Artikel ini akan membandingkan kaedah yang biasa digunakan untuk mencari elemen halaman web dalam beberapa perangkak Python untuk dipelajari oleh semua orang
“
TradisionalBeautifulSoup operasi
berdasarkan Pemilih CSS BeautifulSoup (dengan PyQuery similar)
<pre class="brush:php;toolbar:false;">http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1</pre><figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/001/267/443/21d313e128464b6c1113677cb281678c-1.jpg" class="lazy" alt="Perbandingan empat kaedah yang biasa digunakan untuk mencari elemen dalam perangkak Python, yang manakah anda lebih suka?" ></figure><p data-tool="mdnice编辑器" style="max-width:90%"> Mari kita ambil tajuk 20 buku pertama sebagai contoh. Mula-mula pastikan tapak web itu tidak menyediakan langkah anti-merangkak, dan sama ada ia boleh mengembalikan kandungan secara terus untuk dihuraikan: </p><pre class="brush:php;toolbar:false;">import requests
url = &#39;http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1&#39;
response = requests.get(url).text
print(response)</pre><figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/001/267/443/21d313e128464b6c1113677cb281678c-2.png" class="lazy" alt="Perbandingan empat kaedah yang biasa digunakan untuk mencari elemen dalam perangkak Python, yang manakah anda lebih suka?" ></figure><p data-tool="mdnice编辑器" style="max-width:90%">Setelah diperiksa dengan teliti, didapati bahawa data yang diperlukan semuanya telah dikembalikan kandungan, menunjukkan bahawa tidak ada keperluan untuk mempertimbangkan langkah anti-merangkak </p>
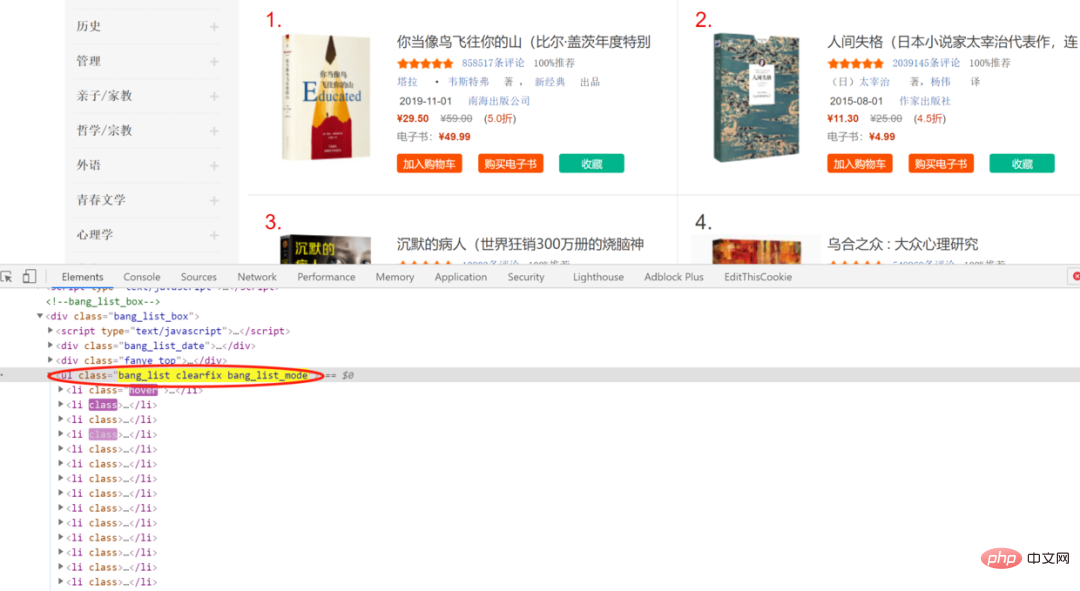
<p data-tool="mdnice编辑器" style="padding-top: 8px;padding-bottom: 8px;line-height: 26px;font-size: 16px;">Semak elemen halaman web Ia boleh didapati kemudian bahawa maklumat bibliografi disertakan dalam <code style="padding: 2px 4px;border-radius: 4px;margin -kanan: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05 );font-family: " operator mono consolas monaco menlo monospace break-all rgb>li in, subordinat kepada class ialah bang_list clearfix bang_list_mode'sul dalam li 中,从属于 class 为 bang_list clearfix bang_list_mode 的 ul 中
Peperiksaan seterusnya juga boleh mendedahkan kedudukan sepadan tajuk buku, yang merupakan asas penting untuk pelbagai kaedah analisis
1. Operasi BeautifulSoup Tradisional
Kaedah BeautifulSoup klasik menggunakan dari bs4 import BeautifulSoup, dan kemudian lulus soup = BeautifulSoup(html, "lxml") Tukar teks kepada struktur Standard tertentu, menggunakan find siri kaedah Analisis, kodnya adalah seperti berikut:
import requests
from bs4 import BeautifulSoup
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def bs_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li') # 锁定ul后获取20个li
for li in li_list:
title = li.find('div', class_='name').find('a')['title'] # 逐个解析获取书名
print(title)
if __name__ == '__main__':
bs_for_parse(response)
🎜🎜 Berjaya memperoleh 20 judul buku. Sebahagian daripadanya panjang dan boleh diproses melalui ungkapan biasa atau kaedah rentetan lain Artikel ini tidak akan memperkenalkannya secara terperinci🎜
import requests
from bs4 import BeautifulSoup
from lxml import html
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def css_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li')
for li in li_list:
title = li.select('div.name > a')[0]['title']
print(title)
if __name__ == '__main__':
css_for_parse(response)
3. XPath
XPath 即为 XML 路径语言,它是一种用来确定 XML 文档中某部分位置的计算机语言,如果使用 Chrome 浏览器建议安装 XPath Helper 插件,会大大提高写 XPath 的效率。
之前的爬虫文章基本都是基于 XPath,大家相对比较熟悉因此代码直接给出:
import requests
from lxml import html
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def xpath_for_parse(response):
selector = html.fromstring(response)
books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")
for book in books:
title = book.xpath('div[@class="name"]/a/@title')[0]
print(title)
if __name__ == '__main__':
xpath_for_parse(response)
4. 正则表达式
如果对 HTML 语言不熟悉,那么之前的几种解析方法都会比较吃力。这里也提供一种万能解析大法:正则表达式,只需要关注文本本身有什么特殊构造文法,即可用特定规则获取相应内容。依赖的模块是 re
import requests
from bs4 import BeautifulSoup
from lxml import html
import re
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def bs_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li')
for li in li_list:
title = li.find('div', class_='name').find('a')['title']
print(title)
def css_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li')
for li in li_list:
title = li.select('div.name > a')[0]['title']
print(title)
def xpath_for_parse(response):
selector = html.fromstring(response)
books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")
for book in books:
title = book.xpath('div[@class="name"]/a/@title')[0]
print(title)
def re_for_parse(response):
reg = '<div class="name"><a href="http://product.dangdang.com/\d+.html" target="_blank" title="(.*?)">'
for title in re.findall(reg, response):
print(title)
if __name__ == '__main__':
# bs_for_parse(response)
# css_for_parse(response)
# xpath_for_parse(response)
re_for_parse(response)
Atas ialah kandungan terperinci Perbandingan empat kaedah yang biasa digunakan untuk mencari elemen dalam perangkak Python, yang manakah anda lebih suka?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!






 观察几个数目相信就有答案了:
观察几个数目相信就有答案了: