh dihalakan.
Nota: Cache biasanya menetapkan masa tamat tempoh Untuk mengelakkan kegagalan cache berpusat, kami cuba untuk tidak mempunyai masa tamat cache yang sama Kami boleh menambah nombor rawak berdasarkan pratetap.
Bagi keseragaman penghalaan data, ini dijamin oleh algoritma Hash.
2. Cache memori tempatan
Simpan data tempat liputan dalam memori tempatan pelanggan dan tetapkan masa tamat tempoh. Untuk setiap permintaan baca, ia terlebih dahulu akan menyemak sama ada data wujud dalam cache tempatan. Jika ia wujud, ia akan dikembalikan secara langsung Jika ia tidak wujud, ia kemudiannya akan mengakses pelayan cache yang diedarkan.
Cache memori tempatan sepenuhnya "membebaskan" pelayan cache dan tidak memberi sebarang tekanan pada pelayan cache.
🎜Kelemahan: Agak menyusahkan untuk mengesan data cache terkini dalam masa nyata dan ketidakkonsistenan data mungkin berlaku. Kami boleh menetapkan masa tamat tempoh yang agak singkat dan menggunakan kemas kini pasif. Sudah tentu, anda juga boleh menggunakan mekanisme pemantauan untuk mengemas kini cache setempat tepat pada masanya jika ia merasakan bahawa data telah berubah. 🎜🎜🎜Kluster Redis style="font-family: SFMono-Regular, Consolas, "Mono Pembebasan ", Menlo, Kurier, monospace;warna latar belakang: rgba(0, 0, 0, 0.06);lebar sempadan: 1px;gaya sempadan: pepejal;warna sempadan: rgba(0, 0, 0, 0.08); jejari sempadan: 2px;padding-kanan: 2px;padding-left: 2px;">key
通过<strong>CRC16<span style="color: rgb(17, 124, 238);font-size: 18px;"></span></strong>
校验后对
16384
<span style="font-size: 16px;">化整为零</span>的策略,将一个bigKey拆分为多个小key,独立维护,成本会降低很多。当然这个拆也讲究些原则,既要考虑业务场景也要考虑访问场景,将关联紧密的放到一起。<span style="font-size: 16px;">{}</span> <strong>CRC16<span style="color: rgb(17, 124, 238);font-size: 18px;"></span></strong>取模来决定放置哪个槽。集群的每群的每群的每个花个个花个例子,比如当前集群有3个节点,那么 <code style='font-family: SFMono-Regular, Consolas, "Liberation Mono", Menlo, Courier, monospace;background-color: rgba(0, 0, 0, 0.06);border-width: 1px;border-style: solid;border-color: rgba(0, 0, 0, 0.08);border-radius: 2px;padding-right: 2px;padding-left: 2px;'><span style="font-size: 16px;">key</span>通过<span style="font-size: 16px;">CRC16</span>校验后对<span style="font-size: 16px;">16384</span>取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么 <span style="font-size: 16px;">node-1</span> 包含 0 到 5460 号哈希槽,<span style="font-size: 16px;">node-2</span> 包含 5461 到 10922 号哈希槽,<span style="font-size: 16px;">node-3</span>node- 1 包含 0 到 5460 号哈希槽,
<p style="min-height: 24px;margin-bottom: 24px;">node-2<br></p>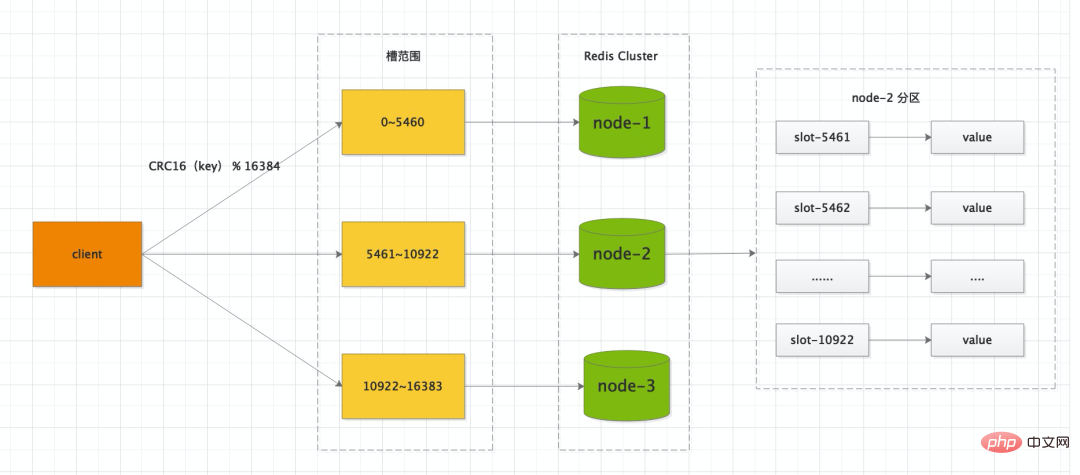 包含 5461 到 10922 号哈希槽,
包含 5461 到 10922 号哈希槽,<p style="min-height: 24px;margin-bottom: 24px;">nod-3<br></p>包含 10922 到 16383 号哈希槽。
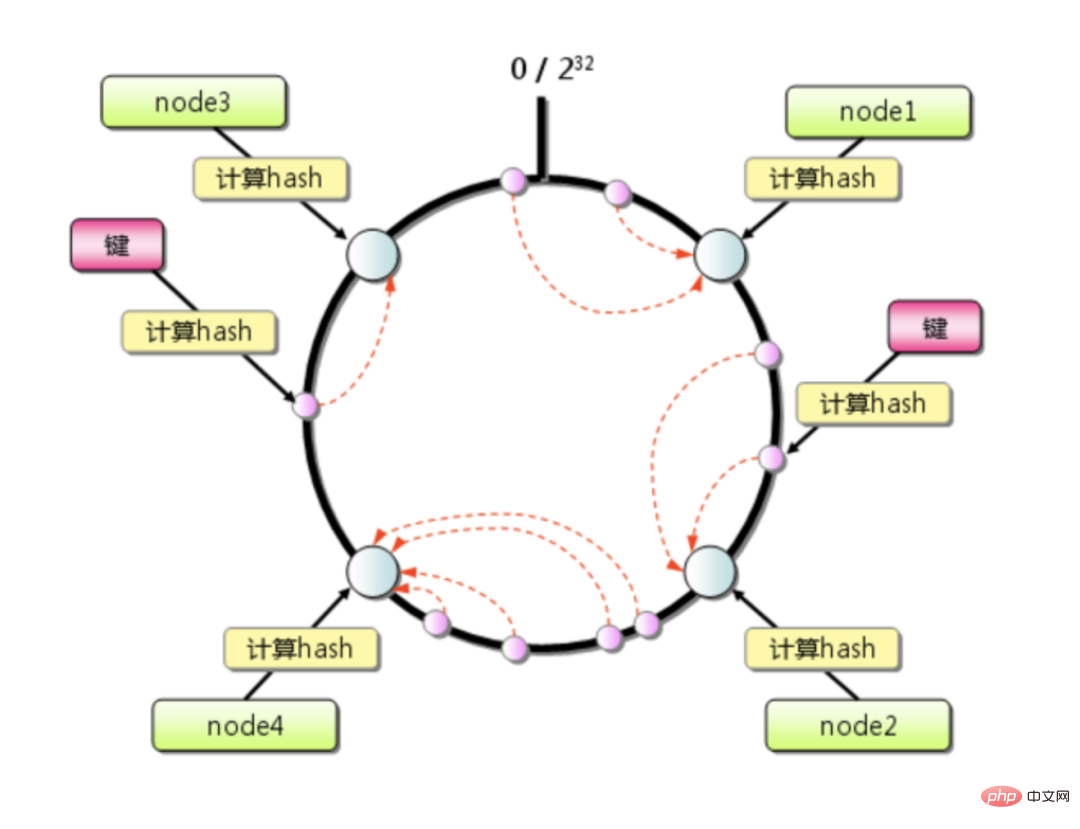 致性哈希算法是 1997年麻省理工学院的 Karger 等人提出了,为的就是解决分布式缓存的问题。上也是一种取模算法,不同于按服务器数量取模,一致性哈希是对固定值 2^32 取模。
致性哈希算法是 1997年麻省理工学院的 Karger 等人提出了,为的就是解决分布式缓存的问题。上也是一种取模算法,不同于按服务器数量取模,一致性哈希是对固定值 2^32 取模。
Algoritma cincang yang konsisten dapat mengurangkan masalah kegagalan cache yang disebabkan oleh pengembangan atau pengecutan, dan hanya memberi kesan kepada segmen kecil kunci yang bertanggungjawab ke atas nod ini. Jika tidak terdapat banyak mesin dalam kluster, dan tahap beban mesin tunggal biasanya sangat tinggi, tekanan yang disebabkan oleh masa henti nod tertentu dengan mudah boleh mencetuskan kesan runtuhan salji. Contohnya:
Kluster Redis mempunyai 4 mesin. hang , mesin seterusnya mengikut arah jam akan menanggung suku tambahan trafik, dan akhirnya akan menanggung separuh daripada trafik, yang masih agak menakutkan.
Tetapi jika anda menggunakan CRC16
Selain itu, jika terdapat perbezaan dalam konfigurasi nod pelayan, kami boleh menyesuaikan nombor slot yang diberikan kepada nod yang berbeza dan melaraskan keupayaan beban nod yang berbeza, yang sangat mudah.
<span style="font-size: 16px;">CRC16</span>
Atas ialah kandungan terperinci Penemubual: Bagaimana untuk menyelesaikan data Redis condong, titik panas dan isu lain. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!